




1 query mapping–破解SQL优化需要改应用代码的困境
1.1 一个ORACLE数据库的SQL优化的场景
某国际物流公司的全球运单追踪系统面临严峻性能挑战:当客户在网站或APP输入运单号查询包裹状态时,对应这个查询的SQL语句如下
SELECT /*+ GATHER_PLAN_STATISTICS */
s.tracking_no, c.name, r.route_path,
d.amount, s.last_update_time
FROM shipments s
JOIN customers c ON s.cust_id = c.id
JOIN route_history r ON s.id = r.ship_id
JOIN duty_info d ON s.id = d.ship_id
WHERE s.tracking_no = 'UPS7829HKG' -- 输入运单号
AND r.is_latest = 'Y' -- 仅取最新路由
系统需要实时关联订单主表、客户信息、最新路由记录及关税明细等8张大表(日均增长50万条,总量超20亿)。在业务高峰期,这项关键查询的响应时间飙升到12秒以上,引发大量的客户投诉。
技术团队深入排查后发现症结所在:Oracle优化器严重误判了路由历史表的返回行数(实际过滤后仅1条记录,却被估算为1万行),导致错误选择了低效的嵌套循环连接方式;同时由于SQL语句中隐含的OR条件冲突(s.tracking_no OR c.phone),本该启用的运单号索引完全失效。更棘手的是,该查询来自封闭的第三方货运平台,企业无权修改原始SQL代码。
面对这种"看得见病灶却无法动手术"的困境,DBA团队启用了Oracle的SQL Profile技术实施精准干预:
-- 创建调优任务锁定问题SQL
EXEC DBMS_SQLTUNE.CREATE_TUNING_TASK(
sql_id => 'g7s2k9hna1v7p',
task_name => 'FIX_SHIPMENT_QUERY'
);
-- 接受优化建议生成Profile
EXEC DBMS_SQLTUNE.ACCEPT_SQL_PROFILE(
task_name => 'FIX_SHIPMENT_QUERY',
name => 'SHIPMENT_TRACKING_PROFILE',
force_match => TRUE -- 强制匹配所有相似SQL结构
);
这个SQL profile注入两个关键修正:首先将致命的嵌套循环连接替换为高效的哈希连接,其次绕过索引冲突点,强制启用shipments.tracking_idx核心索引。优化效果堪称奇迹——逻辑I/O从38,921次暴降至127次,执行时间从11.8秒锐减到0.2秒,数据库CPU负载直接"腰斩"。
1.2 金仓数据库的query mapping
类似前面的场景在Oracle数据库中经常可以看到,sql profile也是Oracle DBA必须掌握的SQL 优化技巧之一(要是真不会这个,不能说是合格的Oracle 工程师吧)。在目前信创的大潮下,国产数据库在关键业务上替换Oracle的工作正在有条不紊的开展,也取得了明显可见的成效。在SQL优化方面,也有国产数据库提供了类似Oracle sql profile的技术,比如openGauss的AI 执行计划固化,阿里PolarDB的执行计划 Outline,今天介绍一下金仓数据库的query mapping。
中电科金仓(北京)科技股份有限公司(以下简称“电科金仓”)成立于1999年,是成立最早的拥有自主知识产权的国产数据库企业,也是中国电子科技集团(CETC)成员企业。电科金仓以“提供卓越的数据库产品助力企业级应用高质量发展”为使命,致力于“成为世界卓越的数据库产品与服务提供商”。
KingbaseES(简称KES)是电科金仓面向全行业、全客户关键应用的提供的企业级大型通用融合数据库产品,适用于事务处理、数据分析、海量时序数据采集检索、互联网等应用场景;可用作管理信息系统、业务及生产系统、决策支持系统、多维数据分析系统、运行日志管理系统、全文检索系统、地理信息系统、时序数据处理相关系统的承载数据库。 KES采用融合数据库架构,通过多语法体系一体化架构兼容Oracle、MySQL、SQL Server、PostgreSQL等主流数据库的语法; 采用多模数据一体化存储,支持对关系模型、文档模型、全文本、GIS数据、时序等数据的统一存储、混合访问、模型间转换; 采用集中分布一体化架构,提供不同级别的可用性。
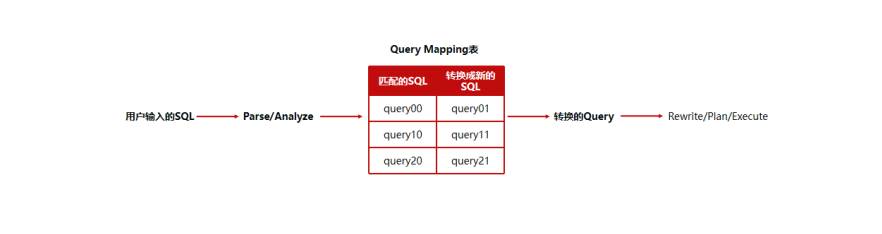
Query Mapping 是KingbaseES提供的的功能,允许用户预先创建 SQL 语句的映射关系并储存在相应的系统表,当用户输入的 SQL 语句与所创建的映射关系相匹配时,替换成映射的 SQL 语句去实际执行。这个功能可用于数据库迁移和优化的场景。
1.3 query mapping的原理
Query Mapping 主要作用是做 SQL 的匹配/替换工作,在数据库中配置源 SQL 语句到目标 SQL 语句的映射关系(存在系统表),根据客户的输入 sql 语句去做匹配,如果匹配,就替换成目标语句进行执行,它有两种级别:
• TEXT 级别:不做词法/语法/语义检查,保存用户的原始 sql 和期望 mapping 的目标 sql,进行字符串匹配
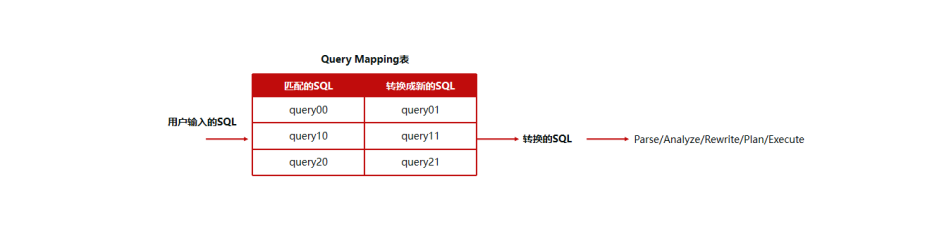
• SEMANTICS 级别:做词法/语法/语义语义检查,并保存用户原始/目标 sql 对应的 Query tree
2 检查query mapping是否激活
kingbase=# select name,setting,boot_val,reset_val from pg_settings where name='enable_query_rule';
name | setting | boot_val | reset_val
-------------------+---------+----------+-----------
enable_query_rule | off | off | off
--编辑kingbase.conf,将enable_query_rule的值改为on
[root@localhost data]# grep enable_query_rule kingbase.conf
enable_query_rule = on # query mapping
--重启数据库,再次检查enable_query_rule的值,当前设置为on
kingbase=# select name,setting,boot_val,reset_val from pg_settings where name='enable_query_rule';
name | setting | boot_val | reset_val
-------------------+---------+----------+-----------
enable_query_rule | on | off | on
(1 row)
3 第一条query mapping
使用create_query_rule函数创建query mapping规则,创建一条简单的映射规则的语句如下
kingbase=# SELECT create_query_rule(
kingbase(# 'qm1',
kingbase(# 'select $1::TEXT AS col',
kingbase(# 'select 2222',
kingbase(# true,
kingbase(# 'semantics'
kingbase(# );
create_query_rule
-------------------
(1 row)
上面的语句创建了一条名为qm1的的语义级别的query mapping规则,把语句 select $1::TEXT AS col 映射为 select 2222,$1为文本型的变量,执行时可以替换为任何类型为text的值,这这条虽则立即生效。
3.2 查看创建的query mapping
规则创建后,保存在系统表_qrymapping内,这个表的定义如下
kingbase=# \d _qrymapping
Table "pg_catalog._qrymapping"
Column | Type | Collation | Nullable | Default
----------------------+----------+-----------+----------+---------
oid | oid | | not null |
qmname | name | | not null |
qmenable | boolean | | not null |
qmfromsql | text | c | |
qmreplacedsql | text | c | |
qmcompiledfromsql | text | c | |
qmcompiledreplacesql | text | c | |
qmlevel | smallint | | |
Indexes:
"_qrymapping_name_index" UNIQUE, btree (qmname)
"_qrymapping_oid_index" UNIQUE, btree (oid)
这个表可以查询到映射前后语句的原始文本,也保存了语句的编译后的文本,在qmname和oid创建了唯一索引,这应当是为了支持大量规则时的系统和用户查询。查询这个视图可以看到刚才创建的那条规则
kingbase=# select qmname,qmfromsql,qmreplacedsql,qmenable from _qrymapping;
qmname | qmfromsql | qmreplacedsql | qmenable
--------+------------------------+---------------+----------
qm1 | select $1::TEXT AS col | select 2222 | t
(1 row)
3.3 验证规则
--- 执行query mapping的原始sql语句,发现语句被按照规则替换了
kingbase=# select 'aaa' as col;
?column?
----------
2222
(1 row)
--删除规则后再看
kingbase=# SELECT drop_query_rule('qm1')
kingbase=# select 'aaa' as col;
?column?
----------
aaa
(1 row)
4 query mapping的操作
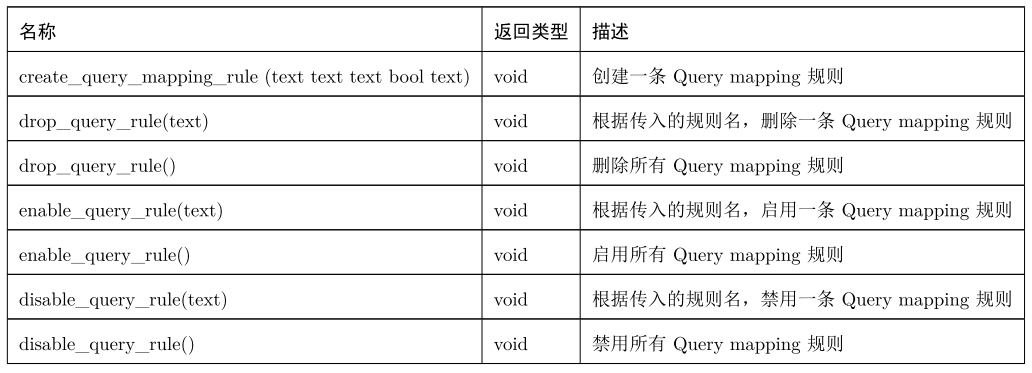
金仓数据库支持对创建的query mapping规则进行激活,关闭,删除三种操作,每一操作可以针对一条规则或者全部规则,对应函数如下
5 query mapping的几个应用场景
5.1 连接数据库,创建测试表,载入数据
kingbase=# ]\c test
You are now connected to database "test" as userName "kingbase".
--创建测试表
test=# create table t1(id int primary key, val int, name varchar(64));
CREATE TABLE
test=# create table t2(id int, val int, name varchar(64));
CREATE TABLE
--表中加入数据
test=# insert into t1 select i, i%10, 'Kingbase'||(i%5) from generate_series(1,1000) as x(i);
INSERT 0 1000
test=# insert into t2 select i, i%20, 'Kingbase'||(i%10) from generate_series(1,1000) as x(i);
INSERT 0 1000
5.2 变量替换
5.2.1 示例语句
test=# select id,val from t1 where id<10;
id | val
----+-----
1 | 1
2 | 2
3 | 3
4 | 4
5 | 5
6 | 6
7 | 7
8 | 8
9 | 9
(9 rows)
5.2.2 替换规则
替换语句选择条件,这里将原来的条件$1替换为$1-5,可以执行多种替换,也可以增加,减少,改变语句的选择条件。
test=# SELECT create_query_rule('qm1', 'select id,val from t1 where id<$1','select id from t1 where id<(
test'# $1-5)', true, 'text');--将$1 替换为$1-5
create_query_rule
-------------------
(1 row)
5.2.3 替换效果
test=# select id,val from t1 where id<10;
id
----
1
2
3
4
(4 rows)
5.2 替换操作目标
query mapping的另一个用途是替换操作目标,可以用于数据清理时的场景。有时,数据库里的日志表积累了大量数据,一年之前的数据基本没什么访问需求,而这些日志是随时写入的,直接truncte会影响会影响对日志记录的写入和对当前数据库的访问。这时,query mapping可以派上用场,可以先创建一个空表,把近期的数据导入到空表中,然后用query mapping将对原表的访问改到对新建表的访问。为了减少切换的时间,可以在创建规则时设置规则为不激活,在创建完所有规则后一次性激活。比如,下面的规则,将对表t1的插入操作改到对表T2上
select create_query_rule('qm10', 'insert into t1 values (1001,0)','insert into t2 values (1001,0)',true,'text');
test=# insert into t1 values (1001,0);
INSERT 0 1
test=# select * from t1 where id=1001;
(0 row)
test=# select * from t2 where id=1001;
id | val | name
------+-----+------
1001 | 0 |
(1 row)
5.3 调整SQL语句的hint
hint是SQL语句常用的技巧,大概也是开发最了解的SQL优化技巧之一,在日常的优化中,有使用了hint提高了SQL语句性能的,更常见的是使用了不恰当的hint反而导致优化器不能选择正常的执行计划,反而导致SQL执行性能严重恶化的,下面是一个使用了不恰当的并行hint导致SQL性能恶化的例子
test=# \timing on
Timing is on.
test=# select /*+Parallel(t1 6) */ count(*) from t1;
count
-------
1001
(1 row)
Time: 16.411 ms
语句使用了并行hint,执行计划如下
test=# explain analyze select /*+Parallel(t1 6) */ count(*) from t1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Aggregate (cost=2.50..2.51 rows=1 width=8) (actual time=36.288..38.369 rows=1 loops=1)
-> Gather (cost=0.00..0.00 rows=1000 width=0) (actual time=1.410..38.314 rows=1001 loops=1)
Workers Planned: 6
Workers Launched: 4
-> Parallel Seq Scan on t1 (cost=0.00..0.00 rows=417 width=0) (actual time=0.004..0.021 rows=200 loops=5)
Planning Time: 0.363 ms
Execution Time: 38.898 ms
(7 rows)
语句的并行hint生效了,hint要求的Workers是6个,实际执行了4个(这个数据库的容器只分配了4个CPU),使用query mapping关闭这条语句的并行hint
test=# SELECT create_query_rule(
test(# 'qmtp',
test(# 'select /*+Parallel(t1 6) */ count(*) from t1',
test(# 'select count(*) from t1',
test(# true,
test(# 'text'
test(# );
create_query_rule
-------------------
(1 row)
执行一下语句看看
test=# select /*+Parallel(t1 6) */ count(*) from t1;
count
-------
1001
(1 row)
Time: 0.700 ms
语句的执行时间从16.411 ms降到了0.700 ms,看一下语句的执行计划
test=# explain (usingquerymapping) select /*+Parallel(t1 6) */ count(*) from t1;
QUERY PLAN
------------------------------------------------------------
Aggregate (cost=19.50..19.51 rows=1 width=8)
-> Seq Scan on t1 (cost=0.00..17.00 rows=1000 width=0)
(2 rows)
需要使用usingquerymapping才能显示query mapping生效后的执行计划,query mapping生效后,语句不再执行并行扫描。
6 注意事项
执行query mapping的SQL语句,与未执行之前相比,需要额外执行读取系统表以执行语句的替换,必然对性能造成一定的影响。对于本身执行性能已经恶化的SQL语句,这种性能损耗可以忽略不计。如果是在高并发的执行时间非常短的SQL语句(如 insert,带唯一条件的update),这种性能损耗可能会造成显著的影响。因此,在实施query mapping时,需要审慎的评估场景及其对性能的影响。
