




随着 DeepSeek 不断爆火,越来越多的个人和企业都在搭建属于自己行业或自己的私域知识库,那么我们应该怎么使用 DeepSeek 来搭建只属于自己的私域知识库呢,其实不难,就让我们来一探究竟。
基于 DeepSeek 搭建个人私域知识库的流程图如下所示:
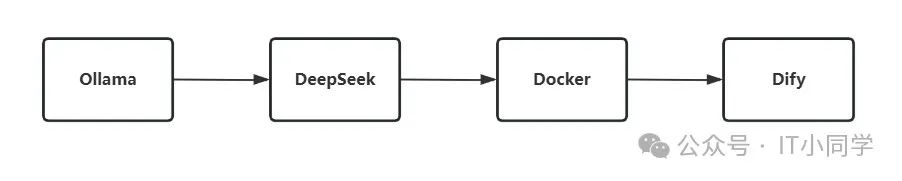
图 1 DeepSeek 模型搭建层流程拆解
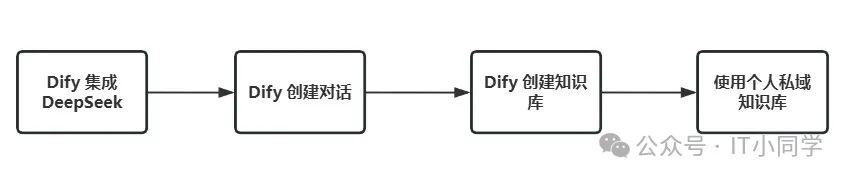
图 2 知识库应用层流程拆解
首先,我们来完成私域知识库需要的模型层的搭建工作。
Ollama 的安装和 DeepSeek 模型的下载和使用,均在我微信公众号之前的文章中有提到,还有不清楚怎么操作的同学请移步至此:全网免费!如何本地化部署 DeepSeek
然后就是安装 Docker,我以 Windows 系统为例,安装 Docker 的话,需要访问 Docker 的官网(https://www.docker.com/),选择对应操作系统的 Docker 进行下载和安装,如下图 3 所示。值得注意的是,Windows 系统安装的是 Docker Desktop Manager 版本,Mac OS 和 Linux 系统推荐安装费图形化界面版本,这是出于不同操作系统的优势来考虑的。
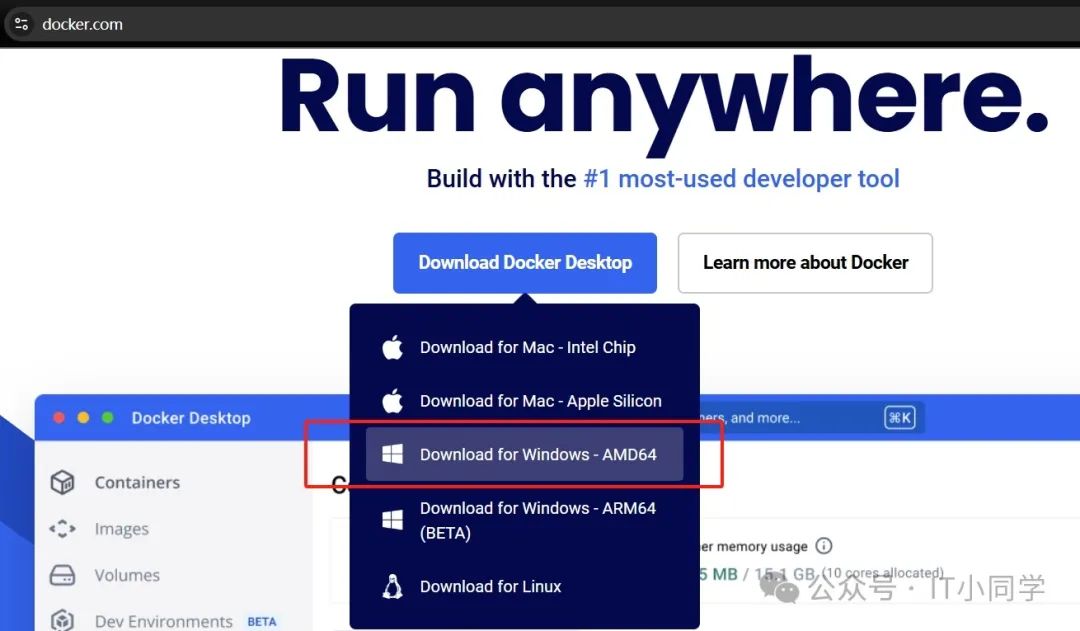
图 3 Docker 下载
点击上图 3 中的红框部分,即可自动开始下载 Docker ,我们需要等待 Docker 下载完毕之后,双击打开 exe 安装包,然后一路 next 安装结束即可。
安装完 Docker 之后,双击打开,我们会看到如下图 4 所示的 Docker 界面:
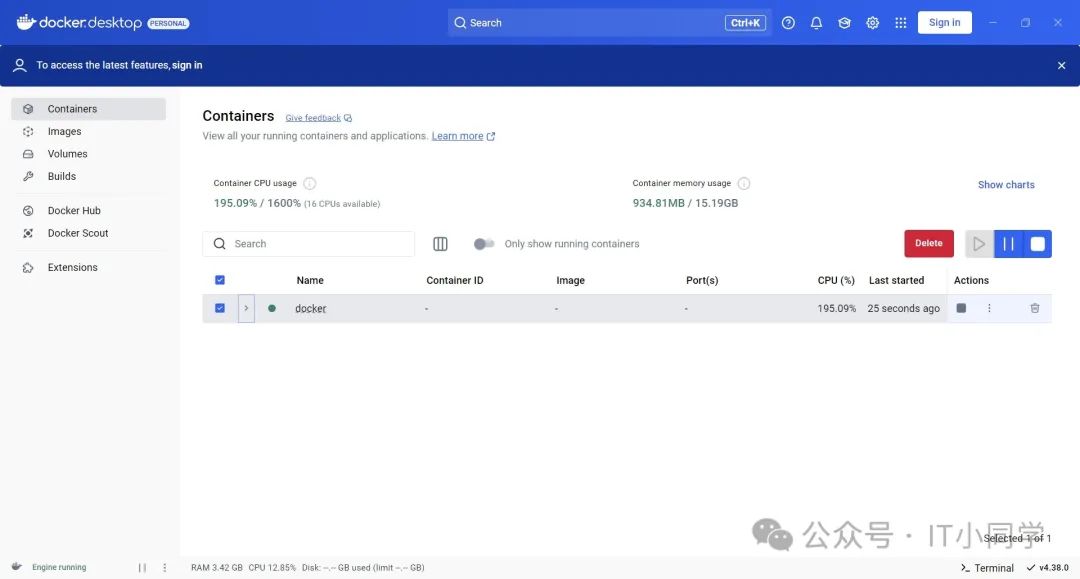
图 4 Docker-Widows 主页
如果在 Docker 时,提醒登录,我们可以直接跳过,不需要登录也能使用。
打开 Docker 之后,我们需要安装 Dify ,因为 Dify 是依赖于 Docker 的,如果没有 Docker ,我们是无法使用 Dify 的。
接着,我们需要创建一个空的文件夹,随便找一个剩余空间比较大的硬盘就行,要给 Dify 留出充足的空间,大概 10GB 左右吧。
然后打开命令行,Windows 系统推荐使用 Git Bash,然后依次执行下述命令:
git clone https://github.com/langgenius/dify.gitcd dify/dockercp .env.example .envdocker compose up -d # 如果版本是 Docker Compose V1,使用以下命令:docker-compose up -d
执行完上述命令之后,如果控制台没有报错,且能看到下图 5 中显示的 Container 信息,说明 Dify 已经安装成功了。
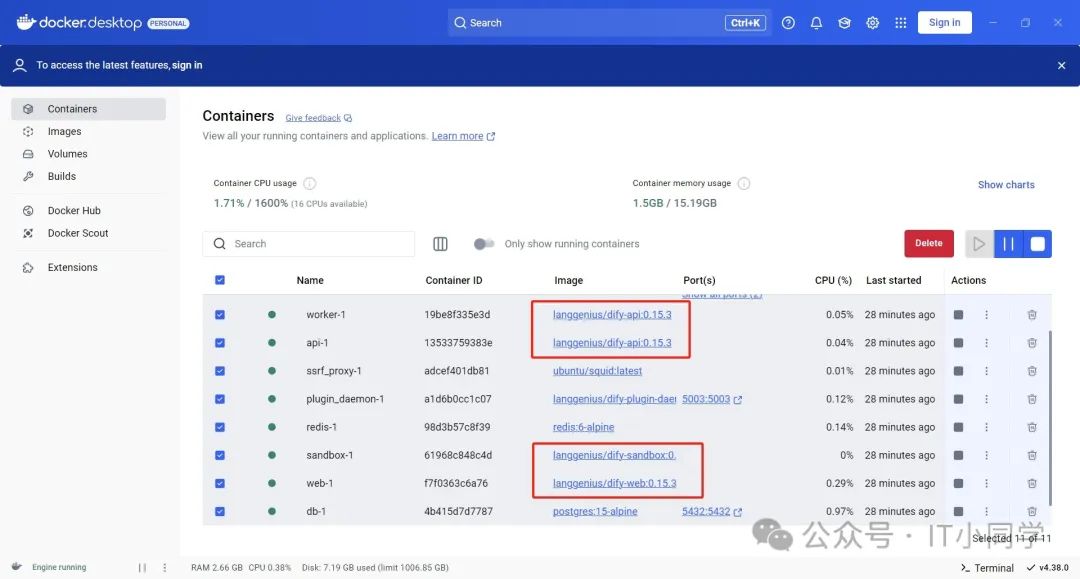
图 5 Dify 在 Docker 中的运行详情
最后,我们来完成使用 DeepSeek 在 Dify 中搭建自己的私域知识库的工作。
Win + R 快捷键,打开 Windows 命令行,然后输入 ipconfig -all 命令,查看自己本机的 ip 地址,复制该地址,然后粘贴到浏览器地址栏中,即可访问到 Dify 的登录首页页面,首次访问需要我们先注册,注册完成之后,即可登录,如下图 6 所示:
图 6 Dify 登录首页
登录进去之后,在 Dify 首页的右上角用户头像位置,选择设置,进入到设置界面,如下图 7 所示:
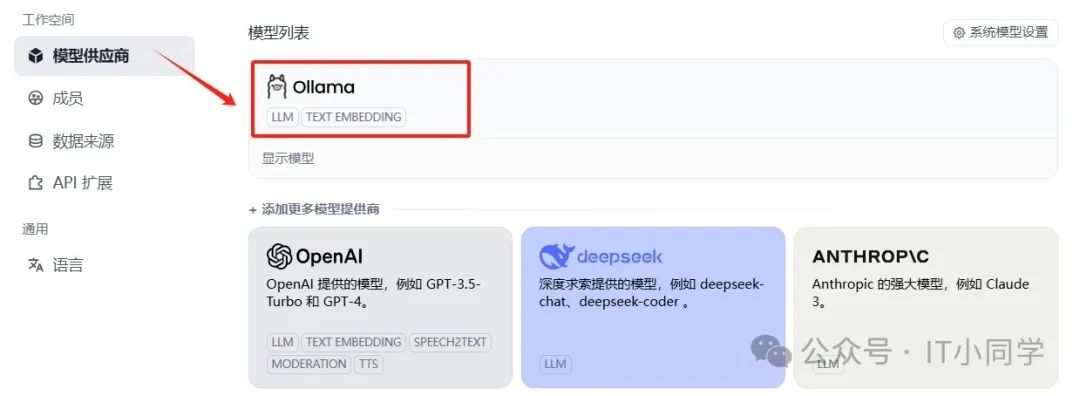
图 7 模型供应商选择
进入到设置界面之后,选择左侧的模型供应商,并且在右侧的添加更多模型提供商列表中,选择 Ollama ,注意选择的是 Ollama 不是 DeepSeek,这里要注意一下。然后点击添加模型按钮,填入必要的信息,如下图 8 所示:
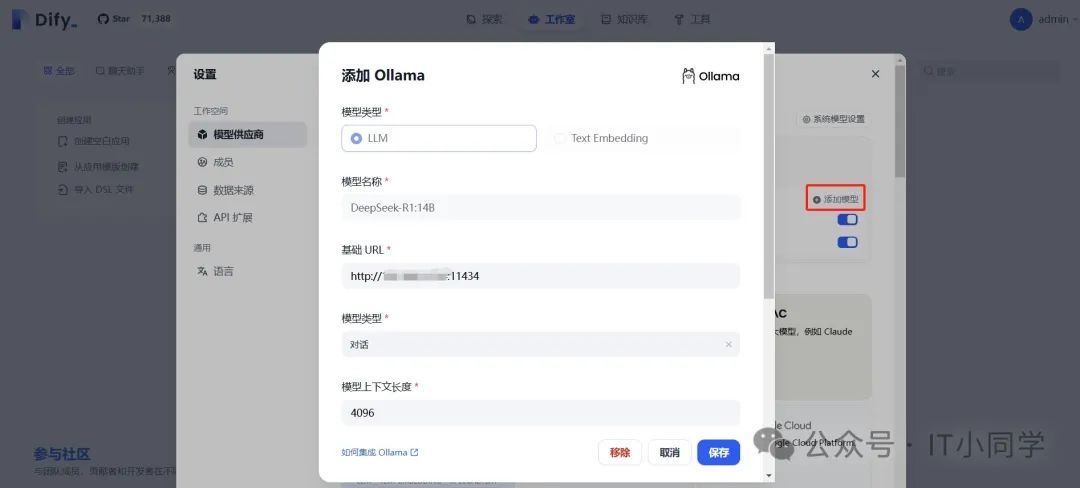
图 8 添加 Ollama 模型
模型名称对应的是我们 Ollama 中已经下载部署好的模型名称,不区分大小写;基础 URL 是 Ollama 映射出的模型后台服务地址,默认端口号是 11434;模型类型选择对话。剩下的其余参数可使用默认配置, 但是 IT 小同学建议将下图 9 红框中的配置打开,以获取更好的性能:
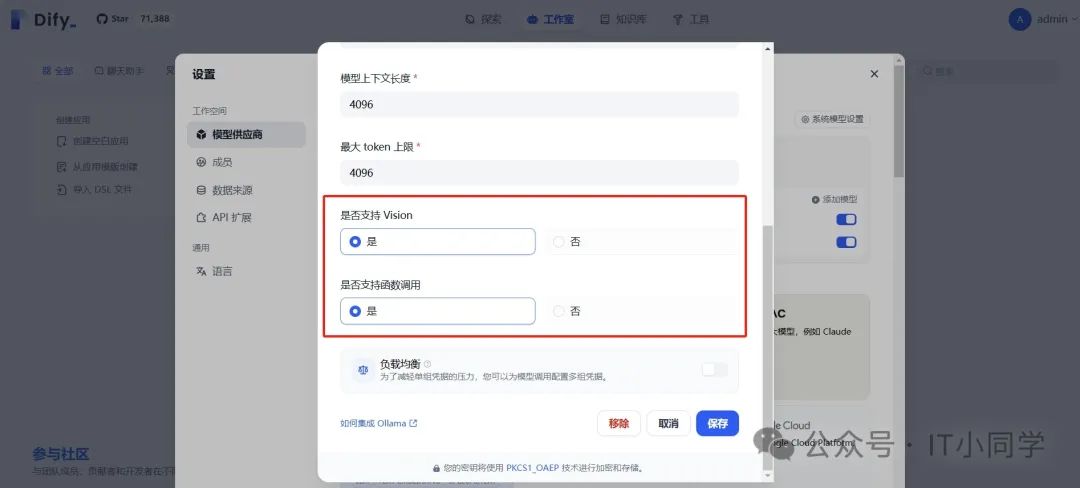
图 9 修改 Dify-Ollama 模型的默认配置项
全部配置完以后,点击保存,即可完成 DIfy 与 DeepSeek 模型的嵌入工作,也就是 Dify 已经集成了 DeepSeek 模型。
我们还需要部署一种模型,就是 TEXT_EMBEDDING 模型,这种模型可将我们上传的知识库文件转换成纯文本大语言模型可识别的向量词,然后传递给我们的大模型进行分析,所以,这个模型是必须要安装的,否则,我们就无法使用我们的知识库。
运行以下命令,以安装 TEXT_EMBEDDING 大模型 bge-m3:
ollama pull bge-m3
安装好 TEXT_EMBEDDING 模型之后,接下来就可以创建我们的 ChatBot 了。
回到 DIfy 工作室,点击创建空白应用,会弹出应用创建对话框,随便填写个名字即可,如下图 10 所示:
图 10 Dify 创建空白应用
点击创建按钮,会进入到应用的调试界面,如下图 11 所示:
图 11 Dify 应用调试界面
在应用调试界面的右上角,需要选择我们刚刚集成好的 DeepSeek 模型,参数配置不需要额外配置,使用默认的即可。 然后我们可以随便问个问题,来测试我们集成的 DeepSeek 模型是否可用,如下图 12 所示:
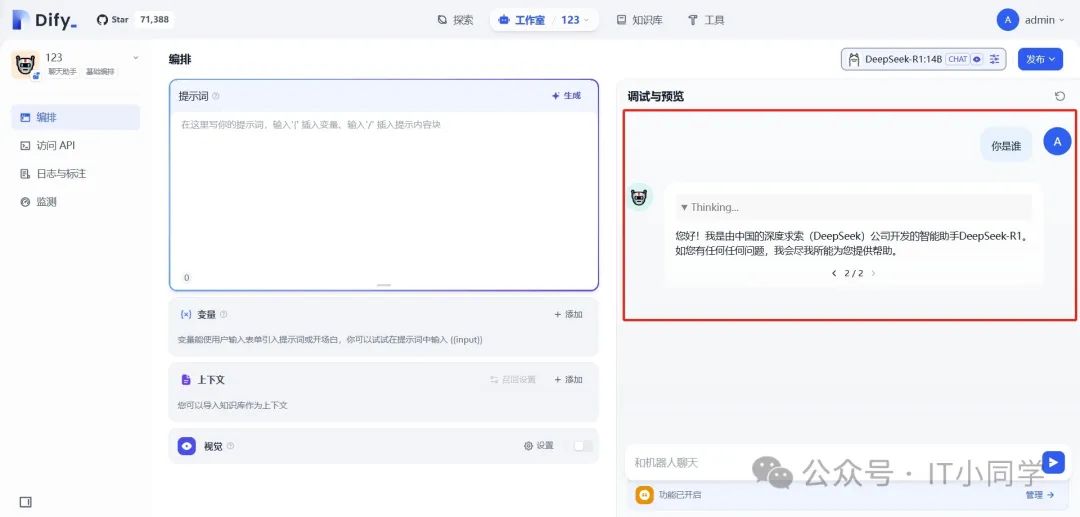
图 12 测试 Dify-DeepSeek 模型是否可用
只要 Dify 给了我们回复,就表示我们集成到 Dify 的 DeepSeek 模型是可用的。
接着,我们来配置我们的知识库,选择 Dify 顶部栏的知识库选项,并点击创建知识库,如下图 13 所示:
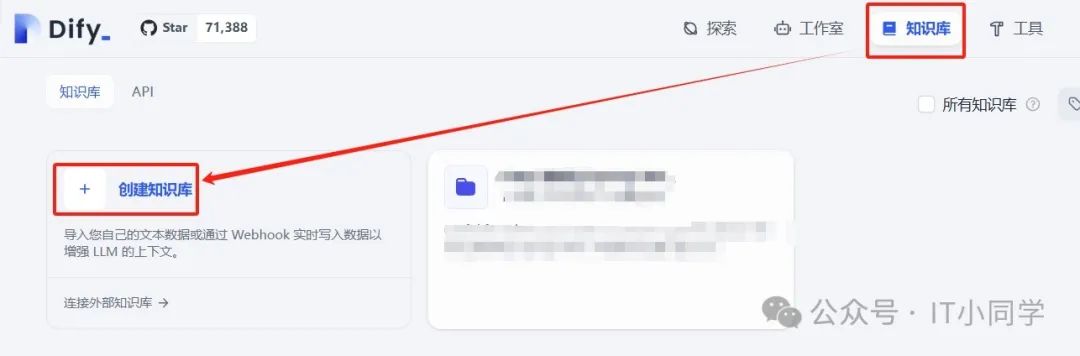
图 13 创建知识库
创建知识库之后,我们就可以来配置我们的知识库了,如下图 14 所示:
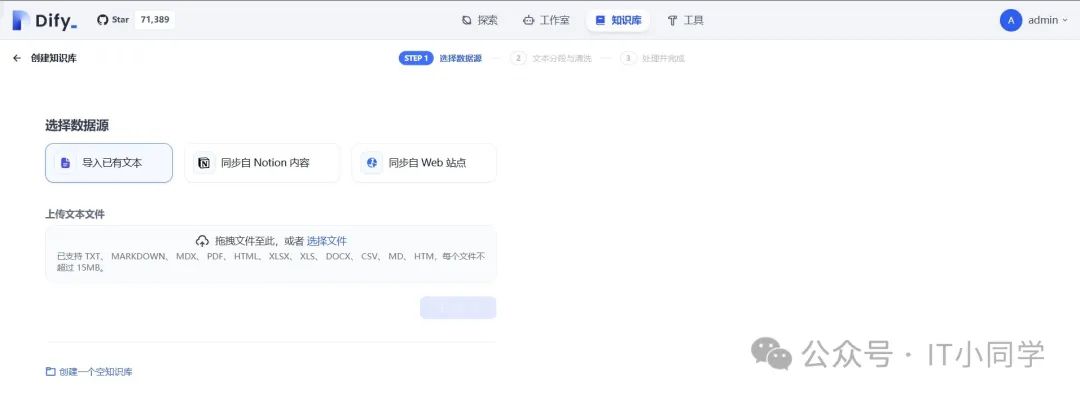
图 14 配置知识库
我们可以选择导入已有文本、同步自 Notion 内容、同步自 Web 站点三个选项。以导入已有文本为例,将需要投喂到 DeepSeek 大模型中的文档进行上传,在选择了文件之后,点击下一步按钮,可进行后续的配置,如下图 15 所示:
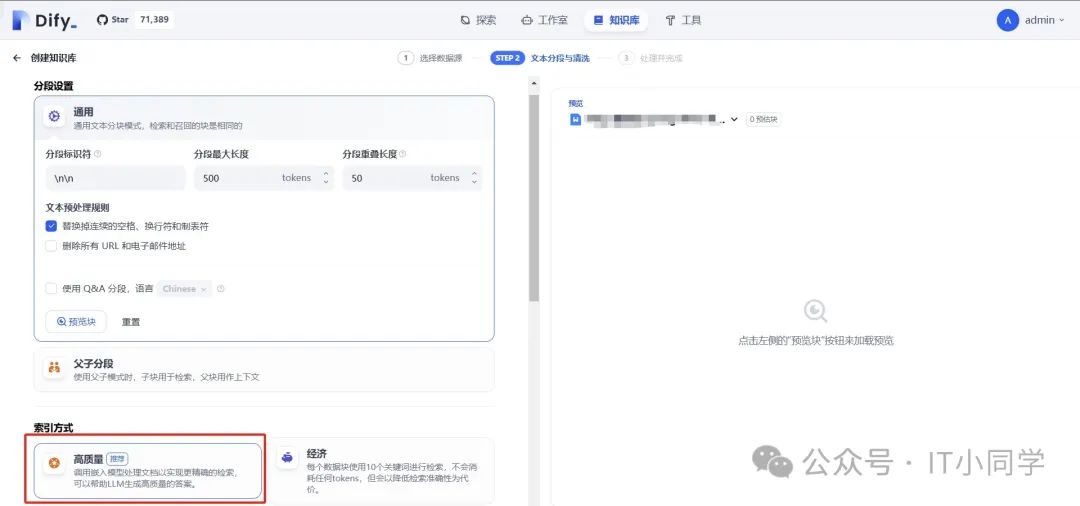
图 15 知识库调试
这里面,通用配置不用额外配置,索引方式选择高质量模式,以便更好地对我们上传的文档进行向量化转化。
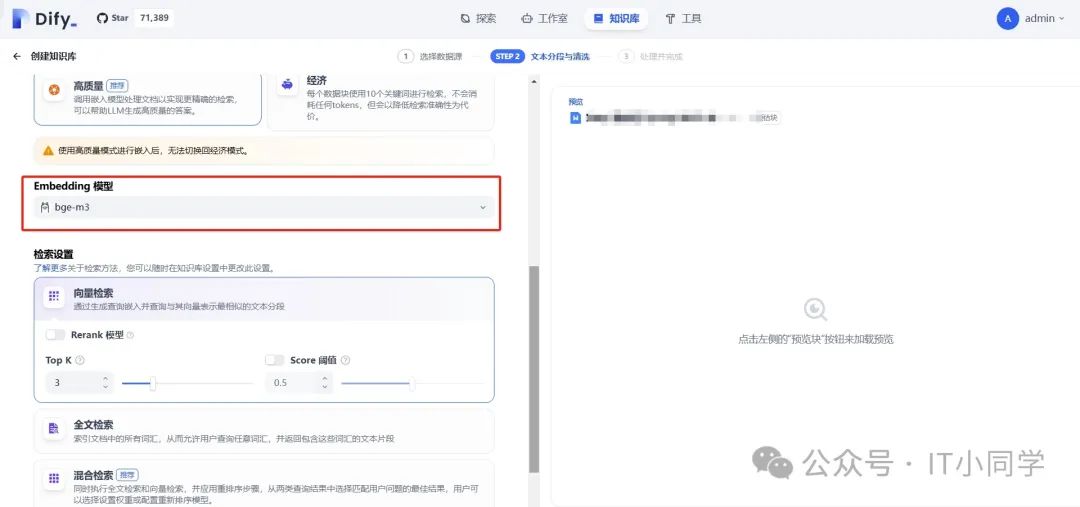
图 16 TEXT_EMBEDDING 模型选择
而 Embedding 模型,则选择我们安装好的 bge-m3 模型即可。下面的检索设置不需要额外的配置。之后,保存并处理,等待文档被解析完毕,如下图 17 所示:
图 17 知识库解析文件
接着,我们回到我们创建的应用中,在上下文配置面板,点击添加按钮,选择刚才解析好的文档进行使用,选择之后点击添加即可将该文档添加到 DeepSeek 中,我们再次询问 DeepSeek 有关问题时,DeepSeek 就会自动引入我们添加的文档,并结合文档内容进行回复,如下图 18 所示:
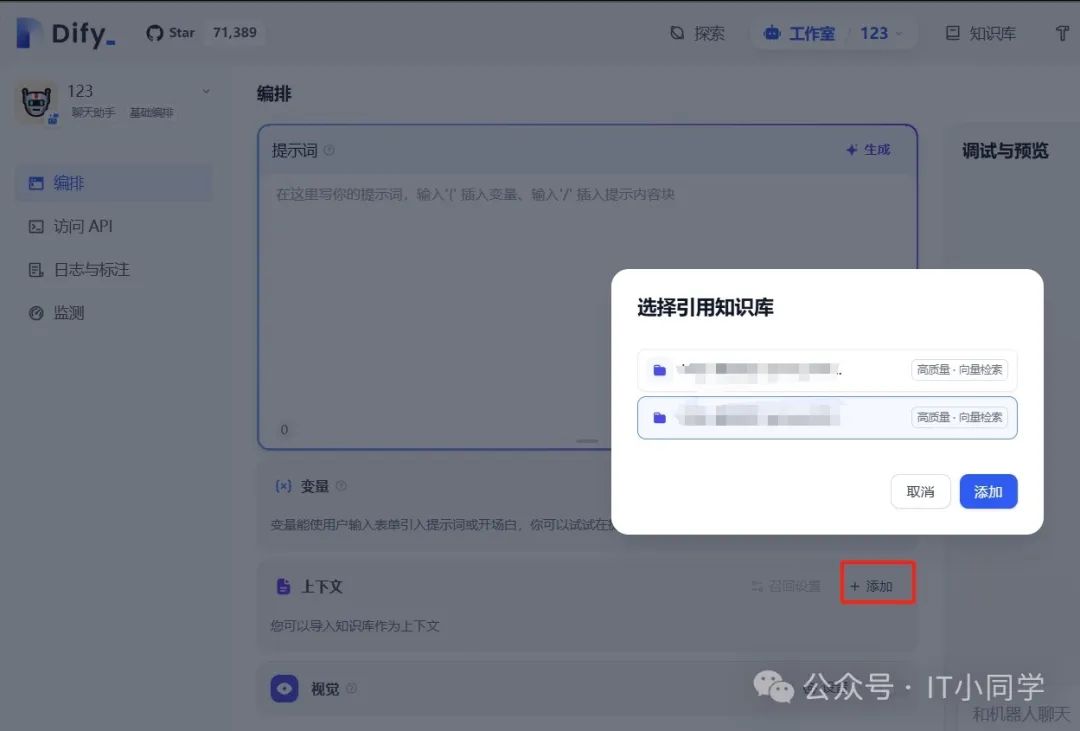
图 18 选择引用知识库
DeepSeek 结合知识库的回答效果如下图 19 所示:

图 19 DeepSeek 结合知识库回复
经过上述步骤的操作,我们就完成了使用DeepSeek+Docker+Dify 搭建个人私域知识库的全部流程,可以将 DeepSeek 训练成特定业务领域的智能助手了。
