




引言
Apache Doris作为一款高性能的实时数据仓库,近年来在OLAP(在线分析处理)领域大放异彩。它以强大的查询性能、实时数据处理能力和灵活的数据模型,广泛应用于商业智能、用户行为分析、实时监控等场景。
而 DeepSeek 的崛起,则为数据分析注入了新的活力。通过 DeepSeek 的自然语言处理能力,用户可以直接用日常语言查询数据,极大降低了数据分析的门槛。
本文将重点探讨 Apache Doris 与 DeepSeek 的深度融合,详细分析其技术实现、优化策略、应用场景和未来趋势。希望通过这篇内容,您能全面了解这一组合的潜力,并找到适合您业务的实践路径。
Apache Doris深度解析:OLAP领域的"数据加速器"
1.1 Apache Doris 的核心特性
Apache Doris是一款基于MPP(Massively Parallel Processing,大规模并行处理)架构的实时数据仓库,专为高并发复杂查询和数据分析设计。以下是其核心特性:
• 高性能查询: • Doris采用分布式架构,将查询任务拆分到多个节点并行执行,极大提升查询速度。 • 支持亚秒级查询响应,适用于高并发点查询和复杂分析查询。 • 实时数据处理: • 支持实时数据写入和更新,数据时效性强。 • 通过Stream Load、Routine Load等方式,实现数据的实时导入。 • 易用性: • 兼容MySQL协议,支持标准SQL,开发者和分析师易于上手。 • 提供可视化管理工具,如Doris Manager,便于集群运维。 • 高可用性: • 多副本机制确保数据可靠性,支持故障自动恢复。 • 集群扩展灵活,支持动态扩缩容。 • 灵活的数据模型: • 支持多种数据模型,包括Aggregate Key(聚合模型)、Unique Key(唯一键模型)、Duplicate Key(明细模型)。 • 适配不同的业务场景,如聚合分析、明细查询等。
1.2 Doris的技术架构
Doris的架构主要分为以下几个模块:
• Frontend(FE): • 负责接收用户的SQL请求,解析和优化查询计划。 • 管理元数据,包括表结构、分区信息等。 • Backend(BE): • 负责数据的存储和计算,执行具体的查询任务。 • 数据以列式存储,支持向量化和SIMD优化,提升查询效率。
1.3 Doris的典型应用场景
• 商业智能(BI): • 生成实时报表和仪表板,支持多维度分析。 • 例如,分析销售额、用户增长、地域分布等指标。 • 用户行为分析: • 分析用户的点击、购买、浏览等行为,优化产品体验。 • 例如,电商平台分析用户的购物路径,优化推荐系统。 • 实时监控: • 监控系统性能、业务指标,及时发现异常。 • 例如,制造业监控生产线状态,触发告警。 • 数据湖加速: • 作为数据湖的查询加速层,提升查询效率。 • 例如,结合Hadoop生态,加速Hive或Spark的查询。
DeepSeek 与 Apache Doris 的结合:智能数据分析的未来
2.1 为什么需要 DeepSeek 与Doris结合?
在传统的数据分析中,用户需要精通 SQL 才能从 Doris 中提取信息。但 SQL 的门槛较高,对于业务人员来说,学习成本不小。而 DeepSeek 的出现,打破了这一壁垒。DeepSeek 能理解自然语言,将用户的口语化问题翻译成SQL 查询,让数据分析变得像聊天一样简单。
2.2 LLM与Doris的结合方式
• 自然语言查询(NL2SQL): • 用户用日常语言提问,如"最近一个月的销售额是多少?"。 • LLM自动生成SQL查询,从Doris中提取答案。 • 数据洞察生成: • LLM分析Doris的查询结果,生成易懂的洞察和建议。 • 例如,分析销售额下降的原因,并提出优化建议。 • 自动化报告: • LLM根据Doris的数据,自动生成完整的报告,包括图表和文字说明。 • 例如,生成每周销售报表,包含销售额趋势、热门商品等。 • 向量检索能力(研发中): • 通过 Doris 自己的向量检索能力,可不用再引入 Faiss、Milvus 等向量库 • 降低整体架构的使用成本,同时将数据可以做到完整统一在单一组件中
2.3 结合后的优势
• 降低门槛: • 业务人员无需学习SQL,即可进行数据分析。 • 提升效率: • 自动生成SQL和报告,节省大量时间。 • 增强洞察: • LLM能从Doris的数据中挖掘更深层次的洞察,辅助决策。 • 统一技术栈: • 实时数据仓库与向量化检索的合二为一,架构简单,更新效率快
技术实现:基于RAG架构的外部系统集成
3.1 系统架构设计
3.1.1 当前版本
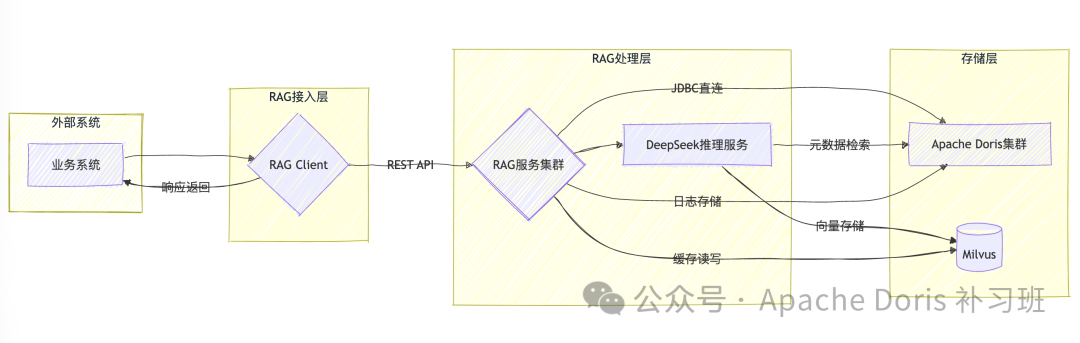
3.1.2 未来版本
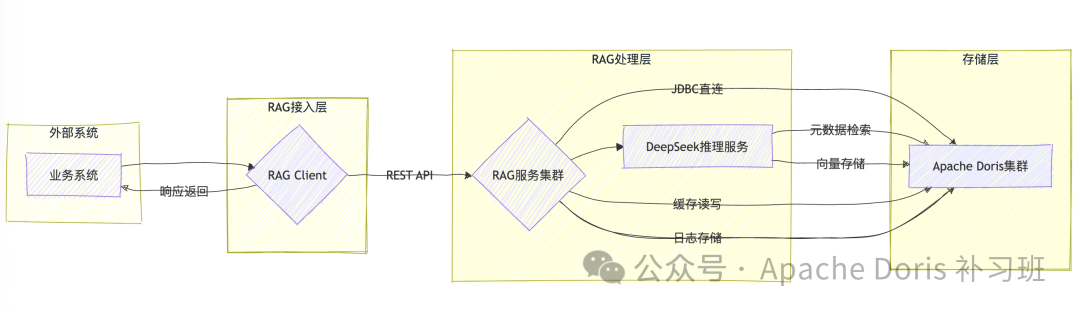
3.2 核心工作流程
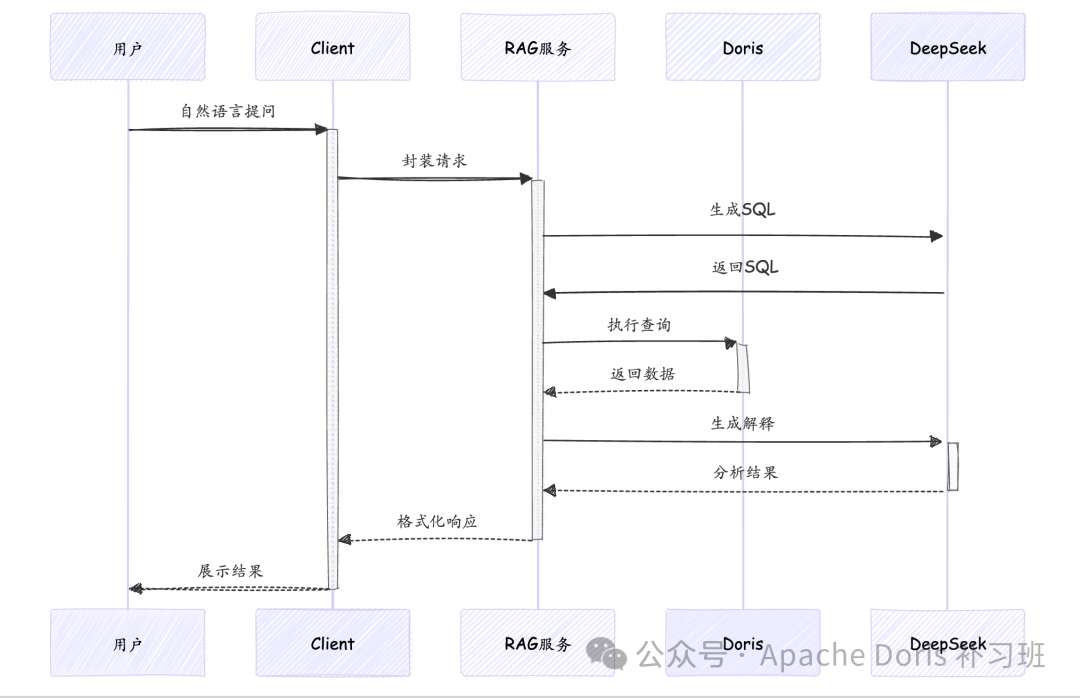
3.3 关键实现细节
• 统一存储架构: -- 在Doris集群中创建元数据索引
CREATE TABLE metadata_index (
table_name VARCHAR(64),
column_name VARCHAR(64),
description TEXT,
INDEX idx_desc(description) USING INVERTED
)
DUPLICATE KEY(table_name, column_name)
DISTRIBUTED BY HASH(table_name) BUCKETS 20;• 元数据管理(伪代码): def sync_metadata():
# 从Doris系统表获取元数据
metadata = doris.execute("""
SELECT TABLE_NAME, COLUMN_NAME, DATA_TYPE, COMMENT
FROM information_schema.columns
WHERE TABLE_SCHEMA = 'business_db'
""")
# 同步到元数据索引表
doris.load_data(
table="metadata_index",
data=metadata,
format="json"
)
3.4 错误重试与自愈机制
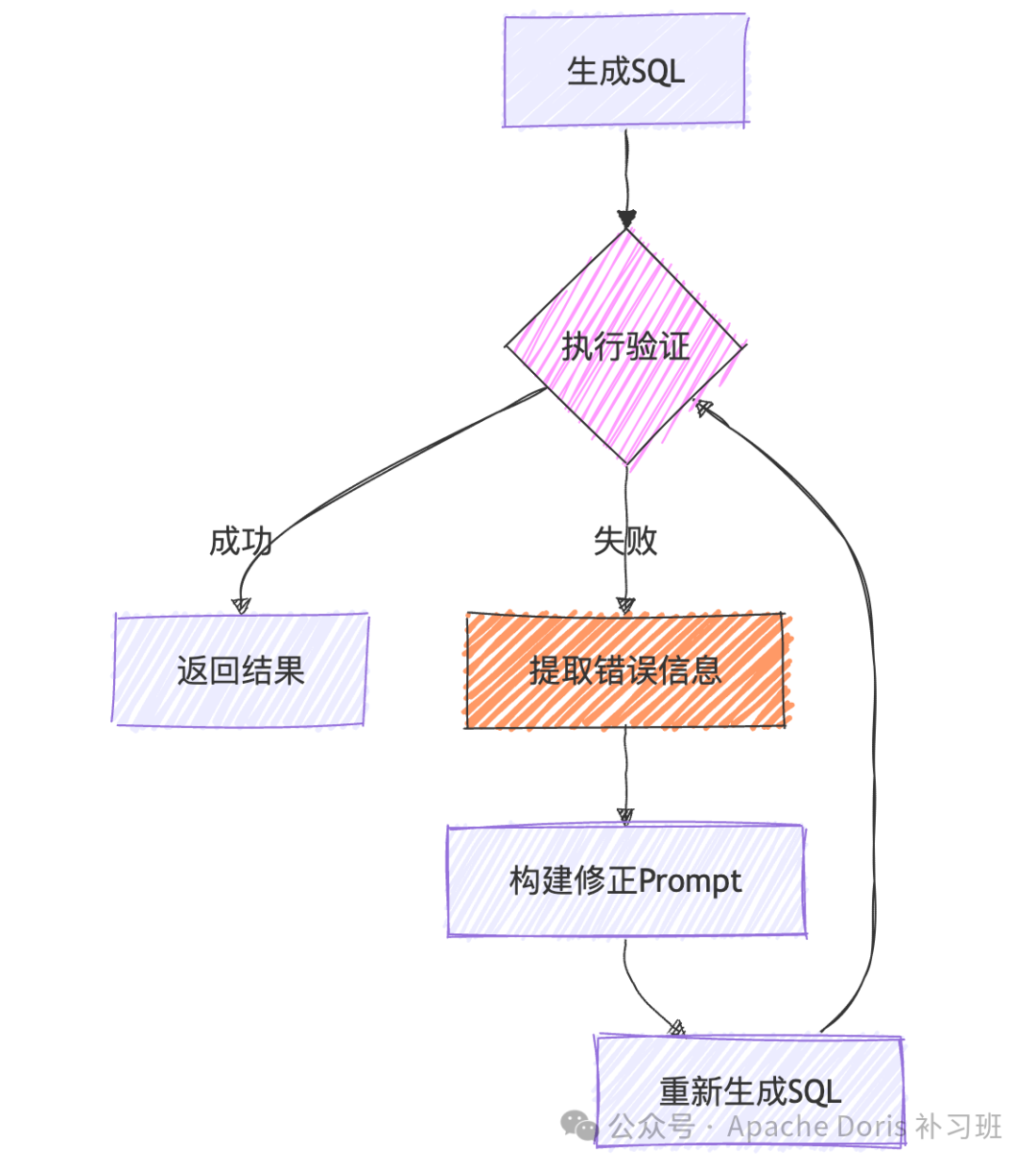
• 智能重试流程(伪代码): MAX_RETRY = 3
def execute_with_retry(query, context):
for _ in range(MAX_RETRY):
sql = deepseek.generate_sql(query, context)
try:
result = doris.execute(sql)
return result
except DorisException as e:
error_msg = parse_error(e)
context.append(f"上次错误:{error_msg}\n错误SQL:{sql}")
raise RetryExceededError()• 错误类型处理: 错误类型 处理策略 重试建议 语法错误 修正SQL 自动重试 权限不足 终止流程 通知管理员 资源超限 优化Hints 降低查询复杂度 数据缺失 检查元数据 更新Schema • 修正Prompt示例: 已知错误:Unknown column 'sales_amout' in field list
原SQL:SELECT sales_amout FROM sales
表结构:sales(sales_amount, order_date)
请修正SQL并说明修改原因• 重试效果监控: -- 记录重试统计信息
CREATE TABLE retry_stats (
query_id BIGINT,
retry_count INT,
error_type VARCHAR(32),
final_state VARCHAR(16)
)
DUPLICATE KEY(query_id)
DISTRIBUTED BY HASH (query_id) BUCKETS 32
;
3.5 架构演进计划

性能优化:让智能分析更快更准
4.1 查询加速技术
• 向量化执行: • 利用Doris的向量化引擎加速计算 • 通过SIMD指令优化聚合、过滤等操作 • 缓存机制: • 建立双层缓存:LLM生成的SQL结果缓存 + 用户常见问题缓存 • 使用Redis缓存热点查询结果,设置TTL自动过期 • 预计算优化: CREATE MATERIALIZED VIEW sales_summary
REFRESH COMPLETE ON SCHEDULE EVERY 1 minute
AS
SELECT product_id, SUM(sales_amount), COUNT(*)
FROM sales
GROUP BY product_id;• 对高频查询创建物化视图,每分钟刷新
4.2 LLM响应优化
• 流式输出: • 在生成SQL时即开始数据预取,实现边计算边输出 • 结果分页: def paginate_result(data, page_size=100):
return [data[i:i+page_size] for i in range(0, len(data), page_size)]• 对大数据集自动分页处理,避免单次查询过载 • 多模态输出: • 结合文本、图表(通过Matplotlib/Plotly)、语音多种形式呈现结果
4.3 资源隔离
• 工作负载管理: -- 设置专用资源组
create workload group if not exists metadata_group
properties (
"cpu_share"="1024",
"memory_limit"="50%",
"enable_memory_overcommit"="false"
);
-- 设置用户使用资源组权限
GRANT USAGE_PRIV ON WORKLOAD GROUP 'metadata_group' TO 'deepseek_doris'@'%';• 为LLM查询分配独立资源组,避免影响常规BI查询 • 动态限流: • 根据集群负载自动调整LLM查询并发数 • 使用令牌桶算法控制请求速率
应用场景:智能数据分析的实践案例
5.1 电商场景:智能运营助手
• 用户提问:
"帮我分析上周华东地区手机品类的销售情况,找出销售额下降的原因"• 系统响应: 1. 自动生成对比同期数据、竞品分析的SQL 2. 从Doris提取数据后,LLM识别出"物流延迟导致退货率上升" 3. 生成可视化图表+文字报告
5.2 金融场景:实时风控问答
• 实现功能: • "最近一小时有多少异常交易?" → 实时扫描Doris流数据 • "生成反洗钱报告" → 自动关联多张风控表 • 性能指标: • 从提问到生成报告平均响应时间<3秒 • 支持50+并发风险查询
5.3 物联网场景:设备智能诊断
• 典型应用: -- 自动生成的设备故障分析SQL
SELECT device_id, AVG(temperature) as avg_temp,
COUNT(error_code) as error_count
FROM iot_metrics
WHERE ts > NOW() - INTERVAL 1 HOUR
GROUP BY device_id
HAVING avg_temp > 100 OR error_count > 5;• 执行效果: • 对千万级设备数据查询响应<500ms • 自动生成维护建议工单
挑战与解决方案
6.1 自然语言歧义处理
• 问题示例:
"显示北京销售数据" → 需要明确是北京市还是北京分公司• 解决方案: def clarify_intent(question):
if "北京" in question:
return ["请确认是指北京市还是北京分公司?"]• 建立业务术语词典 • 设计澄清对话流程:
6.2 复杂查询优化
• 挑战:
多表JOIN、嵌套查询可能导致生成的SQL效率低下• 优化策略: • 自动检测查询模式,推荐创建物化视图 • 对超过3表JOIN的查询提示简化问题
6.3 数据安全与隐私
• 防护措施: GRANT Select_priv(col1,col2) ON ctl.db.tbl TO marketing; -- 市场部只能访问部分字段• 敏感字段自动模糊处理(如手机号→138****5678) • 查询结果分级授权,通过Doris的权限体系控制
未来展望:智能数据分析的演进方向
7.1 多模态交互升级
• 语音问答:
支持"Hey Doris,说说昨天的销售情况"等语音指令• AR数据可视化:
通过MR设备呈现3D数据图谱
7.2 自动化决策闭环
• 智能触发:
当LLM检测到异常时,自动触发业务流程if "销售额下降超过10%" in analysis_result:
trigger_alert(email="ceo@company.com")
generate_promotion_plan() # 自动生成促销方案
7.3 持续学习机制
• 反馈循环:
用户对回答的👍/👎评价自动用于模型微调• Schema动态适应:
当Doris表结构变更时,自动更新LLM的知识库
7.4 更多期望
• 自动 Profile 分析优化SQL • 数据治理和探查覆盖面 • Doris 集群智能运维 • ……
结语
Apache Doris 与 DeepSeek 的深度融合,正在重新定义数据分析的边界。这种结合不仅实现了从"人适应机器"到"机器理解人"的转变,更通过智能化的数据处理和自然交互,释放了数据资产的真正价值。随着技术的不断演进,我们期待看到更多企业通过这种智能分析组合,实现数据驱动决策的质的飞跃。
好了,看到这里了,不得来个点赞和在看呀!这是最大的更新动力!也欢迎各位火爆转发!
如果你有加 Apache Doris 官方社区、PowerData 官方社区、Doris 补习班社区的诉求,可加我微信即刻拉你~
公众号:Apache Doris 补习班
B站号:ApacheDoris补习班
个人微信:fl_manyi
文中提到的 RAG 服务系统完整代码,后续将以系列文章方式做以详解,敬请期待。
