




本文对清华大学李国良教授、周煊赫和厦门大学周伟教授、林琛教授等共同编写的VLDB 2024论文《Breaking It Down: An In-depth Study of Index Advisors》进行解读,全文共12871字,预计阅读需要25至35分钟。
索引推荐旨在通过明智地选择一组合适的索引来提高工作负载性能。目前已提出了各种基于启发式和基于学习的方法。然而,如今缺乏对现有索引推荐的全面评估,即评估它们的优势、局限性和应用场景。本文从五个关键方面对现有索引推荐进行了深入研究。首先,本文发起了端到端分析,将索引推荐分解为三个基本构建块,建立分类法对每个块中使用的方法进行分类,并分析这些方法的优缺点。其次,本文开发了一个统一的开源测试平台,其支持可自定义配置以满足不同的测试需求。第三,本文各种场景下跨数据库系统对索引推荐进行了广泛评估,主要评估适应性和鲁棒性,确定了实际应用场景。第四,本文通过研究每个构建块的变体进行了细粒度的消融研究,以确定了有效的变体,并找出了影响索引推荐性能的重要因素。最后,本文整合了研究发现,为推进索引推荐未来发展的研究方向提供了启示。
1. 研究背景与动机
1.1 索引推荐的重要性和局限性
索引对于在数据库中实现高工作负载性能至关重要。在过去,索引由数据库管理员(DBA)识别、构建和维护。然而,DBA管理索引非常繁琐,尤其是对于云上的数百万个数据库实例。为了自动化这一过程,提出了索引推荐,它能够自动且明智地找到一组合适的索引来优化查询性能。索引推荐主要有两类:
● 基于启发式的索引推荐:利用预定义的启发式算法来创建索引。
● 基于学习的索引推荐:基于训练工作负载构建机器学习模型,并利用这些模型选择索引或估计索引收益。
这些索引推荐有不同的应用场景,评估它们的优势和局限性对于实际使用至关重要:
● 首先,尽管基于学习的方法通常被认为一旦经过良好训练,就能为给定的工作负载找到接近最优的索引,但实验结果表明,它们的性能是不可预测的。随着索引存储预算的增加,基于学习的方法可能比基于启发式的方法表现更差。
● 此外,现有工作要么在静态场景(即固定工作负载)中只评估基于启发式的索引推荐,而没有评估基于学习的索引推荐,要么仅研究索引推荐的鲁棒性。
1.2 本文对索引推荐的研究贡献
为了解决这些局限性,并帮助数据库用户确定最适合其应用的索引推荐,本文对基于启发式和基于学习的索引推荐进行了深入研究,并做出了以下贡献:
1. 端到端分析:本文通过构建索引推荐构建块及其每个块内方法的分类法,提供了涵盖索引推荐整个工作流程的完整分析。为了清楚地了解索引推荐的工作机制,作者将索引推荐分解为三个基本构建块:索引候选生成、索引选择和索引收益估计,概述了它们的典型方法,并总结了它们的优缺点。
2. 统一测试平台:本文开发了一个测试平台,该平台通过统一接口在11个数据集上实现了17个索引推荐。不同于现有研究独立开发了索引推荐,作者开发了一个开源测试平台以实现全面评估的目标:
● 关于索引推荐,本文实现了实际系统中广泛使用的传统方法和新开发的基于学习的索引推荐。
● 关于基础数据集,我们基于多个标准基准和真实数据集准备了测试套件。
● 该平台还支持对一组可配置参数上的各种构建块的自定义组合进行评估,以满足不同的测试需求。
3. 综合评估:实验还将索引推荐置于不同场景下,并进行了广泛的实验,以评估它们在开源和真实数据集上的适应性和鲁棒性。目前只有一项研究深入研究了索引推荐的实验评估,且这项工作只关注基于启发式的索引推荐的评估。大多数的研究使用有限和静态的查询模板合成工作负载,这无法反映索引推荐在真实场景中的性能。为了应对这些限制,本文进行了全面评估,以测试索引推荐在三个主要场景中的能力:静态分析场景、动态分析场景、事务场景。
4. 细粒度比较:本文探索了索引推荐的不同变体,比较了它们的性能,并利用可解释的机器学习技术揭示了其潜在机制。随着现代索引推荐变得越来越复杂,了解索引推荐每个构建块的因果关系和贡献至关重要。作者通过探索基础构建块的各种组合来创建多个索引推荐变体。
5. 有见解的发现:本文从评估结果中总结发现,为索引推荐的选择和未来研究提供以下启示:
● 对于具有相同查询的静态场景,基于学习的索引推荐可以比基于启发式的索引推荐识别更有效的索引。
● 具有离线学习策略的基于学习的索引推荐,在各种工作负载上经过离线训练阶段,并直接为新工作负载返回索引,在大多数场景(尤其是对于大型数据集)中比其他方法更高效。
● 对于具有工作负载漂移和数据偏移的动态场景,基于启发式的索引推荐比基于学习的索引推荐更具有鲁棒性。
● 索引候选生成会显著影响索引选择的性能,保留更多的索引候选通常有助于更好的性能,但会增加时间开销。经验规则可以提高索引候选生成的有效性和效率。
● 基于学习的索引推荐的输入特征设计对于找到有效的索引至关重要。
● 一些基于树的估计方法可以利用查询计划特征作为输入,在估计索引收益时达到最高精度。
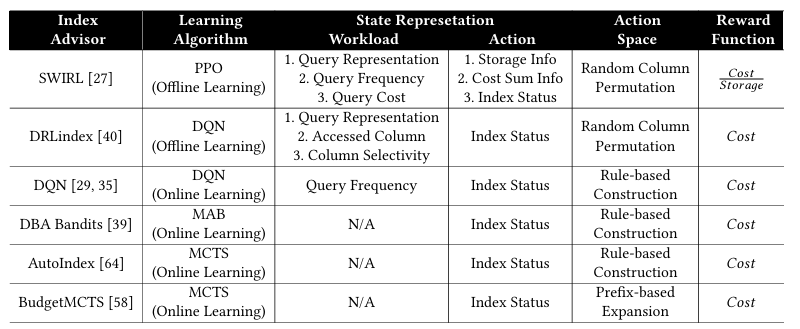
2. 索引推荐
2.1 工作流程概述
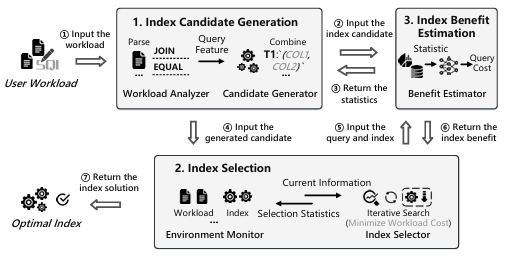
索引推荐工作流程
根据上图,对于给定的工作负载,索引推荐通常包含三个构建块:
1. 索引候选生成:使用预定义策略合成有潜力的索引候选。
2. 索引选择:通过遍历生成的索引候选,并基于底层选择机制来选择索引。
3. 索引收益估计:其用于估计构建索引的收益,以协助上述两个构建块。它为索引候选生成提供估计统计信息,以确定哪些索引是有效的候选;同时量化选择标准,以指导索引选择选择合适的解决方案。
在设计索引推荐时,需要考虑一些关键因素:
● 工作机制:即索引推荐是否采用学习组件。基于工作机制,索引推荐可分为两类:具有一系列预定义算法的基于启发式的方法;涉及具有不同学习范式(如强化学习、分类和回归)的各种学习组件的基于学习的方法。
● 选择约束:包括预算,即索引的存储或要构建的索引的最大数量;以及要考虑的索引类型,例如单列索引或多列索引。由于索引推荐的目标是选择有效的索引,物理索引设计不是索引推荐的重点,本文将B树用作默认的物理索引设计。
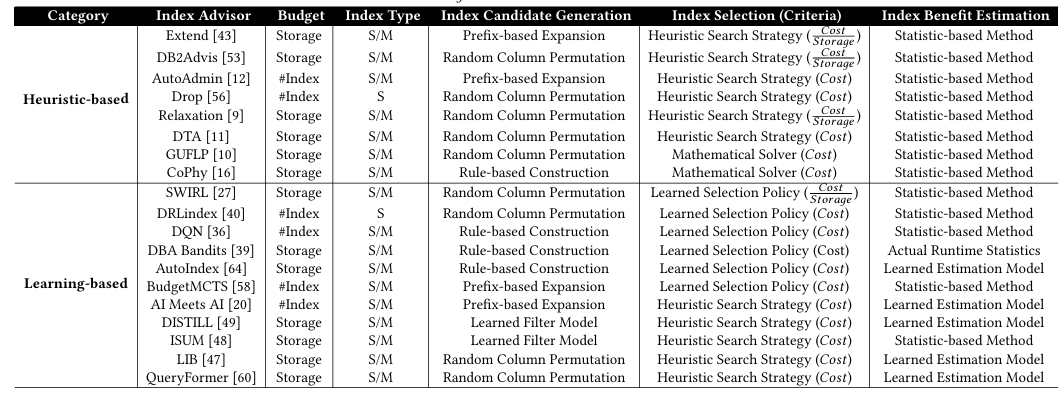
本文研究的现有索引推荐
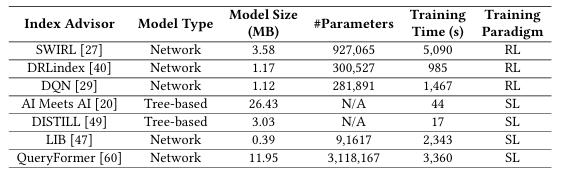
根据上表,本文评估了代表性的索引推荐,包括在生产系统中广泛使用的和最近研究中新兴的方法。
2.2 索引候选生成
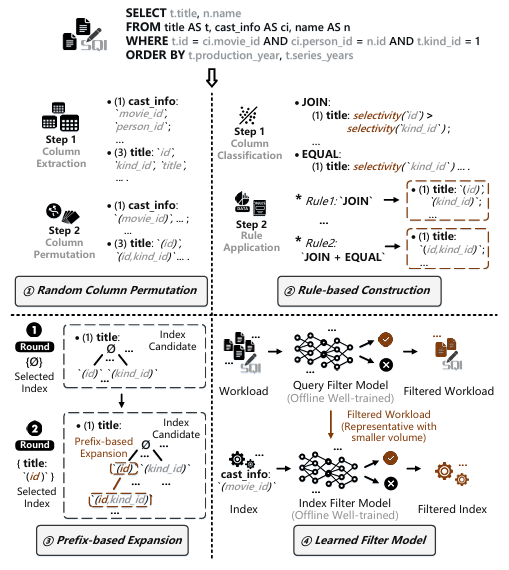
索引候选生成方法
索引候选生成旨在为索引选择准备一组有效的候选。如图所示,如今有四种类型的索引候选生成方法来缓解在巨大候选空间中搜索的问题:
1. 随机列排列:该方法以两步方式生成候选。它首先解析并提取工作负载中所有可索引的列。接下来,它通过在最大索引宽度(即索引中的列数)内对提取的列进行排列来合成索引候选。为了进一步减少候选的数量,一些索引推荐仅生成单列索引,而其他索引推荐利用假设调用仅保留查询计划中使用的索引。
2. 基于规则的构建:该方法使用考虑查询模式的规则生成候选。索引推荐首先根据语法特征(如使用JOIN和EQUAL的语句)将可索引列解析并分类为几个组。然后,它们利用一系列启发式规则来构建有效的候选。除了语法特征外,一些索引推荐在生成过程中还考虑了每列的数据统计信息(如列的选择性)。
3. 基于前缀的扩展:该方法动态维护索引候选,基于前几轮中选择的索引不断优化候选。如图所示,每一轮的候选都是通过将列附加到所选索引来生成的。当索引候选的索引宽度(即索引列的数量)逐渐增加,并且只有当多列索引候选的前缀候选已被选择时,才会考虑该多列索引候选。
4. 学习过滤模型:该方法采用学习模型来过滤掉无用的索引候选,一般有两个连续的模型。查询过滤模型用于识别工作负载中的代表性查询。该模型的输入是各种统计信息,输出是工作负载中过滤后的代表性查询。然后,基于具有这些代表性查询的工作负载生成索引候选。这些索引候选随后被馈送到索引过滤模型,该模型基于与索引相关的特征估计每个索引候选的收益,并消除无用的候选,即影响小于给定过滤阈值的候选。学习过滤模型依赖于工作负载,并使用包含工作负载统计信息的标记数据集进行训练。一旦训练良好,它可以应用于压缩测试工作负载或过滤掉无用的索引候选。每个数据集都需要训练,当测试工作负载与训练工作负载有显著差异时,需要重新训练。
2.3 索引选择
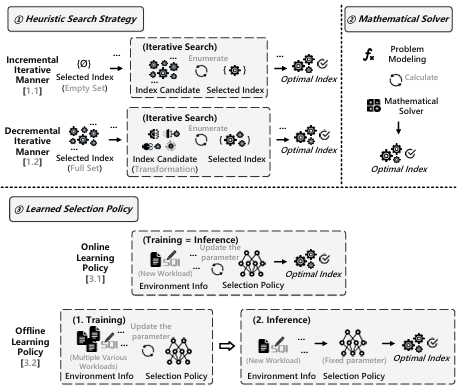
索引选择方法
索引选择探索生成的候选,并基于各种策略或算法识别最有效的索引。通常,选择由制定的标准指导,这些标准要么考虑纯成本(即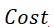 ),要么考虑相对于索引大小的相对成本(即
),要么考虑相对于索引大小的相对成本(即 )。一般有三种类型的选择方法:
)。一般有三种类型的选择方法:
1. 启发式搜索策略:该类型通过不同的启发式策略逐步确定索引,直到满足停止标准。基于所选索引的初始状态,有两种进行索引选择的方式:增量式,从空集添加更多索引;减量式,从完整索引集删除索引。
● 增量迭代方式:这种方式从空集开始,逐步向所选索引集添加索引。由于单纯的贪心策略可能会返回次优的索引解决方案,一些索引推荐采用混合搜索策略,首先利用穷举搜索以蛮力方式推导出几个最优索引,然后利用贪心搜索推导出剩余的索引。另一种避免次优解的方法是改变所选索引,如随机交换一些所选索引与未选索引,并验证它们是否更优。
● 减量迭代方式:这种方式用所有候选初始化。它通过丢弃索引来减少所选索引的集合,直到满足给定的预算。为了获得减少的索引集,一些索引推荐迭代排除最“无用”的索引,删除导致工作负载成本比删除其他索引更小的索引。其他索引推荐采用索引转换,包括合并:将一个索引的列附加到另一个索引的末尾;拆分:将两个具有共享前缀列的索引拆分为三个索引;截断:截断索引的最后一列;删除:从候选集中删除索引;提升为聚簇索引:将非聚簇索引转换为聚簇索引。新的聚簇索引可以加速目标工作负载中的范围查询并减少索引大小。
2. 数学求解器:该类型将索引选择建模为线性规划问题(LP)。索引的选择被视为二进制变量,整体工作负载成本是基于工作负载统计信息(即工作负载成本)和索引选择的线性目标函数。现成的数学求解器得出在一组约束下最小化目标函数的解决方案,即索引。为了降低问题的复杂性,一些索引推荐通过仅允许每个查询拥有一个索引来限制解空间。其他索引推荐将原始问题分解为几个较小的问题,并同时解决这些较小的问题以增强选择过程。
3. 学习选择策略:该类型将选择过程转换为马尔可夫决策过程(MDP),并利用强化学习来解决这个问题。具体来说,以状态表示(如工作负载特征信息)作为输入,这些方法通过学习的选择策略遍历预定义的索引候选,并基于奖励函数优化策略。基于这些方法是否能适应动态工作负载,学习的选择策略可分为在线学习策略或离线学习策略。
不同的学习选择策略概述
● 在线学习策略:这种方法通过迭代试错尝试学习为静态工作负载识别最优索引,其中选择开销指的是给定工作负载上的在线训练工作。它以粗粒度捕获环境信息,即工作负载特征和当前索引状态。工作负载由一维查询频率向量建模,其中每个通道对应一个单独的查询。索引候选由多热索引向量建模,其中每个通道指示索引候选是否被选择。索引中列的顺序和派生的统计信息在一些索引推荐中也被考虑。与对索引使用向量表示相反,一些索引推荐维护一个选择树,其中每个树节点对应一个有效的索引组合。为了优化策略,采用了不同的学习算法,包括深度Q网络(DQN)、多臂老虎机(MAB),它们训练神经网络来表示动作策略,以及蒙特卡洛树搜索(MCTS),它通过大量模拟计算最优动作。
● 离线学习策略:这种方法主要是为了处理动态工作负载。选择开销仅包括推理开销,这由离线训练步骤提供支持。它首先在各种工作负载上进行离线训练过程。然后,学习的策略直接为新工作负载返回索引。这种方法以细粒度方式对环境信息进行建模,并用查询表示矩阵来描述工作负载,其中每一行是由学习模型生成的表示或用统计向量填充。一些索引推荐还引入了其他特征,如列选择性。一些索引推荐还纳入了元信息(例如存储预算)。选择策略通过深度Q网络(DQN)学习,以及近端策略优化(PPO),该策略调整策略网络的参数以最大化索引收益。
2.4 索引收益估计
索引收益评估的目标是在不实际构建索引的情况下估算使用所选索引的收益(即实际运行时统计信息),包括两种主要类型:
1. 基于统计的方法:此方法利用从数据库优化器获得的估算统计信息来计算索引收益。它通过数据库优化器对假设索引的假设调用(what-if calls)推导出估算统计信息。具体而言,假设调用会返回:通过关于不同操作加权和的经验成本函数计算的查询成本;以及基于估算统计信息的预定义大小函数计算的索引大小。
2. 学习评估模型:此方法采用学习模型估算索引收益。这些模型经过训练,作为从输入工作负载统计信息和索引到反映其收益的值的映射函数。学习索引收益评估模型需要表征索引的特征(如索引中列的选择性)来估算其收益。总体而言,有两类评估模型:
● 分类模型:该模型将评估视为分类问题,预测两个输入索引中哪个更有效。给定两个索引和相应的查询计划,训练分类器会基于定义良好的查询计划特征向量返回索引收益更大的索引。
● 回归模型:该模型将评估视为回归问题,估算给定索引上的工作负载成本或其降低比率。它们提出深度学习模型来表征索引相关特征以进行准确评估。比如利用操作信息(如查询计划中受索引影响的操作类型)、数据库统计信息(如索引列的不同比率)和索引信息(如索引中列的顺序)来估算索引收益。
3. 实验测试平台
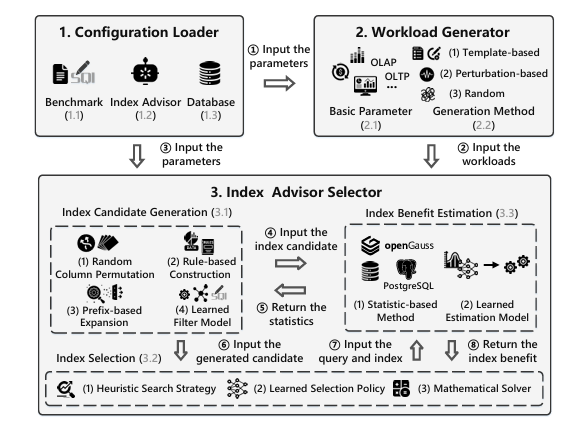
开源测试平台工作流程
本文呢开发了首个开源测试平台,该平台有以下特点:
● 包括总共17种基于启发式和基于学习的索引推荐。
● 支持对索引推荐模块进行细粒度比较,最多可达144种变体。
● 提供统一接口,可在11个数据集上使用不同的用户指定参数在不同场景中进行评估。
该测试平台包括三个模块:
1. 配置加载器:此模块初始化一系列评估设置,涉及以下方面:
● 基准:数据集(如OLAP基准TPC-H)、查询参数(如查询数量)和工作负载生成方法(如基于查询模板的生成)。
● 索引推荐:评估的索引推荐、三个模块的方法和选择约束。
● 数据库:支持假设索引的目标数据库,即PostgreSQL和openGauss。
2 工作负载生成器:此模块支持三种生成具有不同特征的工作负载的方法,以模拟各种场景的需求:
● 基于模板的方法:通过用不同值填充预定义查询模板中的占位符来生成查询。
● 基于扰动的方法:通过应用一系列扰动来增强查询。它通过扰动给定查询来模拟由于日常事务或用户行为引起的工作负载漂移。例如修改过滤谓词中的值;在SELECT子句中添加额外列;调整ORDER BY子句中列的顺序。
● 随机方法:基于主键-外键(PK-FK)关系合成选择-投影-连接(SPJ)查询,并带有不同数量的随机生成过滤谓词。
3. 索引推荐选择器:此模块实现本文列举的索引推荐,包括7种基于启发式的索引推荐和10种基于学习的索引推荐:
● 基于启发式的方法:本文重构基于启发式的索引推荐的实现,扩展选择约束以同时包括存储预算和最大允许数量,并且实现具有数学求解器选择策略的索引推荐。
● 基于学习的方法:本文实现在三个模块中采用学习组件的索引推荐。对于索引候选生成,平台实现具有多种树基变体;对于索引选择,平台实现具有建议的状态表示(即查询表示矩阵、列选择性向量、评估列向量和多热索引状态向量)的DRLindex,同时通过利用SWIRL中的状态表示实现DQN,以支持动态工作负载。对于索引收益评估,平台实现具有统计特征的树基模型分类器,并将其建模为回归问题。本文还重构方法以支持跨数据集的工作负载。
3.1 基准数据集
本文采用各种开源基准和真实数据集来评估OLAP或OLTP场景中的性能。对于OLAP场景,实验采用具有不同特征和复杂度的五个基准:
● TPC-H:一个开源决策支持基准,数据均匀分布,模式较小。
● TPC-DS:一个开源决策支持基准,复杂且模式较大。
● JOB:一个真实的IMDB数据集,其中索引过度使用导致性能下降。
● TPC-H Skew:TPC-H的增强版本,具有偏斜数据分布。
● DSB:TPC-DS的增强版本。
对于OLTP场景,本文通过调整五个事务(NewOrder、Payment、OrderStatus、Delivery和StockLevel)的比例来创建多个具有不同读写比的TPC-C基准,以及包含事务查询的多个真实数据集。
3.2 评估指标
1. 相对成本降低:索引的收益,即各种索引推荐返回的工作负载成本降低比率: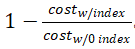 。
。
2. 时间duration:不同索引推荐返回索引所需的时间开销。对于采用离线学习策略的基于学习的索引推荐,其训练开销需单独考虑。
3. 查询延迟:使用所选索引的实际查询运行时间。
4. 吞吐量:在给定时间范围内使用所选索引处理的查询或事务数量。
5. Q-Error:索引收益评估模型的估算准确性: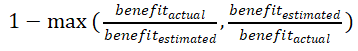 。
。
6. F1分数:学习过滤模型在识别有效索引候选方面的分类性能。
3.3 实现
实验在配备两个Intel (R) Xeon (R) CPU E5-2678 v3 @ 2.50GHz、256 GB主内存和4张 GeForce RTX 2080 Ti显卡的工作站上,使用Python 3.7、PostgreSQL 12.5和openGauss 5.0.0进行。
基于学习的方法的重要训练参数
默认选择约束是存储预算,设置为数据集大小的一半,默认最大索引宽度(使用的列数)为2。对于基于学习的索引推荐,工作负载按8:1:1拆分为训练/验证/测试集。超参数通过采用原始实现中的值或利用网格搜索和交叉验证方法确定。离线学习策略的离线训练开销默认设置为100,000轮。实验结果通过三次运行得出,以减轻外部因素的影响。
4. 整体性能评估
4.1 静态分析场景
实验基于之前的OLAP基准构建工作负载,其中相同的查询模板通过不同的随机种子填充不同的参数值。工作负载大小从1(即查询级选择)到基准中的模板数量(即工作负载级选择)不等。查询频率随机分配为[1,1000]中的值。所有基于学习的方法的训练和测试工作负载是相同的工作负载。结果是索引推荐在这些工作负载上的平均性能。
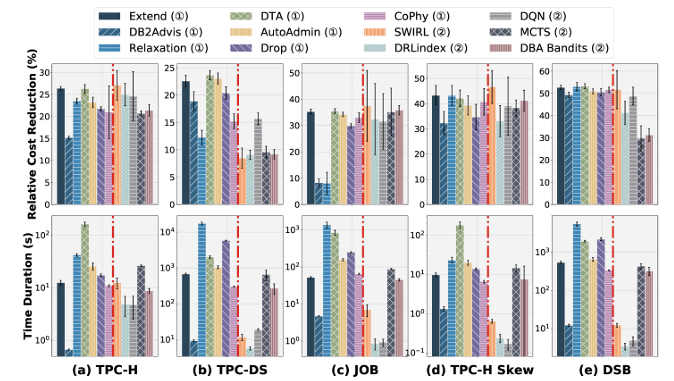
工作负载下的性能(①代表基于启发式的索引推荐,②代表基于学习的索引推荐)
O1(选择有效性):在具有相同查询的静态工作负载上,基于学习的索引推荐可识别更有效的索引,但性能方差高于基于启发式的索引推荐。这可能是由于学习算法使基于学习的索引推荐能够通过大量试错尝试捕捉各种工作负载模式,这些模式对选择有效索引至关重要。但是,试错策略可能涉及错误尝试,误导训练过程,给学习策略的质量带来显著不确定性,导致基于学习的索引推荐的性能波动。相反,基于启发式的索引推荐比基于学习的索引推荐返回的索引具有更小的性能方差。
O2(选择效率):具有离线学习策略的基于学习的索引推荐比基于启发式的索引推荐和具有在线学习策略的基于学习的索引推荐更高效。具有离线学习策略的基于学习的索引推荐所需开销更低,平均为591.39毫秒,比其他方法快163.32倍。原因在于这些方法无需耗时的搜索过程(即枚举和比较不同索引)和在线训练过程(即更新策略网络)即可返回索引。其中,DRLindex所需的选择时间最短,为301.79毫秒,比其他方法快1.44倍。同时,DRLindex在10万轮训练中所需的开销最少,为3216.2秒,平均比SWIRL和DQN快2.43倍。

基于学习的索引推荐的训练开销
相反,采用减量迭代方式的基于启发式的索引推荐耗时最长,尤其是在大型数据集上。根本原因在于减量迭代方式最初包含所有索引候选,与增量迭代方式相比,在大型数据集上需要更多步骤来删除索引。
索引推荐各模块的时间分布
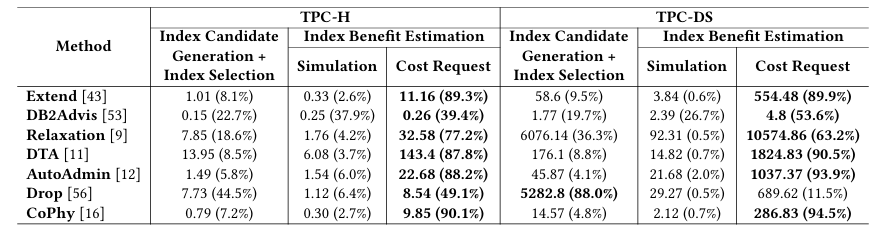
为进一步确定基于启发式索引推荐中最耗时的步骤,实验观察到,索引收益评估所花费的时间占很大比例,因为这涉及使用假设调用来模拟假设索引(即模拟)和推导估算查询成本(即成本请求)以计算索引收益。成本请求是最耗时的步骤,平均占选择时间的72.73%。
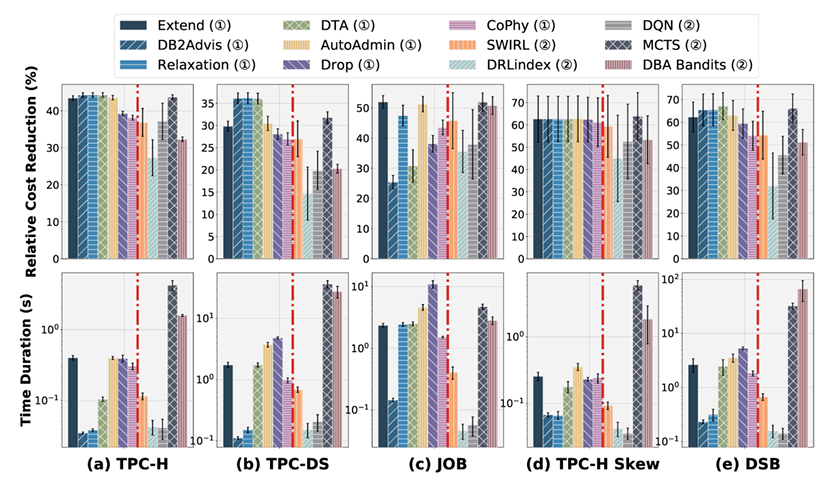
查询级选择表现
O3(选择粒度):索引推荐在查询级选择上的表现优于工作负载级选择。实验表明,索引推荐在查询级选择上获得了更高的相对成本降低。基于启发式和基于学习的索引推荐在查询级选择上的相对成本降低分别为48.11%和41.47%,而在工作负载级选择上分别为31.82%和21.13%。基于启发式索引推荐的时间开销也在可接受范围内。在所有基准上,DB2Advis甚至比SWIRL更高效。这表明简单的工作负载减轻了索引选择的难度,因此无论其内部设计如何,索引推荐都有望很好地处理此类工作负载。
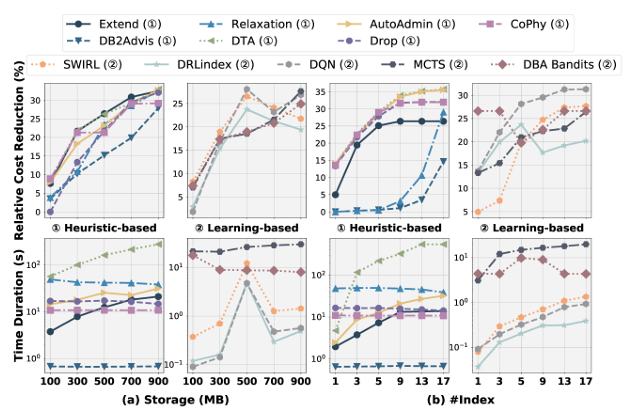
不同成本约束下的性能表现
O4(选择预算):在给定更大的存储预算时,基于启发式的索引推荐可识别更有效的索引,而基于学习的索引推荐可能在存储预算增加时返回较差的索引。随着存储和索引数量值的增加,基于启发式索引推荐的相对成本降低呈现上升趋势。当存储从500MB增加到900MB时,SWIRL和DRLindex的相对成本降低下降。这与中学习基数估算模型的发现一致,即对于添加了额外谓词的查询,估算基数会增加。基于学习方法的这种不可预测性引发了对其可靠性的担忧,缺乏可解释性使其不适用于有严格要求的实际应用。
4.2 动态分析场景
实验还构建了具有不同程度工作负载漂移(即查询变化)的工作负载,以验证索引推荐的鲁棒性:
● 频率变化:工作负载中的查询保持不变,但频率随机分配为[1,1000]中的值。
● 查询扰动:对工作负载中的查询应用一系列扰动(即添加新谓词),以模拟典型工作负载漂移。
● 随机生成:工作负载中的查询通过一些工作随机合成(如基于指定的连接谓词,选择谓词数量不同)。这模拟了由于大量工作负载漂移导致的极端工作负载变化,对索引推荐的鲁棒性提出了很高要求。
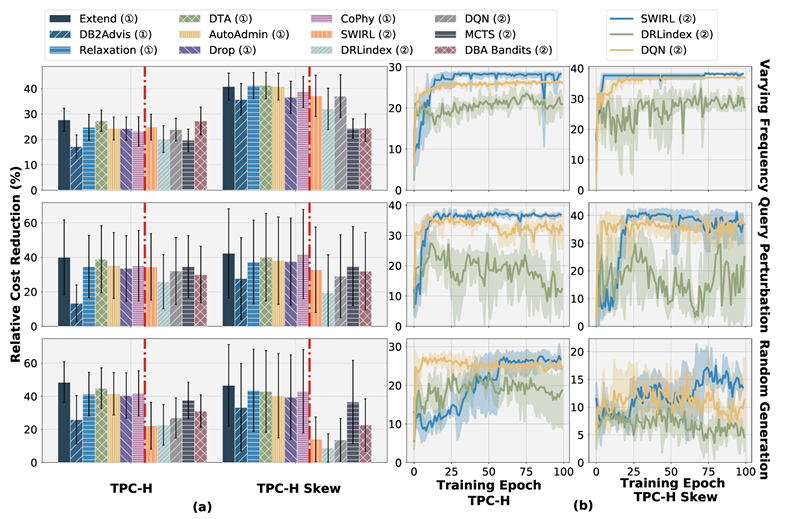
在不同工作负载下的索引推荐的相对成本降低
O5(频率变化与查询扰动):基于启发式和基于学习的索引推荐在频率变化和小扰动的工作负载上具有鲁棒性。如图(a)中,在TPC-H基准上,基于学习和基于启发式的索引推荐在频率变化和查询扰动的工作负载上实现了相似的相对成本降低,平均分别为28.53%和27.29%。然而,在具有偏斜数据分布的TPC-H Skew基准上,性能明显更差,平均分别为38.58%和30.31%。图(b)绘制了具有离线学习策略的基于学习索引推荐的训练曲线,在TPC-H Skew基准上的查询扰动工作负载中,其训练曲线的振荡程度高于TPC-H基准上的频率变化工作负载。所有这些结果表明,基于学习的索引推荐有能力处理简单数据分布上的轻微变化动态工作负载,因为它们可以通过几次试错尝试捕捉基本查询模式并识别有效索引。
O6(随机生成):基于学习的索引推荐的鲁棒性低于基于启发式的索引推荐,且在随机工作负载上收敛性较差。在随机生成工作负载上,基于学习的索引推荐获得的相对成本降低低于基于启发式的索引推荐。在TPC-H基准上,基于学习的索引推荐的相对成本降低平均为28.10%,而基于启发式的为40.61%。除了有效性较低外,基于学习的索引推荐在随机生成工作负载上的收敛性也较差,索引推荐表现出较差的收敛性能,尤其是在TPC-H Skew基准上。因为随机工作负载包含各种查询模式,这对学习良好的选择策略构成了重大挑战。因此,索引推荐需要大量试错尝试才能找到有效的索引解决方案。
4.3 事务场景
实验评估了索引推荐在事务工作负载上的性能,并研究由IUD语句(INSERT、UPDATE和DELETE语句)引起的数据偏移的影响。
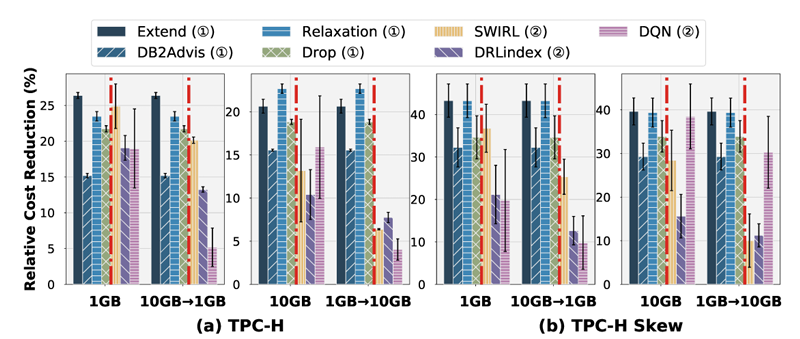
事务工作负载下的性能表现
O7(事务工作负载):索引推荐在具有简单SELECT语句的事务工作负载上表现良好。索引推荐在五个数据集上实现了可比的相对成本降低,时间开销通常较低,即跨数据集<100秒。根本原因可能归因于事务查询的特征,这些查询是来自预定义模板的选择-投影-连接(SPJ)查询,选择谓词较少,且没有复杂分析查询的多个嵌套子查询。简单的特征导致索引候选较少,减轻了识别有效索引的难度。
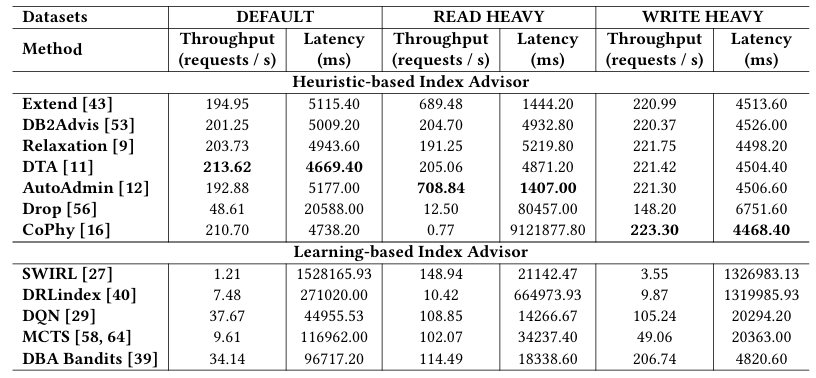
在TPC-C不同基准下的性能效果
O8(读写比变化):基于启发式的索引推荐在READ HEAVY工作负载上表现良好,而基于学习的索引推荐在包含IUD语句的工作负载上效果不佳。例如,Extend和AutoAdmin的吞吐量平均为699.16请求/秒(比其他高5.36倍),延迟平均为1425.6毫秒(比其他小698.38倍),优于其他索引推荐。然而,在DEFAULT或高写入比的WRITE HEAVY工作负载上,它们的优势减弱。同时,基于学习的索引推荐几乎无法超越基于启发式的索引推荐,尤其是在包含IUD语句的DEFAULT或WRITE HEAVY工作负载上。例如,SWIRL在DEFAULT和WRITE HEAVY工作负载上的吞吐量极低,根本原因可能是现有索引推荐在选择过程中仅考虑索引对SELECT语句的收益,忽略了IUD语句的开销。因此,索引推荐无法考虑IUD语句引起的负面影响,在处理大量IUD语句(即高写入比)的工作负载时表现不佳。
在数据偏移下的性能表现
O9(数据偏移):基于启发式的索引推荐在数据偏移时具有鲁棒性,而基于学习的索引推荐在发生数据偏移时性能下降。当基础数据量在1GB和10GB之间偏移时,基于启发式的索引推荐表现出一致的性能。然而,基于学习的索引推荐在发生数据偏移时遭遇性能下降。这种现象可能归因于基于启发式和基于学习的索引推荐的工作机制差异。基于启发式的索引推荐直接针对任何给定数据分布的工作负载重新进行索引选择,而基于学习的索引推荐使用离线过程中获得的学习策略返回索引,该策略专为特定数据分布定制。因此,学习策略不适用于变化的数据分布,基于学习的索引推荐由于学习策略与新数据分布不匹配而导致性能下降。
5. 模块的影响
5.1 索引候选生成
之前提到,有四种类型的索引候选生成方法;其中三种是基于启发式的,一种是基于学习的(即学习过滤模型)。一方面,本文通过将每个索引推荐中的原始模块替换为具有不同方法的三种变体,并保持其他模块不变,来评估各种基于启发式的候选生成方法的端到端性能:
● 排列:随机排列列以生成索引,再通过数据库优化器的假设调用过滤。
● 语法规则:启发式规则,考虑查询的语法特征。
● openGauss:不仅考虑查询的语法特征,还考虑索引列的统计信息。
另一方面,本文将学习过滤模型的性能与利用数据库优化器估算统计信息的方法进行比较。实验在DISTILL中实现学习过滤模型的多种变体,具有四种输入信号:
● 改进:计算并汇总索引可降低的查询计划中每个节点的成本。
● 查询形状:通过自底向上遍历将涉及表的查询计划中的节点类型连接起来表示每个表。
● 索引形状:将索引的每一列替换为查询中使用该列的第一个操作。
● 操作符:用涉及的索引列的统计信息表示查询计划中的每个节点。
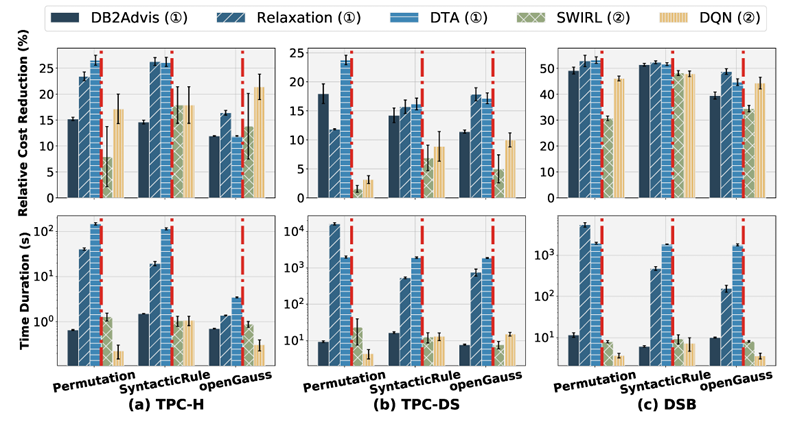
索引候选生成方法的结果
O10(生成方法):通过基于规则的构建生成的候选可增强基于学习的索引推荐的有效性和基于启发式的索引推荐的效率。基于学习的索引推荐在使用语法规则和openGauss时更有效。例如,SWIRL使用语法规则和openGauss的平均相对成本降低为21.04%,高于使用排列的13.40%。此外,基于启发式的索引推荐使用基于规则的构建方法更高效,尤其是在大型数据集上。这可能是由于基于规则构建生成的候选通常是小体积的有效索引,因此基于学习的索引推荐需要更少的训练工作来在这些有效索引上学习良好的选择策略,而基于启发式的索引推荐花费更少的时间开销来从候选空间中探索小集合。

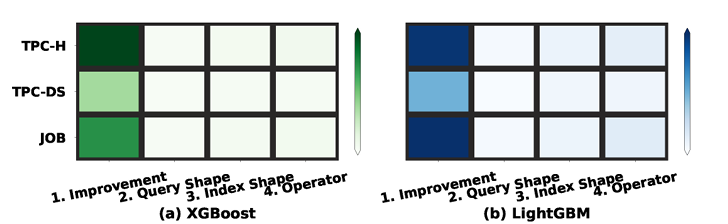
不同过滤模型的F1-分数结果
O11(学习过滤模型):基于树的过滤模型可有效过滤无用索引候选,其中改进是最关键的输入特征。实验表明,树基过滤模型的F1分数高于基于数据库优化器估算统计信息的方法。在不同过滤阈值s下,DIS-XGBoost的F1分数平均为0.89,而PostgreSQL为0.82。为进一步确定对这些模型的有效性贡献最大的输入特征,实验观察到改进是最关键的特征,这与索引的功能一致,即优化查询计划中节点的操作。因此,模型可以估算索引的影响并过滤掉影响低的候选。
输入特征的重要性分数分布
5.2 索引选择
由于基于启发式的索引推荐在索引选择中采用几乎相同的贪心算法,本文实验评估各种基于学习的索引推荐变体的性能。实验首先通过从输入中排除不同特征并观察相对成本降低的变化来计算状态表示中不同特征的重要性分数;然后验证现有索引推荐是否可以为查询以不同顺序组织的相同工作负载返回一致的索引;最后,实验开发多种索引推荐变体,其工作负载表示基于SQL文本或查询计划。这些表示进一步使用三种降维方法PCA、LSI和Doc2Vec转换为固定大小。
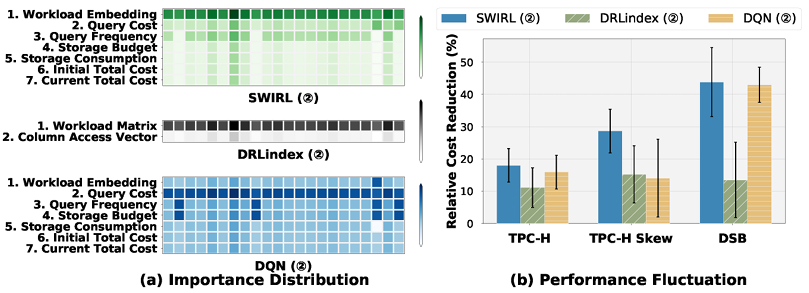
状态表示特征的重要性分数分布和相同负载下的性能方差
O12(状态表示):基于学习的索引推荐在表示排列不变性属性方面不稳定,其中基于查询计划的工作负载表示最为关键。图(a)显示了状态表示特征的重要性分数分布,其中每行对应状态的一个特征,每列是一个工作负载样本。实验观察到,工作负载表示是状态表示中最关键的特征。这是因为现有基于学习的索引推荐依赖工作负载,工作负载表示对于它们在训练期间为给定工作负载识别有效索引至关重要。然而,现有工作负载表示存在问题,因为它们无法保留排列不变性属性。对于查询被随机打乱(即以不同顺序组织)的相同工作负载,索引推荐无法产生一致的相对成本降低(即返回相同的索引)。这个根本原因是索引推荐按顺序处理工作负载中的查询,这与批量处理工作负载的无序性质相矛盾。
不同的状态表示下的性能
实验还发现基于查询计划的工作负载表示比SQL文本更有效。上图显示了SWIRL在各种工作负载表示下的性能。SWIRL使用基于查询计划和SQL文本的工作负载表示的平均相对成本降低分别为18.08%和10.03%。查询计划涉及更多反映索引优化机会的特定于索引的信息,因此基于查询计划的工作负载表示在识别有效索引方面比基于SQL文本的更具指导意义。
5.3 索引收益评估
实验最后评估各种收益评估模型的估算准确性和端到端性能(即更低的查询延迟):
●估算准确性Q-Error:实验评估PostgreSQL和openGauss中数据库优化器的假设调用。此外,实验评估基于树的模型XGBoost和LightGBM、基于注意力的模型LIB和基于Transformer的模型QueryFormer。本文还使用可解释机器学习算法识别这些模型的关键输入特征。
● 端到端性能:实验将学习模型集成到数据库中,并在选择过程和训练过程中使用它们替换数据库优化器来计算索引收益,比较使用这些学习模型的不同索引推荐返回的索引的查询延迟。
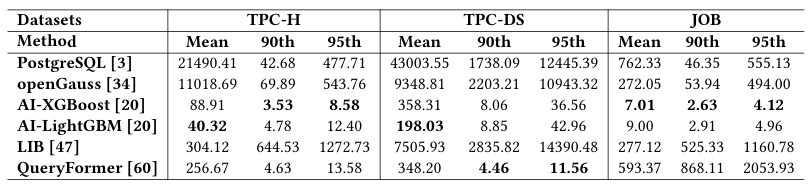
不同索引收益估计模型的Q-Error
O13(估算准确性):具有基于估算基数和成本的输入特征的树基模型比其他估算模型更准确。实验表明,基于树的模型在各种数据集上优于其他模型。AI-XGBoost和AI-LightGBM的第95个Q-Error为18.2,平均比数据库优化器低231.34倍,比其他学习模型低171.50倍。这可能归因于树模型用于估算索引收益的定义良好的索引相关特征向量。
输入特征的重要性分布
然而,其他模型需要更多的训练工作(即更高的训练难度)才能有效学习输入特征之间的相关性。上图显示了输入特征的重要性分布,其中每行对应于由可解释机器学习算法计算的重要性分数。实验观察到估算基数(Card)、估算成本(Cost)和谓词信息(Predicate)是这些学习模型的关键输入特征,这与索引的功能一致。
O14(端到端性能):具有更高准确性的学习收益评估模型可能不会带来更好的端到端性能。根据上述结果,QueryFormer在TPC-H基准上的第95个Q-Error为13.58,而查询延迟平均为32521.21毫秒,是PostgreSQL的20643.83毫秒的1.58倍。这可能归因于学习收益评估模型的优化目标与索引选择之间的差异。因此,在估算模型中实现高准确性可能不会带来更好的索引解决方案。
6. 总结发现
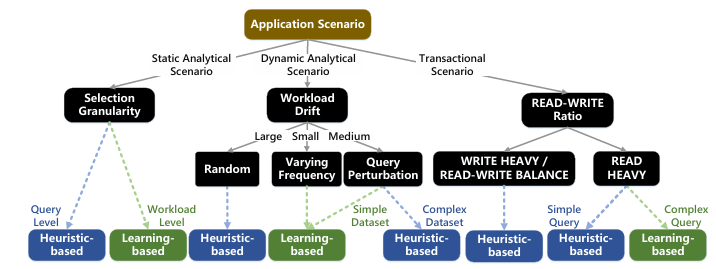
不同索引推荐的应用场景
1. 应用场景:上图总结了基于启发式和基于学习的索引推荐的应用场景:
● 静态分析场景:基于启发式的索引推荐在查询级选择上表现良好,时间开销小。基于学习的索引推荐在包含各种查询模式的工作负载级选择上比基于启发式的索引推荐能识别更有效的索引。此外,具有离线学习策略的基于学习的索引推荐比基于启发式的索引推荐和具有在线学习策略的基于学习的索引推荐更高效。然而,基于学习的索引推荐表现出更高的性能方差,并且在更大的存储预算下可能遭遇性能下降。
● 动态分析场景:基于学习的索引推荐可以适应小工作负载漂移和中等工作负载漂移;而在大工作负载漂移上,基于启发式的索引推荐比基于学习的索引推荐更具有鲁棒性。
● 事务场景:基于启发式的索引推荐在具有简单事务查询的READ HEAVY工作负载上表现良好。此外,在WRITE HEAVY工作负载上,它们比基于学习的索引推荐对数据偏移更具有鲁棒性。
2. 设计选择:
● 索引候选生成:基于启发式的索引推荐更高效,基于学习的索引推荐使用基于规则的构建比随机列排列更有效,尤其是在大型数据集上。前缀扩展高度依赖于底层选择算法的质量,并不适用于所有索引推荐,而基于树的学习过滤模型可有效过滤无用索引候选,估算索引影响是最关键的输入特征。
● 索引选择:对于启发式搜索策略,减量迭代方式比增量迭代方式更耗时,尤其是在具有许多候选的大型数据集上。对于数学求解器,它在不同存储预算下表现出恒定的效率。对于学习选择策略,基于查询计划的工作负载表示是最关键的输入特征。
● 索引收益评估:使用具有估算基数和成本作为输入特征的树基模型比其他模型更准确。
3. 未来方向:首先,需要进一步研究泛化能力,以使高级索引推荐能够处理各种场景。基于学习的索引推荐需要在查询漂移和数据偏移上更具有鲁棒性。而基于启发式的索引推荐需要在大规模工作负载上更高效。其次,需要解决更多因素以促进索引推荐在实际场景中的应用,比如考虑INSERT或UPDATE语句的索引更新开销。以及需要建模重要且相关的数据库状态,使用不同的索引物理实现(如B树或哈希)计算索引收益。
7. 结论
本文首次对现有基于启发式和基于学习的索引推荐进行了全面回顾,并结合广泛的实验评估其性能并探索其合适的应用场景。此外,本文还通过构建多种索引推荐变体深入研究了各个模块的影响,从而识别出最有效的方法和最具影响力的因素。最后,作者总结了研究发现,为用户在其应用场景中选择合适的索引推荐提供指导。本文还提供了一个开源测试平台,旨在简化各种索引推荐的评估。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





