




问题:多业务过程(如入职、离职)复用一张用户基础信息表(包含入职时间和离职时间字段)是否需要拆分为多个表?
在数据仓库设计中,多业务过程(如入职、离职)复用一张用户基础信息表(包含入职时间
和离职时间
字段)是否需要拆分为多个表,取决于多个关键因素,并非绝对需要拆或绝对不需要拆,需要结合具体场景权衡利弊。

🧠 不拆分(维持单表)的优点:
查询便捷性高用户基础信息统一存放,如查询用户完整生命周期状态时,单次查询即可获得所有信息(例如:
SELECT user_id, hire_date, resign_date FROM user_base
),避免关联操作。ETL逻辑简单仅需维护一张表的清洗、更新逻辑。入职和离职数据合并处理,流水线开发成本低。
冗余可控若字段数少(如仅核心时间字段),稀疏性(离职率为30%时,
resign_date
空值多)对存储影响不大。列式存储(如Parquet)可有效压缩空值。避免歧义单表不存在「多表关联时用户标识(如user_id)不一致」的问题,数据一致性天然保障。

⚠️ 不拆分的缺点:
生命周期状态耦合活跃用户的离职时间为NULL,但ETL全量更新时可能误触离职逻辑。频繁更新离职字段会影响入职数据的稳定性(如写锁竞争)。
查询性能隐患若表过大,高频查询只需入职时间(如统计入职率)却被迫扫描离职时间,浪费I/O资源。分区优化也需同时兼顾两个时间维度。
业务语义混杂「入职」和「离职」属于独立事件流,强行合并会模糊业务边界。分析师可能误解离职时间为用户属性而非事件时间点。
扩展性限制后期若需增加离职原因、离职审批流程ID等字段,表结构膨胀加剧;而入职过程若增加入职批次、岗位类型等字段时,无关字段混杂共存。

✅ 拆分(入职表、离职表 + 用户基础表)的优点:
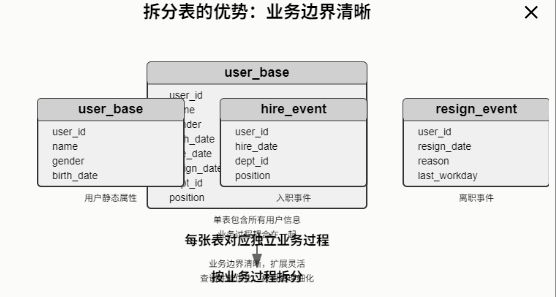
业务边界清晰每张表对应独立业务过程:
user_base
:用户静态属性(姓名、性别、出生日期)hire_event
:入职事件(user_id, hire_date, dept_id, position)resign_event
:离职事件(user_id, resign_date, reason, last_workday)模型扩展灵活新增业务过程如「调岗」「晋升」可直接增表,不影响现存结构。历史表结构独立演进无压力。
查询性能优化高频场景针对性优化:
入职分析:仅扫描
hire_event
(可分区hire_date)在职用户统计:
user_base
LEFT JOINresign_event
(索引高效)权限管理细化敏感离职信息独立管控,避免基础信息表权限过大(如HR部门仅可访问
resign_event
但不接触身份证号等字段)。处理逻辑解耦入职ETL流程(实时同步)和离职ETL(T+1批量)可独立配置,降低故障传播风险。
⚠️ 拆分的缺点:
关联查询复杂度增加需通过JOIN获取完整用户状态,代码复杂度提升。例如:
-- 拆表后查询用户全量信息
SELECT
b.user_id,
h.hire_date,
r.resign_date
FROM user_base b
LEFT JOIN hire_event h ON b.user_id = h.user_id
LEFT JOIN resign_event r ON b.user_id = r.user_id;存储开销略增多表元数据(如HDFS小文件)、索引重复(user_id)带来额外存储消耗(但通常可忽略)。
一致性维护成本需确保跨表user_id完全同步。若入职失败但基础信息已生成,需引入事务或补偿机制。

🔍 决策建议:
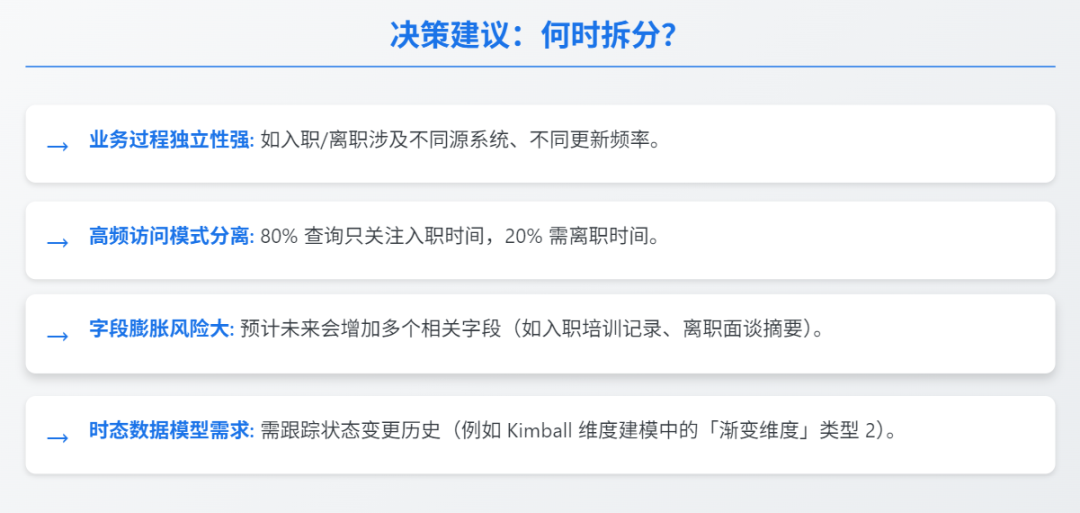
优先考虑拆分场景 →
业务过程独立性强:如入职/离职涉及不同源系统、不同更新频率
高频访问模式分离:80%查询只关注入职时间,20%需离职时间
字段膨胀风险大:预计未来会增加多个相关字段(如入职培训记录、离职面谈摘要)
时态数据模型需求:需跟踪状态变更历史(例如Kimball维度建模中的「渐变维度」类型2)
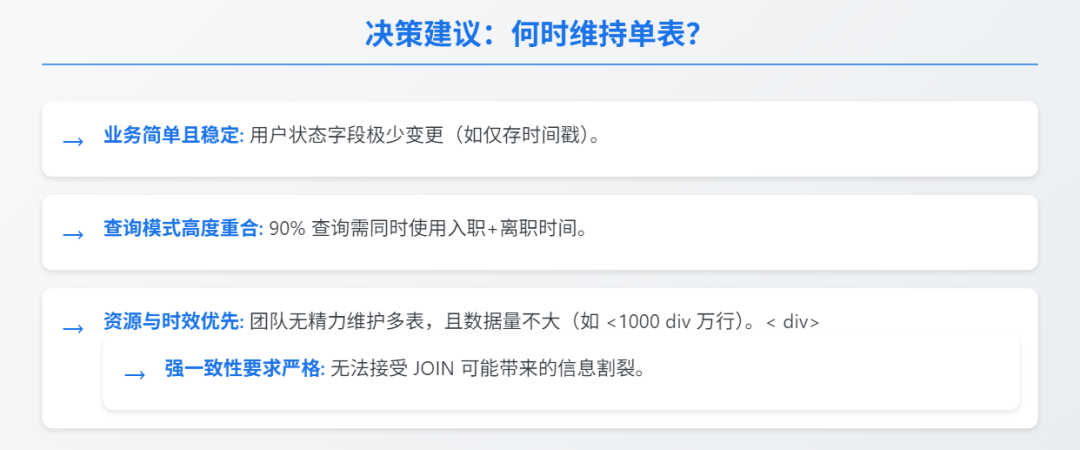
维持单表更佳场景 →
业务简单且稳定:用户状态字段极少变更(如仅存时间戳)
查询模式高度重合:90%查询需同时使用入职+离职时间
资源与时效优先:团队无精力维护多表,且数据量不大(如<1000万行)
强一致性要求严格:无法接受JOIN可能带来的信息割裂
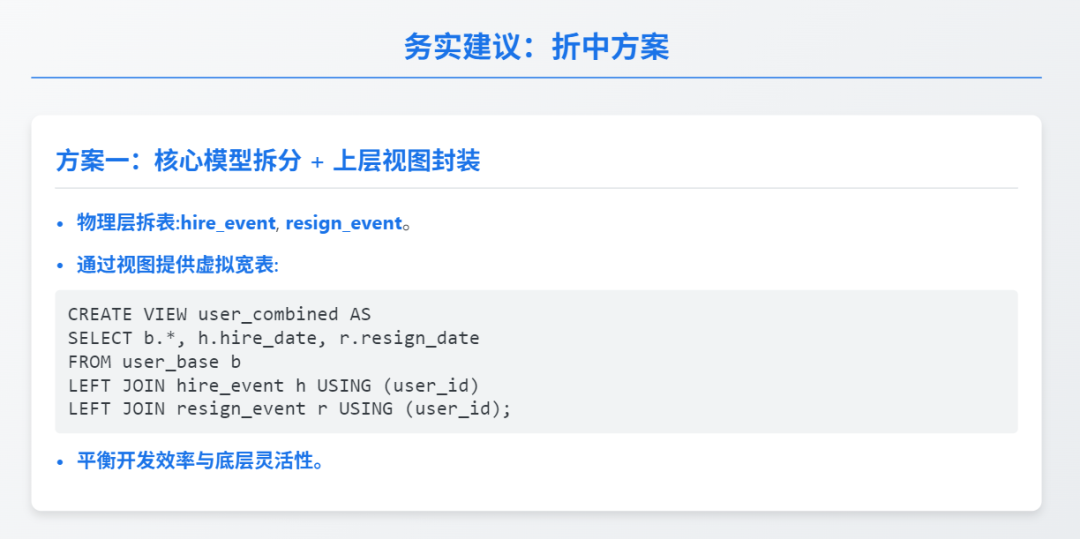
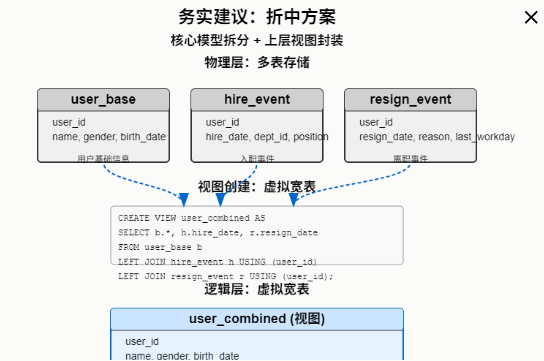
⚖️ 务实建议:折中方案
核心模型拆分 + 上层视图封装物理层拆表(
hire_event
/resign_event
),通过视图提供虚拟宽表:
CREATE VIEW user_combined AS
SELECT b.*, h.hire_date, r.resign_date
FROM user_base b
LEFT JOIN hire_event h USING (user_id)
LEFT JOIN resign_event r USING (user_id);✅ 平衡开发效率与底层灵活性
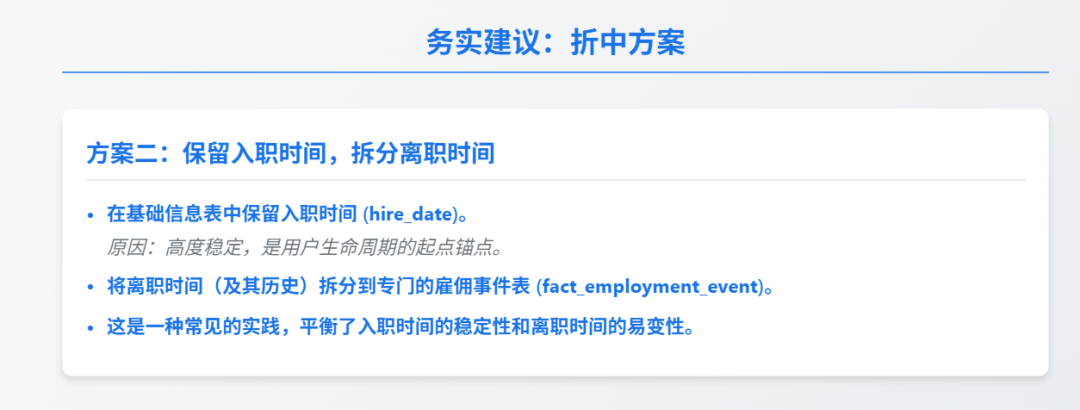
折中方案2:在基础信息表中保留入职时间
(因为它高度稳定且是用户生命周期的起点),将离职时间
(及其历史)拆分到专门的雇佣事件表。 这是一种常见的实践,平衡了入职时间的稳定性和离职时间的易变性。
为了更好地理解折中方案2,我们给出以下示例,帮助读者理解
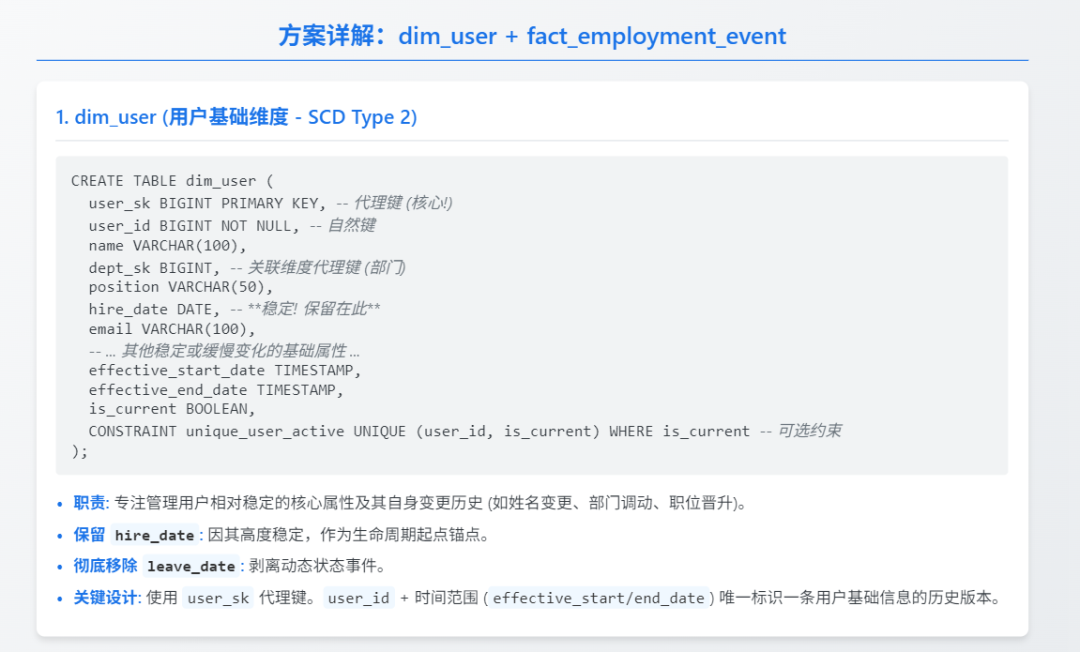
🧠方案: dim_user
+ fact_employment_event
dim_user
(用户基础维度 - SCD Type 2)
CREATETABLE dim_user (
user_sk BIGINT PRIMARY KEY, -- 代理键 (核心!)
user_id BIGINTNOTNULL, -- 自然键
name VARCHAR(100),
dept_sk BIGINT, -- 关联维度代理键 (部门)
position VARCHAR(50),
hire_date DATE, -- **稳定! 保留在此**
email VARCHAR(100),
-- ... 其他稳定或缓慢变化的基础属性 ...
effective_start_date TIMESTAMP,
effective_end_date TIMESTAMP,
is_current BOOLEAN,
CONSTRAINT unique_user_active UNIQUE (user_id, is_current) WHERE is_current -- 可选约束
);职责: 专注管理用户相对稳定的核心属性及其自身变更历史 (如姓名变更、部门调动、职位晋升)。
保留
hire_date
: 因其高度稳定,作为生命周期起点锚点,留在基础维度是合理且安全的。其变更概率远低于离职状态。彻底移除
leave_date
: 剥离动态状态事件。关键设计: 使用
user_sk
代理键。user_id
+ 时间范围 (effective_start/end_date
) 唯一标识一条用户基础信息的历史版本。
fact_employment_event
(雇佣关系事件事实表)
CREATETABLE fact_employment_event (
event_id BIGSERIAL PRIMARY KEY, -- 事件唯一ID (可选, 利于去重、审计)
user_id BIGINTNOTNULL, -- 关联用户自然键 (关键! 避免代理键陷阱)
-- user_sk BIGINT, -- **谨慎! 关联维度代理键的陷阱 (见下文分析)**
event_type VARCHAR(20) NOTNULL, -- 'HIRED', 'LEFT', 'REHIRED', 'CONVERSION' (转正), 'TRANSFER' (调岗)
event_time TIMESTAMPNOTNULL, -- 事件发生精确时间点
effective_date DATENOTNULL, -- 事件生效日期 (通常 = DATE(event_time))
-- 事件相关属性
leave_reason VARCHAR(100), -- 当 event_type = 'LEFT'
previous_position VARCHAR(50), -- 当 event_type = 'TRANSFER'/'DEMOTION'
target_dept_id BIGINT, -- 当 event_type = 'TRANSFER'
-- ... 其他事件专有属性 ...
record_created_at TIMESTAMP DEFAULT NOW(),
-- 可选: 记录来源、操作人等审计字段
);
-- 重要索引: (user_id, effective_date), (event_type, effective_date)
职责:记录雇佣关系生命周期中的所有关键事件。以事务事实表思维构建。
核心字段:
- user_id: 强烈建议使用自然键! 避免关联 dim_user.user_sk 的代理键。为什么?
- 代理键陷阱: user_sk 随 dim_user 的 SCD Type 2 变更而变化。一个用户的 user_id 可能对应多个 user_sk。将 fact_employment_event 关联到 user_sk 意味着:
- 要么关联到事件发生当时有效的 user_sk (需要复杂的时间点快照关联,ETL 逻辑沉重)。
- 要么关联到当前有效的 user_sk (历史事件关联关系会随着 dim_user 的 SCD 变更而断裂!灾难性错误!)。
- 自然键优势: user_id 是用户不变的业务标识。fact_employment_event 记录的是发生在这个用户身上的事件,无论其基础信息在 dim_user 中如何变化。关联分析时,通过 user_id 关联到 dim_user 的当前视图或特定历史视图更清晰、可控。
- event_type: 明确的事件类型标识。
- event_time/effective_date: 事件发生的精确时间点和生效日期。更新模式:只增不改 (Insert-Only)。任何状态变更(包括离职日期修正)都通过插入新事件记录 (
event_type='REHIRED'
或'LEFT'
) 实现,规避更新冲突。历史追溯: 天然完整。按
user_id
排序effective_date
即可清晰看到雇佣状态全生命周期变迁。扩展性: 新增事件类型 或事件属性极其方便,不影响
dim_user
。

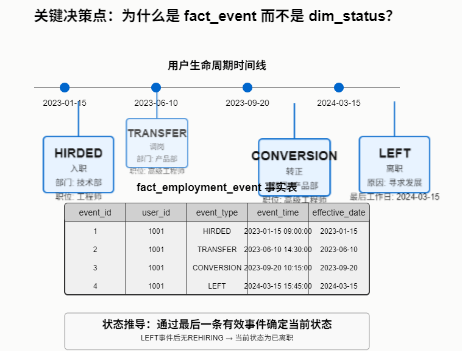
关键决策点:为什么是 fact_event
而不是 dim_status
?
fact_employment_event
(事件表) 优势:纯粹的事件溯源: 完美记录状态变迁的每一次跃迁及其上下文。
无状态推导: 当前状态 可通过
user_id
的最后一条有效事件 (LEFT
事件后无REHIRED
) 计算得出处理复杂变更: 轻松应对多次离职/复职、状态修正。
扩展性强: 容纳任意雇佣相关事件。
关联分析: 方便与其他事件流(如绩效事件、薪资事件)关联。
dim_employee_status
(状态维度) 适用场景:对当前状态查询性能要求极端苛刻。
业务上不关心完整的历史状态变迁细节,只关注当前结果。
可作为基于
fact_employment_event
的汇总物化视图/快照存在。
高级建议:优先构建 fact_employment_event
。它是雇佣关系状态的唯一可信源。在其之上:
通过视图 (View) 提供当前状态 (
dim_employee_status
的模拟)。通过周期性快照或累积快照 (Accumulating Snapshot) 满足特定分析场景。
保持核心事件表的纯净与权威性。
📌 结论
优先选择单表:若业务稳定、查询为主、无复杂扩展需求。
优先选择拆分表:若业务高频变更、需审计跟踪、未来可能增加事件类型。
终极方案:采用星型模型,将核心属性放维度表,业务事件作事实表关联,兼顾灵活性与性能。
最终思考
面对 用户基础信息表
中耦合的 hire_date
与 leave_date
,尤其当业务具备一定规模与复杂度时,“拆” 不是可选项,而是保障数仓可维护性、性能、扩展性与数据质量的必然工程选择。这一拆分的本质,是遵循维度建模的核心原则——按业务过程构建模型。
资深数仓工程师的价值,不仅在于实现功能,更在于预见耦合带来的长期架构腐蚀,并运用建模思想,构建清晰、健壮、可持续演进的数仓模型。拆,是为了更优雅地构建;解耦,是为了更强大地生长

