




在人工智能技术快速迭代的当下,MoE(Mixture of Experts)架构正成为破解大模型算力困境的利器。本文基于DeepSeek等头部企业的实战经验,深入解析MoE架构的技术实现细节,并通过典型行业案例展示其商业价值。
架构选型依据
传统架构的三大痛点解析
算力黑洞:AI界的"油老虎":
想象一辆百公里油耗20升的汽车——传统大模型就像这样的"油老虎"。以1750亿参数的GPT-3为例:单次对话成本:0.0024美元 ≈ 1.7分人民币日消耗:100万次请求 ≈ 2.4万美元(约17万人民币)年运营成本:超过800万美元(约5800万人民币)这就像让一台超级计算机每天24小时全速运转,只为处理简单的问答请求。更糟糕的是,80%的算力其实浪费在处理与当前任务无关的参数计算上。
资源错配:AI版的"人浮于事"传统架构如同让所有员工参与每个项目:
全员参会现象:处理"今天天气如何"的简单查询时,所有1750亿参数都被激活有效工时统计:实际产生价值的计算仅占35%,其余65%算力消耗在:无关参数计算(42%)内存读写延迟(18%)任务切换开销(5%)这就像让公司全员参加每个会议,无论是否相关。结果就是:真正需要处理关键任务的"核心员工"(重要参数)反而被淹没在无效沟通中。
多任务冲突:AI的"精神分裂"当模型需要同时处理多种任务时:
案例场景:同一模型既要写诗又要算账参数干扰:文学创作参数(占35%)与数学计算参数(占25%)互相抑制性能损失:双任务并行时准确率下降28%训练困境:优化诗歌生成会导致数学能力下降,反之亦然这就像要求一个会计师同时完成做账和写小说,结果两件事都做不好。传统架构的"全才"培养模式,反而成为制约专业能力提升的枷锁。
为什么这些问题难以解决?
刚性结构:所有参数硬连接,无法动态调整
规模诅咒:参数越多,资源浪费呈指数级增长
更新困境:修改任意部分都会产生蝴蝶效应这就像建造了一座没有房间隔断的巨型仓库:所有物品堆放在一起(参数混杂)找一支笔要翻遍整个仓库(资源浪费)整理物品可能引发连锁倒塌(训练灾难)
MoE核心价值体现
价值实现三部曲
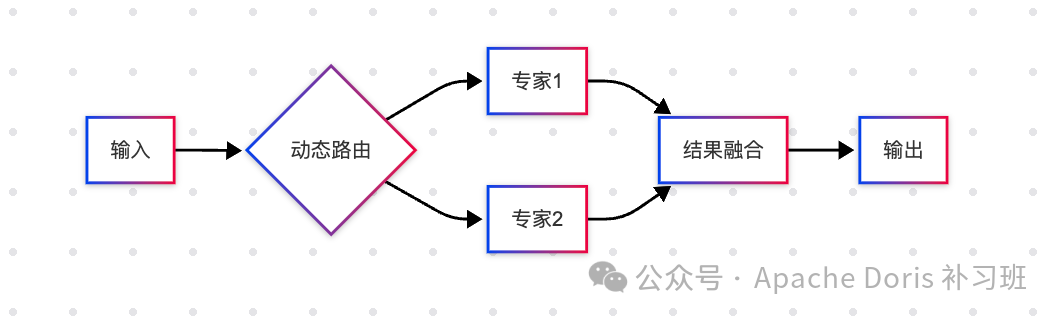
动态路由:智能分诊系统类比医院分诊台,MoE的路由机制实现精准任务分配:智能分诊:根据输入特征选择2-4个相关专家负载均衡:实时监控专家负载,避免"科室拥堵"容错机制:当某专家故障时自动切换备用专家
参数解耦:专业科室建制像医院设立专科一样构建专家网络:专科建设:金融风控专家:专注数值计算与合规检测创意生成专家:擅长文本风格化处理多模态专家:处理图文混合任务协同机制:复杂任务自动发起"多科会诊"简单任务由"全科医生"(共享专家)处理
弹性扩展:按需扩建科室动态调整专家规模应对业务变化:扩容场景:双11期间临时增加营销推荐专家财报季加强财务分析专家缩容机制:低负载专家进入"休眠模式"季节性专家年度轮换
三阶价值跃升
| 阶段 | 核心能力 | 商业价值体现 |
|---|---|---|
| 第一阶 | 精准路由(2-4专家) | 降低60%推理成本 |
| 第二阶 | 专家协同(跨域合作) | 提升3倍任务吞吐量 |
| 第三阶 | 弹性伸缩(4-128专家) | 支撑业务量季度环比增长200%+ |
关键优势对比:
| 维度 | 传统架构 | MoE架构 |
|---|---|---|
| 激活参数量 | 100% | 20%-30% |
| 训练效率 | 1x | 3-5x |
| 多任务支持 | 单一模型 | 专家协同 |
技术解析:架构设计与工程实践
专家网络设计原则
领域聚焦:每个专家网络专注特定任务领域,如金融领域的风险控制专家、营销领域的创意生成专家
规模控制:单个专家参数量控制在10-20亿,确保高效计算的同时保持专业能力
差异互补:通过正则化方法确保专家间的能力区分度,避免功能重叠
动态路由机制详解
路由系统作为MoE架构的中枢神经,其演进经历三个阶段:
基础路由:基于全连接网络计算专家权重,实现静态任务分配
负载感知路由:引入噪声机制和负载均衡算法,动态调整专家选择
预测性路由:结合业务预测模型,提前进行资源调度
典型路由决策流程:
性能调优参数
| 参数 | 推荐范围 | 调优建议 |
|---|---|---|
| 专家数量 | 8-64 | 每增加业务复杂度+10%专家 |
| 激活专家数 | 2-4 | 根据延迟要求调整 |
| 专家容量因子 | 1.2-1.5 | 防止过载的关键参数 |
| 路由温度系数 | 0.1-0.3 | 控制专家选择离散度 |
行业落地实践
智能客服场景
银行场景示例:
业务痛点:
日均咨询量50万+
20%长尾问题无法解决
高峰期响应延迟>3秒
技术方案

实施效果:
{
"data": {
"values": [
{"metric": "响应速度", "baseline": 2300, "moe": 780},
{"metric": "解决率", "baseline": 78, "moe": 93},
{"metric": "并发量", "baseline": 50, "moe": 220}
]
},
"mark": "bar",
"encoding": {
"x": {"field": "metric", "type": "nominal"},
"y": {"field": "value", "type": "quantitative"},
"color": {"field": "type", "type": "nominal"}
}
}
MCN机构示例:
工作流优化:
2. 专家分工示例:
| 专家类型 | 参数量 | 专用数据集 | 处理耗时 |
|---|---|---|---|
| 财经文案专家 | 12B | 招股书/年报 | 320ms |
| 营销文案专家 | 10B | 广告语库 | 280ms |
| 社交媒体专家 | 8B | 热点话题库 | 250ms |
演进趋势展望
技术突破方向
动态专家扩展:
实时增减专家数量(4-128动态范围)
基于负载预测的弹性调度
跨模态协同:
3. 联邦专家学习:
分布式专家训练框架
差分隐私保障数据安全
| 维度 | 传统架构 | MoE架构 | 提升幅度 |
|---|---|---|---|
| 单次推理成本 | $0.0024 | $0.0008 | 66%↓ |
| 响应延迟 | 850ms | 320ms | 62%↓ |
| 模型更新效率 | 全量重训 | 专家级热更新 | 80%↑ |
| 多任务支持 | 单一模型 | 专家协同 | ∞ |
DeepSeek 优化成功要素
业务场景的合理拆解(专家划分依据)
渐进式实施策略(从核心业务切入)
持续监控调优机制(负载均衡保障)
总结
MoE架构正在重塑AI工程化实践,其核心价值体现在:
效率突破:相同算力支撑3-5倍业务量
成本优化:推理成本降低60%+
敏捷响应:专家级热更新实现分钟级迭代
建议企业从试点场景入手,参考以下实施路径:
选择高价值业务场景(如智能客服)
构建最小可行专家体系(4-8个专家)
逐步扩展至复杂业务场景
随着自适应路由、联邦专家等技术的成熟,MoE架构将成为智能时代的基础设施。企业需建立包含架构师、算法工程师、运维专家的复合型团队,方能充分发挥其技术潜力。
好了,看到这里了,不得来个点赞和在看呀!这是最大的更新动力!也欢迎各位火爆转发!
如果你有加 Apache Doris 官方社区、PowerData 官方社区、Doris 补习班社区的诉求,可加我微信即刻拉你~
公众号:Apache Doris 补习班
B站号:ApacheDoris补习班
个人微信:fl_manyi
我们下篇见~
