




评估数据仓库模型的复用性是个非常实际且重要的问题,它直接关系到数仓建设的效率、成本、灵活性和长期可维护性。一个高复用性的模型能显著减少重复开发、提升数据一致性、加速分析交付。
🧩一、核心评价指标
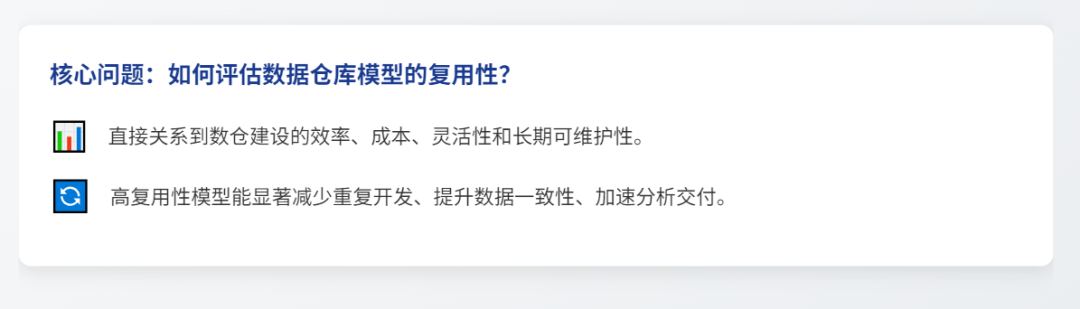
下游依赖数量:
定义: 直接引用该模型作为数据源的下游对象(报表、仪表盘、数据集市、其他ETL任务/模型、即席查询模板等)的总数量。
意义: 最直接、最核心的指标,数值越高通常表示复用性越强。反映了模型被实际“消费”的广度。
评价方法:
利用数据血缘工具自动追踪并统计所有直接依赖该模型的下游对象。审查ETL调度配置、BI工具数据源配置、SQL脚本引用记录(如果工具支持日志分析)。定期进行人工审计或问卷调查(作为补充,尤其在血缘工具不完善时)。
跨业务域/团队使用比例:
定义: 使用该模型的下游对象所属的不同业务领域(如销售、市场、财务、供应链)或不同团队的数量,占所有使用该模型的下游对象涉及的总业务域/团队数的比例(或直接统计绝对数量)。
意义: 衡量模型通用性和跨领域价值。复用性高的模型通常服务于多个独立的需求方。绝对数量或比例越高越好。
评价方法:
在统计“下游依赖数量”的基础上,对下游对象打标签(标注其所属的业务域或团队)。计算:依赖数据血缘工具的元数据管理功能或人工分类。涉及的独立业务域/团队数量涉及的独立业务域/团队数量 / 组织内相关业务域/团队总数 (比例)
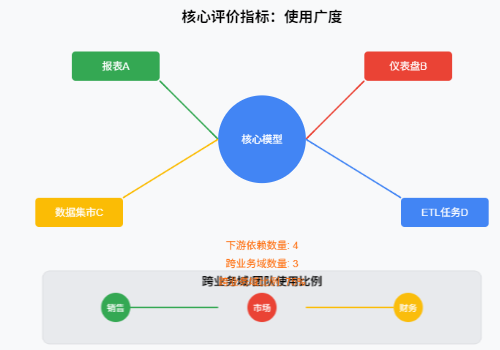
调用频率:
定义: 单位时间内(如每日、每周、每月)下游对象访问(查询或读取)该模型的次数或扫描的数据量。
意义: 反映模型的活跃度和实际价值。高频访问通常意味着高复用性和核心地位。但需注意,单一高频访问可能掩盖广度不足。
评价方法:
分析数据库查询日志或数仓平台的审计日志,按模型表名/ID进行聚合统计。利用ETL调度工具的执行日志统计依赖该模型的作业运行次数。利用BI工具的访问日志(如果能关联到数据源)。
关键下游依赖占比:
定义: 依赖该模型的下游对象中,被组织定义为“关键”(如核心KPI报表、重要决策支持仪表盘、营收相关应用)的数量,占该模型所有下游依赖总数的比例。
意义: 衡量模型支撑核心业务的能力。复用性不仅在于数量,更在于质量。占比越高,说明模型的基础性和重要性越强。
评价方法:
建立下游对象关键性分级标准(如核心、重要、一般、临时)。在统计“下游依赖数量”的基础上,标注每个下游对象的关键性等级。计算:关键下游依赖数量 / 总下游依赖数量
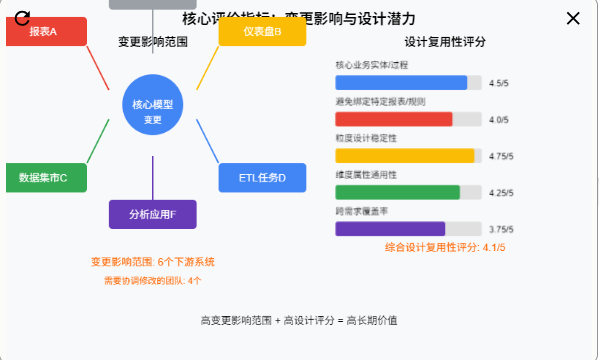
变更影响范围:
定义: 对该模型进行结构变更(如增删改字段、修改数据类型)或逻辑变更(如过滤条件、计算逻辑)时,需要同步通知或协调修改的下游依赖方数量。
意义:逆向指标。复用性高的模型,其变更影响范围必然很大。该指标数值越高,说明复用性越强(但也意味着变更风险越高,需要更严格的变更管理)。
评价方法:
在模型变更流程中,强制进行下游影响分析(利用血缘工具)。记录每次模型变更实际通知或需要协调的下游团队/应用数量。计算历史平均值或跟踪趋势。
设计复用性评分:
定义: 基于模型设计的特性(抽象程度、通用性、稳定性)对其潜在复用能力进行前瞻性评分(例如:1-5分)。
意义: 在模型上线初期或设计阶段,预估其未来的复用潜力。可作为“实际复用指标”的补充或先导指标。
评价方法:
专家评审会: 由数据架构师、资深建模师根据以下方面评分:跨需求覆盖率: 统计模型设计时预期满足的初始需求数量 vs. 这些需求所属的不同业务场景数量。比例越高,潜在复用性越好。模型是否描述核心业务实体/过程(是:高分;否:低分)。模型是否避免绑定特定报表或临时规则(是:高分;否:低分)。粒度设计是否稳定且适合多种汇总需求(是:高分;否:低分)。维度属性是否通用、描述性强、非场景专有(是:高分;否:低分)。

🔄二、评价方法与实施建议
数据血缘工具是基石: 上述指标(1, 2, 4, 5)的核心数据获取高度依赖强大的元数据管理和数据血缘分析工具。投资此类工具对于客观评估复用性至关重要。
日志分析: 指标(3)需要访问和分析数据库、ETL调度、BI工具的访问日志。
元数据管理: 指标(2, 4, 6)需要完善的元数据(业务域标签、下游对象关键性标签、模型设计文档)支持。
流程嵌入:
将“下游依赖分析”嵌入到模型变更管理流程中(支持指标5)。
将“设计复用性评审”嵌入到模型设计评审流程中(支持指标6)。
定期评估与报告:
为关键核心模型(如公共维度表、核心事实表)定期计算指标1-5(如每季度)。
制作复用性仪表盘,展示核心模型的各项复用指标及其变化趋势。
综合解读:
一个模型依赖数多(指标1高)但全在同一业务域(指标2低),其跨域复用性有限。
一个模型调用频率高(指标3高)但关键下游占比低(指标4低),可能主要用于临时查询。
设计复用性评分高(指标6)但实际依赖数低(指标1低),说明推广或易用性可能存在问题。
不要孤立看待单一指标。 例如:
关注趋势: 指标随时间的变化(如依赖数增长、跨域团队增加)比单次绝对值更能说明复用性的提升或下降。

⚖ 三、 平衡与权衡
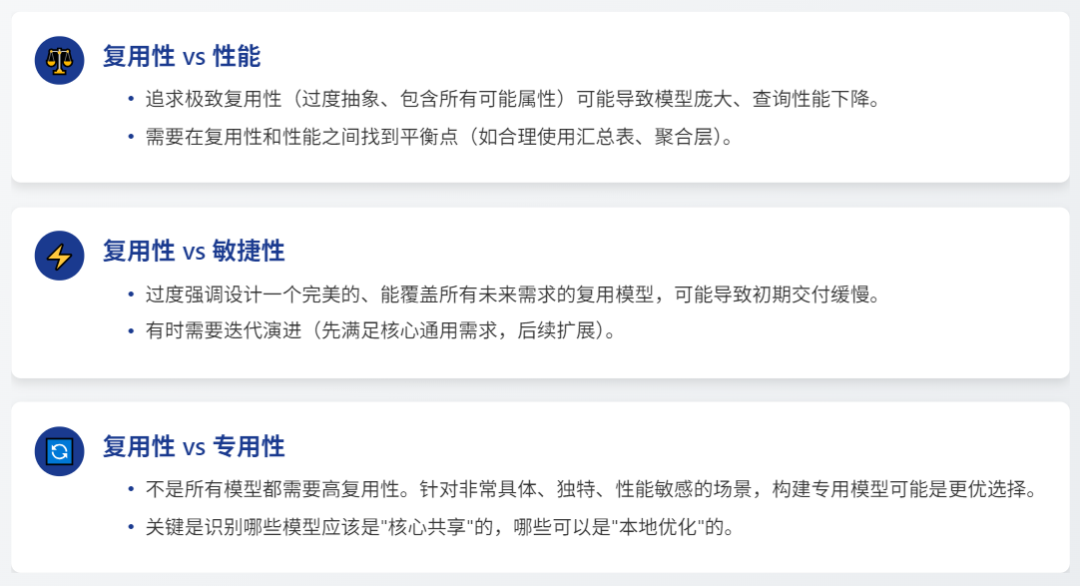
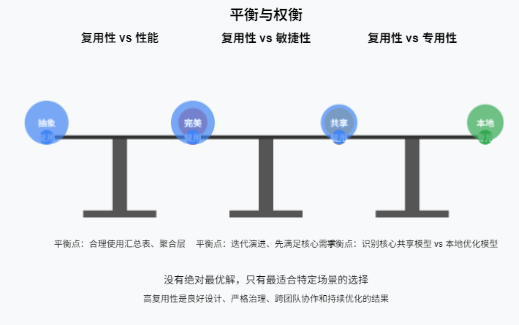
复用性 vs 性能: 追求极致复用性(过度抽象、包含所有可能属性)可能导致模型庞大、查询性能下降。需要在复用性和性能之间找到平衡点(如合理使用汇总表、聚合层)。
复用性 vs 敏捷性: 过度强调设计一个完美的、能覆盖所有未来需求的复用模型,可能导致初期交付缓慢。有时需要迭代演进(先满足核心通用需求,后续扩展)。
复用性 vs 专用性: 不是所有模型都需要高复用性。针对非常具体、独特、性能敏感的场景,构建专用模型可能是更优选择。关键是识别哪些模型应该是“核心共享”的,哪些可以是“本地优化”的
📌四、总结关键指标
| 指标类型 | 核心指标 | 核心评价方法 |
|---|---|---|
| 实际使用广度 | 1. 下游依赖数量 | 数据血缘分析、日志分析、审计 |
| 2. 跨业务域/团队使用比例/数量 | 血缘分析 + 元数据(业务域标签) | |
| 实际使用深度 | 3. 调用频率 | 数据库/ETL/BI 访问日志分析 |
| 4. 关键下游依赖占比 | 血缘分析 + 元数据(关键性标签) | |
| 变更影响 | 5. 变更影响范围(需通知下游数量) | 变更流程中的下游影响分析记录 |
| 设计潜力 | 6. 设计复用性评分 | 专家评审会(基于设计文档/标准) |
通过持续跟踪和分析这些指标,数据团队可以清晰量化数仓模型的复用价值,识别高价值核心资产,定位复用性不足的瓶颈,并有效指导模型的优化、重构和推广决策。记住,高复用性不是偶然发生的,它是良好设计、严格治理、跨团队协作和持续优化的结果。💡


