




如何导入
通常,我们按如下方式导入:
In [1]: import numpy as npIn [2]: import pandas as pd
Pandas的基本数据结构
Pandas 提供了两种类型的类来处理数据:
Series: 保存任何类型数据的一维标记数组
such as integers, strings, Python objects etc.
DataFrame:一种二维数据结构,用于保存类似 二维数组或包含行和列的表。
Object creation对象创建
通过传递值列表来创建Series,让 pandas 创建 默认的 RangeIndex.
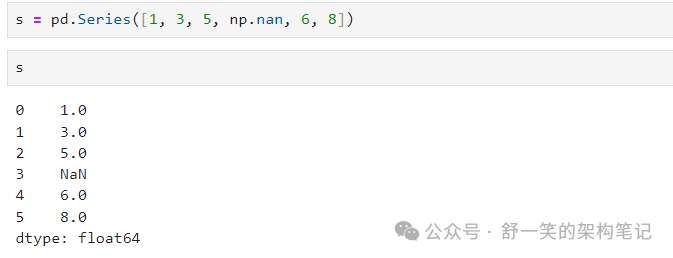
通过使用 date_range() 传递具有日期时间索引的 NumPy 数组来创建 DataFrame 和标记的列:
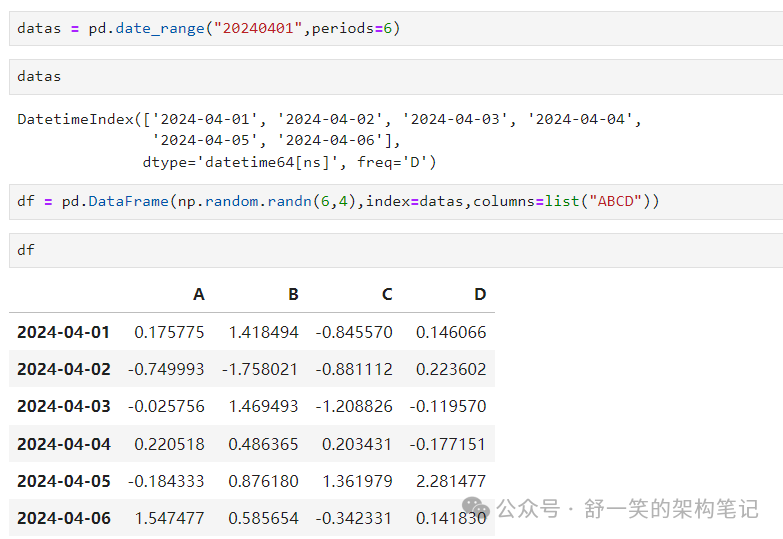
通过传递对象字典(其中键为列)创建 DataFrame 标签和值是列值。
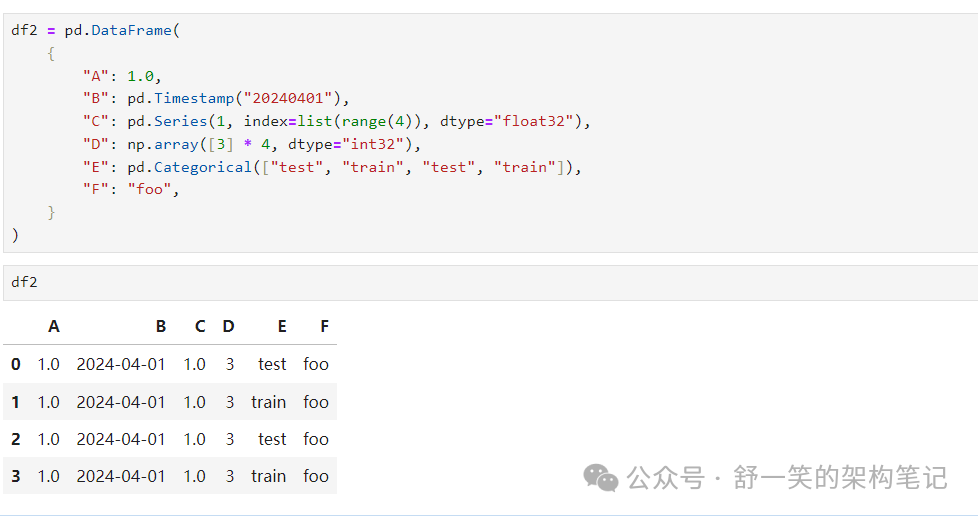
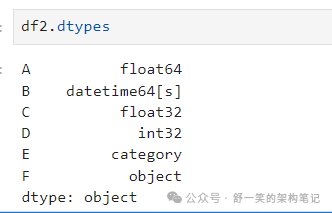
生成的 DataFrame 的列具有不同的 类型:
Viewing data查看数据
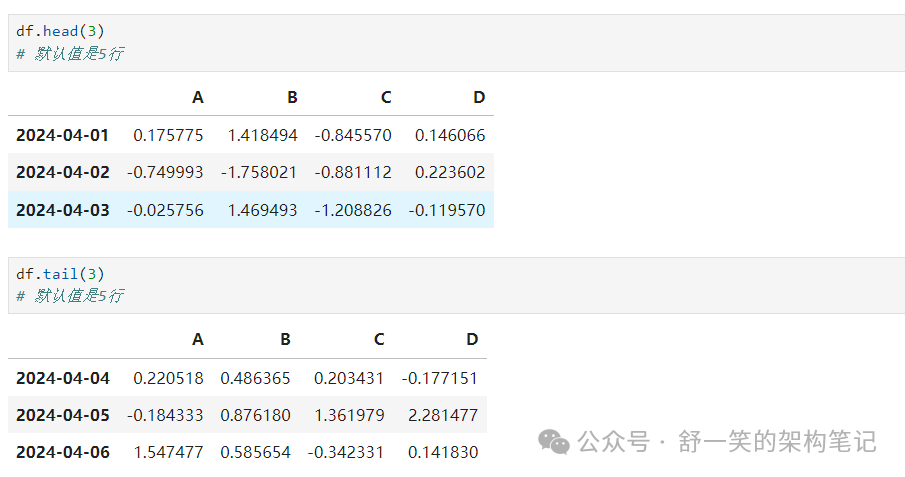
使用 DataFrame.head() 和 DataFrame.tail() 查看框架的顶行和底行 分别:如何参数未指定默认显示5行
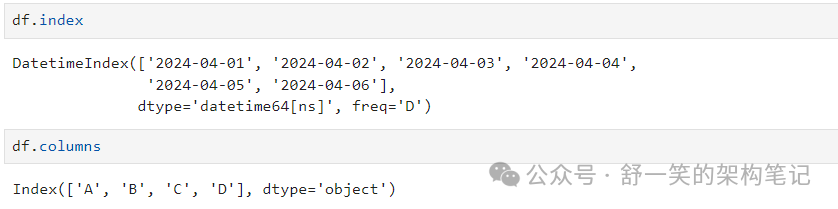
显示 DataFrame.index 或 DataFrame.columns:
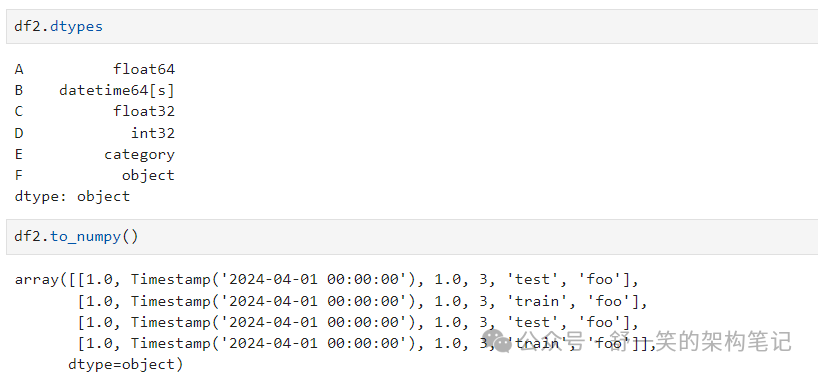
返回基础数据的 NumPy 表示形式,并带有“DataFrame.to_numpy()” 没有索引或列标签:

NumPy 数组对整个数组有一个 dtype,而 pandas DataFrames 每列有一个 dtype。当你调用“DataFrame.to_numpy()”时,熊猫会 找到可以保存 DataFrame 中所有 dtype 的 NumPy dtype。 如果通用数据类型为“object”,则DataFrame.to_numpy()“将需要 复制数据。
describe() 显示数据的快速统计摘要

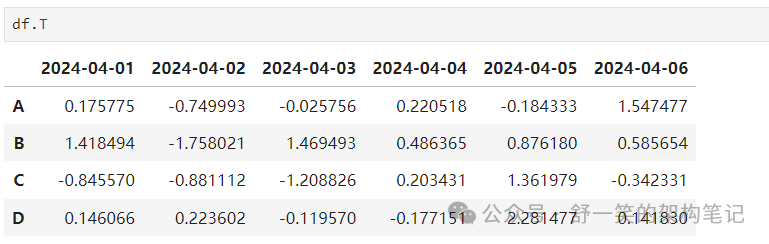
转置数据
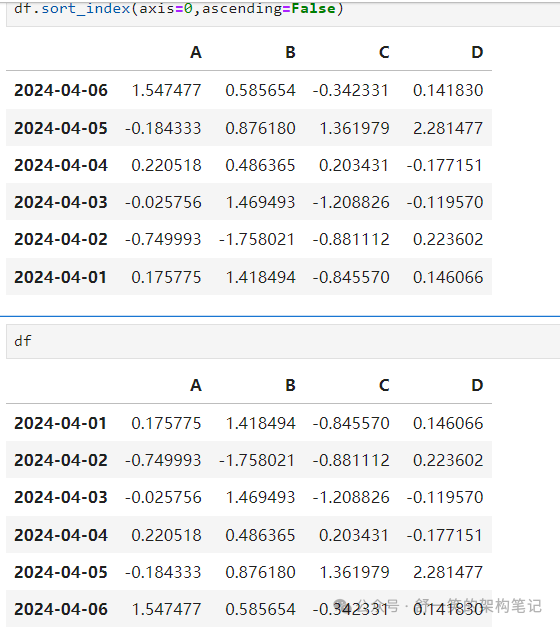
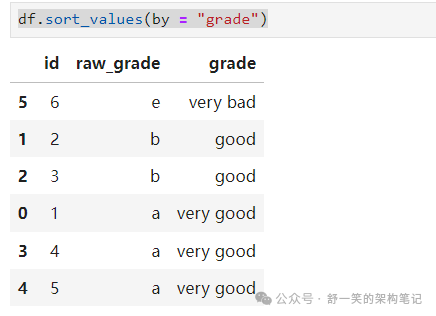
DataFrame.sort_index() 按轴排序:
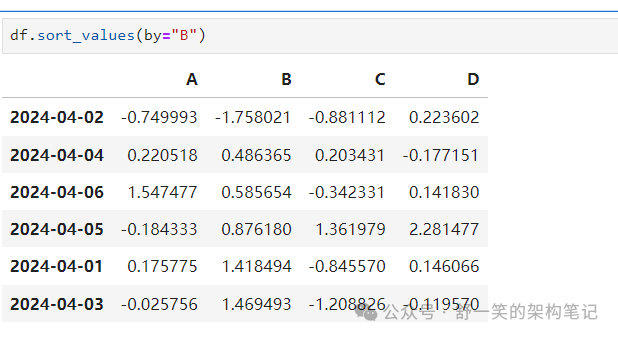
DataFrame.sort_values() 按值排序: 在这里插入图片描述
Selection选择
选择和设置的标准 Python NumPy 表达式是 直观且方便交互式工作,对于生产代码,我们 推荐优化的 pandas 数据访问方式 DataFrame.at()DataFrame.iat()、DataFrame.loc() 和 DataFrame.iloc()
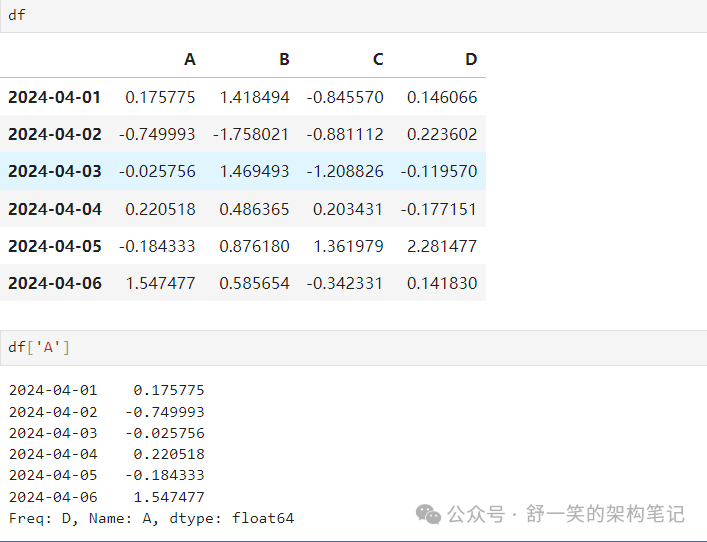
对于 DataFrame,传递单个标签会选择列和 生成一个等效于 'df 的序列。A'
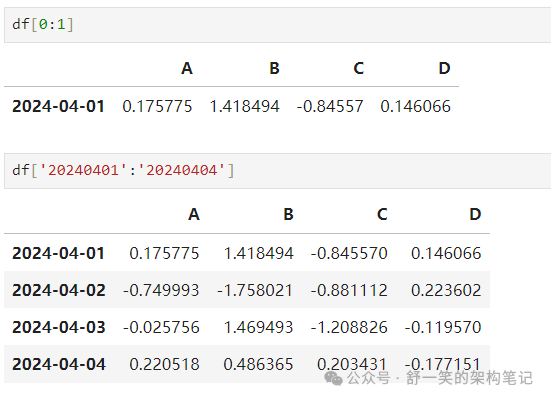
对于 DataFrame,传递切片会选择匹配的行:
Selection by label按标签选择
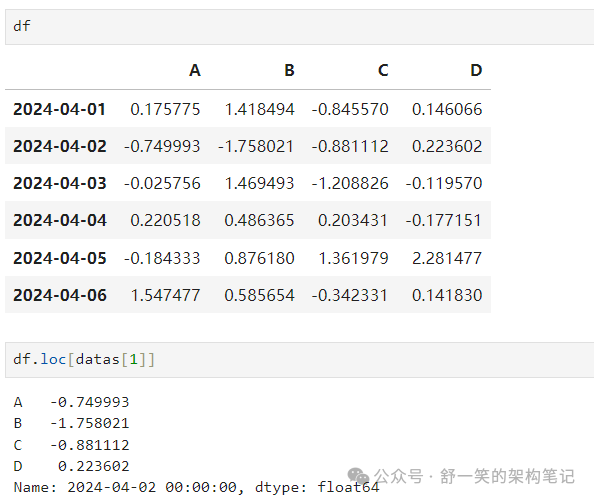
选择与标签匹配的行:
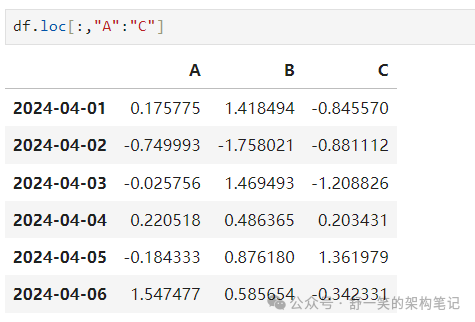
选择所有行 (:) 并选择列标签
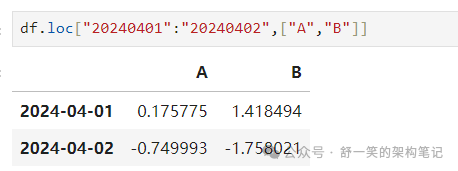
对于标签切片,包括两个终结点:
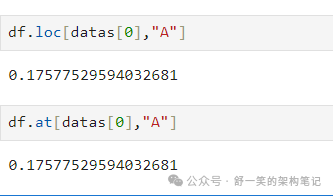
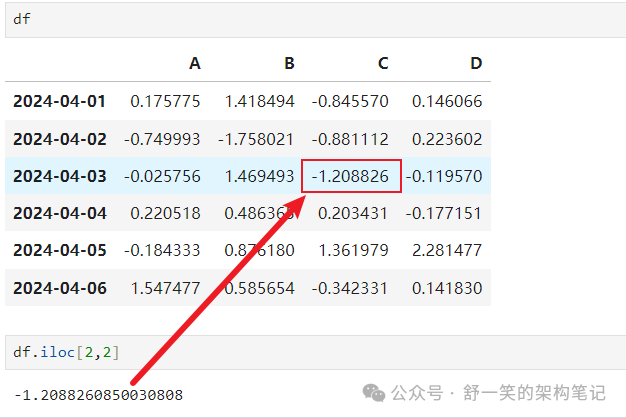
选择单行和列标签将返回标量
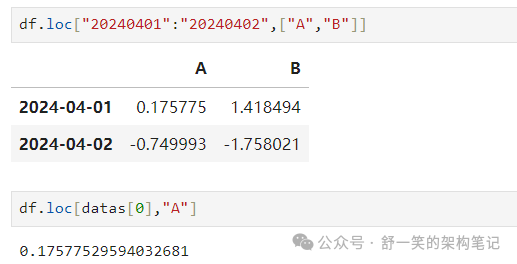
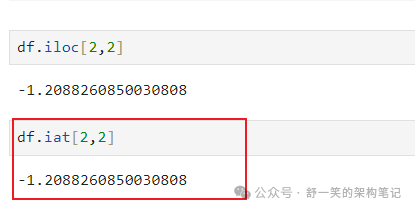
为了快速访问标量(等效于前面的方法):
在这里插入图片描述
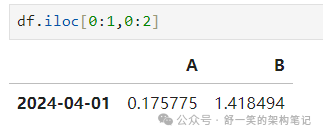
Selection by position按位置选择
通过传递的整数的位置进行选择:

整数切片的作用类似于 NumPy/Python:
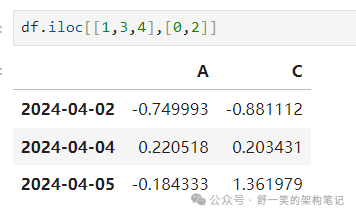
整数位置列表:
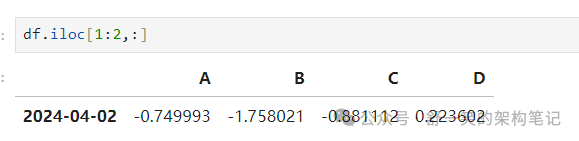
对于显式切行:
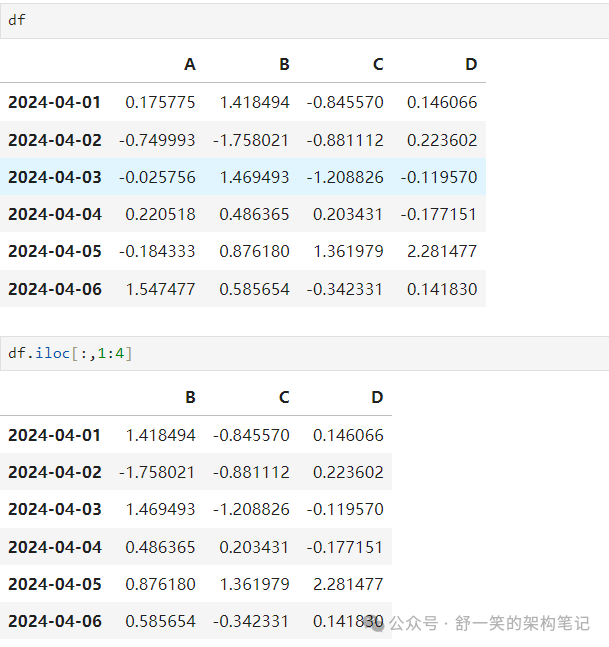
对于显式切片列: 在这里插入图片描述 要显式获取值: 在这里插入图片描述 为了快速访问标量(等效于前面的方法): 在这里插入图片描述 在这里插入图片描述
Boolean indexing布尔索引
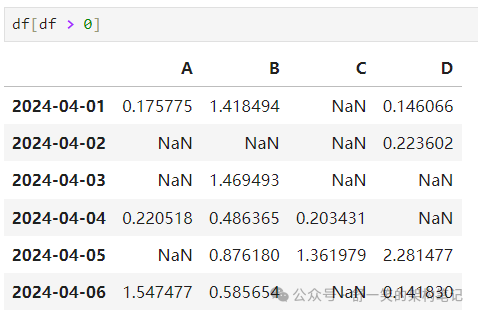
选择其中 'df.A' 大于0.
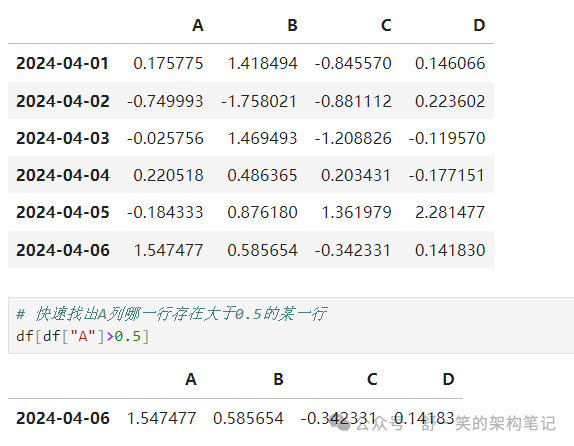
从满足布尔条件的 DataFrame 中选择值
使用 isin() 方法进行过滤:

Setting设置
设置新列会自动按索引对齐数据:
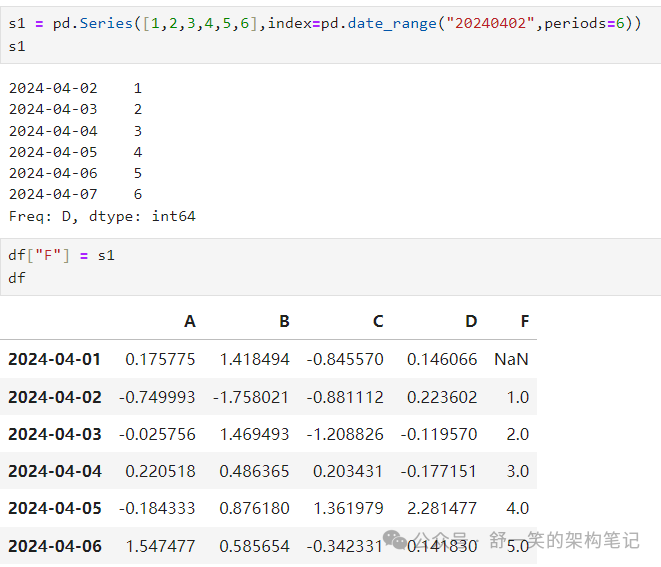
按标签设置值:

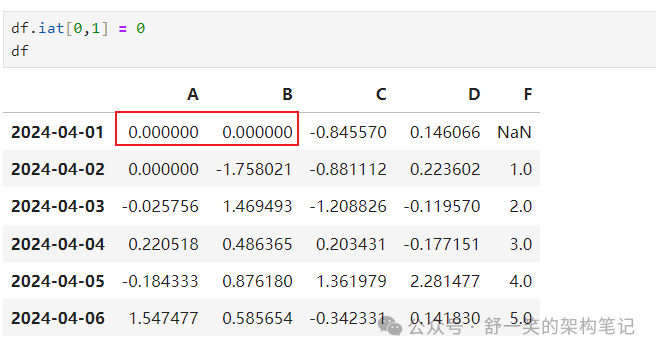
按位置设置值:
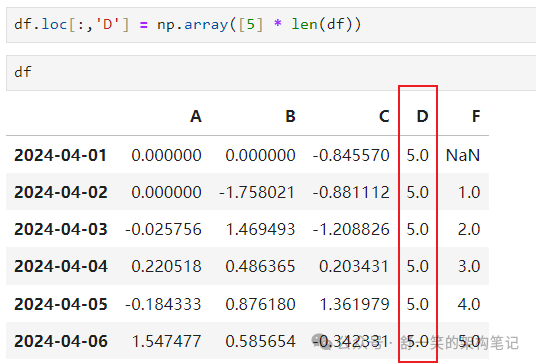
通过使用 NumPy 数组进行赋值进行设置:
带有设置的“where”操作:
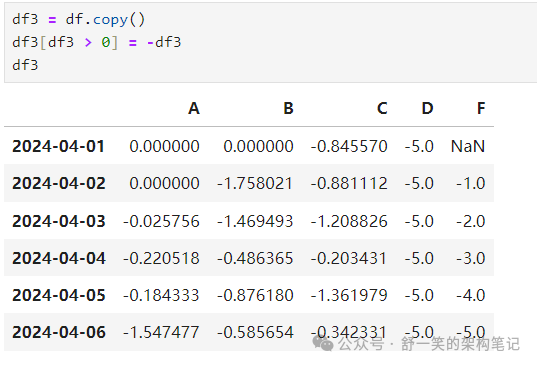
Missing data缺少数据
对于 NumPy 数据类型,“np.nan”表示缺失数据。它是由 默认值不包括在计算中。
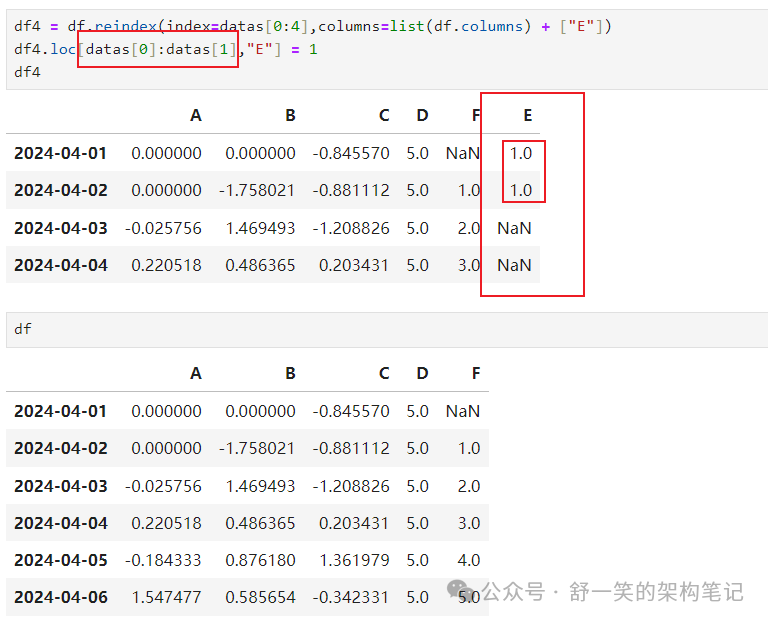
重新索引允许您更改/添加/删除指定轴上的索引。这 返回数据的副本:
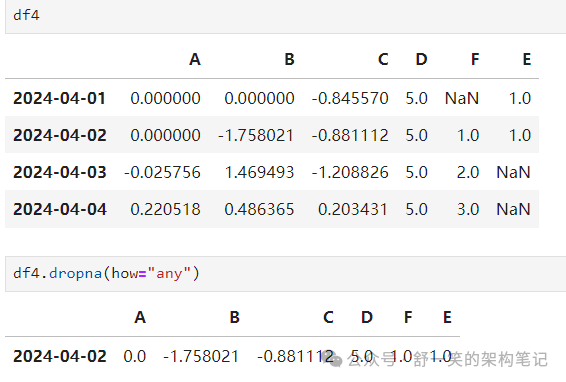
DataFrame.dropna() 删除任何缺少数据的行:
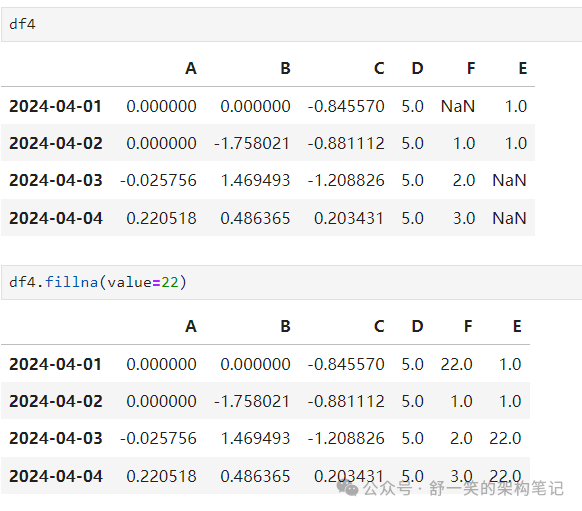
DataFrame.fillna() 填充缺失的数据:
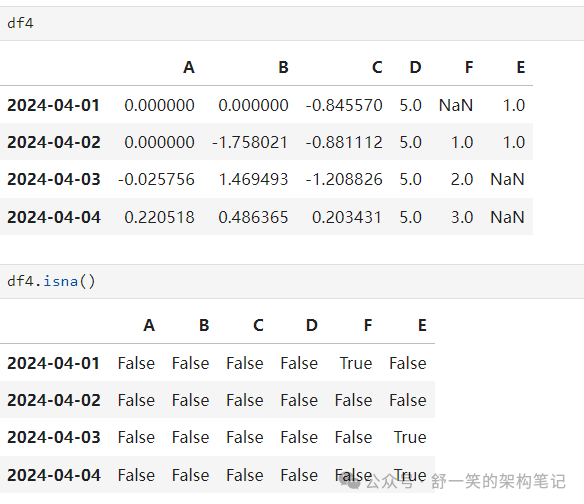
isna() 获取值为 'nan' 的布尔掩码:
Operations操作
操作通常排除缺失数据。
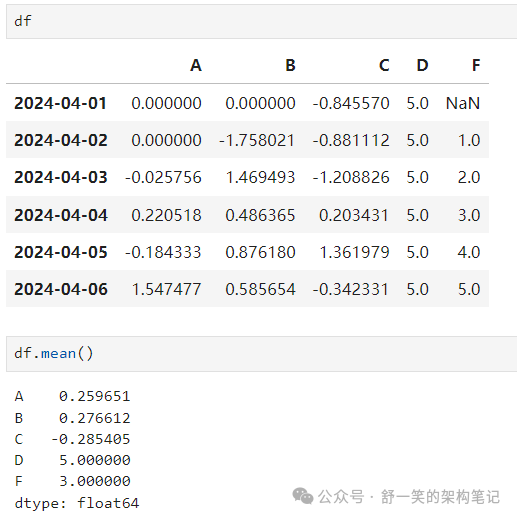
计算每列的平均值:
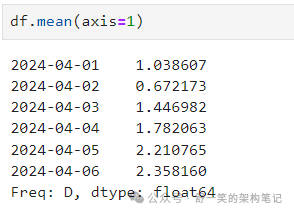
计算每行的平均值:
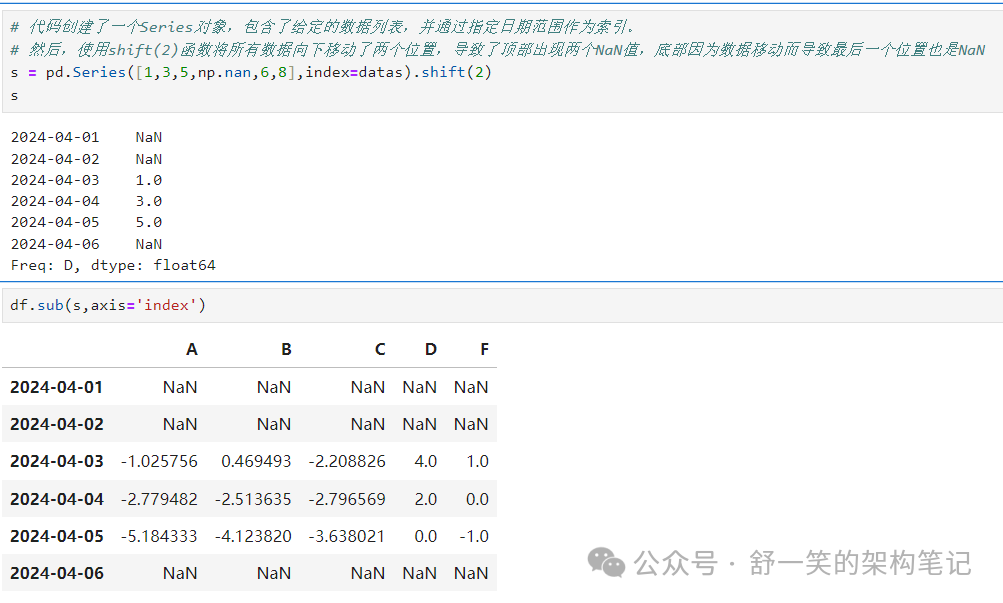
使用具有不同索引或列的另一个 Series 或 DataFrame 进行操作 将使结果与索引或列标签的并集对齐。此外,大熊猫 自动沿指定尺寸广播,并将使用“np.nan”填充未对齐的标签
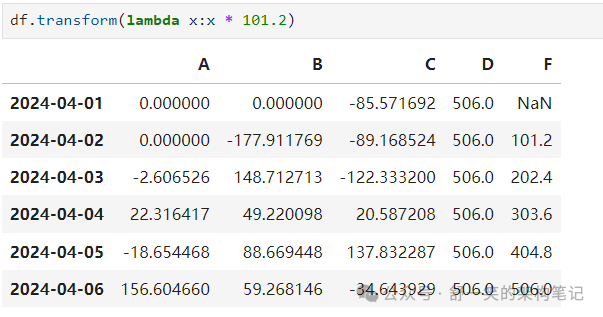
User defined functions用户定义的函数
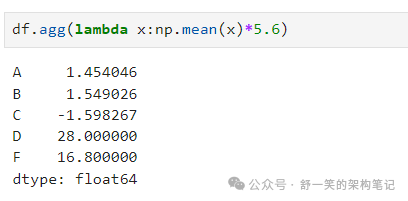
DataFrame.agg() 和 DataFrame.transform() 应用用户定义的函数 分别减少或广播其结果。平均值乘以5.6
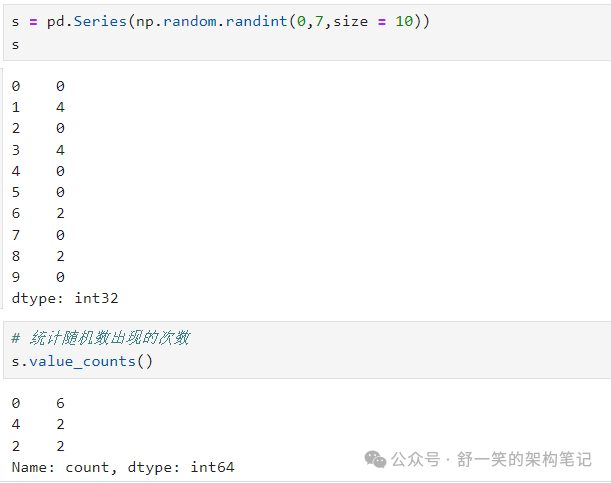
Value Counts价值计数
String 方法
Series在'str'中配备了一套字符串处理方法 属性,以便于对数组的每个元素进行操作,如 下面的代码片段。在矢量化字符串方法中查看更多信息

Merge合并
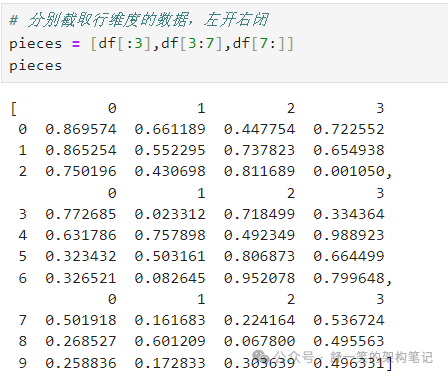
使用concat()按行连接pandas对象:
向DataFrame中添加列的速度相对较快。 一行需要一个副本,并且可能是昂贵的。我们建议传递一个 而是将预先构建的记录列表添加到DataFrame构造函数中 通过迭代地向其添加记录来构建DataFrame。 在这里插入图片描述 在这里插入图片描述
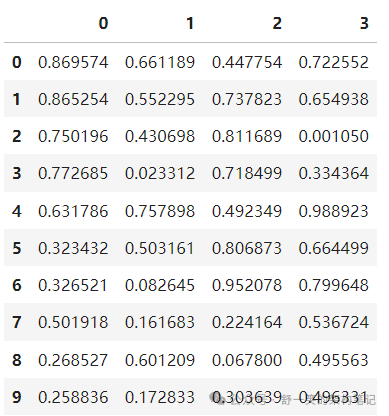
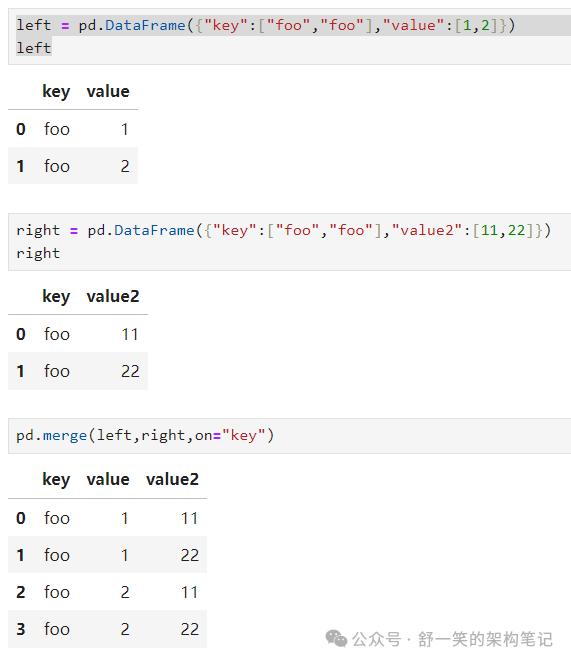
Join加入
merge()在特定列上启用SQL样式连接类型沿着。请参阅数据库样式连接部分。
Grouping分组
分组的含义 根据某些标准将数据分组 将函数独立地应用于每个组 将结果合并到数据结构中
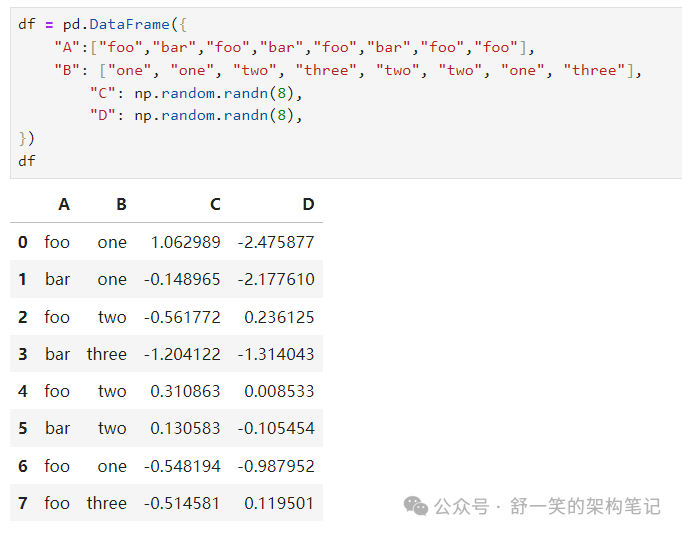
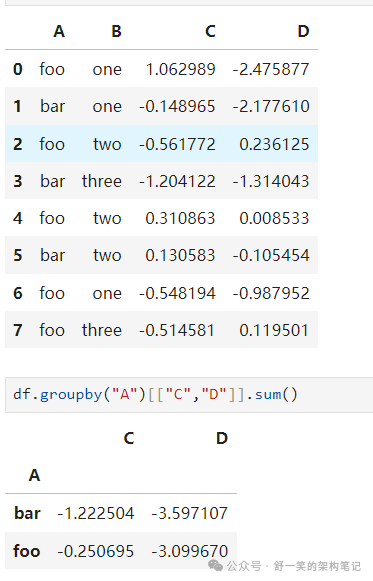
按列标签分组,选择列标签,然后应用 DataFrameGroupBy.sum() 函数到结果 团体:
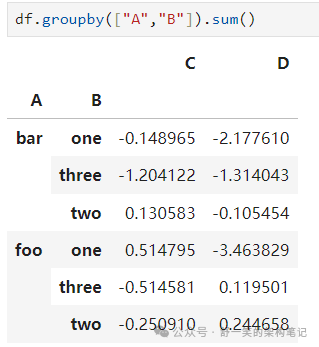
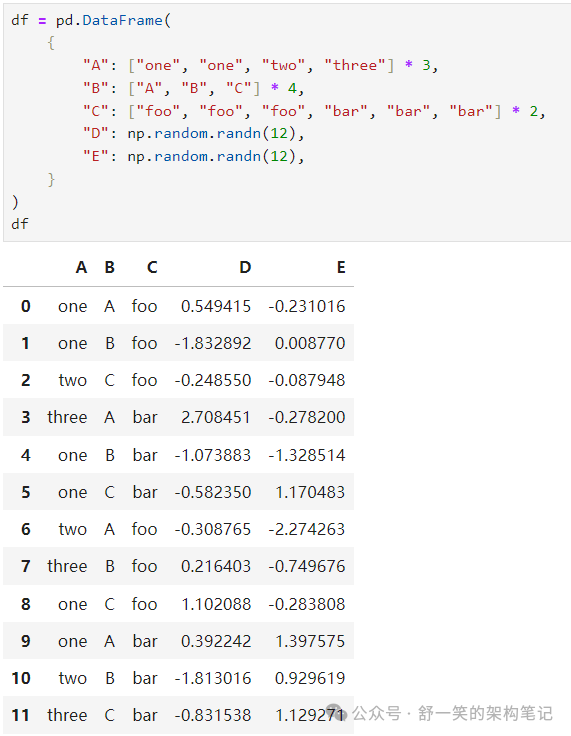
按多列标签分组形成MultiIndex.:
Reshaping重塑
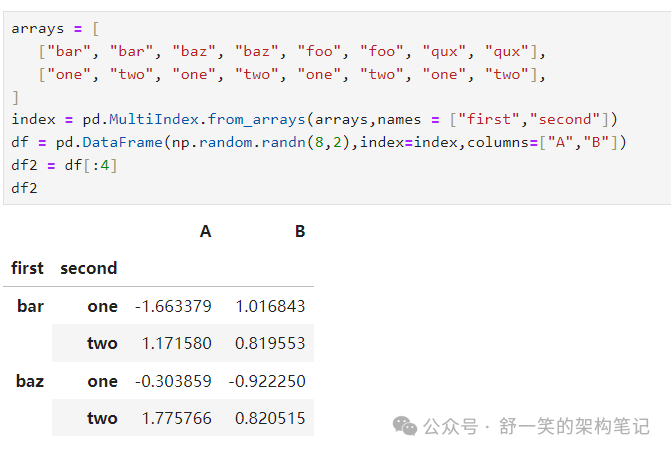
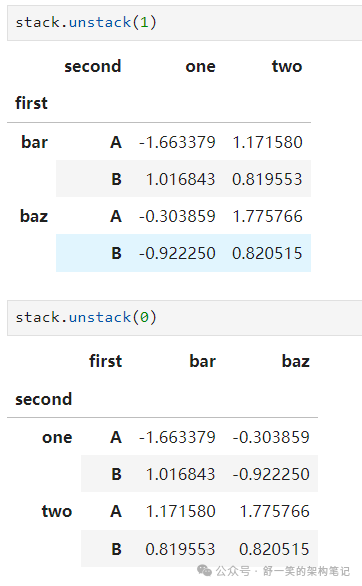
stack() 方法“压缩”DataFrame 中的一个级别 列:
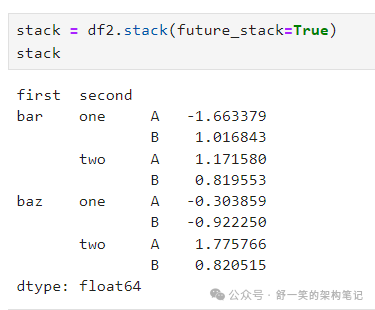
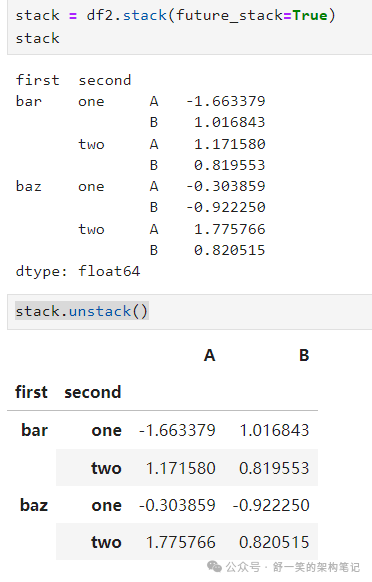
使用“堆叠”的 DataFrame 或 Series(使用 MultiIndex 作为
index
), stack() 的逆操作是 unstack(),默认情况下取消最后一层的堆叠:
Pivot tables数据透视表
ivot_table() 对指定“values”index“和”columns“的 DataFrame 进行透视

Time series时间序列
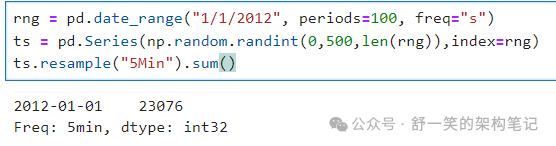
pandas 具有简单、强大、高效的执行功能 频率转换期间的重采样操作(例如,二次转换 数据转换为 5 分钟数据)。这在但不限于以下情况中极为常见: 金融应用。 **这段代码使用了Python的Pandas库和NumPy库来处理时间序列数据。下面是代码的逐行解释:
1.rng = pd.date_range("1/1/2012", periods=100, freq="s")
:这一行创建了一个日期范围(rng
),这个日期范围从2012年1月1日开始,总共包含100个时间点,每个时间点之间的间隔是1秒(由freq="s"
指定)。2.ts = pd.Series(np.random.randint(0,500,len(rng)),index=rng)
:这一行创建了一个Pandas的Series
对象(ts
),它的数据是通过np.random.randint(0,500,len(rng))
生成的,这个函数从0到499(包含0和499)中随机选择整数,数量与rng
的长度相同,即100个。这些随机整数作为Series
的值,而rng
(即之前创建的日期范围)作为Series
的索引。3.ts.resample("5Min").sum()
:这一行是对ts
进行重新采样(resample),并对每个采样区间的数据求和。"5Min"
指定了采样频率,即每5分钟为一个采样区间。由于原始数据每秒有一个数据点,重新采样后,每个5分钟的区间内的数据点会被求和。在这个例子中,因为原始数据只覆盖了100秒,所以实际上只有一个5分钟的采样区间,且这个区间内包含所有的数据点。因此,最终结果将是这100个随机整数的总和。
输出结果将是一个Pandas的Series
对象,其索引是重新采样的时间区间(在这个例子中,只有一个时间区间,即从2012年1月1日 00:00:00开始的第一个5分钟区间),值是该时间区间内所有数据点的总和。
简而言之,这段代码生成了一个以秒为间隔的100个随机整数的时间序列,然后将这个时间序列的数据点按每5分钟一个区间进行分组,并计算每个区间内数据点的总和。由于只有100秒的数据,实际上只有一个区间,所以输出结果将是这100个随机数的总和。**
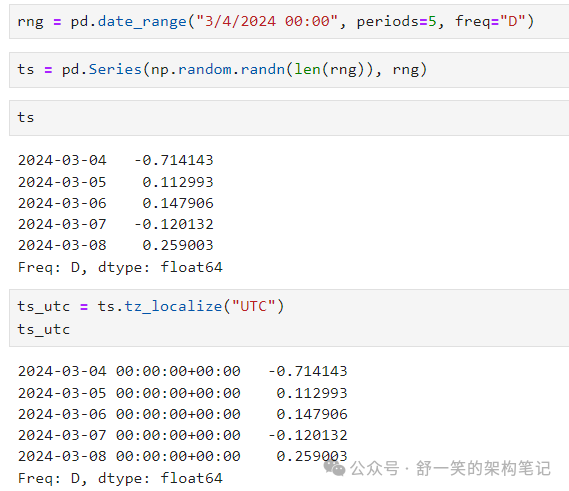
Series.tz_localize() 将时间序列本地化到时区
Series.tz_convert() 将时区感知时间序列转换为另一个时区:

向时间序列添加非固定持续时间(BusinessDay): pd.offsets.BusinessDay(5) 的含义是表示一个时间偏移量,用于将一个特定的日期向前或向后移动 5 个工作日。这里的“工作日”通常指的是周一到周五,不包括周末和公共假日。
在这里插入图片描述

Categoricals分类

将原始成绩转换为分类数据类型:
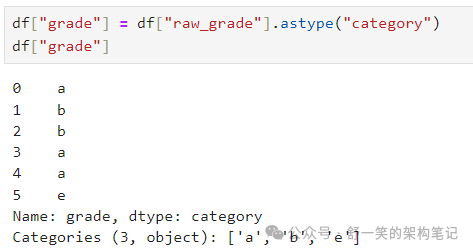
将类别重命名为更有意义的名称:
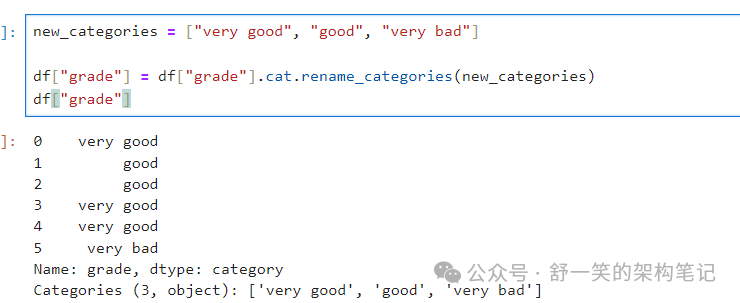
对类别重新排序并同时添加缺失的类别(Series.cat() 下的方法默认返回一个新的 Series):
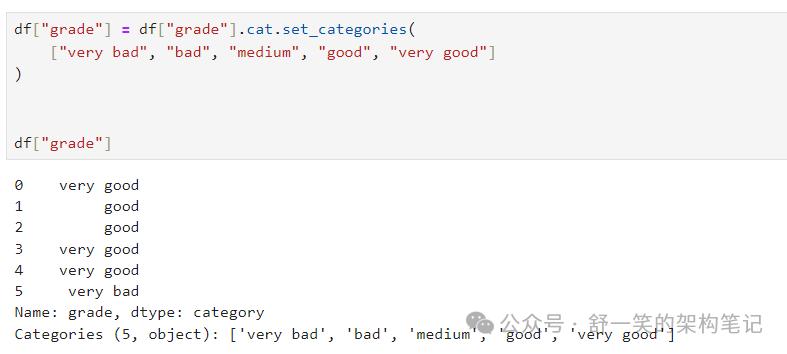
排序是按照类别中的顺序,而不是词汇顺序:
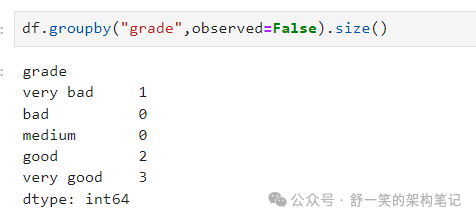
按带有“observed=False”的分类列分组也会显示空类别:
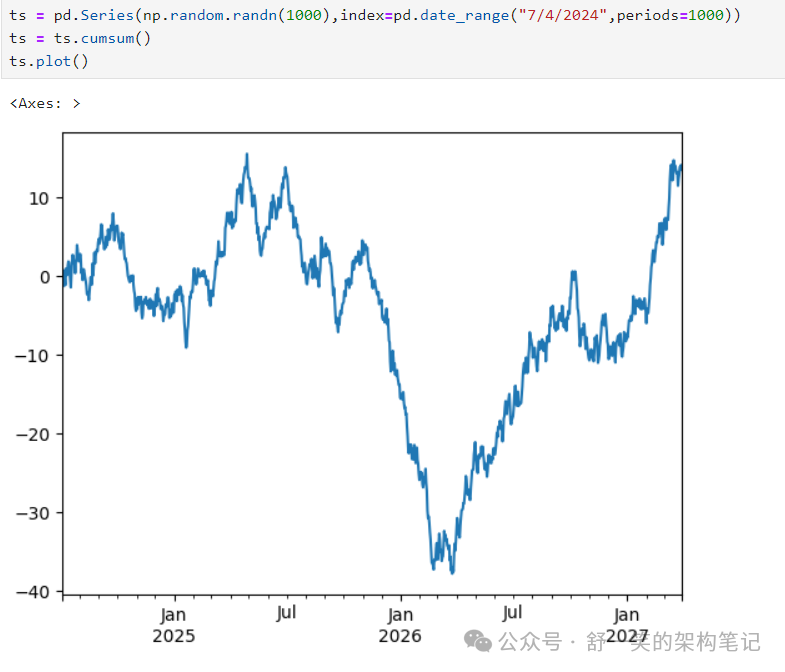
Plotting绘图
我们使用标准约定来引用 matplotlib API:

plt.close
方法用于关闭图形窗口:
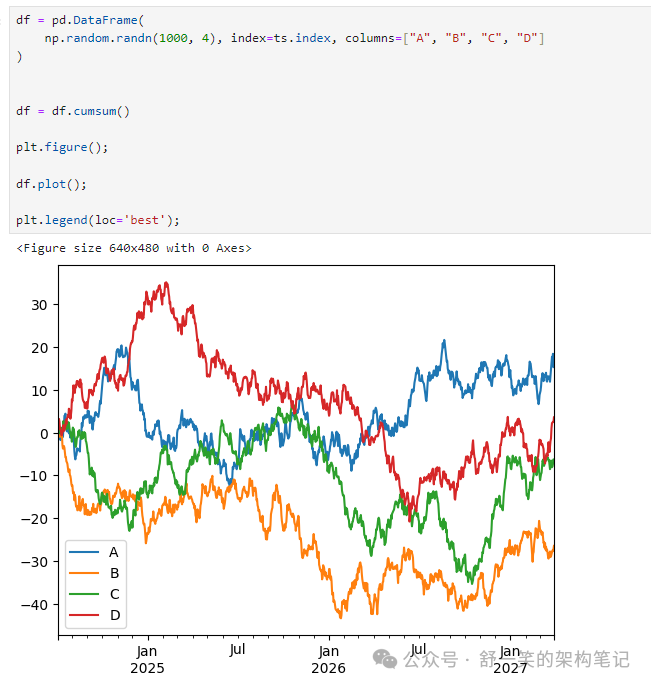
plot() 绘制所有列:
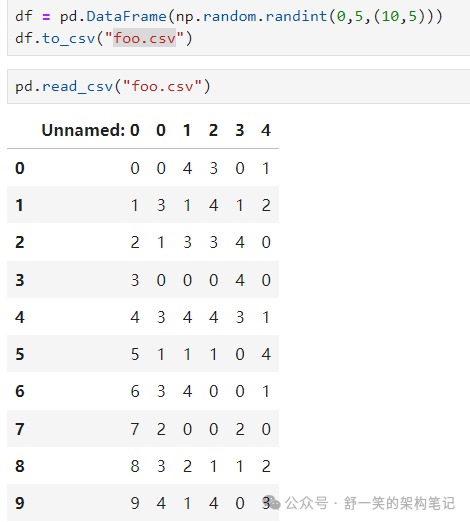
Importing and exporting data 导入和导出数据
写入 csv 文件:使用 DataFrame.to_csv() 从 csv 文件读取:使用 read_csv()
Parquet实木复合地板
写入 Parquet 文件: 使用 read_parquet() 从 Parquet 文件存储读取:
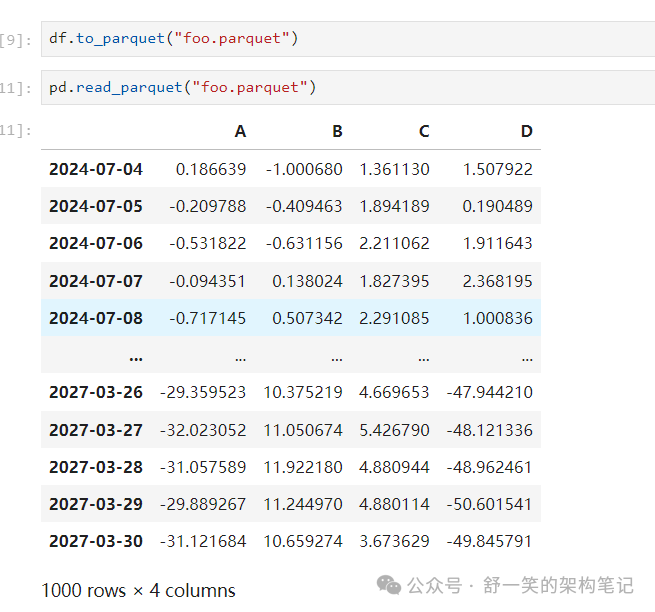
Excel
使用 DataFrame.to_excel() 写入 Excel 文件: 使用 read_excel() 从 Excel 文件读取:
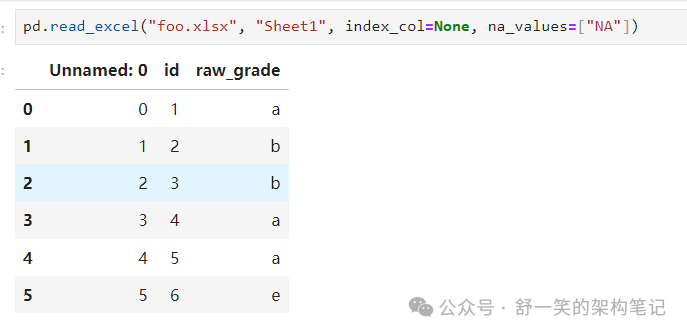
Gotchas陷阱
尝试对 Series 或 DataFrame 执行布尔运算 您可能会看到如下异常:
In [141]: if pd.Series([False, True, False]):.....: print("I was true").....:---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-141-b27eb9c1dfc0> in ?()----> 1 if pd.Series([False, True, False]):2 print("I was true")~/work/pandas/pandas/pandas/core/generic.py in ?(self)1574 @final1575 def __nonzero__(self) -> NoReturn:-> 1576 raise ValueError(1577 f"The truth value of a {type(self).__name__} is ambiguous. "1578 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."1579 )ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
