




❝开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共3000人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7群均已爆满,开8群近400 9群 150+,将开10群)
最近遇到一个事情,历史问题,在PolarDB for MySQL中从MySQL迁移过来的表,被开发通过hash 进行分区了,一个表被分成了64个表,且还不是一张表,很多张表,表之间还有表连接查询,且表连接之间并不是一对一的关系。我画一个图,我们来通过图来了解一下相关的解释。
在看图前,我们先看具体的结果,这边模拟了现场
1 两个hash 64的分区表进行join 的处理的执行计划
+----+-------------+-------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+-----------------------------------------------------------+-----------------------+---------+------------------+-------+----------+--------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+-----------------------------------------------------------+-----------------------+---------+------------------+-------+----------+--------------------------------------------------+
| 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 75066 | 100.00 | NULL |
| 1 | SIMPLE | s | p12 | ref | PRIMARY,idx_sku_enterprise_id,idx_enterpriseid_createtype | idx_sku_enterprise_id | 8 | const | 33336 | 100.00 | Parallel scan (2 workers); Using index condition |
| 1 | SIMPLE | su | p0,p1,p2,p3,p4,p5,p6,p7,p8,p9,p10,p11,p12,p13,p14,p15,p16,p17,p18,p19,p20,p21,p22,p23,p24,p25,p26,p27,p28,p29,p30,p31,p32,p33,p34,p35,p36,p37,p38,p39,p40,p41,p42,p43,p44,p45,p46,p47,p48,p49,p50,p51,p52,p53,p54,p55,p56,p57,p58,p59,p60,p61,p62,p63 | ref | idx_sku_unit_sku_id | idx_sku_unit_sku_id | 8 | bill_center.s.id | 1 | 100.00 | NULL |
+----+-------------+-------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+-----------------------------------------------------------+-----------------------+---------+------------------+-------+----------+--------------------------------------------------+
2 同样两个普通表表 join 的处理的执行计划
+----+-------------+-------+------------+------+-----------------------------------------------------------+-----------------------+---------+------------------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------------------------------------------+-----------------------+---------+------------------+-------+----------+-----------------------+
| 1 | SIMPLE | s | NULL | ref | PRIMARY,idx_enterpriseid_createtype,idx_sku_enterprise_id | idx_sku_enterprise_id | 8 | const | 61634 | 100.00 | Using index condition |
| 1 | SIMPLE | su | NULL | ref | idx_sku_unit_sku_id | idx_sku_unit_sku_id | 8 | bill_center.s.id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+-----------------------------------------------------------+-----------------------+---------+------------------+-------+----------+-----------------------+
我们看下图假设这为两个分区表,通过hash进行了每个表10个hash 的分区,而这两个表之间链接,每个分区都有对方分区链接的数据。
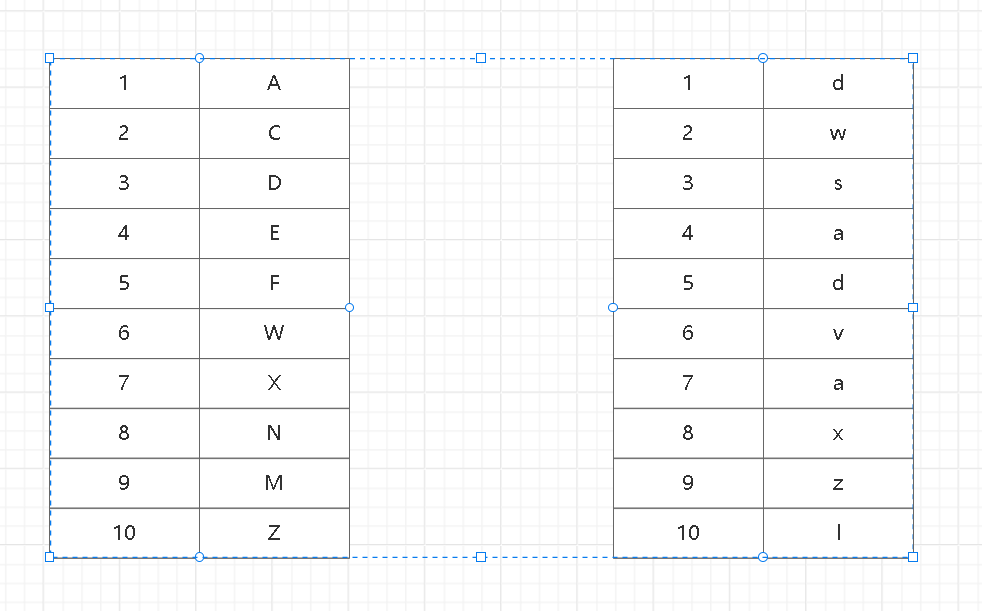
这里我们先解释这样会出现什么问题
1 分区对齐:分区对齐的意思是,在进行hash 分区的时候两个表的每个分区都是对齐的,A表的1分区针对的就是B分区的1分区,一一对应,此时PolarDB for MySQL 之间的表链接会避免全表分区笛卡尔链接。这样JOIN 发生在匹配的分区,JOIN 在分区之间只会发生10次的之间链接。
2 分区没有对齐:这就是我们担心的问题,意思就是A表的1分区的数据会对应B表的1-10的分区,以此类推,最后JOIN在两个表之间发生的链接的时候,是100 也是就是10×10 访问链接表的方式,且这里提示,即使你的分区达到了我们所说的 1号的情况,你还是要注意JOIN 只能是INNER JOIN,一定不是LEFT OR RIGHT Join,且MySQL必须是8这个版本及以上,
显然我们这个问题里面的开发人员,属于只知其一,不知其二的MySQL使用者,只是知道MySQL的行数多了后,会导致性能的差的问题,从未考虑你的业务是否复杂,你使用分区表的原则和限制是什么。
今天我必须要要批判一下,分区表,这个问题不光是针对MySQL,或兼容MySQL的一众数据库,包含ORACLE ,MSSQL 这样的数据库也是一样。
分区表是否应该大面积应用到数据库系统中,这是我们应该深思的。
1 业务简单,且这些业务没有那么多的需求,或者在直白的说就是你的这个应用是甲方,纯甲方的业务,你才可以考虑使用分区表,如果你是乙方,或者类似Saas这类服务甲方的软件,或者系统,我个人的看法,严禁使用分区表。
分区表中三大分类hash,list,range这三类分区分别针对的是
1 数据要进行归档和删除的情况,使用日期类型的分区形式,且查询一定带有日期
2 list 这个分区我非常不建议,对于业务灵活的情况下,list显然是最糟糕的分区,会导致分区的数据存储的不均衡导致分区失败或无意义。
3 hash 这是这三类分区最不能使用的分区类型。
为什么hash是这三类最不能使用的分区,一句话讲明hash是为了服务数据插入而提供的一种输入性的分区方式,他主要的目的就是提高数据在输入INSERT时的效率,仅此而已。(也有通过取余方式的定向hash分区匹配业务中的主键定义,可针对业务来说太复杂了,所有的表都要这么干,想想就头疼)
所以 hash分区是业务查询的杀手,尤其在MySQL上,多个表之间是无法通过对齐分区的方式来进行查询的,这就造成如果有两个表进行数据的JOIN且产生了分区无法对齐的情况,就会导致A分区表分区数量 * B表分区的数量,分区越多情况越糟糕。
这里需要说明,PolarDB for MySQL 虽然兼容MySQL,但一般我们不能将MySQL的使用经验完全照搬到Polar-M上,首先我们应该打破一个表行数的限制,基于Polar-M 提供
1 engine_condition_pushdown 的功能,我们可以开启并尽量让数据的过滤在PolarDB-M的存储引擎,而不是要到server层。
SET optimizer_switch='engine_condition_pushdown=on';
2 在资源充沛的情况下,开Polar-M的 parallel_query = ON,开启并行查询的模式
3 在多表巨大且要进行JOIN后聚合的操作,我们直接开启 IMCI功能,在我们的PolarDB-M中的大表建立IMCI index,通过行列混合的方式解决大表之间的JOIN后的GROUP BY 或 where条件复杂的情况。
4 PolarDB -M 底层使用的PLS5 高性能磁盘系统,且匹配polar-fs的文件系统4kB的页面,一写三的纯硬件数据落盘方式,性能比自建的ESC 的云盘的性能不知道要高几个等级,这也是PolarDB敢使用并行的另一个原因,你的IOPS的高,否则在多的CPU都卡在等待IO设备的层面,这也是传统数据库并行无法施展能力的根本原因。
✅ IMCI 的功能
所以在上云后,我们完全抛弃了MySQL,线下是无奈的选择MySQL,线上还坚持选择MySQL.很可能是你的架构师和开发还在愚昧的阶段,否则他们也不会让你这么干。
目前基于此种情况,只能将分区表还原为单表,同时如果非要进行分区的情况,也应该是通过业务逻辑分区,也就是在业务代码中对表进行逻辑分区,而不是通过数据库的分区方式来进行物理分区去解决单表数据量大的问题。
云数据库产品应改造PostgreSQL逻辑复制槽缺陷--来自真实企业的需求
泉城济南IvorySQL 2025 “雷暴云” 就在云和云原生会场
SQL SERVER 2025发布了, China幸亏有信创!
MongoDB 麻烦专业点,不懂可以问,别这么用行吗 ! --TTL
PostgreSQL 新版本就一定好--由培训现象让我做的实验
删除数据“八扇屏” 之 锦门英豪 --我去-BigData!
写了3750万字的我,在2000字的OB白皮书上了一课--记 《OceanBase 社区版在泛互场景的应用案例研究》
疯狂老DBA 和 年轻“网红” 程序员 --火星撞地球-- 谁也不是怂货
和架构师沟通那种“一坨”的系统,推荐只能是OceanBase,Why ?
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
MongoDB 相关文章
MongoDB “升级项目” 大型连续剧(4)-- 与开发和架构沟通与扫尾
MongoDB “升级项目” 大型连续剧(3)-- 自动校对代码与注意事项
MongoDB “升级项目” 大型连续剧(2)-- 到底谁是"der"
MongoDB “升级项目” 大型连续剧(1)-- 可“生”可不升
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火
PostgreSQL 无服务 Neon and Aurora 新技术下的新经济模式 (翻译)
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
MySQL相关文章

