




在大数据时代,企业最头疼的莫过于海量数据带来的性能瓶颈。今天要介绍的Apache Doris物化视图技术,正是破解这一难题的"真香"利器。它像一位智能管家,既能预存关键计算结果,又能自动优化查询路径,让数据分析效率提升十倍不止!
一、物化视图的核心价值
物化视图本质上是一种预计算机制,通过将复杂查询结果持久化存储,实现三大核心价值:
1. 查询加速:将分钟级查询优化至秒级响应 2. 资源节省:减少80%重复计算资源消耗 3. 架构简化:替代传统ETL流程实现实时数仓
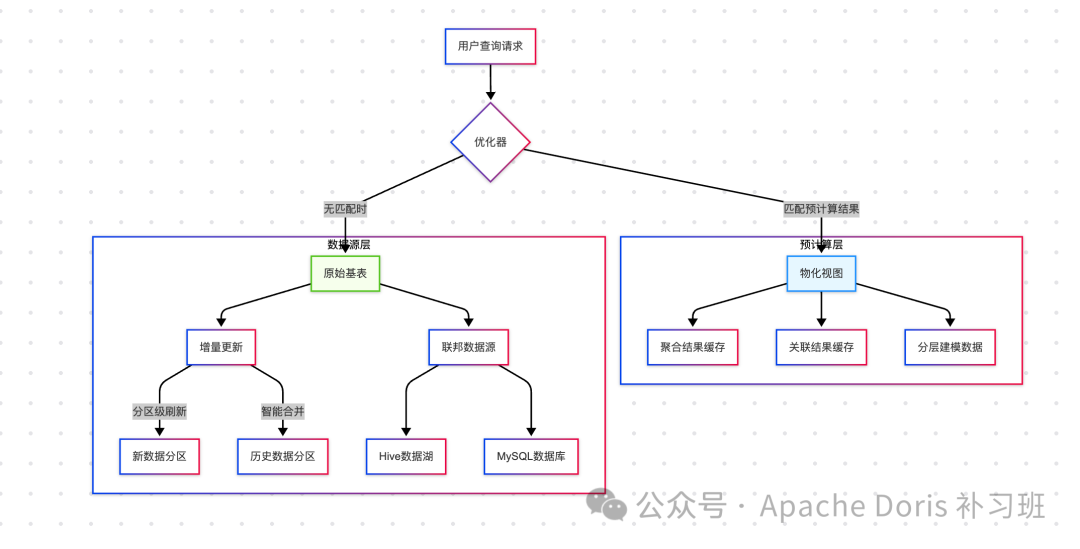
二、异步物化视图的三大绝活
1. 智能透明改写
当用户发起查询时,优化器自动匹配预计算结果。比如这个多表关联查询:
SELECT nation, SUM(revenue)
FROM orders JOIN customer ON o_custkey = c_custkey
GROUP BY nation;
系统会自动识别到已有物化视图存储了聚合结果,直接读取预计算结果,响应速度提升10倍!
2. 增量更新黑科技
支持分区级智能刷新,仅更新变化数据分区。某电商平台订单表每天新增百万数据,通过分区增量更新:
CREATE MATERIALIZED VIEW order_mv
PARTITION BY (o_orderdate)
AS SELECT o_orderdate, SUM(total)
FROM orders GROUP BY o_orderdate;
每日仅需刷新当天分区,资源消耗降低90%。
3. 联邦数据融合
完美整合数据湖与数仓,实现跨存储查询加速。某车企将Hive中的历史数据与Doris实时数据结合:
CREATE MATERIALIZED VIEW hive_mv
AS SELECT * FROM hive_catalog.sales
WHERE year = 2023;
复杂分析查询耗时从分钟级降至秒级。
三、四大典型场景实战
场景1:实时BI报表
某零售企业通过物化视图预计算各区域销售Top10:
CREATE MATERIALIZED VIEW top_sales_mv
REFRESH EVERY 1 HOUR
AS SELECT region, product, SUM(sales)
FROM transactions
GROUP BY region, product
ORDER BY SUM(sales) DESC LIMIT 10;
报表响应时间从3分钟缩短至0.5秒。
场景2:时序数据分析
物联网设备分钟级聚合:
CREATE MATERIALIZED VIEW iot_agg_mv
PARTITION BY (date_trunc(`timestamp`, 'day'))
AS SELECT device_id,
date_trunc(`timestamp`, 'minute'),
AVG(temperature)
FROM iot_stream
GROUP BY 1,2;
时序查询性能提升20倍。
场景3:跨库关联分析
整合MySQL用户数据与日志数据:
CREATE MATERIALIZED VIEW user_behavior_mv
AS SELECT u.user_id, l.action, COUNT(*)
FROM mysql.users u
JOIN log_analysis.logs l
ON u.device_id = l.device_id;
复杂关联查询耗时从30秒降至1秒。
场景4:数据分层建模
通过物化视图实现分层计算:
-- DWD层
CREATE MATERIALIZED VIEW dwd_order
AS SELECT /*+列裁剪*/ ...;
-- DWS层
CREATE MATERIALIZED VIEW dws_sales
AS SELECT region, SUM(amount)
FROM dwd_order GROUP BY region;
建模效率提升50%,存储成本降低60%。
四、最佳实践指南
1. 设计原则
• 高频查询优先:80%的查询往往来自20%的SQL模式 • 适度冗余:单个物化视图覆盖多个相似查询 • 生命周期管理:定期清理使用率低的视图
2. 性能调优
-- 查看改写情况
EXPLAIN SELECT...
-- 部分场景下,关键参数设置
-- 如果查询使用了失效分区的数据,并且数据时效在 grace_period 范围内,那么此物化视图仍然可用。如果物化视图数据时效超出 grace_period 范围,可以通过联合原表和物化视图来响应查询。此时需要开启允许联合改写开关 enable_materialized_view_union_rewrite(自 2.1.5 版本起,该开关默认开启。)
SET enable_materialized_view_union_rewrite = true;
-- 透明改写成功的结果集合,允许参与到 CBO 候选的最大数量,默认是 3。如果发现透明改写的性能很慢,可以考虑把这个值调小。
SET materialized_view_rewrite_success_candidate_num = 1;
3. 避坑指南
• 避免过度使用:建议物化视图依赖层级不超过3层,尽可能1-2层(后续有 DAG 依赖可以增加) • 分区策略:按时间分区时保持与基表一致 • 刷新策略:交易类数据建议小时级或分钟级刷新,日志类数据天级刷新
五、常见问题精解
Q:基表数据变更后,物化视图如何保证一致性?
A:通过grace_period设置容忍延迟(如10秒),在时效性与性能间取得平衡
Q:如何应对频繁更新的基表?
A:采用分区增量刷新+UNION ALL补偿策略,确保查询连续性
Q:复杂嵌套查询如何优化?
A:使用嵌套物化视图逐层计算,2.1.3版本后支持多级视图联动
Q:外表数据如何加速?
A:通过Hive等Catalog对接,设置materialized_view_rewrite_enable_contain_external_table
开启外表支持
Q:是否支持自动刷新?
A:支持创建时选择定时触发时段进行自动刷新,从2.1.4版本起,支持触发式自动刷新,即Base表有数据灌入,就立马触发刷新动作(不适用高频导入场景)
六、未来展望
随着3.0版本的发布,Apache Doris物化视图正在向更智能的方向进化:
• 自动物化视图推荐:基于AI自动识别优化机会 • 智能刷新策略:根据查询模式自动调整刷新频率 • 跨集群同步:实现物化视图的集群级高可用
技术没有最好只有最合适,物化视图就像数据分析的"快捷键",用对场景才能事半功倍。
好了,看到这里了,不得来个点赞和在看呀!这是最大的更新动力!也欢迎各位火爆转发!
如果你有加 Apache Doris 官方社区、PowerData 官方社区、Doris 补习班社区的诉求,可加我微信即刻拉你~
公众号:Apache Doris 补习班
B站号:ApacheDoris补习班
个人微信:fl_manyi
我们下篇见~
