




前言
本文将分享PanweiDB所在主机的磁盘 IO 使用率过高时,该如何进行排查和优化(相关的修改配置在生产上需要谨慎进行),排查方向如下:
-
检查当前活跃的 SQL 和锁等待
-
分析慢查询
-
检查表膨胀和死元组
-
检查 WAL 写入和检查点
-
分析临时文件和排序操作
-
检查索引缺失或失效
-
检查磁盘 I/O 的 SQL 来源
-
优化数据库配置
现象
数据库所在的文件系统磁盘i/o使用率接近100%,这种i/o长期负载很高的,很大可能是和磁盘的硬件有关,需进一步更换更好的磁盘或扩展存储架构。
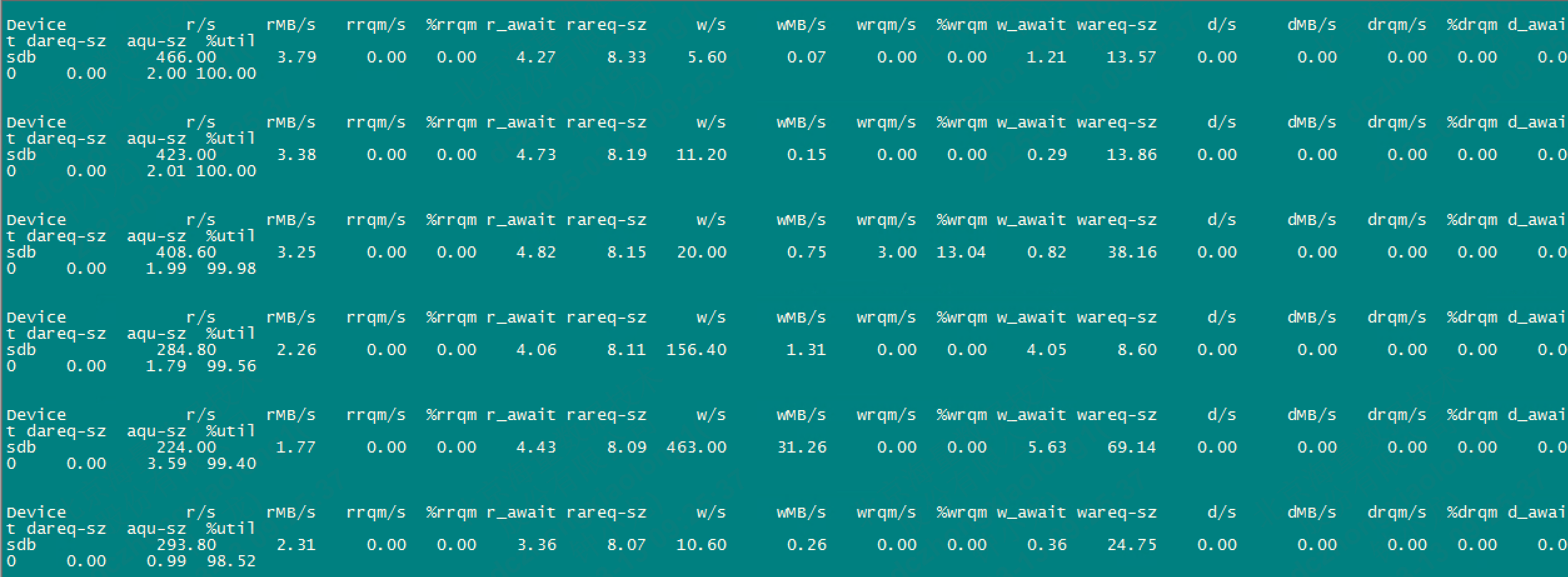
排查过程
1. 检查当前活跃的 SQL 和锁等待
高 IO 通常由低效或长时间运行的 SQL(如全表扫描、大事务写入)引起。
-
查看当前活跃会话:
select pid,datname,usename,client_addr,application_name,state,query_start,query,count(*) from pg_stat_activity where state='active' group by datname,usename,application_name,client_addr,state,query_start,query,pid order by datname;关注 query(执行的 SQL)、query_start(开始时间)、client_addr(客户端 IP)等字段。
-
检查锁等待:
SELECT l.relation::regclass AS table_name, l.locktype, l.mode AS lock_mode, l.granted, a.datname AS dbname, a.usename AS username, a.pid FROM pg_locks l JOIN pg_stat_activity a ON l.pid = a.pid WHERE l.relation IS NOT NULL and dbname!='postgres' and username !='omm';阻塞的锁可能导致事务堆积,间接引发高 IO。
2. 分析慢查询
慢查询通常是高 IO 的罪魁祸首。
-
通过系统视图分析:
-- 通过pg_stat_statements统计执行超过10s的sql SELECT query, total_time / 1000.0 AS total_time_seconds, calls, rows FROM pg_stat_statements WHERE total_time > 10 * 1000; -- 通过DBE_PERF.statement_history按时间段查询超过10S的sql(在postgresql下执行) SELECT db_name, schema_name, start_time, finish_time, query, finish_time - start_time AS total_time FROM DBE_PERF.statement_history WHERE start_time >= '2025-06-17 15:50:12' AND start_time < '2025-06-18 16:02:12' AND (finish_time - start_time) > interval '10 seconds';需要先启用 pg_stat_statements扩展(修改 shared_preload_libraries并重启)。
3. 检查表膨胀和死元组
未及时清理的死元组(由 UPDATE/DELETE 产生)会导致表膨胀,增加 IO 压力。
-
查看表膨胀情况:
SELECT schemaname, relname, n_live_tup, n_dead_tup, (n_dead_tup::float / (n_live_tup + 1)) AS dead_ratio FROM pg_stat_all_tables WHERE n_dead_tup > 1000 ORDER BY dead_ratio DESC;如果 dead_ratio过高,需检查autovacuum是否正常工作。
-
调整 autovacuum 参数:
在 postgresql.conf 中优化:
autovacuum_vacuum_scale_factor = 0.1 -- 当死元组超过 10% 时触发清理 autovacuum_vacuum_cost_limit = 2000 -- 提高清理效率
4. 检查 WAL 写入和检查点
频繁的检查点(Checkpoint)或 WAL 日志写入可能导致 IO 尖峰。
-
查看检查点统计:
SELECT * FROM pg_stat_bgwriter;关注 checkpoints_timed(计划内检查点)和 checkpoints_req(计划外检查点)。过多的计划外检查点需优化。
-
优化检查点参数:
checkpoint_timeout = 30min -- 增大检查点间隔 max_wal_size = 32GB -- 允许更大的 WAL 空间 min_wal_size = 8GB
5. 分析临时文件和排序操作
大量临时文件(如排序、哈希操作)会写入磁盘。
-
查看临时文件使用:
SELECT datname, temp_files, temp_bytes FROM pg_stat_database WHERE temp_files > 0; -- 查看产生大量临时文件的查询 SELECT query, temp_blks_read, temp_blks_written, calls, total_time FROM pg_stat_statements WHERE dbid = (SELECT oid FROM pg_database WHERE datname = 'ktzx') and query not like '%dbe_perf%' ORDER BY temp_blks_written DESC LIMIT 10;如果 temp_files过高,需优化 SQL 或调整 work_mem:
work_mem = 16MB -- 增大排序/哈希操作的内存分配
6. 检查索引缺失或失效
缺失索引会导致全表扫描,显著增加 IO。
- 查找全表扫描:
-- 切换到业务库查询 SELECT schemaname AS schema_name, relname AS table_name, seq_scan AS sequential_scans, seq_tup_read AS sequential_rows_read, idx_scan AS index_scans, idx_tup_fetch AS index_rows_fetched FROM pg_stat_all_tables WHERE seq_scan > 100 AND idx_scan < seq_scan ORDER BY seq_scan DESC;
7. 检查磁盘 IO 的 SQL 来源
通过系统视图定位具体 SQL:
SELECT
t.relname AS table_name,
i.indexrelname AS index_name,
pg_stat_get_blocks_fetched(i.indexrelid) - pg_stat_get_blocks_hit(i.indexrelid) AS disk_reads
FROM
pg_stat_user_indexes i
JOIN pg_stat_user_tables t ON i.relid = t.relid
ORDER BY disk_reads DESC
LIMIT 10;
8. 优化数据库配置
- 内存分配:
shared_buffers = 30% of RAM -- 提高共享缓冲区 effective_cache_size = 50% of RAM - 并行查询:
max_worker_processes = 16 -- 根据 CPU 核数调整 max_parallel_workers = 8
总结步骤
通过以上步骤,通常可以显著降低磁盘 IO 负载。以上步骤若有不足或者错误之处,请留言指出,欢迎读者一起交流。
