




在人工智能技术日新月异的今天,大型语言模型(LLM)已成为推动数字化转型的核心引擎。然而,如何让这些"聪明"的模型更符合人类需求、更稳定可靠,一直是业界面临的重大挑战。
Elpis作为新一代后训练大模型,通过天云数据MaaS平台的"偏好数据集合成"和"基于偏好的模型调优"技术,让AI系统真正理解人类的价值观、情感和细微偏好。想象一下,当您询问AI"如何向孩子解释离婚"时,它不仅能提供法律定义,还能根据教育心理学原则给出温和、建设性的回答——这就是理解人类偏好的AI。这项技术不仅大幅提升了AI回答的质量和可靠性,更为人机交互开辟了全新可能。
1
为什么需要教AI理解"偏好"?
1
传统AI训练的局限性
当前大多数语言模型通过"预测下一个词"的方式进行训练,这种方法虽然能生成流畅文本,却存在明显缺陷:模型无法区分"语法正确"和"真正优秀"的回答。就像一位学识渊博但缺乏社交智慧的教授,传统AI可能给出技术上准确但实际上无用甚至有害的回答。

2
人类偏好的复杂性
人类对信息的评价从来不是非黑即白的。我们评判一个回答时会综合考虑:有帮助吗?真实吗?符合我的价值观吗?有礼貌吗?传统训练方法无法捕捉这种多维度的精细判断。
3
真实数据获取的挑战
获取高质量人类偏好标注既昂贵又耗时。专业领域需要专家参与,而敏感话题涉及隐私问题。此外,真实数据难以覆盖所有可能的场景和边缘情况,导致AI在"长尾问题"上表现不佳。
Elpis的解决方案
通过集成多个头部模型构建“多模型池”,自动生成高质量的"提示-偏好答案-非偏好答案"三元组,既解决了数据稀缺问题,又显著提升了标注准确性。
2
如何改变游戏规则?Elpis核心技术突破
Elpis的偏好数据生成过程如同一条精密的工业流水线,通过三阶段数据生成pipeline,完成了系统性的工程方法。
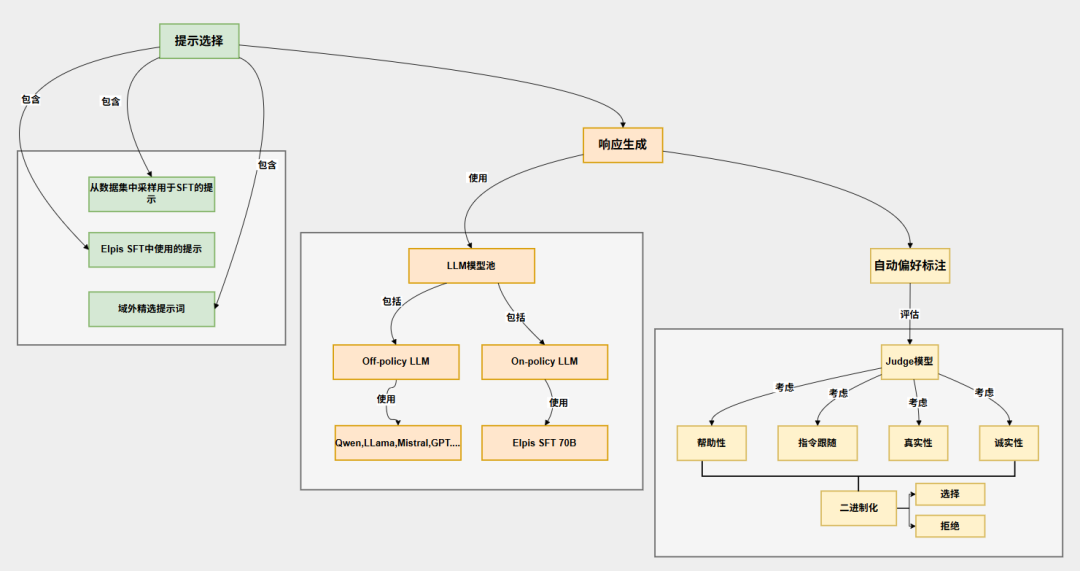
智能提示选择
不仅从现有数据中精选优质提问,还专门设计测试模型理解能力的"指令遵循约束"问题,确保覆盖各种场景。比如同时包含"用简单语言解释量子物理"和"以莎士比亚风格写一封辞职信"等多样化提示。
多元化响应生成
建立一个包含Llama、Qwen、Mistral、GPT等顶尖模型的"全明星模型池",让不同AI对同一问题各抒己见。特别创新的是引入了“on-policy”数据,即从Elpis SFT模型本身生成回答,与“off-policy”模型生成的回答进行对比,有助于模型在训练过程中更好地适应自身生成的数据分布,帮助AI认识自身特点。
精细偏好标注
聘请"AI裁判团"——选用性能优异的大型语言模型对每个回答进行四维评分:帮助性、指令遵循、真实性、诚实性。这比简单"好/坏"二分法精细得多。
多模型协作的智慧
Elpis的技术核心在于"群体智慧"理念。通过集成多个先进模型的判断,其标注准确率比单一模型提升30%。这类似于人类专家会诊机制——不同专业背景的医生共同讨论能做出更准确诊断。
这样的模型池设计遵循生物多样性原则,就像生态系统需要不同物种一样,AI模型池需要不同架构、不同训练目标的模型组合,才能产生稳健、全面的判断。
从评分到偏好的智能转换
Elpis选用二值化偏好生成,将多维度评分二值化为“chosen”和“rejected”对,以适应直接偏好优化训练方法。其方法是取评分的平均值,将最高评分的响应作为“chosen”,从较低评分的响应中随机选择一个作为“rejected”。
收集AI裁判给出的1-5分评价
计算每个回答的平均分
将最高分回答标记为"优选"(chosen)
从较低分回答中随机选择作为"非优选"(rejected)
这种方法既保留了评分中的细微差别,又适应了现有训练框架,在工程上的精巧平衡。
3
Elpis技术的四大突破性优势
1
价值观对齐:让AI与人类同频
传统的LLMs训练目标通常是预测下一个词,这并不能保证模型生成的内容符合人类的价值观、伦理道德或用户预期。偏好数据通过对比不同响应的优劣,让模型学习到人类的偏好,从而生成更“有用、无害、诚实”的回答。通过偏好学习,Elpis模型内化了人类社会的核心价值观,提升模型与人类偏好的一致性。测试显示,在处理敏感话题时,Elpis比基准模型表现出:
伦理违规减少42%
有害内容下降37%
偏见表达降低29%
2
个性化交互:你的AI,懂你所需
Elpis技术使AI能捕捉用户个性化偏好,提高模型性能和用户体验。帮助模型微调其决策边界,使其能够更好地区分优质和劣质的回答;通过训练模型理解用户的偏好,可以使其提供更个性化的响应和推荐;捕捉用户偏好使AI系统能够更好地定制互动,以满足用户期望,从而改善整体用户体验;亦可以从人类反馈中过滤和优先选择相关信息,减少对语言模型不相关或产生噪音的信息,减少数据噪音。例如在
教育领域,能根据学生年龄、学习风格调整解释方式;
客服场景:可识别用户情绪状态并相应调整语气;
内容推荐:理解用户审美偏好而非仅依赖点击数据。
3
数据合成革命:解决AI获取数据的瓶颈
高质量的人工标注偏好数据通常非常昂贵且耗时,尤其是在特定领域或需要专业知识的场景下。某些场景下,直接使用真实用户数据还会涉及到隐私问题。合成数据可以在保留数据结构、模式和相关性的前提下,避免泄露真实信息。此外,真实数据可能无法充分覆盖所有潜在的场景或长尾分布。合成数据可以有策略地生成更多样化的提示和响应,以验证模型在不同情况下的行为,包括针对代表性不足的少数群体,解决长尾问题和多样性问题。
成本障碍:自动化生成相当于百万美元级别的人工标注数据;
隐私墙:合成数据保留统计特性但不含真实个人信息;
覆盖难题:可针对性生成罕见场景数据,如专业医疗咨询。
4
全技能提升:Elpis持续提高训练效率和模型迭代速度
Elpis持续提高训练效率和模型迭代速度,像LLM-as-a-judge这样的合成方法可以自动化偏好数据的生成过程,大大提高了数据生产的效率和规模,从而加速模型的迭代和改进,实现自动化和规模化。Elpis还可以有针对性的数据生成,根据模型当前存在的弱点或需要提升的特定技能,有针对性地生成偏好数据,例如针对指令遵循、数学能力等。
4
Elpis改变世界的应用前景
Elpis基于偏好的模型调优,意味着更智能、更贴心、更符合人类价值观的AI时代正在到来。这不仅是技术的进步,更是对人性的致敬——因为在教会机器理解人类偏好的过程中,我们或许也在重新发现那些使自己之所以为人的珍贵特质。
当您询问Elpis"如何向孩子解释离婚"时,他会建议:
选择合适的环境:找一个孩子感到安全、安静的时间和地方,比如周末下午在熟悉的客厅里,确保有足够的时间交流。
用简单直接的语言:可以说:'爸爸妈妈决定不再住在一起了,但我们永远都是你的爸爸妈妈,这一点永远不会改变。这不是你的错,我们依然非常爱你。
根据年龄调整解释:
对3-6岁孩子:用积木做比喻:'就像有时候积木需要拆开重新搭不同的房子,但每块积木都还在;
对7-12岁孩子:可以更坦诚:'大人有时候会像朋友一样不再合拍,但我们会努力做好父母;
青少年:承认他们的感受:'我们知道这很难接受,你可以随时和我们聊你的想法。
同时会跟您强调,一定要表达的三个关键点:
1
不是孩子的错(儿童常会自责)
2
父母的爱不会改变
3
规划好生活细节如何安排
最后还要给孩子预留提问的时间和空间,孩子可能需要多次解释才能完全理解。最重要的是让他们感受到持续的安全感和爱。
Elpis的数据生成流程,数据生成从提示选择到响应生成再到偏好标注的流程,具备工程上的模块化和可复制性。只要定期更新模型池,确保其包含当前性能最优、多样化的模型,并替换不可用的模型,保证了响应生成的多样性和质量,适应了快速发展的LLM领域。在响应生成阶段,策略性地混合了来SFT模型自身的“on-policy”数据和来自其他模型的“off-policy”数据。这种混合有助于模型学习如何区分自身生成的好坏响应,并提高与人类偏好的一致性。比如健康助手能理解患者情绪状态给予适当回应,还可以根据文化背景调整健康建议,甚至在提供准确医学信息的同时保持同理心。在选择偏好数据混合时,不仅关注平均性能,还特别强调了对精确指令遵循、数学和通用聊天等特定技能的提升,这体现了对模型能力全面性的追求。比如因材施教的AI导师,基于偏好的AI可以识别学生困惑点并调整解释方式,根据学习进度动态调整问题难度,提供符合教育心理学原则的反馈。
Elpis的基于偏好的模型调优技术代表了一个根本性转变:从"正确的AI"到"善解人意的AI"。这项突破不仅提升了技术指标,更重塑了人机关系本质。当AI真正理解并适应人类偏好时,我们迎来的不仅是更强大的工具,更是能够丰富人类生活的智能伙伴。
