




【摘要】在postgresql数据库中,表的类型有很多种,传统普通表,堆表,都是以行的方式存储的,以记录为单位存储到数据块中,数据页面是完整的行记录。随着大数据、数仓的高速发展,应用系统出现大量以查询为主的分析型需求,以列为单位进行存储的,每列的所有行数据都存储在一起的,这样的列存表是不是可以提升按列的数据查询需求?列数据的类型一致,是否能获得更大的压缩效率,进而节约大量的存储空间呢?本文是对列存表进行一些探索。
概述
传统关系型数据库是以行的方式来存储数据,随着数据量的剧增,表字段越多,占用的数据空间就越多,数据库查询可能要跨数据块,导致查询速度变慢,带来性能瓶颈。如果打破这种按照行存储的模式,采用一种基于列存储的模式,按列存储每个字段的数据聚集存储,能大大减少读取的数据量,而且由于列数据类型一致、数据特征相似,能更好的采用压缩算法,大幅度节省存储空间。
行存表、列存表介绍
行存表是按照行存储的,维护大量的索引和物化视图,无论是在时间(处理)还是空间(存储)的成本都很高。而列式数据库恰恰相反,列式数据库的数据是按照列存储,每一列单独存放,数据即是索引,只访问查询涉及的列,大大降低了系统I/O。
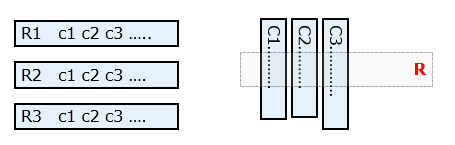
2.1 行存储(Row-based)
对于传统的关系型数据库,一般都是采用行存储(Row-based)行。在基于行式存储的数据库中,数据是按照行数据为基础逻辑存储单元进行存储的,一行中的数据在存储介质中以连续存储形式存在。
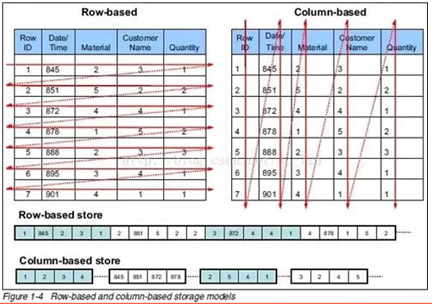
行存储是将数据顺序写入数据块中,持续写入的情况下,组成一行的所有列被连续地存储在磁盘上,一条完整记录可能在同一数据块中命中,这样IO开销相对小,执行速度快。 如果在查询少量字段时,这样会访问整条记录的数据块,会造成一定的IO浪费。没有索引的查询会使用大量IO,建立索引和物化视图需要花费大量时间和资源。
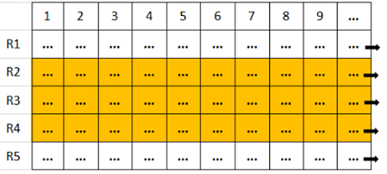
2.2 列存储(Column-based)
在基于列式存储的数据库中,数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。
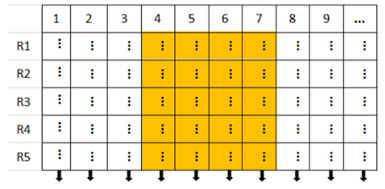
列存储是把每一列存在一起,都会创建一个单独的文件,数据即是索引,只访问查询涉及到列,大量降低系统IO,不必像行存储一样从磁盘上检索没有被应用到的列。由于列数据类型一致、数据特征相似,能更好的采用压缩算法,高效压缩。
列存储对于写入操作性能较差,每条记录都需要写入到磁盘的不同文件上,当需要查询大量字段时,会造成离散IO较多。由于IO的放大,列存储不适合OLTP的场景,列存储适合一次写入多次读取的数据表。
2.3 建表语法
antdb=# \h create table Command: CREATE TABLE Description: define a new table Syntax: CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name ( [ { column_name data_type [ COLLATE collation ] [ column_constraint [ ... ] ] | table_constraint | LIKE source_table [ like_option ... ] } [, ... ] ] ) [ INHERITS ( parent_table [, ... ] ) ] [ PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ] [ USING method ] [ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace_name ] [ DISTRIBUTE BY { REPLICATION | RANDOM | { [HASH | MODULO ] ( column_name ) } } ] [ TO { GROUP groupname | NODE ( nodename [, ... ] ) } ] CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name OF type_name [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] [ PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ] [ USING method ] [ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace_name ] CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] { FOR VALUES partition_bound_spec | DEFAULT } [ PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ] [ USING method ] [ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace_name ] [ DISTRIBUTE BY { REPLICATION | RANDOM | { [HASH | MODULO ] ( column_name ) } } ] [ TO { GROUP groupname | NODE ( nodename [, ... ] ) } ] |
Where storage_parameter [参考GP的语法]:
APPENDONLY={TRUE|FALSE} BLOCKSIZE={8192-2097152} ORIENTATION={COLUMN|ROW} CHECKSUM={TRUE|FALSE} COMPRESSTYPE={ZLIB|QUICKLZ|RLE_TYPE|NONE} COMPRESSLEVEL={0-9} FILLFACTOR={10-100} |
2.4 压缩技术
数据库压缩数据的初衷是出于最小化存储空间,cpu消耗和压缩速度是选择压缩技术的重要考虑因素。压缩数据不一定会带来性能的下降,压缩表将消耗CPU资源,但是减少I/O资源占用。针对不再更新的历史表,备份表,归档表,建议使用压缩存储,释放存储空间。
数据库基于行级别和列级别对数据进行压缩时,行存表、列存表有如下压缩算法选择:
行存表:能够选择zlib和quicklz算法,zlib有1-9个压缩级别,级别越高压缩比越高。
列存表:能够选择zlib和quicklz以及rle_type算法,rle_type是GP 4.2.1以后版本新推出的称为运行长度编码的算法,适合于有大量重复的数据记录。
quicklz一般比zlib更少的消耗cpu,更快的压缩速度;在zlib压缩级别1的状况之下,二者一般具备相同的压缩比,在级别大于6的状况下,会有更加显著的压缩比。
曾经在电信运营商某基地,对基地的经分系统的生产数据,用对CPU开销较小的quicklz方式可以达到4.5:1的数据压缩率。

2.5 选择行存、列存表应用场景
在create table时选择行存或列存时,选择行存,还是列存?尤其重要。从一般角度说,行存具有更广泛的适用性,列存对于一些特定的业务场景可以节省大量I/O资源以提升性能,也可以提供更好的压缩效果,但是目前的列存技术很容易导致文件数膨胀, 后果更为严重。建议根据业务应用场景进行确切评估测试。
行存的适合场景
- 查询中涉及到多列,在select列表或where条件中经常涉及很多字段,选择行存表。
- 适合数据频繁插入更新的场景,采用INSERT方式的实时写入,当行存表建有B-Tree索引时,具备更好的查询数据检索性能。
- 行存储适合非常典型的OLTP应用场景。
列存的适合场景
- 查询中只访问列的一个小集合,列存表对于大数据量的单字段聚合查询表现更好。
- 定期更新单个列,不修改行中其他列的表。
- 采用压缩技术,节约存储空间。
- 列存储适合非常典型的OLAP应用场景,按列做较大范围的聚合分析,或者JOIN分析。
3. 案例分析:列存表并发更新时的锁等待
3.1 案例背景
在电信运营商某基地,经分系统数据库某一列存表在并发update操作时报错。列存表在事务执行update操作时,会申请行级锁,在申请行级锁之前会申请transactionid锁,等待超时后报错信息为:waiting for ShareLock on transaction xxx after ..ms。
3.2 问题分析
列存储是为压缩单元为最小单位的,在导入数据生成后数据是固定不可更改的,同一列的压缩单元是连续存储在一个文件中,当大于文件阀值后,会切换到新文件中,其中的ctid字段标识列存表的一行,代表了数据行在表中的物理位置,由一对数值组成(块编号和offset),一次性写入的多条的数据位于同一压缩单元。
数据库为了防止bock中同一个元组被两个事务同时更新,在update操作时都会申请行级锁,行存表是对一行数据申请加锁,而列存表是对一个压缩单元申请加锁。假如列存表在开启事务时,一个事务在update操作后未及时commit或rollback,则会导致其他事务无法去更新同一个压缩单元里数据,出现锁等待的情况,最后会出现等待超时报错。
3.3 场景复现
测试一、创建列存表test_col,进行模拟测试:
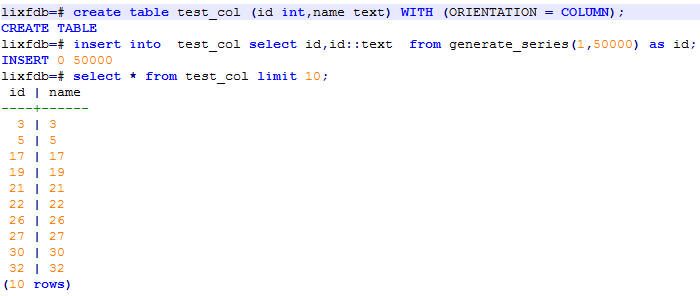
开启事务执行update操作:
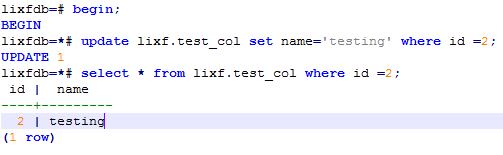
事务未提交并发更新数据出现等待:
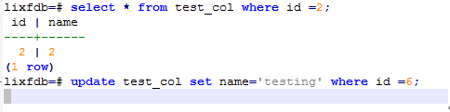
查询后发现两条数据位于同一压缩单元:

测试发现UPDATE的数据在同一压缩单元,出现锁等待的情况,最后会出现等待超时报错,符合预期。
测试二、UPDATA操作后,再模拟测试
数据分布压缩单元:

再次开启事务执行update操作:

事务未提交并发更新数据正常:
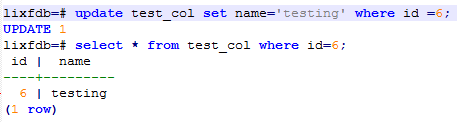
经测试发现,在update操作后,旧元组被标记为deleted,新元组会写到新的压缩单元后,就不存在这种锁冲突。
测试三、创建行存表test_col,进行模拟测试
开启事务执行update操作:
事务未提交并发更新数据正常:
经测试发现,行存表test_col,事务未提交并发更新数据正常。
3.4 小结
列存表不适合高频次update操作应用场景,频繁的update操作容易触发并发更新等锁超时,会造成压缩单元数量猛增,从而导致磁盘空间迅速膨胀,最终带来性能问题。有高频update操作的应用场景,建议使用行存表。
4. 探索总结
列存储技术是一把双刃剑,在OLAP场景中做大范围的聚合、JOIN展示高性能,但在高并发更新或删除操作时出现瓶颈,所以在选择列存表时,根据当前业务应用场景,进行评估性能测试显得格外重要。
随着数据库并行执行发展,丰富的聚合函数,窗口函数等,很好支持OLAP的处理能力。如果能在数据存储组织形式上支持列存技术,势必会给OLAP的能力带来更大的飞跃,以更好的适配OLTP、OLAP混合业务场景。
