




见字如面,我是一臻 探索数字AI,专注Apache Doris
探索数字AI,专注Apache Doris
点击关注 👇 免费获取数字AI知识库
❝曾经,一封书信传千里,几天就过去了。如今......
"小李,这个数据报告怎么又跑了3个小时还没出来?"
"老板,我们的数据分散在好几个地方,这边要查Hive,那边要查MySQL,还得去看看S3上的日志文件..."
"能不能一个地方搞定?我就想看个销售趋势,怎么这么复杂?"
这样的对话,在各大公司的数据部门里每天都在上演。
数据越来越多,分布越来越散,工具越来越复杂,但分析效率却越来越低。

数据分析的"三体"演化史
从前车马很慢,书信很远,而发展至今,回想一下,人类的数据分析经历了怎样的演化?
第一体:数据库时代
那时候数据量不大,一个MySQL就能搞定一切。
查询快,事务强,简单粗暴。现实版武侠小说里的"一招鲜,吃遍天
"。
第二体:数据仓库时代
数据量暴增,MySQL扛不住了。
于是我们有了数据仓库——把数据清洗、建模、优化,专门用来做分析。性能飞跃,查询秒级响应。
第三体:数据湖时代
原始数据越来越多,各种格式的文件堆积如山。数据湖应运而生——什么都能存,成本还低。
三个时代,三种方案,各有千秋。
可是问题来了:现实中的企业需要的是什么?
理想很丰满,现实很骨感
张总监最近也很头疼。他们公司的数据架构是这样的:
1. 交易数据在MySQL里 -> 2. 历史数据在Hive里 -> 3. 日志文件在S3上 -> 4. 用户行为数据在Kafka里
每次做个分析报告,就像拼图游戏:
1. 先从MySQL导出交易数据 -> 2. 再从Hive查历史趋势 -> 3. 最后从S3下载日志分析
一个简单的"本月销售额 vs 去年同期"的报告,要跑3个系统,写5个脚本,等2个小时。
张总监想:能不能有个"万能钥匙
",一把锁打开所有门?
Doris湖仓一体:一个平台,统治所有
Apache Doris给出了答案:湖仓一体。
什么是湖仓一体?
简单说就是"鱼和熊掌兼得
"——既要数据仓库的查询速度,又要数据湖的存储成本,还要简单上手。
Doris是怎么做到的?
Multi-Catalog:数据的任意门
记得儿时常看的哆啦A梦的任意门?想去哪里就去哪里。Doris的Multi-Catalog就是这样一扇门。
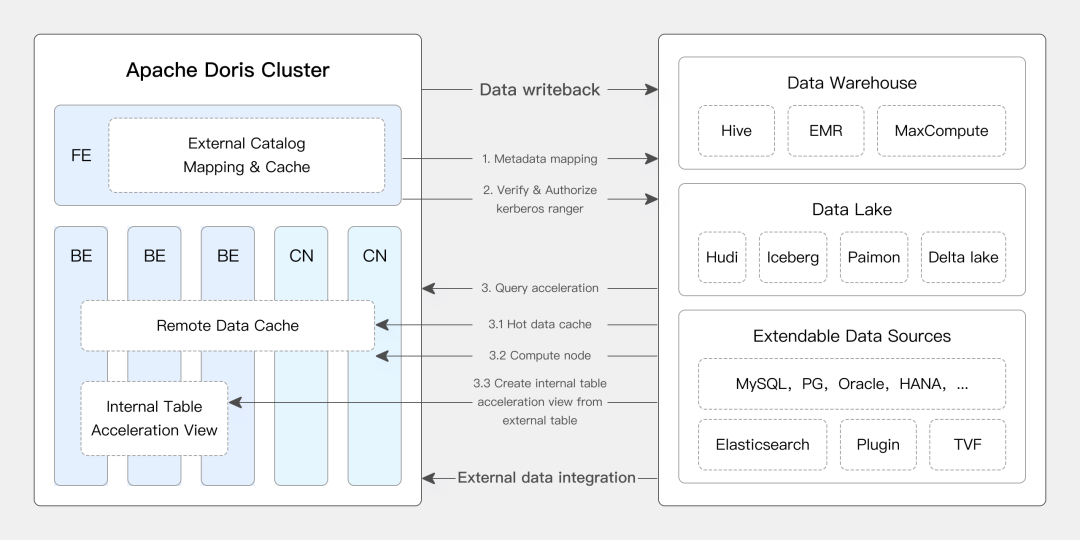
创建一个Catalog,就像在Doris里装了一个"翻译器":
想查Hive?没问题,直接SELECT * FROM hive.sales.orders
想看MySQL?轻松,SELECT * FROM mysql.crm.customers
想分析S3上的日志?简单,SELECT * FROM s3(......)
一个SQL语句,跨越多个数据源。好比在一个超市里,能买到全世界的商品。
智能缓存:数据的"预言家"
Doris很聪明,它知道哪些数据你经常用。
元数据缓存:把表结构、分区信息这些"地图"存在内存里,查询规划瞬间完成。
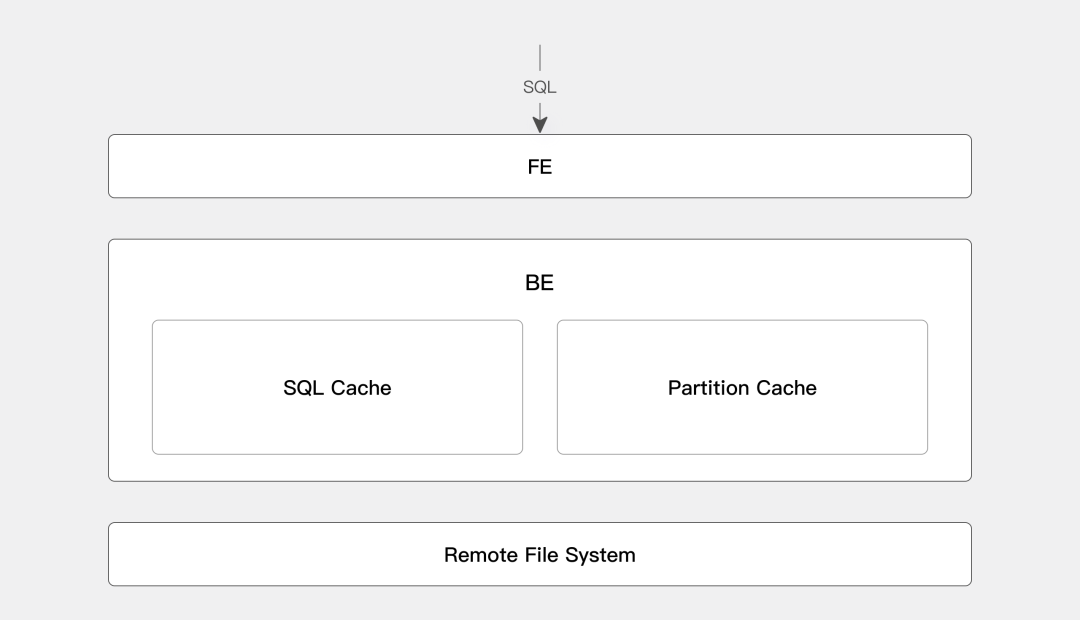
数据缓存:热点数据自动缓存,下次查询直接命中。就像你常用的APP会自动预加载一样。
查询结果缓存:相同的查询结果直接返回,不用重复计算。
一个用户说:"我们的报表查询从30秒优化到了3秒,团队效率提升了10倍!
"
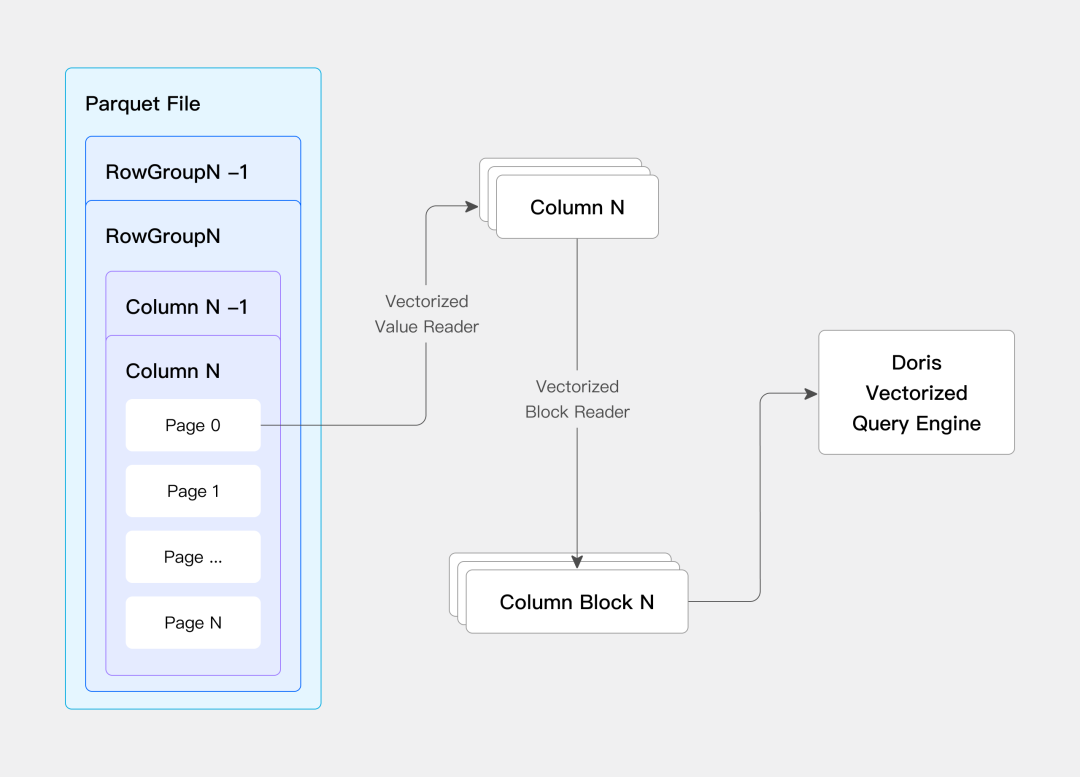
Native Reader:数据的"翻译官"
传统的数据读取是这样的:
1. 从存储读取Parquet文件
2. 转换成通用格式
3. 再转换成Doris内部格式
4. 最后进行计算
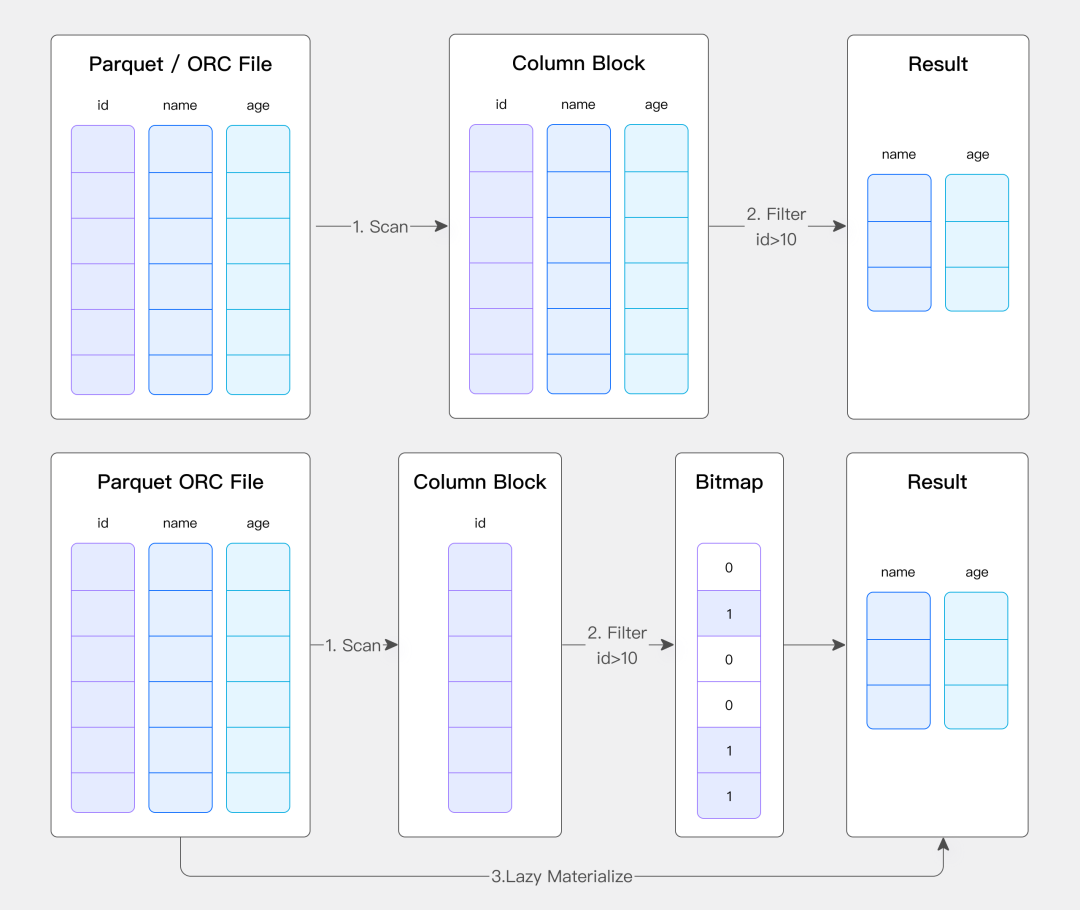
Doris的Native Reader直接跳过中间步骤,从Parquet直接读取到Doris格式。就像两个人直接对话,不需要翻译。
延迟物化技术更绝:只读你需要的列,只读满足条件的行。1TB的数据文件,可能只需要读取100MB。
不仅如此,Doris还做了一系列优化👇
IO合并优化
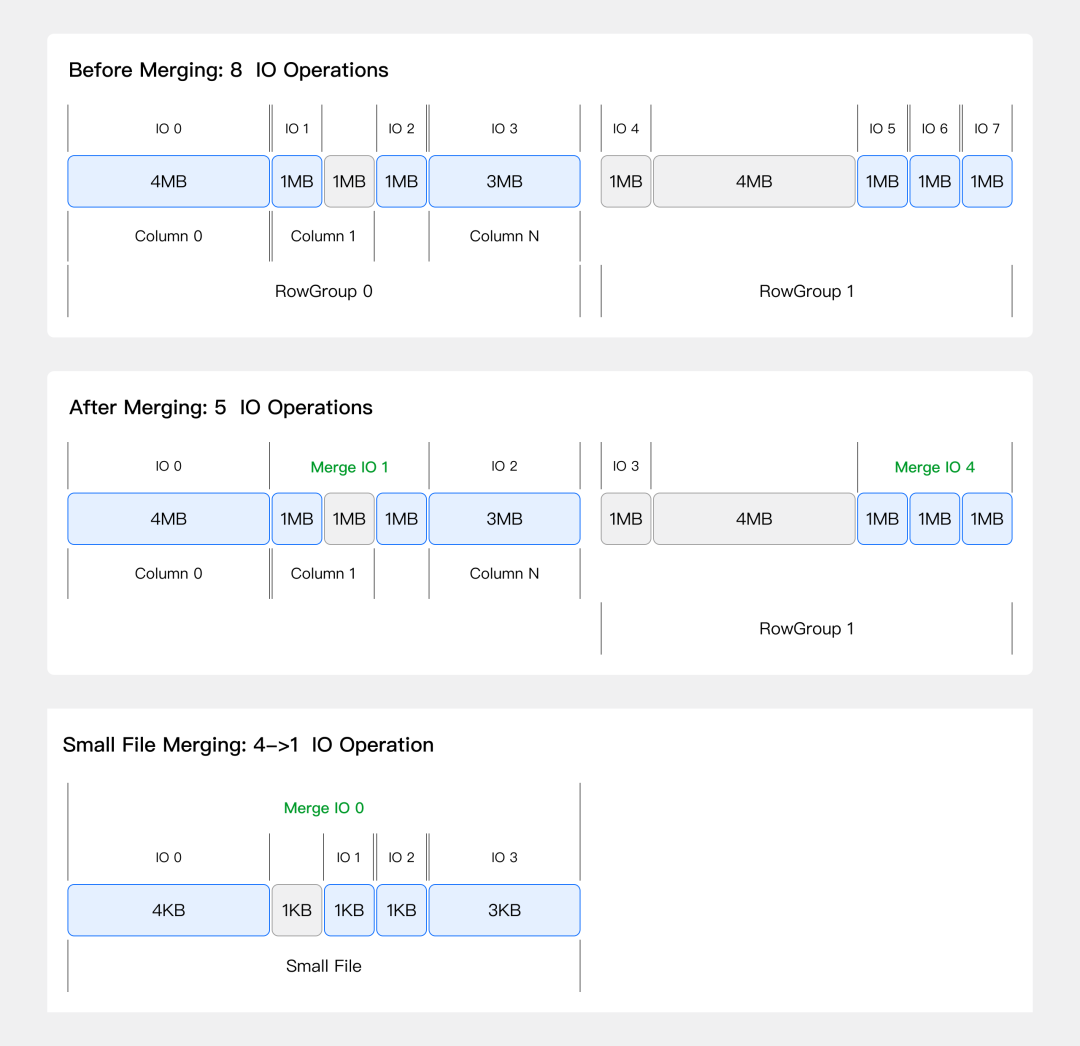
网络上有很多小文件?
Doris会把小于3MB的IO请求合并处理。原来8次网络请求,现在只需要5次。
正如大家平时网购一样,零散下单运费很贵,打包一起买更划算!
统计信息优化
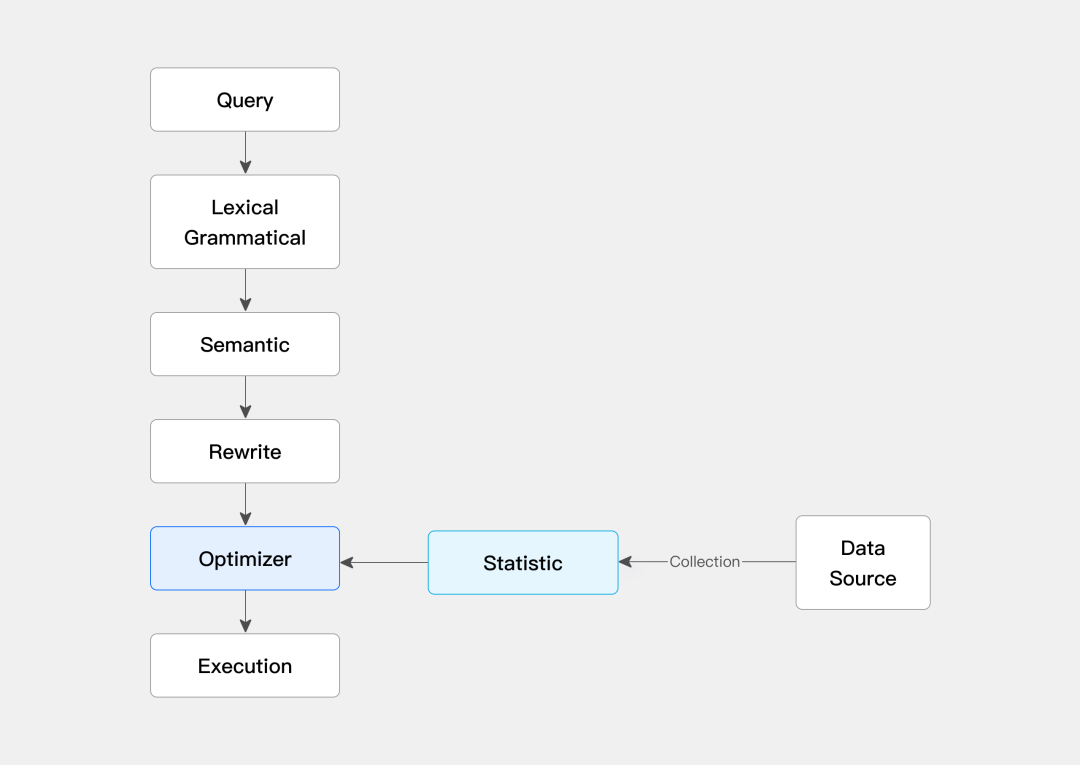
Doris会收集数据分布信息,优化器根据这些信息选择最优的执行计划。
好比用导航软件一样,知道哪条路堵车,会自动选择更快的路线。
向量化计算
传统的行式处理改为列式批量处理,CPU利用率大幅提升。
直接从手工作坊升级到流水线生产,效率提升几十倍,极大加速了数据读取效率。
结语
数据分析的"三体"时代,我们不需要选择。
Doris湖仓一体让你拥有数据库的简单、数据仓库的性能、数据湖的灵活。
"从前车马很慢,书信很远,一生只够爱一个人。"
现在数据很快,查询很近,一个Doris够用一辈子。

完
👇欢迎扫描下方二维码 👇
备注 666 免费领取资料  加入Doris官方群和PowerData数据社区❗️
加入Doris官方群和PowerData数据社区❗️

