




前言
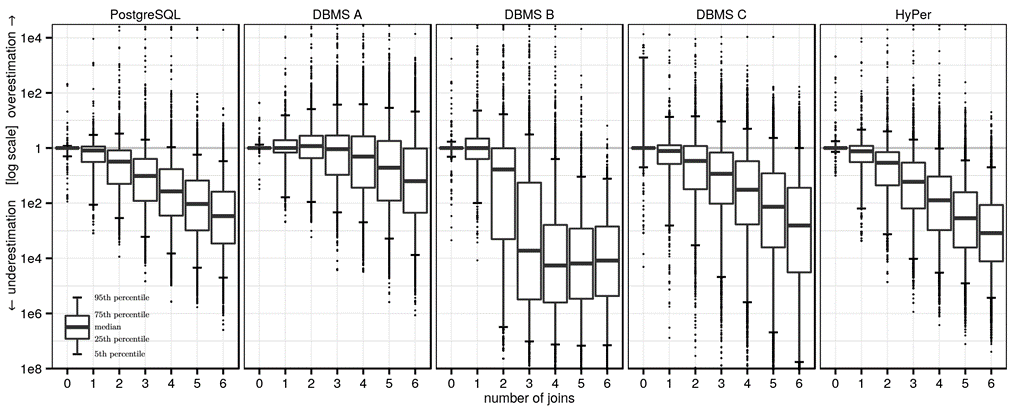
查询优化是数据库系统中的核心问题。给定一个SQL查询,传统的基于代价的优化器(Cost-Based Optimizer, CBO)枚举所有可能的执行计划,并利用代价估计模型估计不同执行计划的代价,从中选出代价最小的计划,交给执行器执行。然而,在庞杂的计划空间中估计每个执行计划的代价绝非易事,传统方法往往产生巨大的误差,进而导致次优甚至灾难的计划被执行。Viktor Leis 等人的实验研究 [1] 表明,随着查询中连接数的增加,传统的基数估计算法的误差逐渐增大,甚至有若干数量级的误差(如下图)。在最受欢迎的开源数据库 PostgreSQL 和其他商业数据库都有类似的表现,准确估计执行代价并选出较好的执行计划对传统 CBO 是一项挑战。
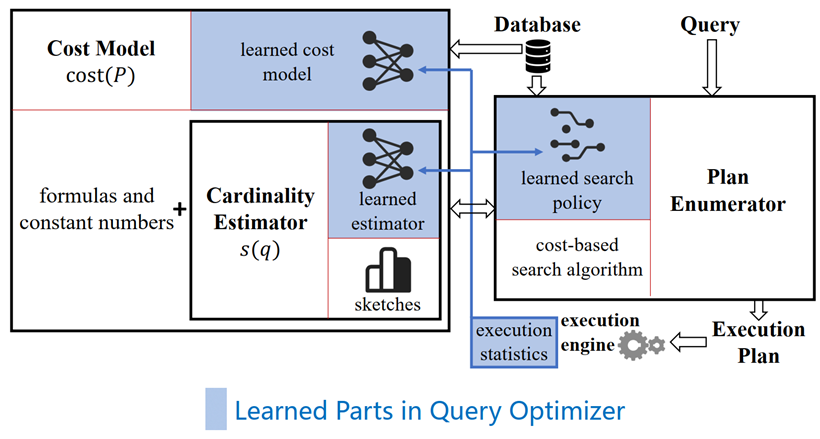
如今,随着人工智能技术的蓬勃发展,研究者们开始考虑用机器学习的技术来帮助解决查询优化问题。现有的研究主要可以划分为如下三个方向,如下图 [2] 所示
学习型基数估计(Learned Cardinality Estimation,LCE):用基于学习的方法代替 CBO 中传统的基数估计模块,来估计中间结果集的大小。 学习型代价模型(Learned Cost Model,LCM):用基于学习的方法来取代 CBO 中手工设计的代价模型,用于估计查询计划的执行代价。 学习型查询优化器(Learned Query Optimizer,LQO):不依赖传统 CBO 的架构,而是利用学习的方法,直接生成一个可执行的计划或部分计划(例如查询提示),再交给数据库执行。
机器学习的技术从一个全新的视角,给古老的查询优化问题提供了新的可能解决方案,在已有研究中初步验证了提升性能的可能性。然而,如此对传统方法的颠覆,能带来多少性能提升,又有多少潜在的问题,仍是研究者们持续关注的问题。本文将从近几年最新的实验论文的研究,自顶向下依次介绍学习型优化器、学习型代价模型和学习型基数估计,来对基于学习的查询优化方法一探究竟。
学习型优化器 (LQO)
LQO 简介
LQO 的基本工作流大致如下:从典型负载中取出查询,生成计划、执行计划,得到一个返回(执行时间),最后根据反馈持续提升自己,通常基于强化学习的方法。目前主流 LQO 有两类变种,
端到端的学习型查询优化器(End-to-End Learned Optimizer):以端到端的方式直接产生物理计划(或连接次序)。 学习型优化器助手(Learned Optimizer Assistant):给定一个查询,学习型优化器助手为传统优化器提供查询提示(Query Hint),来帮助传统优化器生产更好的计划。
下面以端到端的学习型优化器为例,简单进行介绍。其思想是将查询优化问题建模为马尔可夫决策过程(MDP),如下图所示。
状态定义为一个部分计划(Partial Plan,空计划和完整计划也算)P,一个部分计划是一个森林,还未将所有的表连接起来,也有些表的访问模式还没确定(如直接 Scan还是Index Scan等) 状态转移为(1)确定一个表的访问方式(Scan 或 Index)(2)将两个子树通过某物理连接算子Join起来 每一步动作的价值定义为0 终点(完整计划)的价值(回报)定义为该计划在真实引擎上的执行时间(latency)的相反数。
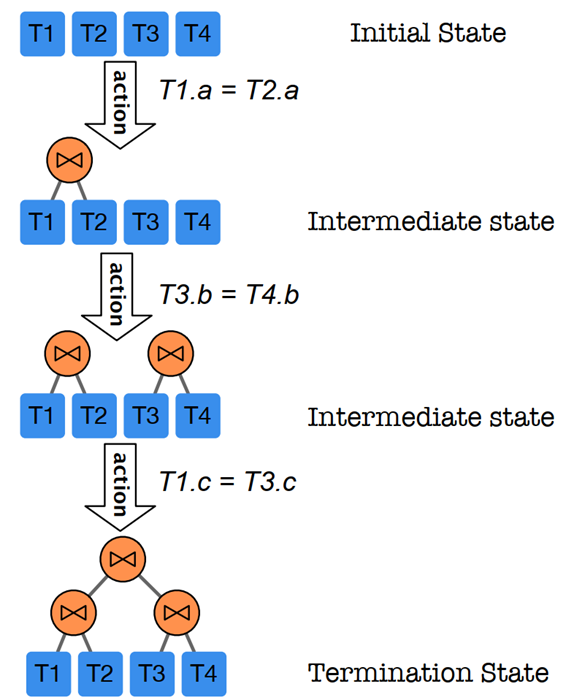
按照这种 MDP 的定义,最有的执行计划对应于 MDP 中奖励最高的路径。因此,我们可以用强化学习的技术来求解 MDP。例如,让神经网络来学习状态值函数或动作值函数。在线生成计划的阶段,可以由价值网络来指导每一步的动作选择。
LQO 实验
下面,将介绍来自苏黎世应用科学大学的 Claude Lehmann 等人对 LQO 的一个实验研究 “Is Your Learned Query Optimizer Behaving As You Expect? A Machine Learning Perspective”[3],发表在 VLDB 2024 。这篇工作首先指出了 LQO 在实验的流程上存在一些问题,违反了机器学习的准则,然后给出了一些建议来改进方法的设计与评估。最终,在尽可能公平的设置下进行实验,比较了五种经典 LQO 的效果,分别是 Neo、Bao、Balsa、HybridQO、LEON。其中,Bao 和 HybridQO 是基于提示的方法,Neo、Balsa 是端到端的学习型方法,LEON 是基于计划代价比较(Learning To Rank,LTR)的方法。接下来,我们重点看实验部分。
实验设置
查询集使用
JOB 的 113 个查询(由33个模板生成) STACK 原有 6191 个查询 (由16个模板生成),作者从中采样了 14 个模板,每个模板 8 个查询,共 112 个查询
训练集/测试集的划分方法:作者考虑了三种划分,对应不同的难度,从低到高依次是 Leave One Out Sampling,Random Sampling,Base Query Sampling。每种划分的训练集测试集比例都是8:2。

实验结果
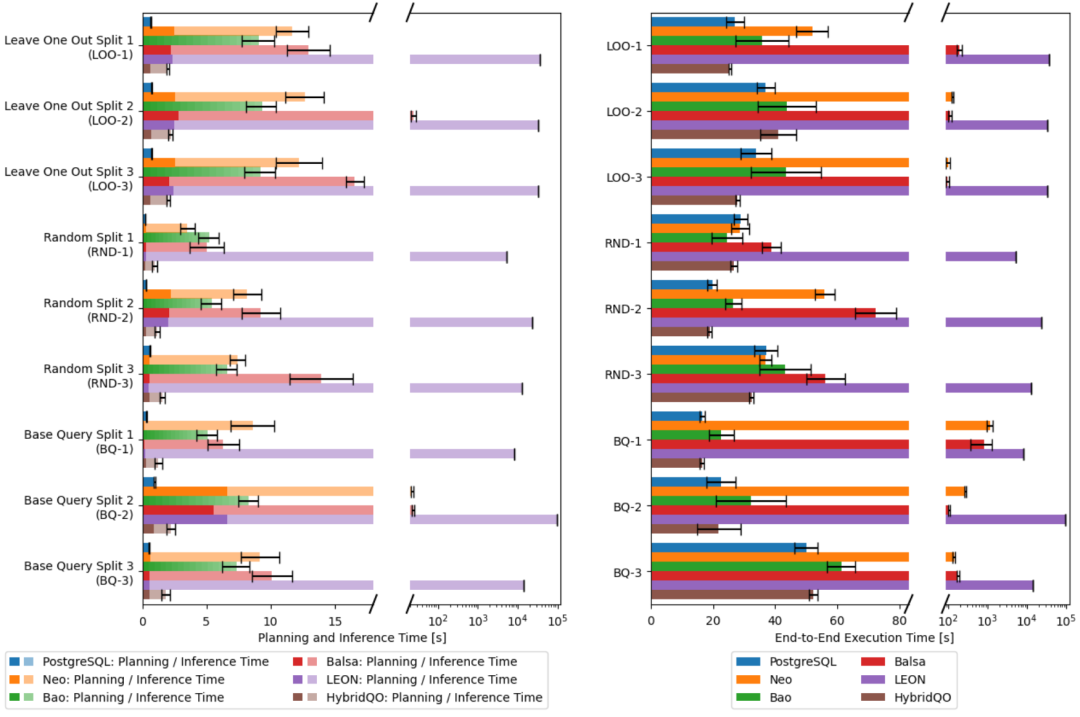
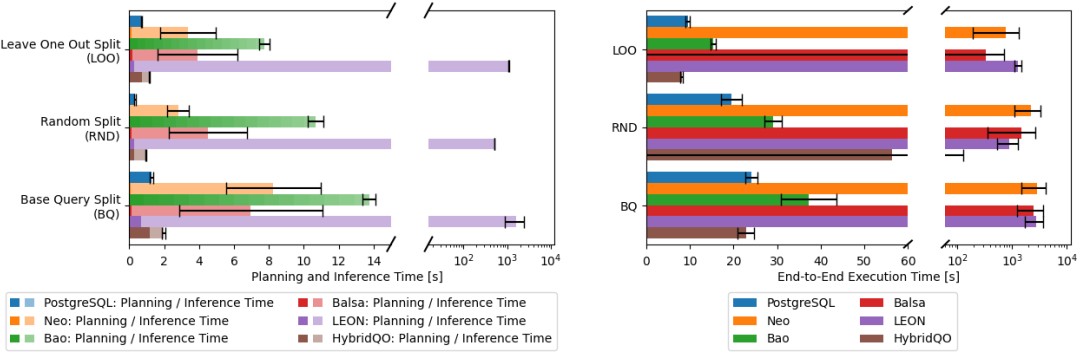
下图是 JOB 数据集上的实验结果,左图为 planning(搜索)和 inference(模型推理)时间,有图为 end-to-end(端到端)时间。从左图看到,LQO 相比于 PostgreSQL,在优化阶段花得时间要多一些。其中,LEON 的时间已经大到不可接受的程度,最坏可能 到 秒。其他方法的时间,在几秒到几十秒不等,HybridQO最短。当我们看到右图的端到端时间时,结果同样令人大跌眼镜,PostgreSQL 几乎持续胜出。基于学习的方法只有HybridQO稍好,能在若干场景下胜出。其次是Bao,能够生成和PostgreSQL质量相当的计划,只不过慢在了推理和规划的时间。
在 STACK 数据集上,实验结果类似,LQO 的端到端时间仍然不如 PostgreSQL。
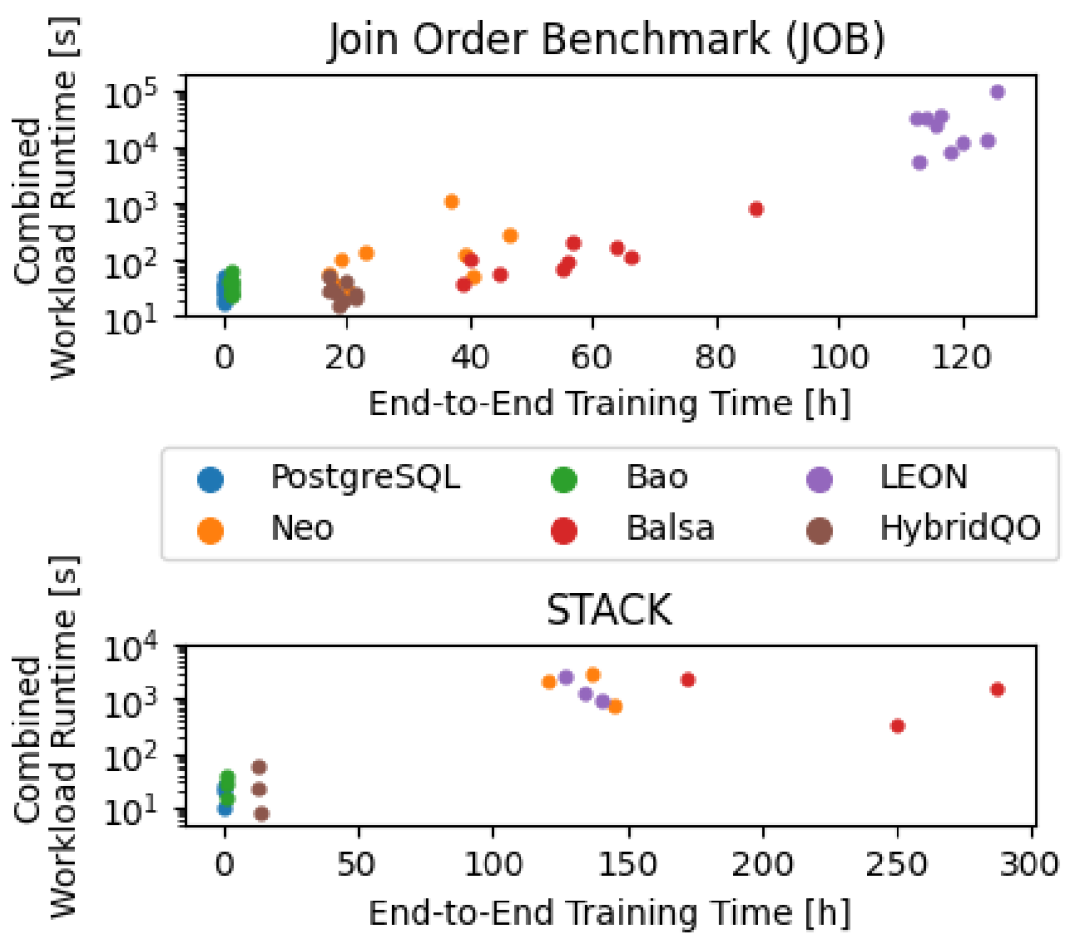
最后,作者汇总了每个实验对应的模型训练时间。我们看到,模型的训练往往需要几十个小时,其中主要的时间是要反复执行查询的各种计划。需要强调的是,两个数据集中训练查询都只有不到 100 个,但却消耗如此之长的时间,而且也没能比过 PostgreSQL。LQO 的数据效率还是太低了,花太长时间才能得到一条训练数据。
小结
学习型优化器想战胜 PostgreSQL 并没有那么容易。在本文的实验中,几乎所有设置下,PostgreSQL 都占优。一方面可能因为本文的训练集有限,不到一百个查询;另一方面,还是 LQO 的训练效率太低了,与数据库交互、执行查询,但花了很长时间只获得了执行时间这一点信息,反馈太稀疏了。
学习型代价模型(LCM)
LCM 简介
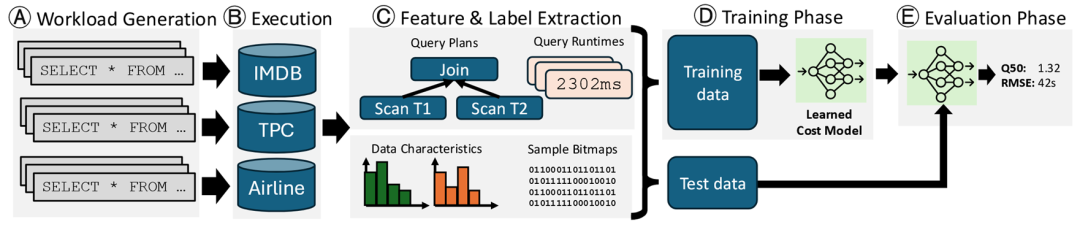
学习型优化器 LQO 并没有取得令人满意的结果,我们把目光转向学习型代价模型(LCM)。代价模型的目的是给定一个查询的执行计划,估计其执行代价。传统的方法是考虑计划的每一步的中间结果的大小,通过人工设计的计算公式,综合考虑 IO 代价、CPU 代价等因素。而基于学习的方法则是将查询计划作为输入特征,用回归模型来预测执行代价。LCM 的经典工作流如下图所示 [4]。
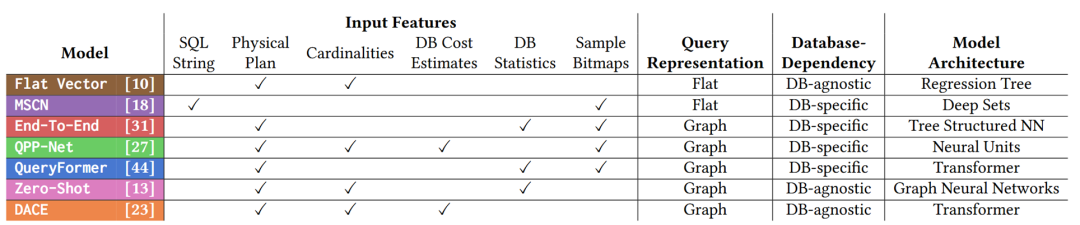
下面,将介绍来自德国达姆施塔特工业大学的 Roman Heinrich 等人的工作“How Good are Learned Cost Models, Really? Insights from Query Optimization Tasks”[4],发表在 SIGMOD 2025。比较了如下 7 个方法。
本工作注意到,现有的对 LCM 的评估只关注了估计的准确性,而没有从考虑 LCM 对查询优化任务的贡献。即,能否得到更好的计划,改善端到端时间。因此,本文从查询优化的角度,对 LCM 进行了系统的实验。面向连接顺序、访问路径选择、物理算子选择三个查询优化的子任务,展开实验,下面依次介绍。
任务 1:连接顺序
实验设置:对于一个查询,令枚举其所有可能的计划,令 LCM 估计代价。
评价指标:
被选计划运行时间 :LCM 所选择的那个计划的执行时间 超越比例 :LCM 所选择的计划超过计划空间中其他计划的比例 排名关联度 :使用 Spearman’s Correlation 估计 LCM 对计划排序与真实计划排序的关联度。 最大高(低)估 :对于给定查询的所有计划,LCM 对其代价的最大高(低)估
下面,从一个例子来看这些指标的含义。如下是 JOB-LIGHT 的第 33 个查询,折线图表示 LCM 对该查询所有后续计划的代价估计,这些计划按照真实运行时间从小到大排序了,黑色折线表示真实时间。好的估计应该是一个单调递增的曲线,但很遗憾,图中的学习型代价模型都没有很好地保持单调,而是剧烈波动。Flat Vector、Zero-Shot、DACE 这三个是数据库无关(DB-agnostic)的方法,它们虽然波动剧烈,但总归有个上升的趋势;其他的学习型方法甚至都没有上升趋势。此外,还有一个观察是,执行时间越短的计划,学习型方法相对来说估计的更准,这一点是因为训练数据有偏斜:收集到的计划都是数据库实际执行的计划——已经被 PostgreSQL 优化器优化过了,这体现了现有的 LCM 训练收集阶段的问题。至于其他评价指标,不管是估计的准度(B)、被选计划运行时间(C)、超越比例(D)、排名关联度(E)、还是最大估计误差(F,G),学习型方法都不如 PostgreSQL。
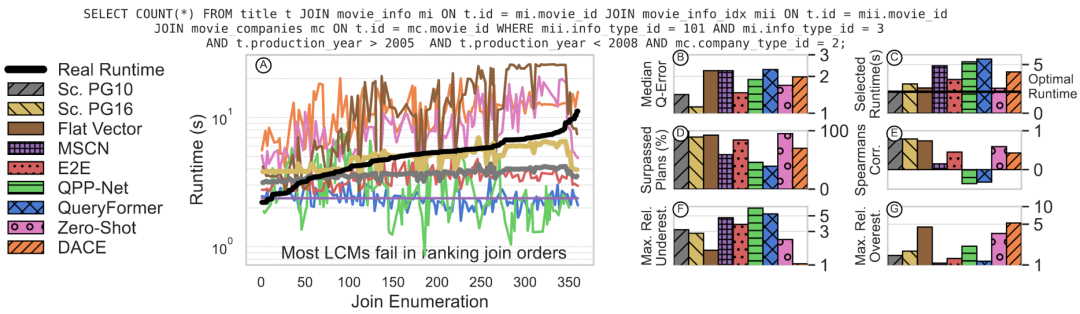
现在,将所有 JOB-LIGHT 上所有查询的实验结果汇总起来。很遗憾,学习型方法败于 PostgreSQL。其中,DB-agnostic 的方法稍好一些。

任务 2:访问路径选择
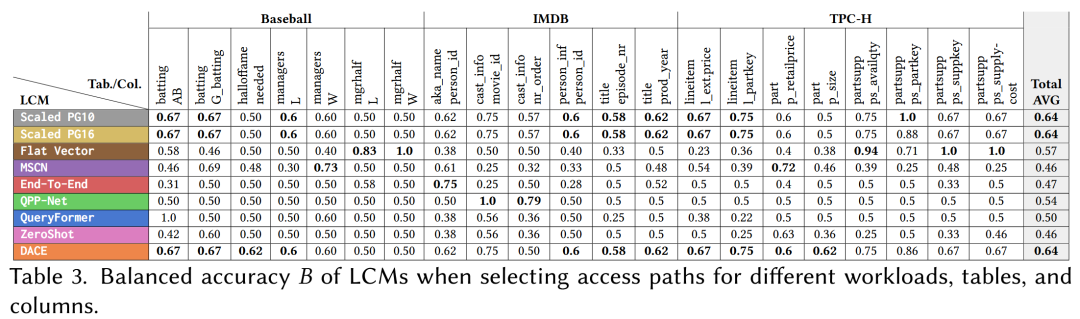
实验设置:给定一个查询,在一个表上有一个选择谓词,需要选择顺序扫描还是索引扫描。
评价指标:这是一个二分类问题,考虑平衡的准确度,为正例准确度与负例准确度的平均值
在 IMDB 数据集上的效果如下图。可以看到,几乎所有的 LCM 都是默认选择索引扫描(Index Scan)。作者分析了训练数据,发现训练数据集中只有10%的索引扫描,这些都是索引扫描真正有益的场景,因此模型盲目任务索引扫描更好,这同样是数据集有偏导致的。
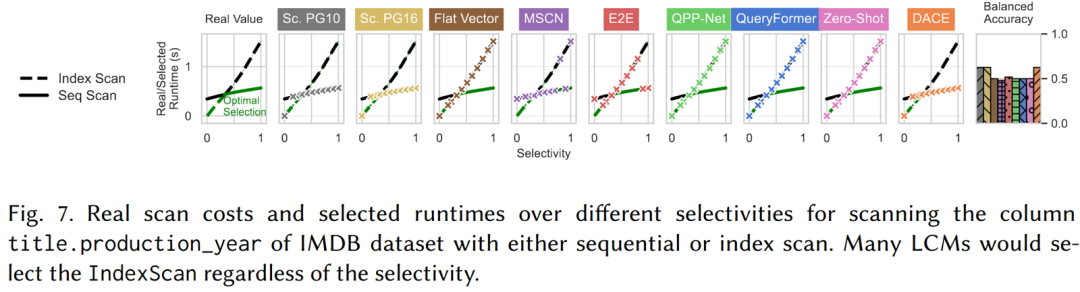
三个数据集上的汇总结果如下。请注意,准确率 < 50% 意味着还不如随即猜测。LCM 在访问路径选择上表现不佳。
任务 3:物理算子选择
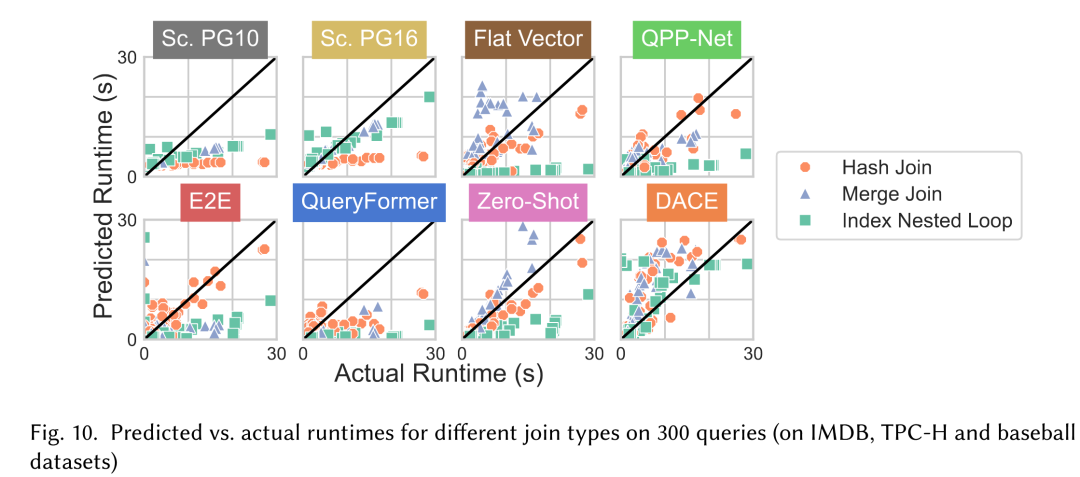
实验设置:连接两个表的查询,让模型选择连接算子的物理实现。
评价指标:选对的概率 ,表示模型选出最佳算子的频率
先看模型对不同算子的执行时间的估计,如下图,数据点靠近斜线意味着估计的准。从图中看出,LCM普遍估计很差,特别是很多都低估了 Index Nested Loop Join 的代价,这同样是因为训练数据集的问题。
最后是汇总的实验结果,也不尽人意。
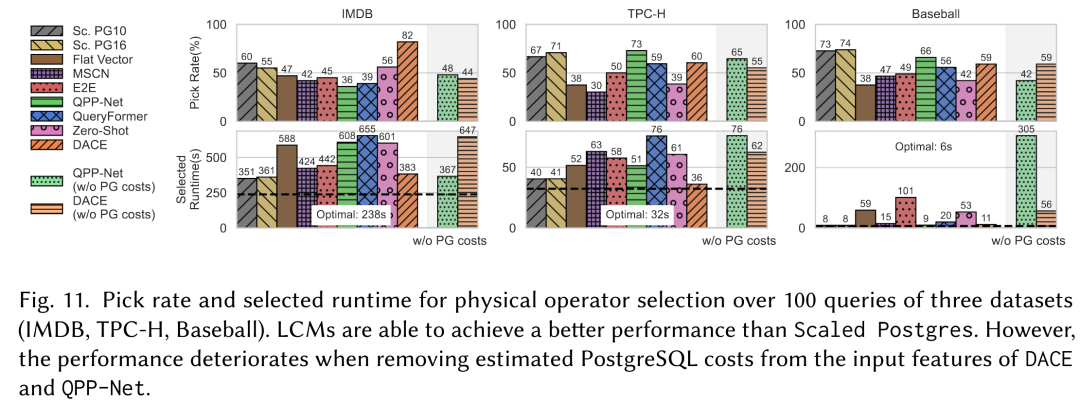
小结
现有的学习型代价模型在预测执行代价任务上,不能战胜 PostgreSQL。主要原因是训练数据是有偏的,数据集中的执行计划都是已经被 PostgreSQL 优化、执行的计划。
学习型基数估计(LCE)
LCE 简介
基数估计任务是在一个查询执行之前预测其基数。现有的学习型基数估计方法主要可以分为如下两大类:
Query-driven:即查询驱动。直接学习查询特征到其基数的映射,i.e. 。通常是一个回归模型,但需要大量的查询及其真实基数作为训练集。 Data-driven:即数据驱动。与查询驱动的思想不同,数据驱动并不直接学习查询的基数,而是学习底层数据的分布,并用这个分布来回答查询的基数。例如,一个具有属性的表 ,可以看作是定义在 上的多元概率分布 ,用机器学习模型来拟合此分布,得到 。之后,原表上的带有选择谓词的查询,可以看作在 上的积分来近似估计基数。
LCE实验
下面介绍 Yuxing Han、Ziniu Wu 等人的实验论文“Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation”,发表在 VLDB 2022。这个工作中,对主流的学习型基数估计方法进行了端到端实验,并证明了在许多场景下,特别是复杂查询下,LCE 是有益的,能减少端到端时间。
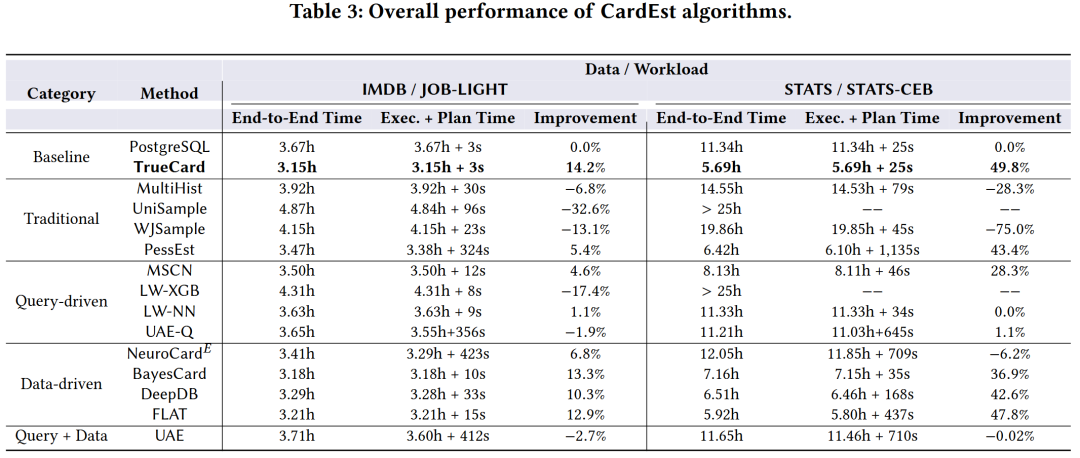
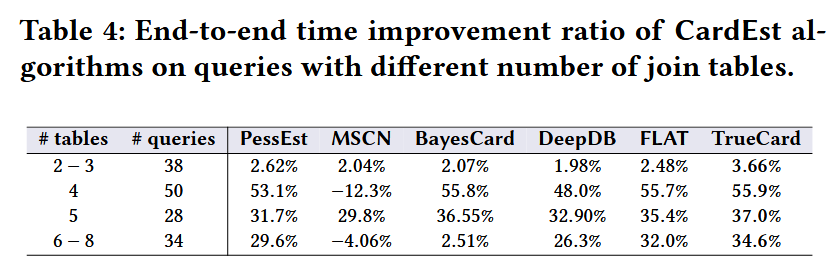
小结
学习型基数估计在端到端时间上能够击败 PostgreSQL,特别是在复杂查询上有优势。然而,在小查询上,PostgreSQL 端到端更快。
总结与展望
基于学习的查询优化方法为传统的查询优化问题提供了新的视角和解决方案。如上的实验研究表明,LQO 和 LCM 很难战胜 PostgreSQL,但 LCE 可以。尽管目前的学习型方法仍然存在着很多局限,但仍然表现出了超越传统方法的潜力。AI与查询优化的进一步融合,往往需要更多的巧思。我们的最终目标是既可用又高效的智能优化器,未来可能的研究方向有
融合 query-driven 方法和 data-driven 方法 预训练模型,提供跨数据库的迁移能力 与大模型结合 考虑实用性,如 OOD 问题、动态更新场景、训练效率、鲁棒性、可解释性等
参考文献
[1] Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter A. Boncz, Alfons Kemper, Thomas Neumann. How Good Are Query Optimizers, Really? VLDB 2015.
[2] Rong Zhu, Lianggui Weng, Bolin Ding, Jingren Zhou. Learned Query Optimizer: What is New and What is Next. SIGMOD 2024 Tutorial.
[3] Claude Lehmann, Pavel Sulimov, Kurt Stockinger. Is Your Learned Query Optimizer Behaving As You Expect? A Machine Learning Perspective. VLDB 2024.
[4] Roman Heinrich, Manisha Luthra, Johannes Wehrstein, Harald Kornmayer, and Carsten Binnig. How Good are Learned Cost Models, Really? Insights from Query Optimization Tasks. SIGMOD 2025.
[5] Yuxing Han, Ziniu Wu, Peizhi Wu, Rong Zhu, Jingyi Yang, Liang Wei Tan, Kai Zeng, Gao Cong, Yanzhao Qin, Andreas Pfadler, Zhengping Qian, Jingren Zhou, Jiangneng Li, Bin Cui. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation. VLDB 2022.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

