




DPU的赛道真有趣,Fungible换了CEO、Pensando融了35M、Xilinx发布Versal HBM还专门提到Marvell的CN106xx、Marvell则是直接买了Innovium. Linkedin看到Google自己在做CPU
去年写过一篇<苏妈会买Innovium么?>[1],其实来自于SiFive的CEO发的一个DataCenter Equation:
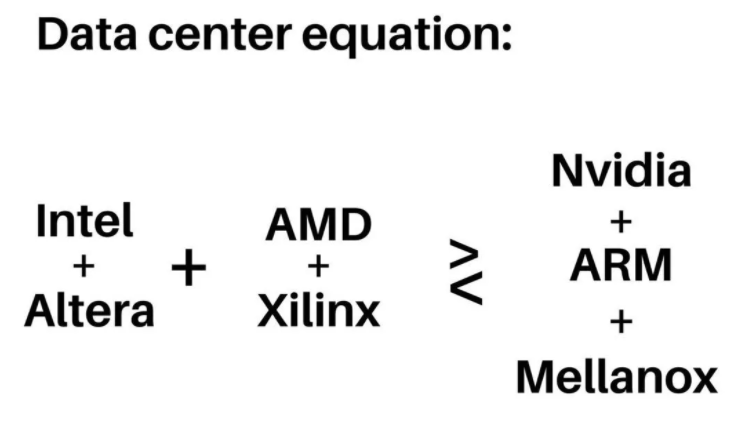
nVidia
买了ARM
和Mellanox
以后,基本上协议栈全了,Intel
买了Barefoot
后,配合Altera FPGA
玩起了IPU
,最近又在大张旗鼓的基于P4实现NDP协议去和RDMA竞争. 当时我就在想AMD
怎么玩呢,买了Xilinx
以后数据中心交换还缺一块呀,Innovium又不贵,应该是苏妈很好的选择...没想到最后被Marvell
收了.
DPU的赛道上,的确是需要一个25.6T以上的傻快傻快的Fabric的。Fungible
换CEO想必也是原来的战略出现了问题,至于Pensando要做一个25.6T的交换芯片对于MPLS来说根本就不是事,或者某个公司已经... 笑而不语~~
然后这个赛道上AMD
和Xilinx
的最佳合作伙伴就只能BRCM
和Cisco
选了, 继续笑而不语..
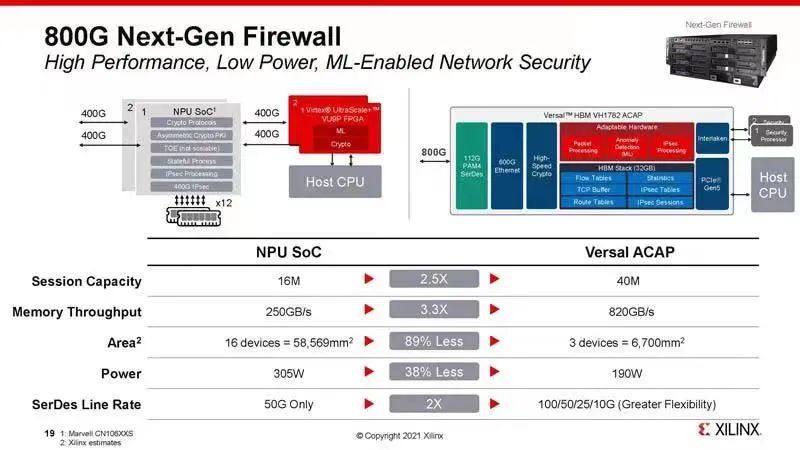
Xilinx最近很有趣的发了一个图,左边的NPU SoC就是CN106XXS,右边是带HBM的Versal,其实两家都有自己很好玩的东西,Marvell是ARM多核跑DPDK可以和主CPU软件架构上同构,这样在小于200Gbps的边缘和中档次场景中是一个很好的选择。而Xilinx新的FPGA有600G Ethernet的硬核也是一个很不错的选择,不过正如它自己的定位,更多的还是在大于200Gbps以上的高端高吞吐市场上做网络相关的处理。
其实Victor在ISSC 2021上的一张ppt把Xilinx的定位讲的非常的好:Disagregated
Computing
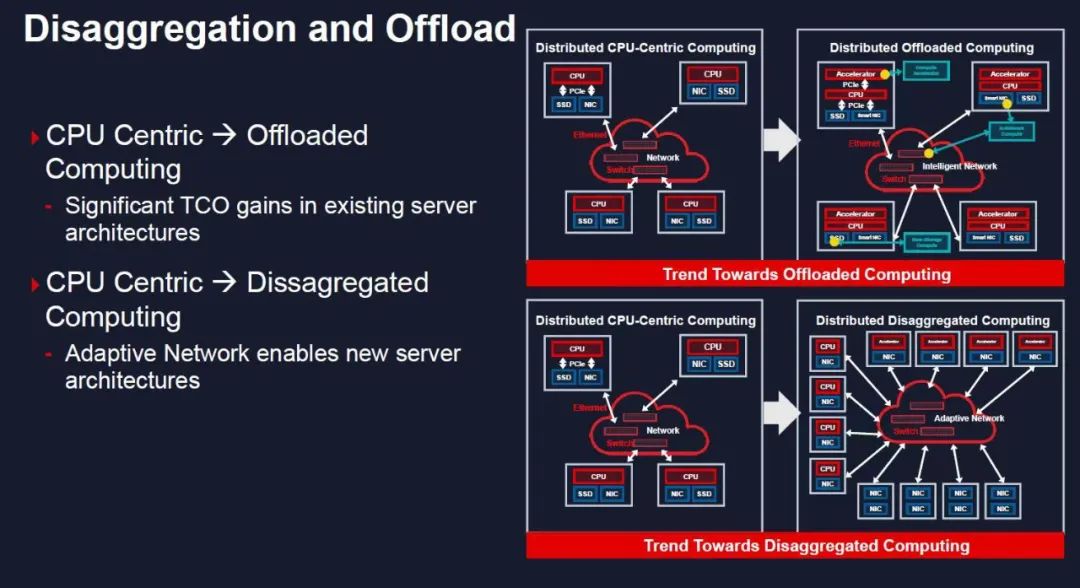
DPU的赛道上,并不是简单的加一个U去Offload。任何一条赛道需要告诉别人你做的是什么和不是什么的时候,本质上这个东西就是一个毫无意义的做加法的过程。SDWAN便是一个典型的例子。
而真正的精髓来自于架构的减法,最近深陷在五六个减法项目中:
比RDMA还快的一个东西 一个很好玩的DPU调度算法 基于上周ZaDNS实现xxx及跟Ruta的整合实现Z*** 基于复杂网络理论的链路预测和威胁分析来实现Predictive Routing Ruta下一版RFC-Draft及相关代码的开源... ... RISC-V的DataCentric ISA
Reference
苏妈会买Innovium么?: https://mp.weixin.qq.com/s/9C1MkIpoxVwDkkw5LmC51w
