




在企业级数据管理场景中,高效、稳定地将数据导入数据库是业务迁移与数据同步的核心环节。OceanBase 作为分布式关系型数据库,为不同规模的数据文件提供了灵活的导入方案,但大规模数据导入时的字符集匹配、性能优化及资源管理问题,往往需要系统化的解决方案。
本文基于 OceanBase 4.3.5 版本,从字符集配置原理入手,详解 SQL/CSV 文件导入策略、旁路导入技术及 CPU / 内存 / 磁盘资源调优方法,帮助用户在数据导入过程中规避乱码风险、提升导入效率,同时降低数据库资源消耗。
一、字符集和编码
在导入数据之前,需要了解字符集和编码原理,以避免在数据导入后读数据时出现乱码。编码和解码使用不同的规则,或者字符集不匹配将导致乱码。导入数据文件出现乱码,可能是数据存储正确但是读取的编码不正确,也可能是数据存储时编码不正确。
从数据文件自身到读取数据文件、写入到 OceanBase 数据库,每个环节的字符集设置均影响最终数据的正确性。
(一)数据文件的字符集
请确保数据文件使用正确的字符集。在导出数据文件时,以 UTF8 格式保存,这样大部分的字符(特别是中文字符)都能在文件中正确保存。如果数据内容包含表情字符等,在导出数据文件时,以 UTF8MB4 格式保存。
以 Linux 环境为例,查看文件的编码:
file /tmp/test.sql/tmp/test.sql: UTF-8 Unicode text
(二)客户端的字符集
请确保客户端能正确读取数据文件。以下方客户端导入数据文件至 OceanBase 数据库:
🧡 注意:
请确保操作系统的语言包含目标字符集(如简体中文),并且 OceanBase 图形化客户端工具也支持目标字符集。推荐将编码设置为 UTF-8。
可以在 Windows、Linux 或国产操作系统使用图形化工具。如果使用 Linux 系统,请确保 Linux 系统支持目标字符集。使用命令 locale -m 查看系统可用的字符编码方案。GBK 或 UTF-8 均支持中文。推荐使用 UTF-8。如果操作系统不支持 GBK 或 UTF-8,需要安装简体中文对应的语言包。然后在 Shell 环境下设置环境变量 LANG 为 GBK 或 UTF-8。
终端的编码将决定终端中输入中文字符后转换的编码,以及读取中文内容时显示的编码。
使用以下方式设置会话的显示语言和编码:
设置编码export LANG=en_US.UTF-8检查是否设置成功localeLANG=en_US.UTF-8LC_CTYPE="en_US.UTF-8"LC_NUMERIC="en_US.UTF-8"LC_TIME="en_US.UTF-8"LC_COLLATE="en_US.UTF-8"...
(三)OceanBase 租户的字符集
请确保 OceanBase 租户的字符集支持目标字符集。可以在创建租户时指定租户的字符集。推荐将字符集设置为 UTF8MB4。这样在任何一个客户端环境出现中文乱码的概率最低,因为上文已建议将客户端操作系统以及客户端工具的字符集编码均设置为 UTF-8。
👉 如果使用的是 Oracle 租户,则租户的数据表的字符集都是租户初始化时指定的字符集,不可以改变。
👉 如果使用的是 MySQL 租户,在创建数据库或者建表时可以改变字符集。此操作仅影响数据库中后续的表或当前表。
MySQL 的字符集参数比较复杂,推荐将 MySQL 租户的字符集设置为 UTF8MB4。以下示例新建了一个 MySQL 租户,字符集选择 GBK。GBK 支持中文正常读写。
🙋♀️ 说明:
此示例仅说明原理,生产中不常用。
虽然租户字符集选择了 GBK,上文提到客户端程序以及 Linux 环境变量中的字符集编码均设置为 UTF-8(因为 UTF-8 能兼容 GBK)。假设还想创建一个字符集是 UTF8MB4 的数据库 test2。
CREATE DATABASE test2 CHARACTER SET = utf8mb4;Query OK, 1 row affected (0.111 sec)USE test2;Database changedCREATE TABLE t1(id bigint, c1 varchar(50));Query OK, 0 rows affected (0.163 sec)INSERT INTO t1 VALUES(1,'中');Query OK, 1 row affected (0.049 sec)SHOW FULL COLUMNS FROM t1;+-------+-------------+--------------------+------+-----+---------+-------+---------------------------------+---------+| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |+-------+-------------+--------------------+------+-----+---------+-------+---------------------------------+---------+| id | bigint(20) | NULL | YES | | NULL | | SELECT,INSERT,UPDATE,REFERENCES | || c1 | varchar(50) | utf8mb4_general_ci | YES | | NULL | | SELECT,INSERT,UPDATE,REFERENCES | |+-------+-------------+--------------------+------+-----+---------+-------+---------------------------------+---------+2 rows in set (0.004 sec)SELECT id, c1, hex(c1) FROM t1;+------+------+---------+| id | c1 | hex(c1) |+------+------+---------+| 1 | 中 | E4B8AD |+------+------+---------+1 row in set (0.006 sec)SHOW VARIABLES LIKE '%character%';+--------------------------+---------+| Variable_name | Value |+--------------------------+---------+| character_sets_dir | || character_set_client | utf8mb4 || character_set_connection | utf8mb4 || character_set_database | utf8mb4 || character_set_filesystem | binary || character_set_results | utf8mb4 || character_set_server | gbk || character_set_system | utf8mb4 |+--------------------------+---------+8 rows in set (0.004 sec)
从返回结果看出,虽然租户字符集是 GBK,但是有多个字符集变量值是跟随客户端环境的,值为 UTF8MB4。变量的作用如下:
👉 character_set_client:客户端发送的查询数据的字符集。
👉 character_set_connection:客户端与服务器连接时的数据字符集。
👉 character_set_results:服务器返回给客户端结果时使用的字符集。
👉 character_set_server:服务器存储数据时使用的字符集。
character_set_results 决定查询结果集中的数据编码方式。character_set_results 默认与 character_set_connection 保持一致。也可以单独设置 character_set_results,以在返回数据时使用不同的字符集。
上述示例未出现乱码。如果在导入数据过程中遇到了乱码,请参考上述示例分析哪个环节的字符集编码设置不正确,从而导致字符数据传输过程中发生了编码转换错误。要识别是不是转换错误,需要关注显示的字符以及字符对应的编码。在 MySQL 租户中使用 hex 查看,在 Linux Shell 中命令使用 xxd 查看。
二、数据导入准备
为提高导入性能,请确保待导入数据的目标表除了主键外,不包含索引和其他约束。可以在数据导入成功后创建索引和约束。但是,如果数据文件是目标表的增量数据,且表包含唯一约束或索引,必须提前建好约束或索引。
三、数据导入方案
数据导入方案跟数据文件格式和位置有关。常见数据文件格式为 SQL 和 CSV。SQL 文件包括 DDL 和 DML。
(一)SQL 文件导入
SQL 文件可能包含 DDL 和 DML。推荐将 DDL 和 DML 文件分开。可以通过 OceanBase 的客户端命令 OBclient 调用执行 SQL 文件。如果使用的是 MySQL 租户,也可以使用 MySQL 调用执行。此外,有些图形化客户端工具,例如 ODC 和 DBeaver,也可以执行 SQL 文件。
例如,使用以下命令执行 SQL 文件:
obclient -h27.0.0.1 -uroot@obmysql -P2883 -p******** -c -A test < /tmp/test.sql或使用命令行执行 SQL 文件:
连接到 OceanBase 数据库obclient -h27.0.0.1 -uroot@obmysql -P2881 -p -c -A test在 OceanBase 数据库执行以下命令source /tmp/test.sqlQuery OK, 1 row affected (0.003 sec)
如果 SQL 文件是通过 OceanBase 工具 OBDumper 导出的,也可以通过工具 OBLoader 导入到 OceanBase 租户数据库中。更多信息,参考官网 OBLoader 使用文档。
(二)CSV 文件导入
可以使用 OceanBase 的客户端工具 OBLoader 或者 SQL 命令 load data [local] infile 导入 CSV 文件。
在导入 CSV 文件之前,请检查:
1️⃣ CSV 文件格式是否正确。
2️⃣ 文件首行是否包含列标题。请确保数据导入到对应的列。如果数据错位,可能会因为类型不对而报错。如果数据文件中的列跟目标列无法映射,需要在导入命令中指定列映射。如果使用的是 OBLoader,指定控制文件。如果使用的是 load data,指定列名。
3️⃣ 导入数据时允许的最大报错行数。如果报错数量超出允许的最大报错行数,数据导入将报错。
4️⃣ 日期和时间类型数据的格式。在导入日期和时间类型的数据时,需要将 OceanBase 数据库的时间格式变量(如 MySQL 租户的 datetime_format 和 time_format)调整为与数据文件的时间列格式,以避免时间数据(字符串格式)写入到时间列(如 date、time 或 datetime 等)类型转换报错。如果不能调整租户的时间格式变量,请在导入命令 OBLoader 的控制文件里对列使用预处理函数。load data 命令不支持对列使用预处理函数。
OBLoader
CSV 文件的位置影响导入方案。如果文件不在 OBServer 可以访问的位置,可以使用导入工具 OBLoader。OBLoader 支持从本地、S3 和 HDFS 读取文件。
以下示例演示从一个 OceanBase 数据库租户中导出大表并导入到另外一个租户。为了提升性能,此处直连 OBServer 节点。
导出数据bin/obdumper -hxx.x.x.1 -P 2881 -utemp01@obmysql -p'**********' -D testdb --table 'big_table' --csv -f /data/obdumper/20240801 --skip-check-dir --thread 64导入数据bin/obloader -hxx.x.x.2 -P 2881 -utemp02@obmysql -p'**********' -D testdb --table 'big_table' --csv -f /data/obdumper/20240801 --parallel=16 --truncate-table
推荐选择目标表主副本所在的节点作为直连节点。如果目标表是单表,这个方式性能最好。如果目标表是个分区表并且多个分区主副本位于多个节点,选择任意一个节点写入都可能产生 OBServer 二次路由。导入性能还跟目标表的分区策略以及数据文件中数据分布特征有关。如果不想关注目标表的主副本节点位置,可以通过 ODP 连接 OceanBase 租户数据库。
参数 --truncate-table 在数据导入之前清空原表数据,否则就会追加数据。
load data
如果 CSV 文件位于 OceanBase 租户的节点服务器上,可以直连 OBServer 节点并使用 load data infile 命令从服务器端加载文件。在导入之前,还需要通过 socket 直连到 OBServer 节点并设置租户全局变量 secure_file_priv 值。这个值是一个目录,它必须包含需要导入的文件目录。
以下是通过 OceanBase 业务租户的任意一个 OBServer 节点上的 socket 文件直连的示例。
连接 OceanBase 业务租户obclient -S ~/oceanbase/run/sql.sock -uroot@obmysql -P2881 -p -c -A oceanbase
-- 设置租户全局变量 `secure_file_priv`SHOW GLOBAL VARIABLES LIKE '%secure_file_priv%';+------------------+-------+| Variable_name | Value |+------------------+-------+| secure_file_priv | |+------------------+-------+1 row in set (0.004 sec)SET GLOBAL secure_file_priv = '/data';Query OK, 0 rows affected (0.114 sec)SHOW GLOBAL VARIABLES LIKE '%secure_file_priv%';+------------------+-------+| Variable_name | Value |+------------------+-------+| secure_file_priv | /data |+------------------+-------+1 row in set (0.002 sec)
如果 CSV 文件不在 OceanBase 租户的节点服务器上,则直连 OBServer 或通过 ODP 连接租户并使用命令 load data local infile 命令从客户端加载文件。后者是客户端工具 obclient读取文件并通过网络发送给 OceanBase 服务端。OBClient 在启动的时候需要带上参数 --local-infile 以启用加载本地数据的功能。
示例命令如下:
load data /*+ parallel(12) append */ local infile '/data2/tpch/s100/lineitem.tbl.*' into table lineitem fields terminated by '|';如果 CSV 文件位于对象存储,可以通过 ODP 连接租户并使用命令 load data remote_oss infile 从对象存储中加载文件。对象存储目前支持阿里云 OSS(地址协议头:oss://)、腾讯云 COS(地址协议头:cos://)和 S3 协议的对象存储(地址协议头:s3://)。需要在对象存储的路径里指定访问地址(host)、访问账户(access_id)和访问密码(access_key)。
此外,如果 CSV 文件位于对象存储,还可以在 OceanBase 数据库中创建基于这组 CSV 文件的外部表,通过外部表直接读取 CSV 内容,然后通过 INSERT INTO ... SELECT ... FROM ... 命令将 CSV 文件读取到目标表中。
在使用 load data 导入数据时,如果目标表已有存在数据(有主键或唯一键),使用参数 replace 或 ignore 设置是替换数据还是忽略新数据。如果没有主键或唯一键,可以忽略两个参数。数据导入中报错的数据会记录到日志文件中。日志文件默认会在 OceanBase 软件目录下的 log 目录(/home/admin/oceanbase/log/)中。大批量的导入任务也会导致这个目录下日志文件增多。如果有大量导入报错,请留意这个日志文件的大小。
四、性能调优
针对大规模数据导入(>100G)的性能优化需要采取灵活的平衡策略。导入速度过慢会延长等待时间,影响业务进度,而导入速度过快可能造成 OceanBase 资源过度消耗。建议在保证系统稳定的前提下优化导入性能。此处的资源分为三类:CPU、内存和磁盘。
(一)CPU 资源分析和优化
同一个租户内部默认所有会话的 CPU 资源使用是平等的,在 CPU 调度上,OceanBase 租户会将队列分为两个:一个用于满足快的 SQL 请求,一个用于满足慢的 SQL 请求。快和慢的分界点是集群参数 large_query_threshold(默认值是 5s)。慢队列的 CPU 使用比例上限由集群参数 large_query_worker_percentage(默认值是 30,表示 30%)决定。在 OceanBase 4.X 版本中,默认使用 cgroup 做租户之间的 CPU 资源隔离。在某些客户场景里,可能会关闭 cgroup 功能,此时通过集群参数 enable_cgroup 来控制。这个参数设置为 false 的时候,就退回到 OceanBase 4.0 以前的版本资源隔离方式。数据导入会话使用的是目标租户的 CPU 资源。在不开启并行导入的情况下,就是一个单线程会话,对租户 CPU 使用不会很大(跟其他业务会话公平竞争)。
(二)内存资源分析和优化
在使用 OceanBase 数据库时,需要关注租户的内存管理机制。每个租户的所有会话分配的总内存都受限于其内存配额。当数据导入速度过快时,会导致单位时间内的内存消耗剧增,从而挤压了业务事务可用的内存空间。虽然 OceanBase 的 MemStore(写内存)管理机制具有一定的灵活性 - 当内存使用超过预设的 freeze_trigger_percentage 阈值时,系统会自动将部分数据冻结并转储到磁盘,释放内存空间。但是,如果数据写入速度远超过内存转储速度,MemStore 的使用率仍可能趋近 100%。这种情况下,业务事务和数据导入会话都可能遇到 -4002 错误。同时,数据导入任务也会报错。为了及时发现潜在问题,建议持续监控租户的 MemStore 内存使用情况。
推荐使用 OCP 监控租户性能的 MemStore 指标图。
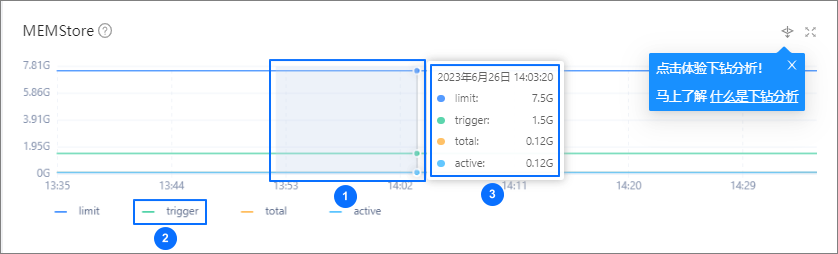
OceanBase 数据库提供写入限速功能。写入限速通过writing_throttling_trigger_percentage 和 writing_throttling_maximum_duration(默认为 2 小时)控制。需要,在 4.2 和 4.3 版本中,由于 writing_throttling_trigger_percentage 的默认值为 100,这一保护机制实际上并未发挥作用。为了预防 MemStore 内存耗尽,推荐将该参数值调整至 90 左右,具体的参数设置可以根据租户内存大小灵活调整。内存较大的租户可以适当提高这个值,而内存较小的租户则应该相应降低。参数的最终设定应当基于对数据导入时内存消耗速度的合理评估。
数据导入性能调优的核心方法之一是优化内存 MemStore 相关参数:
👉writing_throttling_trigger_percentage:控制数据转储的触发阈值。较大的转储量会增加 IO 开销,导致写入性能出现较大波动且持续时间更长。过早转储可以预留更多内存空间,但会增加转储频率造成资源浪费。推荐根据业务负载特点设置合适的阈值。
👉writing_throttling_trigger_percentage:决定写入限速的触发点。设置过低会导致过度限速,影响写入性能并浪费内存资源,设置过高可能引发内存不足错误。推荐通过压测确定最优阈值,在性能和稳定性之间取得平衡。
👉memstore_limit:用于控制租户内存中 MemStore 的占比,默认为 50,写密集型业务可适当提高此值。
🧡 注意:
✅ 参数调整会影响所有租户,需要全局评估。
✅ 对于小内存(小于 8G)租户,大型查询可能挤占 MemStore 空间导致参数失效。
(三)磁盘资源分析和优化建议
OceanBase 数据库在转储过程中会将内存数据写入磁盘文件,默认采用 lz4 压缩算法。系统每天执行一次 Major Freeze 合并操作,将最近 24 小时的内存增量数据、磁盘增量数据以及上一次合并的基线数据进行合并,生成新的基线版本。这些操作会占用磁盘空间,且由于数据多版本存储特性可能导致空间放大。虽然合并操作仅针对发生变化的数据块,但在进行大批量数据导入时,仍可能造成大量的数据合并,从而导致数据文件存储空间暂时增长。如果数据文件剩余空间不足,系统将报告空间错误。OceanBase 数据库支持通过 datafile_maxsize 和 datafile_next 参数控制数据文件自动扩展。在 OCP 默认部署的集群中,这两个参数未配置。因此对于初始配置较小的数据文件(datafile_size),推荐在文件系统空间充足的情况下启用自动扩展功能。而对于初始配置较大的数据文件则无需此设置。这也是企业级部署的典型特征:配置大容量初始数据文件并关闭自动扩展。
在转储和合并过程中,系统使用不同的压缩算法。转储过程生成的中间版本数据块采用 lz4 算法,而合并后的最终版本数据块使用 ZSTD 算法。由于 lz4 算法的压缩比相对较低(但 CPU 资源消耗较少),中间数据会占用更多存储空间。因此在评估系统所需剩余容量时,需要考虑这一因素带来的临时空间增长。
可以使用 OCP 查看 OceanBase 的租户空间,但是 OCP 有延迟。也可以在集群的 SYS 租户下,使用以下 SQL 实时查看一个表在所有节点上所有版本的数据大小。
WITH table_locs AS (SELECTt.tenant_id,t.database_name,t.table_id,t.table_name,t.table_type tablet_type,t.tablet_id,REPLACE(concat(t.table_name,':',t.partition_name,':',t.subpartition_name),':NULL','') tablet_name,t.tablegroup_name,t.ls_id,t.ZONE,t.ROLE,t.svr_ipFROMoceanbase.CDB_OB_TABLE_LOCATIONS tWHEREt.data_table_id IS NULLUNIONSELECTi.tenant_id,i.database_name,i.table_id,t.table_name,i.table_type tablet_type,i.tablet_id,REPLACE(REPLACE(concat(i.table_name,':',i.partition_name,':',i.subpartition_name) ,concat('__idx_', i.data_table_id, '_'),''),':NULL','') tablet_name,i.tablegroup_name,i.ls_id,i.ZONE,i.ROLE,i.svr_ipFROMoceanbase.CDB_OB_TABLE_LOCATIONS iINNER JOIN oceanbase.__all_virtual_table t ON( i.tenant_id = t.tenant_idAND i.data_table_id = t.table_id )WHERE i.data_table_id IS NOT NULL)SELECTt.database_name,t.ls_id,t.ROLE,t.svr_ip,t.table_name,t.tablet_name,-- group_concat(s.table_type,',') tablet_types,round(sum(s.size)/1024/1024/1024,2) size_gbFROMtable_locs t JOIN oceanbase.GV$OB_SSTABLES sON (t.tenant_id=s.tenant_id AND t.ls_id=s.ls_id AND t.svr_ip=s.svr_ip AND t.tablet_id=s.tablet_id)WHEREt.tenant_id = 1004AND t.database_name IN ('tpccdb')AND t.table_name IN ('bmsql_stock2')AND s.table_type NOT IN ('MEMTABLE')-- AND t.ROLE IN ('LEADER')GROUP BYt.database_name,t.ls_id,t.ROLE,t.svr_ip,t.table_name,t.tablet_nameWITH ROLLUPORDER BYt.database_name,t.ls_id,t.ROLE,t.svr_ip,t.table_name,t.tablet_name;
还需要关注数据导入对磁盘性能的影响。这种影响体现在两个方面:内存数据转储和合并过程中的顺序写 IO,这种操作是间歇性的,OceanBase 事务日志(clog)的持续化也是顺序写小 IO。当数据文件和事务日志文件部署在 NVMe SSD 存储上时,可以忽略 IO 影响。如果发现 IO 压力过大,可以通过降低数据导入速度来缓解。OCP 提供实时磁盘 IO 性能监控,可以据此进行精确评估和调整。
(四)参数建议
1、OBLOADER 参数经验值:
-- batch 该选项的参数值不宜设置太大,默认 200。--thread 建议该选项的参数值等于 2 倍的逻辑核心数,默认 2*CPU。--rw 解析线程与写入线程的比例。解析线程的数量等于 --thread * 0.2,默认 0.2。
2、OceanBase 集群参数经验值:
-- 必设的系统变量和参数set global max_allowed_packet=1073741824; -- 设置为 1GBset global ob_sql_work_area_percentage=30; -- 默认值:5alter system set freeze_trigger_percentage=30; -- 默认值:70-- 选设的系统变量和参数alter system set enable_syslog_recycle='True'; -- 默认值:falsealter system set max_syslog_file_count=100; -- 默认值:0alter system set minor_freeze_times=500; -- 默认值:5alter system set minor_compact_trigger=5; -- 默认值:5alter system set merge_thread_count=45; -- 默认值:0alter system set minor_merge_concurrency=20; -- 默认值:0alter system set writting_throttling_trigger_percentage=85; -- 默认值:10alter system set flush_log_at_trx_commit=0; -- 默认值:1alter system set syslog_io_bandwidth_limit=100; -- 默认值:30MB
🙋♀️ 说明:
在数据导入后,将系统变量和参数务重新修改为默认值。
(五)并行导入
提升数据导入效率的主要方法是增加并发度。OBLoader 和 load data 命令都支持设置并行加载任务数。OBLoader 支持同时使用程序多线程并行和 SQL 并行加载。
在使用 OBLoader 时,可以通过设置 --thread 和 --parallel 参数实现并行加载。其中,--parallel 参数用于配置 SQL 并行加载,需要与旁路导入参数 --direct 配合使用。
bin/obloader -h 10.0.0.65 -P 2883 -u TPCH -t oboracle -c OB4216 -p ******** --sys-password aaAA11__ -D TPCH --table LINEITEM --external-data --csv -f /data/1/tpch/s4/bak/ --truncate-table --column-separator='|' --thread 16 --rpc-port=2885 --direct --parallel=16(六)旁路导入
OceanBase 数据库支持旁路导入,旁路导入有如下特点:
👉 绕过常规 SQL 层的大部分接口。
👉 数据直接写入数据文件,而不经过租户的 MemStore 内存。
👉 通过 KV Cache 中的内存缓冲区写入数据文件。
👉 由于写入路径更短,在大批量数据插入时性能更好。
当执行旁路导入时,客户端程序(OBClient、OBLoader 或 Java 程序)需要通过 OBServer 的 RPC 端口(默认 2882)发送 SQL。当使用 OBProxy 转发连接时,需要同时开通 OBProxy 的 RPC 端口(默认 2885)。虽然也可以通过负载均衡设备访问并开通 OBProxy 的 RPC 端口转发,但由于旁路导入会产生大量网络流量,可能影响其他应用的网络带宽使用,因此推荐大批量数据导入时直接连接固定的 OBProxy。
要为 OBLoader 命令开启旁路导入,需要指定以下参数:
👉 --rpc-port=:指定连接的 OBProxy 或 OBServer 的 RPC 端口。
👉 --direct :开启旁路导入。
👉 --parallel=:可选,指定旁路导入时 OBServer 内部并行度。
要为 OBClient 命令行下 INSERT SQL 或 load data 要开启旁路导入,需要添加以下 Hint:
👉 append:等效于 direct(true,0)。同时可以在线收集统计信息,相当于 GATHER_OPTIMIZER_STATISTICS。
👉 direct(bool, int, [load_mode]:bool 表示数据写入时是否排序(true:数据排序;false:数据不排序)。int 表示最大容忍报错行数,load_mode 可选,表示导入模式,默认值 full 表示全量导入,新增功能值 inc 表示增量导入(支持 insert ignore),新增功能值(inc_replace)表示增量导入,但不检查主键重复,相当于 replace(跟 ignore 冲突)。
👉 enable_parallel_dml parallel(N):可选,表示加载数据的并行度。
以下是 INSERT SQL 使用旁路导入示例:
INSERT /*+ DIRECT(true, 0, 'full') enable_parallel_dml parallel(16) */ INTO big_table2 SELECT * FROM big_table ;在 4.3.5 版本中,OceanBase 数据库支持在租户全局级别设置默认数据加载模式,这样上面的 SQL 就不用写旁路导入相关的 Hint。
ALTER SYSTEM SET default_load_mode ='FULL_DIRECT_WRITE';重新登录。
INSERT INTO big_table2 SELECT * FROM big_table;旁路导入不使用 MemStore 而是使用独立的内存空间,因此与普通数据导入的内存使用特点有所不同。在使用旁路导入时,需要确保分配足够的 KV Cache 内存,以防出现内存不足。另外,由于旁路导入会直接写入数据文件且数据压缩比较低,因此数据文件会快速增长,建议提前预留充足的数据文件存储空间。
旁路导入要求会话 SQL 不能在事务中。
BEGIN;Query OK, 0 rows affected (0.001 sec)INSERT /*+ append enable_parallel_dml parallel(4) */ INTO bmsql_oorder2 SELECT * FROM bmsql_oorder;ERROR 1235 (0A000): using direct-insert within a transaction is not supported
五、实践案例
本节将以导入 TPC-H 的表 LINEITEM 为例,介绍如何导入数据至 OceanBase 数据库。
1、环境介绍。业务租户为 4C7G ,MEMTABLE 内存比例 50%,转储参数比例 70%,写限速比例 90%。
2、准备数据。将导入 TPC-H 中最大的表 LINEITEM。数据规模 scale 设置为 4。数据记录数为 23996604。数据文件信息如下:
ls -lrth /data/1/tpch/s4/bak/LINEITEM.*-rwxr-xr-x 1 admin admin 325M Jul 16 11:48 /data/1/tpch/s4/bak/LINEITEM.1.csv-rwxr-xr-x 1 admin admin 326M Jul 16 11:48 /data/1/tpch/s4/bak/LINEITEM.2.csv-rwxr-xr-x 1 admin admin 326M Jul 16 11:48 /data/1/tpch/s4/bak/LINEITEM.3.csv-rwxr-xr-x 1 admin admin 327M Jul 16 11:48 /data/1/tpch/s4/bak/LINEITEM.4.csv-rwxr-xr-x 1 admin admin 328M Jul 16 11:49 /data/1/tpch/s4/bak/LINEITEM.5.csv-rwxr-xr-x 1 admin admin 329M Jul 16 11:49 /data/1/tpch/s4/bak/LINEITEM.6.csv-rwxr-xr-x 1 admin admin 329M Jul 16 11:49 /data/1/tpch/s4/bak/LINEITEM.7.csv-rwxr-xr-x 1 admin admin 329M Jul 16 11:49 /data/1/tpch/s4/bak/LINEITEM.8.csv-rwxr-xr-x 1 admin admin 329M Jul 16 11:49 /data/1/tpch/s4/bak/LINEITEM.9.csv
3、将数据导入至 OceanBase 数据库。使用以下命令,将数据导入至 OceanBase 数据库:
旁路导入:
bin/obloader -h xx.x.x.xx -P 2883 -u TPCH@oboracle#OB4216 -p -D TPCH --table LINEITEM --external-data --csv -f /data/1/tpch/s4/bak/ --truncate-table --column-separator='|' --thread 16 --rpc-port=2885 --direct --parallel=16旁路导入不是连接 OBServer 的 SQL 端口(默认 2881)而是连接 RPC 端口(默认 2882)。OBLoader 如果绕过 ODP 而直连 OBServer,通过额外指定 RPC 端口即可实现旁路导入。ODP 4.3.0 的 RPC 端口是 2885。但是生产中不推荐客户端绕过 ODP。因为原本业务数据的主副本位置对应用客户端是透明的(客户端不需要知道数据在哪个 OBServer 节点上,ODP 会负责 SQL 路由)。直连 OBServer 旁路写入数据,如果主副本不在这个节点,将产生跨机事务。
非旁路导入:
bin/obloader -h xx.x.x.xx -P 2883 -u TPCH@oboracle#OB4216 -p -D TPCH --table LINEITEM --external-data --csv -f /data/1/tpch/s4/bak/ --truncate-table --column-separator='|' --thread 16 以上命令均将 /data/1/tpch/s4/bak/ 目录下所有已支持的 CSV 数据文件导入到表 LINEITEM 中。如果数据文件大小为 TB 以上,请使用旁路导入提高效率。配合更大的租户资源规格,效率将更高。
更多信息,可通过下方链接,参考旁路导入。
https://www.oceanbase.com/docs/common-oceanbase-dumper-loader-1000000001189498
综上所述,OceanBase 数据库的数据导入是一个涉及字符集管理、方案选择、参数调优的系统性工程。通过合理配置租户与客户端字符集、选择适配的导入工具(如 obloader、load data)、优化 MemStore 与并行导入参数,以及灵活运用旁路导入技术,可显著提升大规模数据导入的效率与稳定性。建议在生产环境导入前,先通过小批量数据测试验证方案可行性,并结合 OCP 监控工具实时跟踪资源消耗。如需进一步了解特定场景的优化细节,可参考 OceanBase 官网文档获取更多技术支持。
