





近日,ChatDBA 发布 v2.2 版本更新,显著提升了系统在多类型数据库场景下的问题理解能力、知识覆盖深度及响应准确性。
下面让我们正式进入《一问一实验:AI 版》第 63 期,看看 ChatDBA 最新效果以及与热门大模型 DeepSeek-R1 在 慢 SQL 优化方面 的效果对比(结尾)。

阅读本篇文章,你将了解:
MySQL 中导致慢 SQL 的常见原因。
用户如何与 ChatDBA 协作排查故障?
ChatDBA 与 DeepSeek 解决数据库故障的能力对比。
问题
是什么导致了慢 SQL?如何优化?
MySQL 数据库发生慢 SQL 告警,通过 pt-digest-query[1] 工具指定时间段查看,发现了一条占用时长最长的 SQL。
实验
案例实操
欢迎关注社区视频号及 B 站账号
交互轮次 1/3
用户首先发现数据库存在慢查询告警,并通过排查定位到一条执行时间最长的 SQL 语句及其执行计划。随后,用户将相关信息提交给 ChatDBA。

上下滑动查看交互截图
ChatDBA 在分析执行计划和实际执行情况后,指出了可能导致慢 SQL 的根本原因,包括:隐式数据类型转换、排序操作以及临时表参数设置问题,并提供了相应的排查与优化建议。
交互轮次 2/3
根据上一轮 ChatDBA 给出的排查命令进行操作,并将排查结果反馈给 ChatDBA。
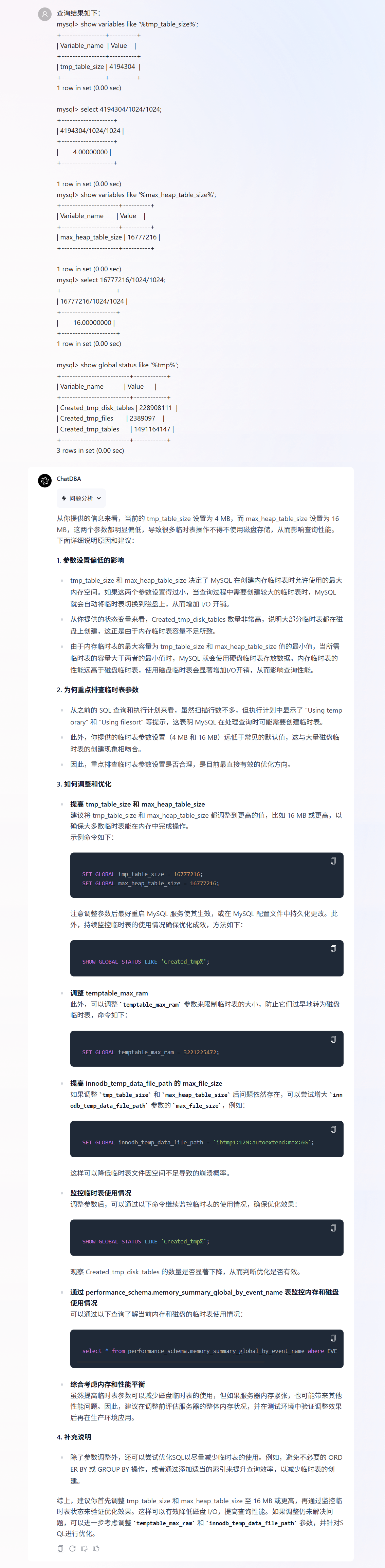
上下滑动查看交互截图
ChatDBA 通过分析当前的临时表参数和状态,指出了根本原因是:内存临时表容量不足导致大量磁盘临时表,并给出了具体的参数调整与优化建议。
交互轮次 3/3
用户根据 ChatDBA 的建议,将 tmp_table_size
参数调整为 16M,SQL 执行效率显著提升,并就性能改善的原因向 ChatDBA 进行询问。
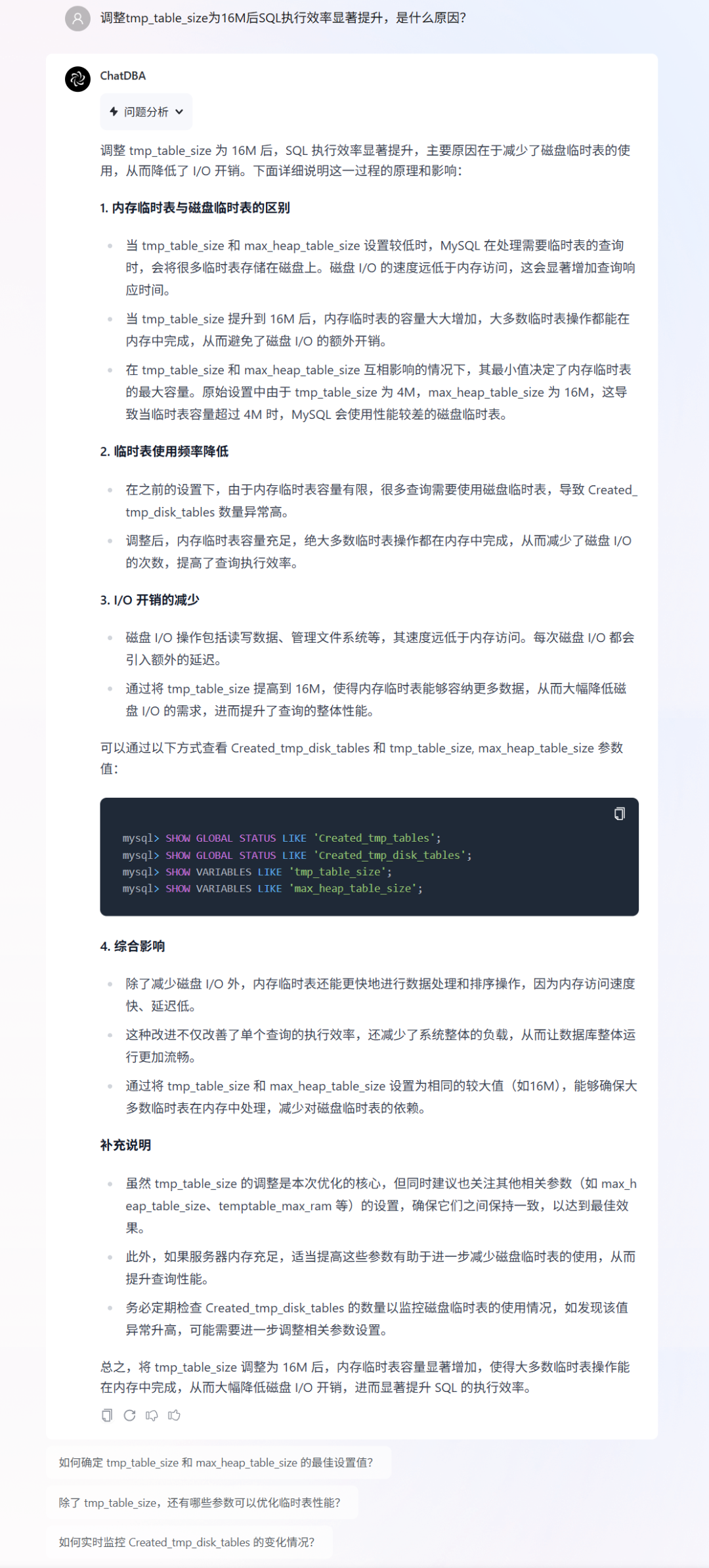
上下滑动查看交互截图
ChatDBA 解释了提升内存临时表容量、减少磁盘临时表使用从而降低 I/O 开销的原理,并给出了相应的监控命令,便于后续观察。
实验总结
1. 慢 SQL 的常见原因
隐式数据类型转换:当 WHERE 或 JOIN 条件中的字段类型与常量/变量类型不匹配时,MySQL 会做额外的转换,导致 “虽然扫描行数少,但实际 CPU 与内存开销增加”,从而触发慢查询告警。 临时表与文件排序(filesort)开销:执行计划中出现 “Using temporary” 或 “Using filesort” 提示时,MySQL 必须先把中间结果写入内存/磁盘临时表,然后再做排序,这一过程会显著增加I/O开销,尤其当临时表被迫写到磁盘时,性能损失更大。 索引与访问类型:虽然该例中扫描行数不多,但若字段没建立合适索引或索引选择不当,即使数据量小也会触发全表扫描或低效范围扫描,这会进一步放大排序和临时表的成本。ChatDBA 侧重临时表和数据类型,是因为它们在该 SQL 里最可能造成 “扫描少却慢” 的假象;若索引有问题,执行计划里通常会显示 type=ALL
或ref
效率极低。内存/缓冲池不足:如果 InnoDB Buffer Pool 太小,大量数据或索引不能命中缓存,也会使查询频繁走磁盘。ChatDBA 补充了查看 InnoDB buffer pool 命中率的建议,就是为了确认是否因缓存不足导致 I/O 瓶颈。
2. 为什么要检查数据类型与隐式转换?
ChatDBA 让用户先 SHOW COLUMNS
确认字段类型,是为了排除 “字段本身为字符串,却用数值比较” 的隐式转换,避免每行都要做类型转换的额外开销。一旦发现类型不匹配,就可通过 CAST(...)
或改写 SQL 来 “对齐” 类型,彻底消除隐式转换带来的 CPU 消耗和索引失效风险。
3. 为什么要检查临时表参数?
MySQL 的 tmp_table_size
与max_heap_table_size
决定了可以在内存中创建的最大临时表大小;当查询需要的临时表容量超过这两个参数中较小的那个值时,会落盘为 “磁盘临时表”。如果大量 “磁盘临时表” 创建( created_tmp_disk_tables
较大),意味着查询过程中频繁进行磁盘 I/O,从而拖慢速度。因此,ChatDBA 会建议先查看这两个参数的当前值、观察 SHOW GLOBAL STATUS LIKE 'Created_tmp%'
,以判断是否真因内存参数偏小导致慢查询。
4. 为什么调整 tmp_table_size
会立刻见效?
当 tmp_table_size
值提高以后,原本必须落盘的临时表能够直接在内存中完成,极大减少了临时表的磁盘 I/O 开销与文件排序成本,于是 SQL 执行效率显著提升。这也说明:慢查询告警并不一定是因为“扫描行数多”,更常见的是某些中间操作(排序、分组)数据量超出了内存临时表限额,转而走磁盘路径带来瓶颈。
ChatDBA VS DeepSeek
DeepSeek 的回答
登录 DeepSeek 官网,提出相同的问题。
DeepSeek-R1 回答首先给出了对问题的分析,然后给出了修改 SQL 语句创建复合索引以及强制索引提示两个解决方,但并未考虑到临时表参数对慢查询的影响。

上下滑动查看交互截图
对比总结
ChatDBA 相较于 DeepSeek-R1 的优势总结如下:
1. 更全面的排查思路
ChatDBA 不仅关注执行计划中的
Using temporary
和Using filesort
,还深入探讨了数据类型隐式转换的问题,这是慢 SQL 常被忽视但重要的性能隐患。明确指出应检查字段类型是否匹配,提出使用 CAST 规避隐式转换,方向明确且实用。ChatDBA 强调检查并调整 临时表相关参数(
tmp_table_size
和max_heap_table_size
),这是一个系统层优化点,正确识别了内存转磁盘临时表可能导致的性能瓶颈,这一点是 DeepSeek 未涉及的。
2. 更细致的性能调优建议
包含了如 InnoDB Buffer Pool 命中率、锁等待情况等系统指标的排查与优化建议,体现了从数据库内部机制角度的深入理解。
ChatDBA 的优势在于考虑更全面,覆盖了 SQL 语义、系统参数和数据库内部资源三方面。当用户偏向于 “快速定位并解决问题” 时,ChatDBA 的排查思路可以帮助用户更加快速解决问题。
引用链接
pt-digest-query: https://docs.percona.com/percona-toolkit/pt-query-digest.html
往期回顾
第 62 期:快速诊断 OceanBase 集群新租户数据同步异常
第 60 期:OceanBase 性能测试竟然出现 4013 错误?
第 59 期:OceanBase NTP 时钟不同步的问题排查?
什么是 ChatDBA?
🤗 ChatDBA 即将在国内上线,敬请期待

