最近的大模型圈子已经乱成一锅粥了。
因为Multi-Agent,Devin(Cognitio旗下自动编程软件)联合创始人把OpenAI、微软、Anthropic,全都点名吐槽了一遍。
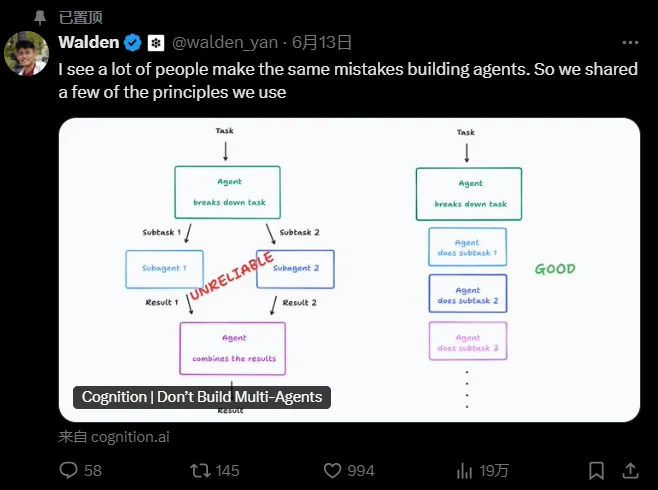
情况大概是这样的:Anthropic刚发布了他们的多智能体研究系统,信心满满地宣称"多智能体是扩展性能的关键";Cognitio就立马跳出来反驳,标题直接挑衅:"Don't Build Multi-Agents"(别搞多智能体),然后又直接说OpenAI 和微软旗下的 Swarm 和 AutoGen 全都错了,把开发者带到了坑里。
Multi-Agent这么火,为什么Devin为什么要吐槽?Multi-Agent当前的争议又在哪里?这场论战对我们做Agent开发又有什么借鉴意义?本文将一一为你解答。

先来看看两家公司拿出的数据:
Anthropic的成绩单:他们的多智能体系统在内部研究评估中,比单智能体Claude Opus 4的表现高出90.2%。
Cognition的反击:多智能体架构"极其脆弱",决策分散导致系统崩溃。而且成本高得离谱——单智能体聊天是基准,多智能体系统的token消耗是单智能体的15倍。(单智能体,你发一条"你好"给AI,可能消耗2个token;AI回复"你好,有什么可以帮助您的?"可能消耗15个token。多智能体系统需要多个AI同时工作,把这些上下文,在多智能体之间来回传递,成本自然就翻倍了)
现在问题来了,90%性能提升 vs 15倍成本消耗,究竟谁对谁错?
真相是,双方都对,但看的角度不同。

Anthropic的"天使论证":多智能体就是生产力
Anthropic的逻辑很直接:单个AI模型就像一个人,再聪明也有极限。但如果让多个AI协同工作,就能突破这个天花板。比如你要研究"2025年AI智能体公司的市场格局"这个复杂问题。如果用单个智能体,它得一步步来:先搜索技术趋势,再看市场数据,然后分析竞争格局...这样下来,半天都搞不定。但多智能体就不一样了。主智能体制定策略,然后同时派出几个"小弟":一个专门搜技术信息,一个专门看市场数据,一个专门分析竞争对手。大家并行工作,效率自然高。
他们的Research系统的设计就是这个理念的完美体现。
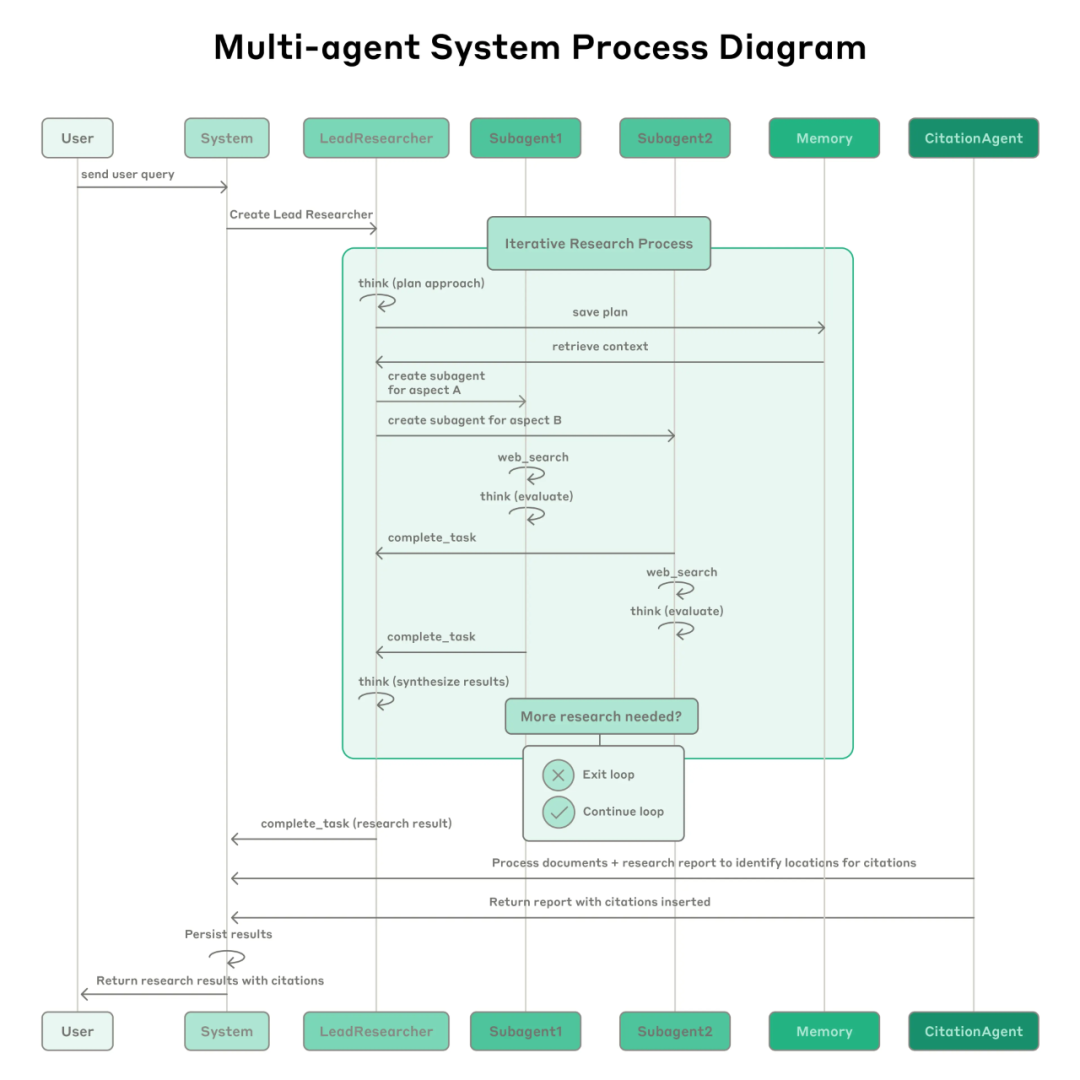
这个架构的精髓在于"编排者-工作者"模式。主Agent就像项目经理,负责拆解任务、分配工作;子Agent就像专业员工,各自专注自己的领域。
对这个架构进行拆解,你就会发现它的优势不只是多个智能体一起思考,另一个更大的优势其实是上下文窗口的突破。现在最强的模型上下文窗口也就200万tokens,看起来很多,但真正处理复杂任务时根本不够用,一旦记忆爆满就直接出现“失忆”的尴尬情况,而多智能体就能很好的解决这个问题。
此外,分工的更大优势还在于不只是把一个事情交给多个智能体做,更是把一件事情拆成不同模块,交给更适合的智能体去做,在Anthropic的系统里,不同的子Agent可以针对不同领域进行优化。搜索Agent专门负责信息检索,分析Agent专门负责数据处理,写作Agent专门负责内容生成。
而且,Anthropic还发现,智能程度和token总用量是正相关的。在BrowseComp评估中,Anthropic观察到token使用量能解释80%的性能差异,即用得越多,效果越好。既然更多token能带来更好效果,那让多个Agent并行使用更多token,自然能获得更强的能力。
Cognition的"魔鬼细节":多智能体的致命缺陷
Cognition的态度很明确:现在的多智能体系统就是个"看起来很美"的陷阱。他们直接开炮:"别搞多智能体了,这条路走不通。"
为什么这么说?因为他们发现了多智能体系统的三个致命问题。
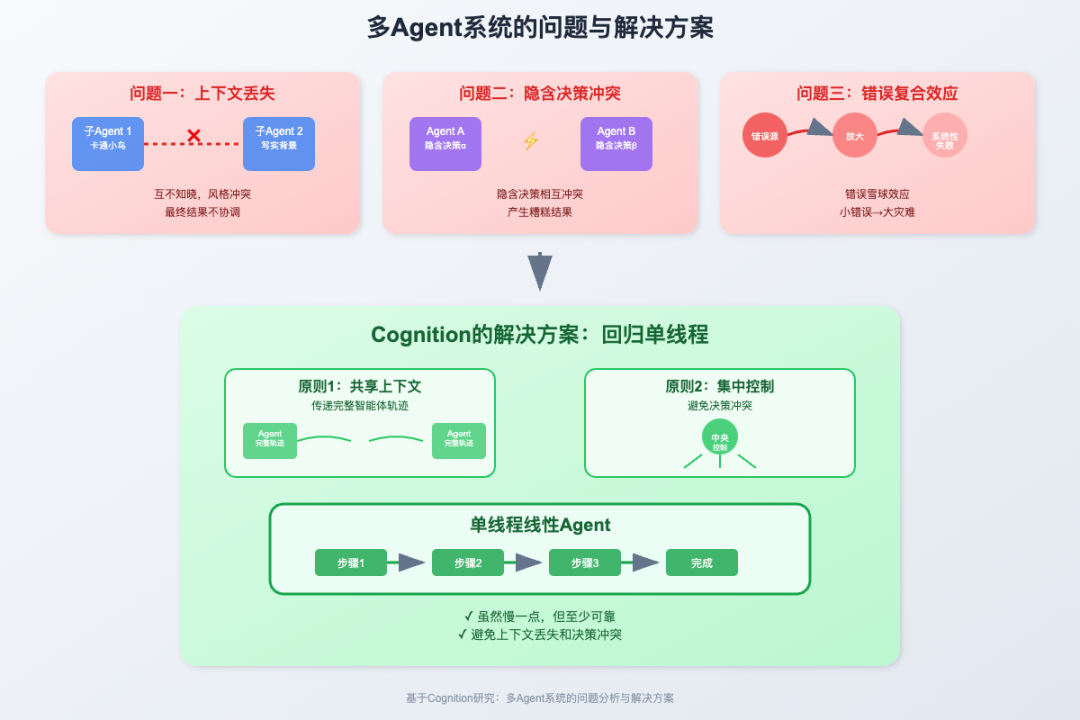
问题一:上下文丢失的灾难。看看Cognition提供的这个架构图:
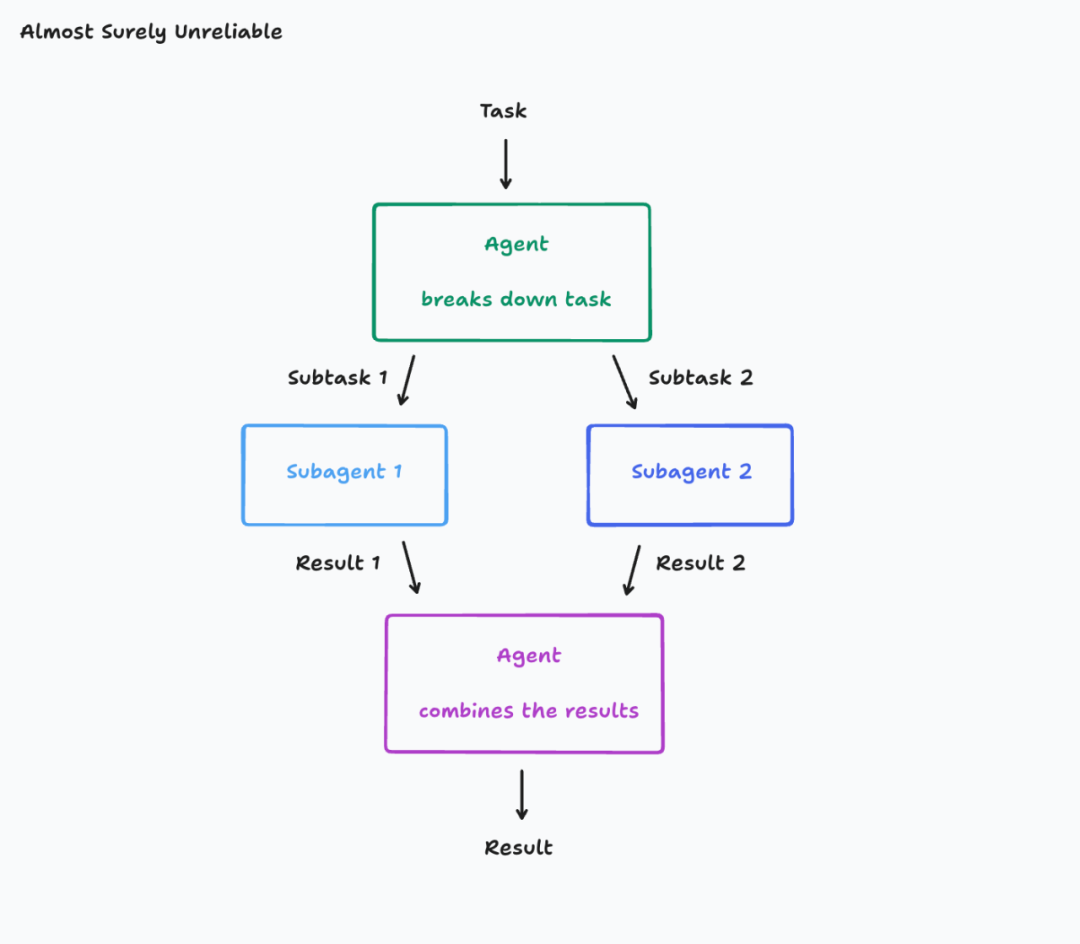
看起来很合理对吧?但问题就出在这里:子Agent 1完全不知道子Agent 2在干什么,反之亦然。
基于问题一,又带来了问题二:隐含决策的冲突。每个Agent都在独立执行任务,期间,都会做出一些"隐含决策"——这些决策没有明确表达出来,但可能不同模块做出的决策其实是相悖的。
问题三,错误的复合效应,也同样典型。单个Agent出错,影响只是局部的。但多Agent系统中,一个Agent的错误会传播给其他Agent,形成"错误雪球"连环传导越滚越大。
总结来说,Cognition担心的问题,除了成本之外,还有信息协调难题。多智能体系统中,每个AI都有自己的"认知边界"和"知识盲区",当它们各自处理信息片段时,缺乏全局视角的统一协调机制。这导致输出结果在逻辑层面、时间维度、数据标准上出现不可调和的冲突,最终产生的综合结论可能完全偏离预期目标。所以,所谓的多智能体更高效,在信息都无法对齐的情况下,可能根本就是个伪命题。
基于以上认知,Cognition认为最合适的解决方案还是回归单线程。这种单线程主要有两个特点:
特点1,共享上下文,传递完整智能体轨迹。不要只传递结果,要传递整个思考过程。让每个Agent都能看到其他Agent的完整决策轨迹,避免信息丢失。
特点2,承认每个行动都包含隐含决策,通过集中控制避免决策冲突。用单线程的线性Agent,虽然慢一点,但至少可靠。

前面两章我们聊了Anthropic和Cognition的架构之争,但有个关键问题一直没深入:多智能体系统最大的技术瓶颈到底在哪里?
就是"记忆"问题。
这个记忆问题,可以从三个方面去理解:
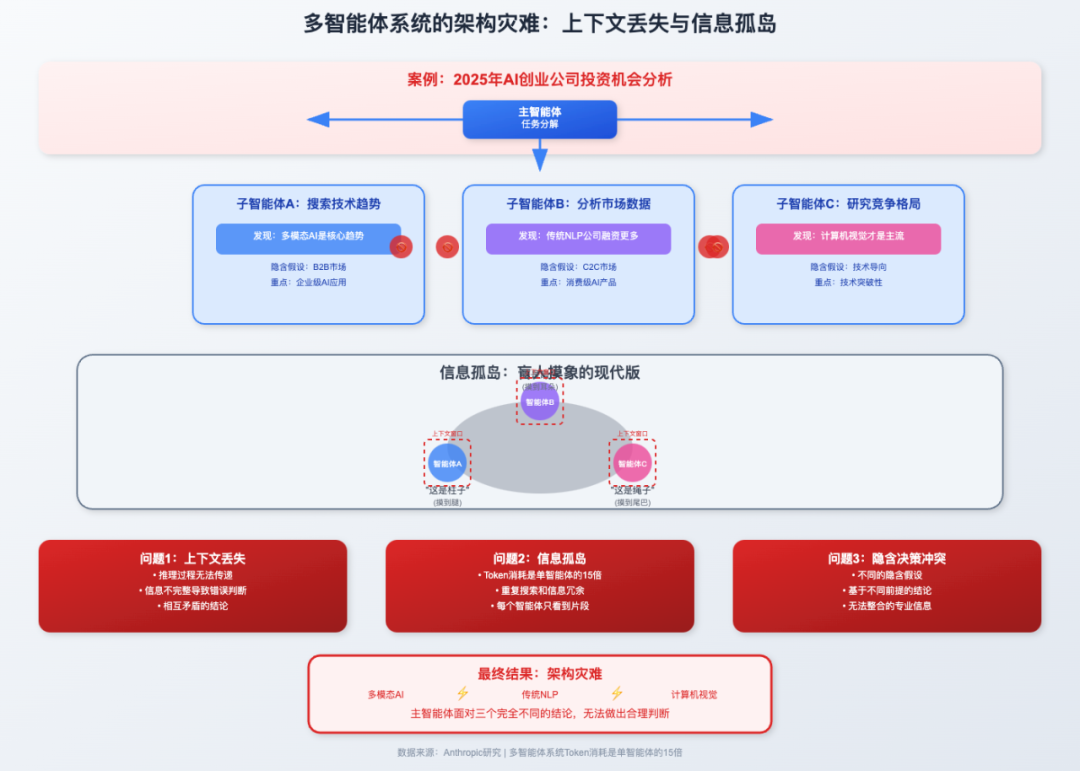
问题一:上下文丢失:不只是技术问题,更是架构灾难。还记得Cognition提到的"上下文丢失"吗?这个问题比表面看起来严重得多。比如:你让AI团队分析"2025年AI投资机会"。
然后三个智能体同时工作时互相看不到彼此的推理与决策过程:于是,A搜索技术趋势,说多模态是趋势;B分析市场数据,发现传统NLP融资更多;C研究了竞争格局,认为计算机视觉是主流
主智能体面对三个矛盾结论,完全无法整合。
问题二:信息孤岛与资源浪费。每个智能体只看到问题的一个片段,就像盲人摸象。为什么多智能体系统token消耗是单智能体的15倍,除了信息传递,大部分浪费在重复搜索上。
问题三:信息整合对齐困难,无法做出决策。A假设关注B2B市场,重点搜索企业级应用;B假设关注C2C市场,重点分析消费级产品。结果看起来都专业,但基于不同假设做的结论,根本无法整合并做出最合适的最终决策。
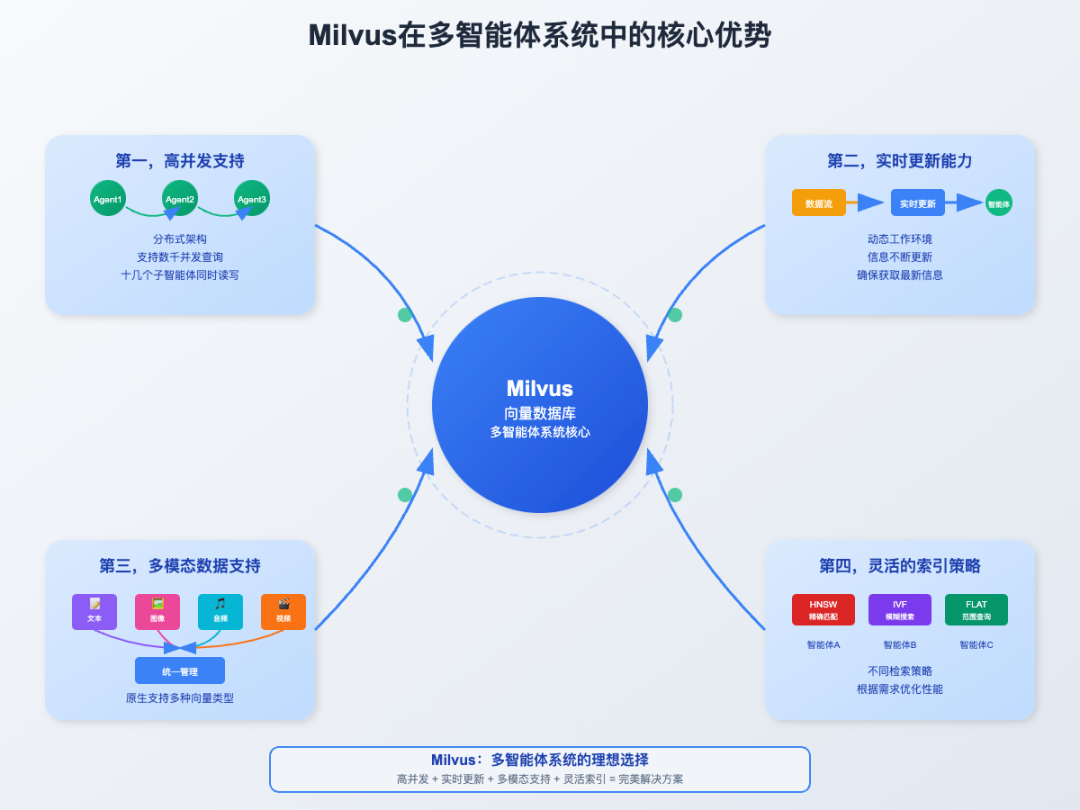
问题客观存在,但解法是否只有单线程一个思路呢?我们可以尝试,用Milvus向量数据库做多智能体协作的统一记忆中枢。
Milvus向量数据库解决多智能体信息孤岛问题的核心优势,一共有四个:
统一存储:所有智能体的推理过程和结果集中存储
实时共享:智能体A的技术分析立即对B、C可见
向量检索(就像给每个信息打上标签,需要时快速匹配):基于语义相似性快速找到相关信息
MCP-Server服务,自然语言交互,高效便捷
智能体A分析"多模态AI趋势"时,B和C能看到完整推理链,避免基于片面信息得出错误结论。三个智能体基于相同信息基础协作,主智能体也能基于此轻松整合一致性结论。

现在,是时候来聊聊那个最扎心的问题了:多智能体系统,在2025年的今天,它到底是个"天使"还是个"魔鬼"?
我的结论是,别急着站队,先看事实。长期来看,多智能体是趋势,但现阶段单智能体更可靠。
Anthropic的"人多力量大"没错,Cognition说的"失忆"和成本也没错。Anthropic看到了它的潜力,Cognition看到了它的挑战。
现阶段,多智能体系统是不是"好",最终还是要看它能解决什么问题,以及解决这个问题的价值是不是大于它消耗的成本。对于那些需要大量并行处理、信息量巨大、或者需要调用多种复杂工具的任务,多智能体系统可能就是那个"天使"。但对于一些简单任务,或者对一致性要求极高的场景,单智能体可能更可靠。
那么,在你看来,多智能体系统在哪些场景下最有潜力?它最大的挑战又是什么?你更看好哪种技术路线?欢迎在评论区,一起聊聊。
作者介绍

Zilliz 黄金写手:尹珉