





写在前面
跨模查询是 KWDB 的核心跨模能力的重要组成部分,主要指的是在 KWDB 中跨关系引擎和时序引擎的查询。
在不少物联网业务场景下,用户通常会使用一张表(例如:时序表)存储所有的多模态数据(如:关系型+时序),导致表数据十分冗余庞大,查询速度慢等诸多问题。通过 KWDB 跨模技术的应用,能够打破传统数据存储与分析的边界,实现多模态数据的无缝连接与高效融合。在 KWDB 中,关系型数据与时序数据可分别存储于关系引擎与时序引擎,通过 KWDB 跨模查询,可实现大幅的性能提升。
接下来,我们将通过具体的项目操作演示,带大家快读体验 KWDB 的跨模查询  ,大家可前往仓库获取对应代码资料哦>>https://gitee.com/kwdb/sampledb/tree/master/multi-mode
,大家可前往仓库获取对应代码资料哦>>https://gitee.com/kwdb/sampledb/tree/master/multi-mode
技术特点
KWDB 的跨模查询主要包含以下三项技术:
• 跨模统计信息和代价估算融合技术:融合了多模的数据统计信息模型和代价估算策略,并以此为基础优化了跨模执行计划的规划和剪枝的逻辑,从而在遇到包括连接、聚合、排序、过滤、嵌套等非常复杂的业务查询的时候也能确保获得较优的执行计划。 • 跨模聚合下推技术:针对跨模计算中包含聚合计算的情况,本项目不仅实现了将常见且理论体系比较成熟的基于关系代数理论的聚合计算下推到时序引擎的优化技术,并且针对时序引擎中数据往往具有静态标签的特性,实现了时序引擎中聚合算子自适应降维和降维算子的自动调用。 • 高速跨模连接算子技术:针对传统数据库系统在跨引擎计算时处理跨模数据连接计算存在的性能问题,KWDB探索并实现了高速跨模连接算子的技术,此项技术通过在引擎融合、算子对接、内存管理、连接策略等方面一系列优化,实现了跨模连接计算效率提升几十倍甚至上百倍。
下图示例展示的是时序数据跟关系数据的跨模查询计划,同时标识了我们应用的三种跨模查询的技术。
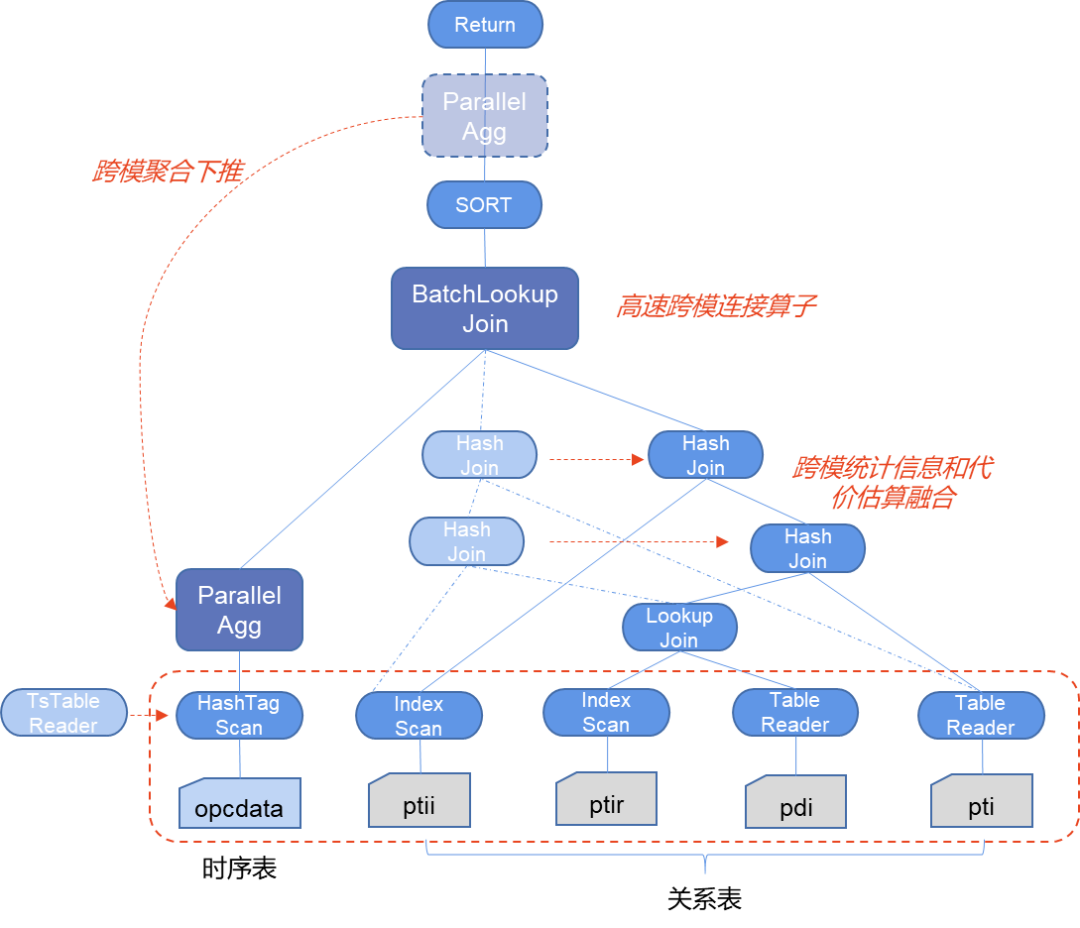
首先基于跨模统计信息和代价估算融合技术来可以调整时序算子和关系算子的最优连接顺序,同时评估查询是否可以应用跨模聚合下推技术和高速跨模连接算子技术。图中 BatchLookJoin 就是 KWDB 创新研发的高速跨模连接算子,可以进行高速连接计算,而跨模聚合下推会将聚合操作中关于时序部分的聚合操作推到前面提前聚合,大量裁剪传输的数据量。
文件清单
multi-mode/
├── start_service.sh # 启动数据库单机服务脚本
├── generate_data.sh # 数据生成脚本,
├── create-load.sh # 创建数据库,创建表以及导入数据的脚本
├── create-load.sql # 创建数据库,创建表以及导入数据的SQL命令
├── query.sh # 跨模查询的脚本
├── query.sql # 跨模查询的SQL命令
├── multi_test.sh # 一键测试的脚本
└── README.md # 跨模查询测试介绍文档
注:本项目的脚本仅在 linux 系统执行
操作步骤
• 将上述文件清单中的脚本以及 SQL 文件移至 KWDB 二进制目录下方 • 执行 start_service.sh
脚本,启动数据库单机服务(如已启动请忽略本步骤)
#!/bin/bash
DEFAULT_LISTEN_PORT="11223"
DEFAULT_HTTP_PORT="8892"
DEFAULT_STORE="./kwbase-data"
LISTEN_ADDR=${1:-$DEFAULT_LISTEN_PORT}
HTTP_ADDR=${2:-$DEFAULT_HTTP_PORT}
STORE=${3:-$DEFAULT_STORE}
./kwbase start-single-node --insecure --listen-addr=127.0.0.1:$LISTEN_ADDR --http-addr=127.0.0.1:$HTTP_ADDR --store=$STORE --background
注:如果启动时候
--listen-addr
服务监听端口以及--http-addr
admin UI 的端口被占用的话,需要重新指定,如:bash start_service.sh 11221 8008 ./kwbase-data12
,参数1是服务监听端口,参数2是 admin UI 端口,参数3是数据保存目录。
• 执行 generate_data.sh
脚本,生成时序表数据以及关系表数据
可以指定数据存储路径,如 bash generate_data.sh ./kwbase-data12
,该路径需要与 start_service.sh
的保持一致,如果不指定的话,默认是 ./kwbase-data
• 执行 create-load.sh
脚本,创建数据库、时序表、关系表,并将数据导入表中
#!/bin/bash
DEFAULT_LISTEN_PORT="11223"
LISTEN_ADDR=${1:-$DEFAULT_LISTEN_PORT}
./kwbase sql --insecure --host=127.0.0.1:$LISTEN_ADDR < create_load.sql
注:如果监听端口被占用了,需要重新指定,如:
bash create-load.sh 11221
,该端口必须与start_service.sh
的监听端口保持一致。
• 执行 query.sh
脚本,体验跨模查询
#!/bin/bash
DEFAULT_LISTEN_·PORT="11223"
LISTEN_ADDR=${1:-$DEFAULT_LISTEN_PORT}
./kwbase sql --insecure --host=127.0.0.1:$LISTEN_ADDR < query.sql
注:如果监听端口被占用了,需要重新指定,如:
bash query.sh 11221
,该端口必须与start_service.sh
的监听端口保持一致。
Tips:可以直接执行 multi_test.sh
脚本,一键体验。
表结构设计
• 时序表结构
// 测点数据表,可以是某些采集传感器,采集温度、电压、电流等实时数据
CREATE TABLE db_pipec.t_point (
k_timestamp timestamp NOT NULL,
measure_value double
) ATTRIBUTES (
point_sn varchar(64) NOT NULL,
sub_com_sn varchar(32),
work_area_sn varchar(16),
station_sn varchar(16),
pipeline_sn varchar(16) not null,
measure_type smallint,
measure_location varchar(64))
PRIMARY TAGS(point_sn)
ACTIVETIME 3h;
• 关系表结构
// 公司信息表
CREATE TABLE pipec_r.company_info (
sub_company_sn varchar(32) PRIMARY KEY,
sub_company_name varchar(50),
sub_compnay_description varchar(128));
// 场站信息表,记录站点的静态信息,记录站点SN码、站点名、属于哪个区域、属于哪家公司等
CREATE TABLE pipec_r.station_info (
station_sn varchar(16) PRIMARY KEY,
station_name varchar(80),
work_area_sn varchar(16),
sub_company_sn varchar(32),
station_location varchar(64),
station_description varchar(128));
// 工作区域信息表,记录地区的静态信息
CREATE TABLE pipec_r.workarea_info (
work_area_sn varchar(16) PRIMARY KEY,
work_area_name varchar(80),
work_area_location varchar(64),
work_area_description varchar(128));
// 管线表信息表,记录管线的静态信息,记录管线SN码、管线名
CREATE TABLE pipec_r.pipeline_info (
pipeline_sn varchar(16) PRIMARY KEY,
pipeline_name varchar(60),
pipe_start varchar(80),
pipe_end varchar(80),
pipe_properties varchar(30));
// 测点信息表,记录测点的静态信息,记录测点SN码、属于哪条管线、属于哪个站点等
CREATE TABLE pipec_r.point_info (
point_sn varchar(64) PRIMARY KEY,
signal_code varchar(120),
signal_description varchar(200),
signal_type varchar(50),
station_sn varchar(16),
pipeline_sn varchar(16));
数据生成
生成数据的脚本可以并行生成数据,也可以串行,并行模式要求环境安装 GUN paraller, 如:Linux 的 Ubuntu 环境使用 sudo apt install parallel
命令安装。
数据生成脚本会在数据库数据目录下生成 extern 文件,然后在 extern 目录下生成一张时序表以及四张关系表的数据,脚本内写死每张表的数据行数,如果希望更大数据量,可以改脚本内的数值即可,数据量大时建议并行生成模式。
最终生成5个 csv 文件,目录如: kwbase-data/extern/*.csv
数据导入
• 导入时序数据
import into db_pipec.t_point CSV DATA ("nodelocal://1/t_point");
• 导入关系数据
import into pipec_r.station_info CSV DATA ("nodelocal://1/station_info/station_info.csv");
import into pipec_r.workarea_info CSV DATA ("nodelocal://1/workarea_info/workarea_info.csv");
import into pipec_r.pipeline_info CSV DATA ("nodelocal://1/pipeline_info/pipeline_info.csv");
import into pipec_r.point_info CSV DATA ("nodelocal://1/point_info/point_info.csv");
import into pipec_r.company_info CSV DATA ("nodelocal://1/company_info/company_info.csv");
场景查询
本项目使用城市管道网络(以下简称“管网”)物联网IoT场景。管网场景是跨模查询的一个典型示例:
• 静态属性较多,但数据量都不大,因此可以使用关系型数据进行存储; • 此场景下,时序表仅记录实时数据以及部分关键属性即可。
通过使用 KWDB,我们将管网场景的数据分类存储在 KWDB 的关系引擎以及时序引擎中,通过跨模查询,既能有效提升查询速率,又能帮助用户节省存储成本。
以下场景涉及共计8家公司,41个作业区,436个场站,26个管道,1497个测点。
| |||
| |||
|
场景一: 查询每个站点采集类型为1且采集数值高于50的且采集条目多余3条的数据均值和条目数
SELECT si.station_name,
COUNT(t.measure_value),
AVG(t.measure_value)
FROM pipec_r.station_info si,
pipec_r.workarea_info wi,
db_pipec.t_point t
WHERE wi.work_area_sn = si.work_area_sn
AND si.station_sn = t.station_sn
AND t.measure_type =1
AND t.measure_value >50
GROUPBY si.station_name
HAVINGCOUNT(t.measure_value) >3
ORDERBY si.station_name;
场景二: 按照10s一个时间窗口查询某三个区域内每个站点的某条管线在23年8月1日之后的每种采集类型数值的均值、最大最小值、条目数
SELECT wi.work_area_name,
si.station_name,
t.measure_type,
time_bucket(t.k_timestamp, '10s') AS timebucket,
AVG(t.measure_value) AS avg_value,
MAX(t.measure_value) AS max_value,
MIN(t.measure_value) AS min_value,
COUNT(t.measure_value) AS number_of_value
FROM pipec_r.station_info si,
pipec_r.workarea_info wi,
pipec_r.pipeline_info li,
pipec_r.point_info pi,
db_pipec.t_point t
WHERE li.pipeline_sn = pi.pipeline_sn
AND pi.station_sn = si.station_sn
AND si.work_area_sn = wi.work_area_sn
AND t.point_sn = pi.point_sn
AND li.pipeline_name ='Pipe_3'
AND wi.work_area_name in ('Area_8', 'Area_Z', 'Area_f')
AND t.k_timestamp >='2023-08-01 01:00:00'
GROUPBY wi.work_area_name,
si.station_name,
t.measure_type,
timebucket;
场景三: 按照1h一个时间窗口查询每个区域中每条管线自23年1月4日14点31分起七年内的条目数、累计值、均值
SELECT
time_bucket(t.k_timestamp, '1h') AS timebucket,
s.work_area_sn,
w.work_area_name,
pinfo.pipeline_name,
COUNT(t.k_timestamp) AS measurement_count,
SUM(t.measure_value) AS total_measure_value,
AVG(t.measure_value) AS avg_measure_value
FROM
db_pipec.t_point t, -- 45M
pipec_r.station_info s, -- 436
pipec_r.workarea_info w, -- 41
pipec_r.pipeline_info pinfo -- 26
WHERE
t.work_area_sn = s.work_area_sn -- 41, 41
AND t.pipeline_sn = pinfo.pipeline_sn -- 21, 41
AND s.work_area_sn = w.work_area_sn -- 41, 41
AND t.k_timestamp BETWEEN'2023-01-04 14:31:00'AND'2030-01-04 14:31:00' -- 2M/45M
GROUPBY
timebucket, s.work_area_sn, w.work_area_name, pinfo.pipeline_name
ORDERBY
timebucket, s.work_area_sn
LIMIT 100;
场景四: 按照5s一个时间窗口查询某个区域中每个站点内某条管线的每一种采集类型的数据均值
SELECT wi.work_area_name,
si.station_name,
t.measure_type,
time_bucket(t.k_timestamp, '5s') as timebucket,
avg(t.measure_value)
FROM pipec_r.point_info pi, -- 41
pipec_r.pipeline_info li, -- 41
pipec_r.workarea_info wi, -- 41
pipec_r.station_info si, -- 436
db_pipec.t_point t -- 45M
WHERE pi.pipeline_sn = li.pipeline_sn
AND pi.station_sn = si.station_sn
AND si.work_area_sn = wi.work_area_sn -- 41, 41
AND pi.point_sn = t.point_sn -- 436, 401
AND li.pipeline_name ='Pipe_t' -- 1/26
AND wi.work_area_name ='Area_f'-- 1/41
GROUPBY wi.work_area_name, si.station_name, t.measure_type, timebucket
LIMIT 100;
上述是本期《一文讲透》有关KWDB跨模查询的全部内容,欢迎大家关注我们,后续更多干货持续更新中,敬请期待~💡
最后,欢迎大家在 Gitee/Github 检索“KWDB”,体验我们的项目并参与互动。
Gitee>>https://gitee.com/kwdb/kwdb Github>>https://github.com/KWDB/KWDB atomgit>>https://atomgit.com/kwdb
不管是操作疑问、功能需求或是其他疑问,大家都可在 Gitee 提交 Issue,欢迎一起共建更完善的 KWDB 生态。


链接合集
开源仓库地址:
Gitee:https://gitee.com/kwdb/kwdb
Github:https://github.com/KWDB/KWDB
atomgit:https://atomgit.com/kwdb
官网地址:
https://www.kaiwudb.com/
Docker 镜像:
官方仓库:kwdb/kwdb:latest
国内镜像:swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/kwdb/kwdb:latest
Github Docker 镜像:ghcr.io/kwdb/kwdb:latest


