




先引用一下去年10月评论P4的一篇文:
P4语言本身由于pipeline的模型限制和命令式编程语法,导致它根本无法进行其它的处理,模块化能力几乎也为零,很多时候pipeline决定了一些模块复用和branch/jmp无法实现。然后到架构选择的时候,总是Pipeline快,RTC慢,Pipeline Recycle性能下降厉害,RTC基于流hash的无法处理elephant flow,单核IPC性能差。如何把数据包编码使得转发模型能够更好适应异构的硬件平台,编码上降低RTC-Pipeline-RTC这样的复杂切换流程,设计一种完备的DSL并且可以同时支持流量的RTC/Pipeline offload,这才是关键。
zartbot.Net,公众号:zartbotSRv6/P4/SDWAN都错了:一些看似离经叛道的苦口良药
也就是我去年说的:
| 如何把数据包编码使得转发模型能够更好适应异构的硬件平台,编码上降低RTC-Pipeline-RTC这样的复杂切换流程,设计一种完备的DSL并且可以同时支持流量的RTC/Pipeline offload,这才是关键 |
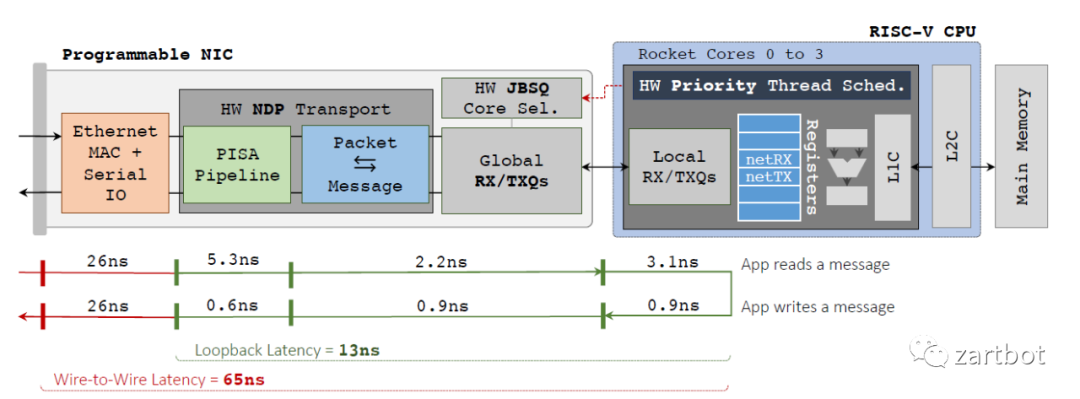
Memory and cache hierarchy on the critical path. The networking stack of a modern CPU uses memory as a workspace to hold and process packets. This inherently leads to interference with applications’ memory accesses, introducing resource contention which causes poor RPC tail latency |
所以在去年初进行下一代处理器架构选型时,我也考虑过这个问题,最终的结论就是第四节所述的随路计算的一些东西。
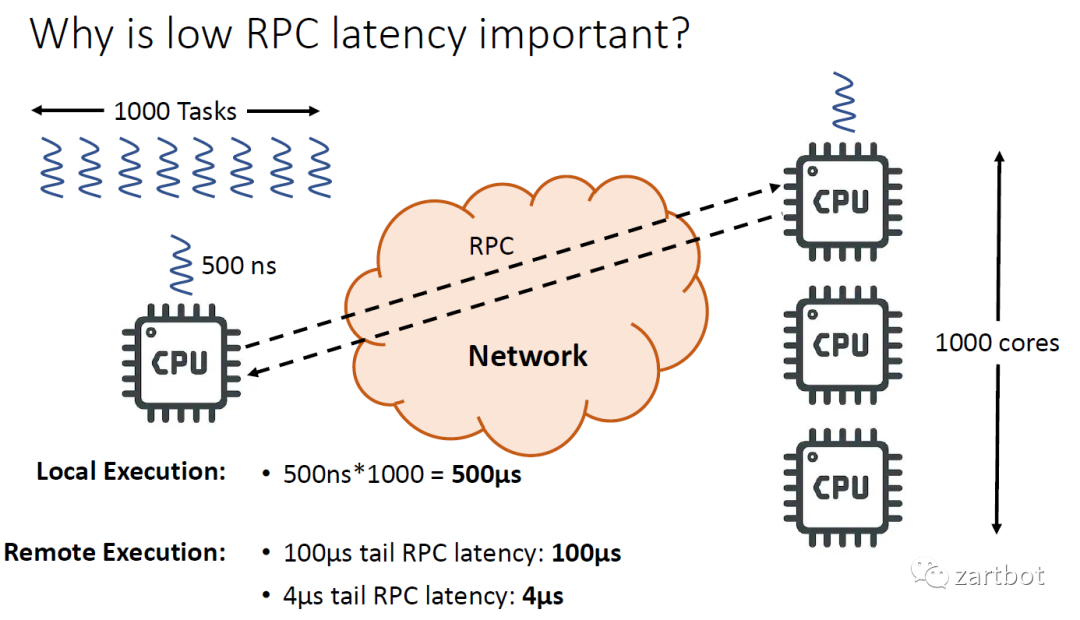
“Sustaining exponential scaling in our computing infrastructure
requires much more predictable, low-latency,
CPU-efficient communication frameworks starting with RPCs,
rather than IP packets.”
Amin Vahdat, 2020
2.冯诺依曼架构的演进

本质上冯诺依曼架构一开始是为标量化的算术和逻辑运算而产生的,指令和数据的鸿沟天然的摆在那里,近代的异构计算或者处理器的AVX指令集等不过都是一些向量、矩阵的计算来降低指令和数据间的鸿沟。
3.内存计算:另一个极端
4.网络计算:不是算力网络的网络算力
当然我们基于FPGA的样机已经做好了,正在进行性能测试,最终会构成一个非常有趣的解决方案可能会在今年某个会议上以论文的形式弄出来。

5.传输层的最佳实践
为了实现3D-Torus拓扑,每台机器需要3张2x100GE网卡,分别连接X+,X-,Y+,Y-,Z+,Z-方向.这些链路可以采用服务器之间网卡直连的方式,当然也可以为了灵活部署全部接在交换机上划分VLAN/VXLAN的方式连接。Ruta会通过链路发现的方式将linkstate和互联拓扑同步到ETCD中,节点的SystemIP编号采用可以采用 10.X.Y.Z方式,这样的目的是可以根据XYZ的值做基于目的地址的路由,Ruta可以根据目的归属的Label或者SystemIP自由选择向dX/dY/dZ方向的方式完成路由。数据包的封装用SRoU实现即可。
zartbot.AI,公众号:zartbotA0001:分布式机器学习的网络优化
