




为了解决海量数据场景下,向量的存储、计算问题,向量数据库应运而生。向量数据库是一种以向量嵌入方式存储和管理向量数据的数据库,其存储的向量主要来自于对文本、语音、图像、视频等非结构化数据的向量化。在向量数据库中,每个向量都有一个唯一的标识符,并且可以存储在一个连续的向量空间中。与传统数据库相比,向量数据库可以处理更多非结构化数据。
近日,在中国信通院组织开展的“可信数据库”首批向量数据库性能测试中,浪潮云信息技术股份公司(以下简称:浪潮云)的浪潮云向量数据库系统顺利完成向量数据库产品性能测试,成为国内首批完成“可信数据库”向量数据库性能测试的向量数据库产品。本次测试依据《向量数据库性能测试方法》,为了能够更贴切地评估和模拟向量数据库在信创环境下的实际性能,全程在符合信创标准的环境下进行。
《向量数据库性能测试方法》是中国信通院云计算与大数据研究所依托中国通信标准化协会大数据与区块链工作组(CCSA TC1 WG6)以及大数据技术标准推进委员会(CCSA TC601),联合超过20家企业专家参与完成的技术标准。该标准覆盖稠密向量检索、多向量检索、标量向量融合检索3种常见向量检索场景,评估指标涵盖索引构建时间、QPS、平均时延、最大时延、P99时延、CPU占用、内存占用等多个维度。该测试融合了国内行业专家丰富的实践经验与智慧,是对向量数据库产品性能的综合评判,能够作为供给侧研发和应用侧选型的参考依据。
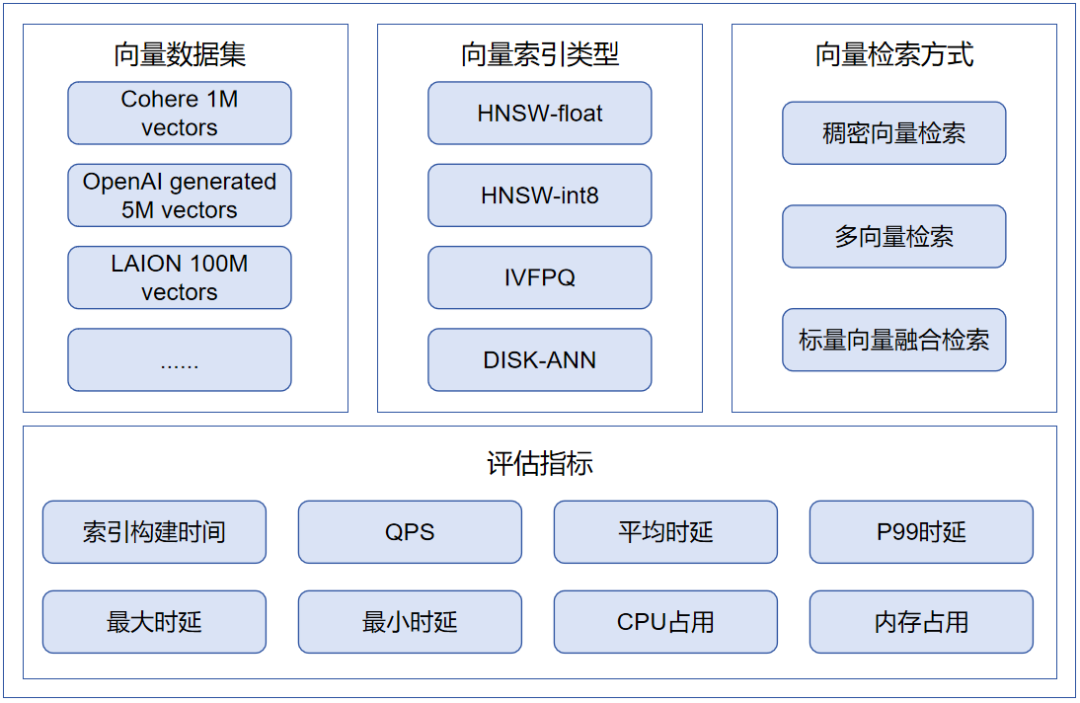
向量数据库性能测试框架
依托“人工智能+”行动部署,浪潮云面向组织用户,完整构建起智数云安一体化融合的发展路径,并基于PoweredBy模式,依托云舟联盟形成全场景生态价值链,加快打通面向组织的智能化落地“最后一公里”。基于此,浪潮云发布分布式智能云战略,并在迈向人工智能落地的“最后一公里”过程中,构建起“前店后厂”新模式,依托海若大模型智能体验中心构建智能技术与实际需求无缝对接的高效平台,依托海若大模型工厂支持大模型快速迭代与持续优化。
作为海若大模型的核心数据组件,浪潮云向量数据库是一款高性能、高可用、低延迟的分布式向量数据库,提供海量多维向量数据、结构化/半结构化数据的存储、检索和分析,支持向量数据、全文数据的多路召回及融合检索。集成AI套件,旨在构建面向大模型和RAG/Agent系统的全流程、端到端、多模态的知识存储及检索底座,为大模型提供一站式知识检索解决方案。
浪潮云向量数据库产品由存储引擎、查询引擎、接口、管理控制台四部分组成,全面支持X86、ARM CPU架构及主流GPU卡。
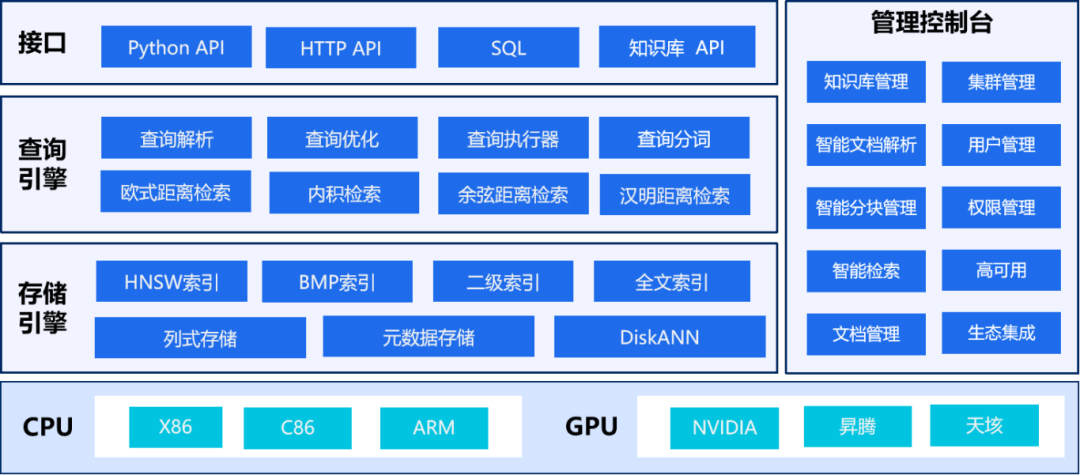
多模数据支持:支持向量、张量、结构化、全文数据等多种数据类型的存储和检索,满足多样化的数据需求。
三路召回与融合排序:支持稀疏向量、稠密向量、张量、全文的多路召回,提供基于RRF、自定义权重、张量的融合排序能力。
高并发、低延迟、高可靠:支持千亿级向量规模、百万级QPS及毫秒级查询延迟。
一站式知识处理:支持一站式知识文档预处理和灵活的内容检索能力,通过多种格式文档的上传解析、自动智能切片(Split)、切片信息补充、知识图谱构建、向量化(Embedding)和自动索引构建等措施进行知识库构建;通过向量+全文融合检索、知识图谱检索、RAPTOR策略等多种措施进行增强的内容检索。
检索增强生成(RAG):在私域知识构建知识库时,解决大模型记忆、幻觉、新鲜度和数据安全等问题,有效扩展大模型的时间与空间边界。
大模型上下文记忆:保持大模型与用户的会话信息,检索相关性高的上下文,生成提示词配合大模型问答,降低幻觉情况发生。
推荐系统:根据用户行为和需求推荐相关信息或产品,提升用户体验。
多模检索:针对文本、图片、音频、视频等多模态数据进行智能化检索,满足多样化的信息需求。
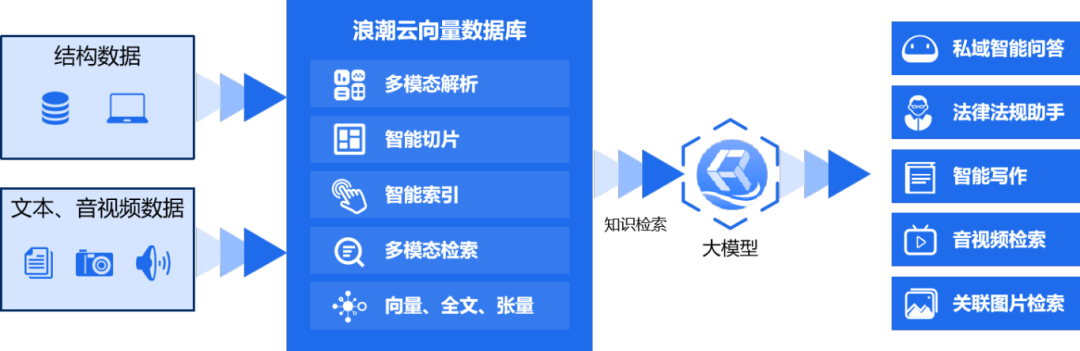
未来,浪潮云将持续以客户需求为中心完善云大模型产品体系,同时依托浪潮云向量数据库的多模态知识处理底座,为组织级用户提供覆盖数据存储、智能检索、知识融合的端到端服务,全面赋能企业智能化转型,为数字经济高质量发展注入强劲动能。
联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





