




学习MPI主要参考的是如下这本书:

当然我也会参考一些中科大的文档:
https://scc.ustc.edu.cn/zlsc/cxyy/200910/MPICH/ https://scc.ustc.edu.cn/389/list.htm
简介
分布式计算误区
其实一直吐槽很多做计算的人不懂网络,大概也就是作者所说的如下几种误区:
the network is reliable, the latency is zero, the bandwidth is infinite (or at least large enough), the network is safe, the network topology does not change (meaning it is static over time), there is only one network administrator, the transport cost is free, and the network is homogeneous.
很多时候网络为了保证可靠那么就要增加延迟, 虽然用的是光纤,但是光在光纤中传输的速度并不是光速,折合一米有1ns左右的时延,低延迟和高带宽通常不可兼得。很多计算任务都要面临网络异构和拓扑因失效或者升级带来的变化,或者针对不同的计算任务设计不同的拓扑,例如3D-Torus一类的,而且通常由于多个系统管理网络,需要很好的容错性设计。
这些东西都是应用侧的人看不见的,应用侧能搞懂网关和子网掩码就很不错了,毕竟术业有专攻。
MPI
传统的冯诺依曼架构面临着内存墙的瓶颈,因此需要一些In-Memory
计算的架构:
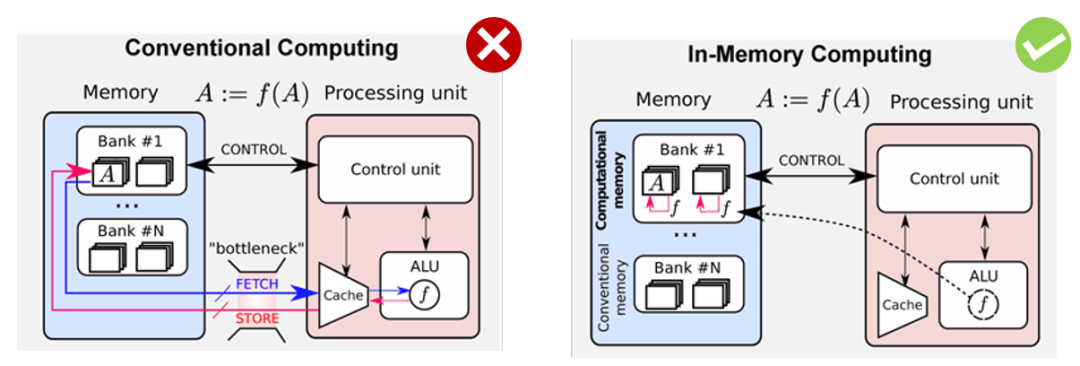
而大量的计算节点,互相通信协作的机制就是Message Passing Interface
,也就是MPI。MPI有MPICH、MVAPICH、OpenMPI、Intel MPI等多种实现,
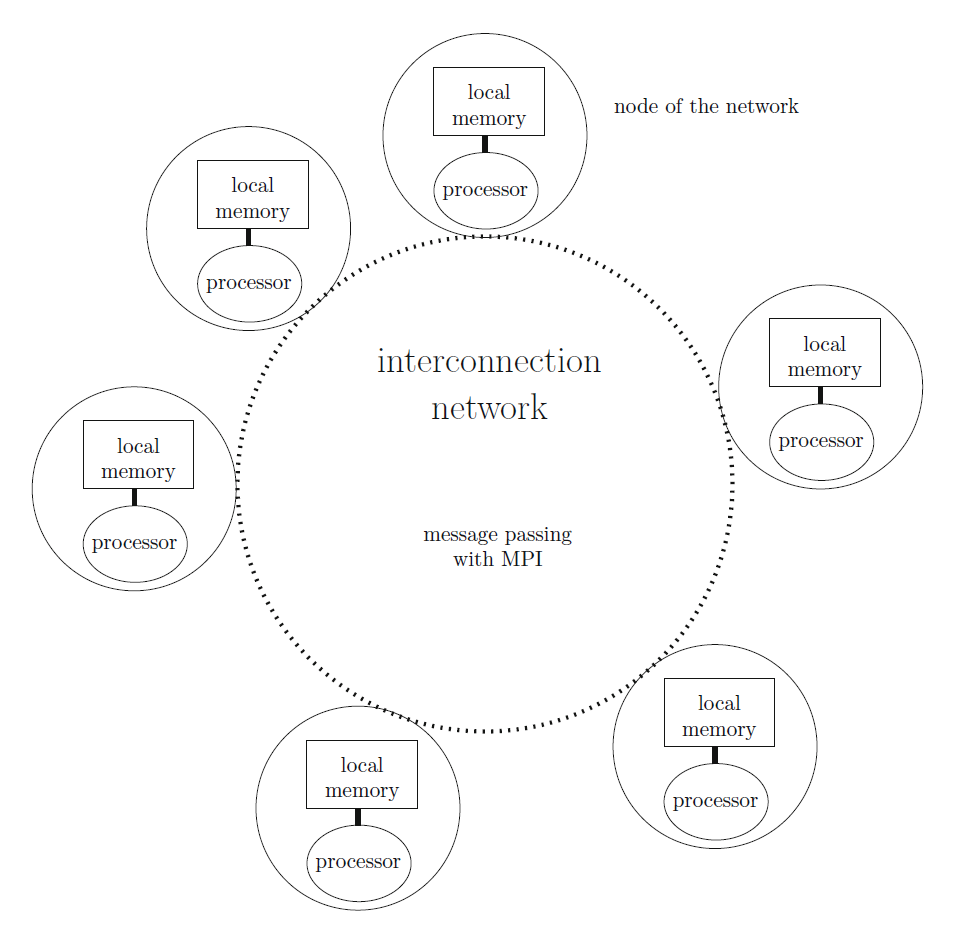
本文系列先采用学习资料推荐的OpenMPI来做,后面再看情况修改。然后编程语言来看,还是以C为主,后期可能看看是否玩一下python的mpi库,毕竟我可以把自己的一些基金量化计算的库Offload到集群上。
MPI原语
MPI有几个基本的原语(Primitives):
BroadCast
: 主要是将相同的消息分发到其它节点,例如Node-0
有数据M
, 需要将其分发到Node-1
...Node-NGather
: 这种模式是指Node-1
有一份数据M1
,Node-2
有一份数据M2
...Node-n
有一份数据Mn
, 这些数据需要完全收集到Node-0
上的过程被称为GatherScatter
: 这个模式正好和Gather
相反,由Node-0
按照一定的规则将M1~Mn
分发到Node-1
~Node-n
的过程Reduce
: 它主要是通过执行一个满足交换律的二元算子来实现的,最简单的算子是求和(MPI_SUM)和求积(MPI_PROD). 例如MPI_SUM(M1~Mn). 其它常见的算子如下:
| MPI name | Meaning |
|---|---|
| MPI_MAX | Maximum |
| MPI_MIN | Minimum |
| MPI_SUM | Sum |
| MPI_PROD | Product |
| MPI_LAND | Logical and |
| MPI_BAND | Bit-wise and |
| MPI_LOR | Logical or |
| MPI_BOR | Bit-wise or |
| MPI_LXOR | Logical xor |
| MPI_BXOR | Bit-wise xor |
| MPI_MAXLOC | Max value and location |
| MPI_MINLOC | Min value and location |
*思考:为啥没有减法和除法,当然减法好说,加负数就好,除法则是不满足交换律,因此会有执行顺序的考虑。
Total Exchange
: 即MPI_ALLtoall, 例如Node-A
有A0~An
,Node-B
有B0~Bn
... 通过AlltoAll处理以后,Node-A
有A0~X0
,Node-B
有A1~X1
....
点对点通信
一切通信的基础都是从最基本的点对点通信出发的。如下的很多内容你会发现和Go语言的Channel非常类似,其实Go的分布式实践很多就是参考了这样的架构。
支持的DataType
MPI通信时可以支持的数据类型如下所示:
| MPI datatype | C datatype |
|---|---|
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | |
| MPI_PACKED |
阻塞通信
send(&data, n, Pdest)
: 从地址&data开始的n个数据发送到Pdestrecv(&data,n, Psrc)
: 从Psrc接收n个数据,并按顺序从&data
地址往后写入
阻塞通信模式使用的函数 MPI_Send、MPI_Recv如下:
int MPI_Send(const void *buf, int count, MPI_Datatype type, int dest,
int tag, MPI_Comm comm)
int MPI_Recv(void *buf, int count, MPI_Datatype type, int source,
int tag, MPI_Comm comm, MPI_Status *status)
阻塞通信在数据传输前都会有一个发送请求
确认通过
得流程。
通信的消息包含几个内容:
source destination tag
: 用于区分不同的消息communicator
: MPI_COMM_WORLD是由MPI提供包含所有节点
一个简单的通信示例如下:
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main(int argc, char *argv[])
{
int myid, numprocs;
int tag1, src, dst, cnt;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
tag1 = 1001;
src = 0;
dst = 1;
cnt = 5;
if (myid == src)
{
int data[5] = {1, 2, 3, 4, 5};
MPI_Send(&data, cnt, MPI_INT, dst, tag1, MPI_COMM_WORLD);
printf("proccessor %d send %d\n", myid, data[0]);
}
if (myid == dst)
{
int data[5];
MPI_Recv(&data, cnt, MPI_INT, src, tag1, MPI_COMM_WORLD, &status);
printf("proccessor %d recv msg with tag:%d\nData:", myid, tag1);
for (int i = 0; i < 5; ++i)
{
printf("%d ", data[i]);
}
printf("\n");
}
MPI_Finalize();
}
编译执行:
zartbot@mpi1:~/mpi/study$ mpicc block_comm.c -o block
zartbot@mpi1:~/mpi/study$ mpirun -np 2 block
proccessor 0 send 1
proccessor 1 recv msg with tag:1001
Data:1 2 3 4 5
阻塞通信通常会有两种死锁状态:
两个同时都在发,或者两个都再等着收
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main(int argc, char *argv[])
{
int myid, numprocs;
int tag, src, dst, cnt;
int buf1,buf2;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
tag = 1234;
src = 0;
dst = 1;
cnt = 1;
if (myid == src)
{
buf1 = 2000;
MPI_Send(&buf1, cnt, MPI_INT, dst, tag, MPI_COMM_WORLD);
printf("proccessor %d send %d\n", myid, buf1);
MPI_Recv(&buf2, cnt, MPI_INT, dst, tag, MPI_COMM_WORLD, &status);
printf("proccessor %d recv %d\n", myid, buf2);
}
if (myid == dst)
{
buf1=200;
MPI_Send(&buf1, cnt, MPI_INT, dst, tag, MPI_COMM_WORLD);
printf("proccessor %d send %d\n", myid, buf1);
MPI_Recv(&buf2, cnt, MPI_INT, src, tag, MPI_COMM_WORLD, &status);
printf("proccessor %d recv %d\n", myid, buf2);
}
MPI_Finalize();
}
非阻塞通信
阻塞通信因为有一个“请求、确认”的握手机制,因此需要等待执行,执行是“同步”的,另一种做法是异步的非阻塞通信。
非阻塞通信采用如下两个函数
int MPI_Isend(const void *buf, int count, MPI_Datatype type, int dest,
int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Irecv(void *buf, int count, MPI_Datatype type, int source,
int tag, MPI_Comm comm, MPI_Request *request)
然后需要注意,这些操作由于是非阻塞的, 因此后续代码可以继续执行,也就是说这样的操作是异步
执行的,而后面有了一个MPI_Wait函数用于等待完成操作。
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#include <math.h>
int main(int argc, char *argv[])
{
int myid, numprocs;
int tag, src, dst, count;
int buffer;
MPI_Status status;
MPI_Request request;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
tag = 1234;
src = 0;
dst = 1;
count = 1;
request = MPI_REQUEST_NULL;
if (myid == src)
{
buffer = 2021;
MPI_Isend(&buffer, count, MPI_INT, dst,
tag, MPI_COMM_WORLD, &request);
}
if (myid == dst)
{
MPI_Irecv(&buffer, count, MPI_INT, src, tag,
MPI_COMM_WORLD, &request);
}
MPI_Wait(&request, &status);
if (myid == src)
{
printf("processor %d sent %d\n", myid, buffer);
}
if (myid == dst)
{
printf("processor %d received %d\n", myid,
buffer);
}
MPI_Finalize();
}
zartbot@mpi1:~/mpi/study$ mpicc non_block.c -o non_block
zartbot@mpi1:~/mpi/study$ mpirun -np 2 non_block
processor 0 sent 2021
processor 1 received 2021
原书的示例还是不太明显,我们再添加一个MPI_test函数,当*req操作执行完后,flag会被改写为1,否则返回0
int MPI_Test(MPI_Request *request, int *completed, MPI_Status *status)
测试代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#include <math.h>
int main(int argc, char *argv[])
{
int myid, numprocs;
int tag, src, dst, count;
int buffer;
MPI_Status status;
MPI_Request request;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
tag = 1234;
src = 0;
dst = 1;
count = 1;
request = MPI_REQUEST_NULL;
if (myid == src)
{
buffer = 2021;
MPI_Isend(&buffer, count, MPI_INT, dst,
tag, MPI_COMM_WORLD, &request);
}
if (myid == dst)
{
MPI_Irecv(&buffer, count, MPI_INT, src, tag,
MPI_COMM_WORLD, &request);
}
int flag;
MPI_Test(&request,&flag, &status);
printf("Processor %d MPI Test flag: %d\n",myid,flag);
MPI_Wait(&request, &status);
MPI_Test(&request,&flag, &status);
printf("Processor %d MPI Test flag: %d\n",myid,flag);
if (myid == src)
{
printf("processor %d sent %d\n", myid, buffer);
}
if (myid == dst)
{
printf("processor %d received %d\n", myid,
buffer);
}
MPI_Finalize();
}
执行结果由于非阻塞就有很多种可能了
zartbot@mpi1:~/mpi/study$ mpirun -np 2 non_block
Processor 0 MPI Test flag: 1
Processor 0 MPI Test flag: 1
processor 0 sent 2021
Processor 1 MPI Test flag: 1
Processor 1 MPI Test flag: 1
processor 1 received 2021
zartbot@mpi1:~/mpi/study$ mpirun -np 2 non_block
Processor 1 MPI Test flag: 0
Processor 0 MPI Test flag: 1
Processor 0 MPI Test flag: 1
processor 0 sent 2021
Processor 1 MPI Test flag: 1
processor 1 received 2021
zartbot@mpi1:~/mpi/study$ mpirun -np 2 non_block
Processor 0 MPI Test flag: 1
Processor 0 MPI Test flag: 1
processor 0 sent 2021
Processor 1 MPI Test flag: 0
Processor 1 MPI Test flag: 1
processor 1 received 2021
双向通信
很多场景需要同时进行双向的通信,因此MPI提供了如下函数:
int MPI_Sendrecv(const void *sendbuf, int sendcount, MPI_Datatype sendtype,
int dest, int sendtag, void *recvbuf, int recvcount,
MPI_Datatype recvtype, int source, int recvtag,
MPI_Comm comm, MPI_Status *status)
例如我们来看一个实例:
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#define SIZE 4
int main(){
int myid,size;
MPI_Init(NULL,NULL);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
MPI_Status status;
int *sendbuf,*recvbuf;
if ( NULL == (sendbuf = malloc( 10 * sizeof (int) ))) exit(1);
if ( NULL == (recvbuf = malloc( 10 * sizeof (int) ))) exit(1);
for ( int i = 0 ; i < SIZE; i++) {
sendbuf[i] = myid;
recvbuf[i] = -10000;
}
int next_id, prev_id;
next_id = (myid < size -1) ? myid + 1 : MPI_PROC_NULL;
prev_id = (myid > 0 ) ? myid - 1 : MPI_PROC_NULL;
for ( int i = 0 ; i < SIZE; i++)
printf("[Before]Proccessor %d Send Buf: %d\tRecv Buf: %d\n",myid,sendbuf[i],recvbuf[i]);
MPI_Sendrecv( sendbuf, SIZE, MPI_INT, next_id, 0, recvbuf, SIZE, MPI_INT, prev_id, MPI_ANY_TAG, MPI_COMM_WORLD, &status );
for ( int i = 0 ; i < SIZE; i++)
printf("[After]Proccessor %d Send Buf: %d\tRecv Buf: %d\n",myid,sendbuf[i],recvbuf[i]);
free(sendbuf);
free(recvbuf);
MPI_Finalize();
return 0;
}
执行
zartbot@mpi1:~/mpi/study$ mpirun -np 3 sendrecv
[Before]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[Before]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[Before]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[Before]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[After]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[After]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[After]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[After]Proccessor 0 Send Buf: 0 Recv Buf: -10000
[Before]Proccessor 1 Send Buf: 1 Recv Buf: -10000
[Before]Proccessor 1 Send Buf: 1 Recv Buf: -10000
[Before]Proccessor 1 Send Buf: 1 Recv Buf: -10000
[Before]Proccessor 1 Send Buf: 1 Recv Buf: -10000
[After]Proccessor 1 Send Buf: 1 Recv Buf: 0
[After]Proccessor 1 Send Buf: 1 Recv Buf: 0
[After]Proccessor 1 Send Buf: 1 Recv Buf: 0
[After]Proccessor 1 Send Buf: 1 Recv Buf: 0
[Before]Proccessor 2 Send Buf: 2 Recv Buf: -10000
[Before]Proccessor 2 Send Buf: 2 Recv Buf: -10000
[Before]Proccessor 2 Send Buf: 2 Recv Buf: -10000
[Before]Proccessor 2 Send Buf: 2 Recv Buf: -10000
[After]Proccessor 2 Send Buf: 2 Recv Buf: 1
[After]Proccessor 2 Send Buf: 2 Recv Buf: 1
[After]Proccessor 2 Send Buf: 2 Recv Buf: 1
[After]Proccessor 2 Send Buf: 2 Recv Buf: 1
