




碎片产生的原因
Oracle 对数据段的管理有一个高水位(HWM, High Water Mark)的概念。高水位是数据段中使用过和未使用过的数据块的分界线。高水位以下的数据块是曾使用过的,以上的是从未被使用或初始化过的。
当表或索引在表空间中频繁地进行DML操作时,表中空闲的数据块(高水位以下)无法被有效的利用,例如一些不连续地空间,无法被有效利用时。数据库的数据块就会产生碎片。
碎片的影响
碎片的产生会导致存储空间利用率低下,并且影响数据库的性能。
以全表扫描为例:
当 Oracle 进行全表扫描(FTS, Full table scan)的操作时,它会读高水位下的所有数据块。当高水位下还有很多空闲空间(碎片),读取这些空闲数据块会降低操作的性能。索引碎片同理(解决办法:重建索引+online)。
产生行链接和行迁移
- 行链接 Row Chaining
当插入数据量大的行的,如果一个Block不能存放一条记录,该记录的一部分会存储到同个Extent中的其他Block,这些block形成一个数据块链。 - 行迁移 Row Migration
当Update的时候导致记录长度增加了,存储的Block已经满了,就会发生行迁移。Oracle会迁移整行数据到一个能够存储下整行数据的Block中,迁移的原始指针指向新的存放行数据的Block,ROWID不变。
当数据行发生链接(chain)或迁移(migrate)时,对其访问将会造成 I/O 性能降低,因为Oracle为获取这些数据行的数据,必须访问更多的数据块(data block)。
- 行链接&行迁移检测方案
-- 检测方案1:
-- 执行脚本创建chained_rows表
@?/rdbms/admin/utlchain.sql
-- 执行分析命令
ANALYZE TABLE 表名 LIST CHAINED ROWS INTO chained_rows;
-- 确认存在行迁移/链接的记录
SELECT owner_name, table_name, head_rowid
FROM chained_rows;
-- 检测方案2:
-- 分析表
exec dbms_stats.gather_table_stats(ownname=>'HR',tabname=> 'EMPLOYEES');
-- 查看
SELECT table_name, chain_cnt
FROM user_tables
WHERE table_name = 'EMPLOYEES';
TABLE_NAME CHAIN_CNT
-------------- ----------
EMPLOYEES 891 --产生迁移
- 解决行迁移&行链接思路
行迁移:由UPDATE导致记录超出块空间,需迁移数据(可优化PCTFREE解决)。
行链接:记录长度超块大小(如LOB字段),需调整块大小或拆分表结构
解决方案
1、支持在线操作-在线重定义(dbms_redefinition)
-- 1. 检查表是否可重定义
EXEC DBMS_REDEFINITION.CAN_REDEF_TABLE('SCOTT', 'EMPLOYEES');
-- 2. 创建中间表(结构需包含新列或修改后的定义)
CREATE TABLE employees_interim AS SELECT * FROM employees WHERE 1=0;
-- 3. 启动重定义
EXEC DBMS_REDEFINITION.START_REDEF_TABLE('SCOTT', 'EMPLOYEES', 'EMPLOYEES_INTERIM');
-- 4. 复制依赖对象(可选,不建议使用,结构手动创建更有把控性)
-- 注意:复制的约束(如主键、唯一约束、外键)在中间表上默认处于 DISABLED 状态。这些约束会在 FINISH_REDEF_TABLE 切换完成后,在新表(原中间表)上自动启用;
-- 索引会被创建,但可能需要在切换后重建以优化性能(尤其是改变了表结构或分区时)
DECLARE
l_errors NUMBER;
BEGIN
DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS(
uname => 'SCOTT',
orig_table => 'EMPLOYEES',
int_table => 'EMPLOYEES_INTERIM',
copy_indexes => DBMS_REDEFINITION.cons_orig_params,
copy_triggers => TRUE,
ignore_errors => FALSE,
num_errors => l_errors
);
DBMS_OUTPUT.PUT_LINE('Errors: ' || l_errors);
END;
/
-- 5. 同步数据
exec dbms_redefinition.sync_interim_table('SCOTT', 'EMPLOYEES', 'EMPLOYEES_INTERIM');
-- 6. 完成重定义
EXEC DBMS_REDEFINITION.FINISH_REDEF_TABLE('SCOTT', 'EMPLOYEES', 'EMPLOYEES_INTERIM');
2、不支持在线操作
1)表迁移
– 注:需手动重建索引和 LOB 字段的存储定义
-- 表迁移
ALTER TABLE table_name MOVE TABLESPACE new_tablespace;
-- 索引重建
alter index index_name rebuild tablespace tablespace_name;
-- 表中有LOB相关字段,使用如下命令迁移表。
alter table tb_name move tablespace tbs_name lob (col_lob1,col_lob2) store as(tablesapce tbs_name);
- 导出导入操作
用exp/imp(expdp/impdp)导出后,重新导入重建,在重新创建索引和重新收集统计信息。
2)Shrink 命令,需要表空间是基于自动段管理的。
- 优化点:不需要索引重建
- 半支持在线操作:整理数据不回收空间(可在线),回收空间会锁表(不支持在线)
-- 整理表,不影响DML操作
--启动行移动功能
alter table TABLE_NAME enable ROW MOVEMENT;
--只整理碎片 不回收空间
alter table TABLE_NAME shrink space compact;
-- 重置高水位,此时不能有DML操作
-- 整理碎片并回收空间,并调整水位线。业务少时执行
alter table TABLE_NAME shrink space;
--关闭行移动
alter table TABLE_NAME disable ROW MOVEMENT;
-- 也可以一步到位:会锁表
alter table TABLE_NAME shrink space;
查看表碎片
set lines 199 pagesize 199
set COLSEP '|'
SELECT table_name,
ROUND ( (blocks * 8)/1024/1024, 2) "高水位空间 G",
ROUND ( (num_rows * avg_row_len /1024)/1024/1024, 2) "真实使用空间 G",
ROUND ( (blocks * 10 / 100) * 8/1024/1024, 2) "预留空间(pctfree) G",
ROUND ( (blocks * 8 - (num_rows * avg_row_len / 1024) - blocks * 8 * 10 / 100)/1024/1024, 2) "浪费空间 G"
FROM dba_tables
WHERE temporary = 'N' and ROUND ( (blocks * 8)/1024/1024, 2)>10
ORDER BY 5 DESC;
查看表空间碎片
- 1、查看fsfi值
-- 数字越小,表空间碎片较多,当小于30%的时候说明碎片程度很可观了。
set lines 199 pagesize 199
set COLSEP '|'
select a.tablespace_name,
trunc(sqrt(max(blocks)/sum(blocks))* (100/sqrt(sqrt(count(blocks)))),2) fsfi
from dba_free_space a,dba_tablespaces b
where a.tablespace_name=b.tablespace_name
and b.contents not in('TEMPORARY','UNDO','SYSAUX')
group by A.tablespace_name
order by fsfi;
- 2.查看dba_free_space
dba_free_space 显示的是有free 空间的tablespace,如果一个tablespace的free 空间不连续,那每段free空间都会在dba_free_space中存在一条记录。如果一个tablespace 有好几条记录,说明表空间存在碎片,当采用字典管理的表空间碎片超过500就需要对表空间进行碎片整理。
set lines 199 pagesize 199
set COLSEP '|'
SELECT a.tablespace_name, COUNT (1) 碎片量
FROM dba_free_space a, dba_tablespaces b
WHERE a.tablespace_name = b.tablespace_name
AND b.contents NOT IN ('TEMPORARY', 'UNDO', 'SYSAUX')
GROUP BY a.tablespace_name
HAVING COUNT (1) > 20
ORDER BY 2;
注:以上查询基于数据字典表,因为想要获取最新的数据需要对表或用户进行信息收集
收集统计信息
- 收集表统计信息
SQL> exec dbms_stats.gather_table_stats(ownname=>'SCHEMA_NAME',tabname=> 'TABLE_NAME');
- 整个 Schema 中对象的统计信息
SQL> exec dbms_stats.gather_schema_stats(ownname=>'SCHEMA_NAME');
测试Shrink命令整理表碎片的效果
- 表及数据准备
SYS@phytest1:1411> create table t1 TABLESPACE TWO_DAT as select * from dba_objects;
Table created.
SYS@phytest1:1411> insert into t1 select * from t1;
76795 rows created.
SYS@phytest1:1411> /
153590 rows created.
......(执行8次)
SYS@phytest1:1411> commit;
Commit complete.
SYS@phytest1:1411> select count(*) from t1;
COUNT(*)
----------
9829760
- 输出格式
SYS@phytest1:1411> set lines 199 pagesize 199
SYS@phytest1:1411> set COLSEP '|'
SYS@phytest1:1411> set timing on
- 收集T1表信息
SYS@phytest1:1411> exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=> 'T1'); PL/SQL procedure successfully completed. Elapsed: 00:00:13.20
- 查看表碎片:113.88MB

- 删除数据
SYS@phytest1:1411> delete from T1 where object_type in('INDEX','TABLE','SYNONYM');
4720384 rows deleted.
Elapsed: 00:00:37.42
SYS@phytest1:1411> commit;
Commit complete.
- 再次分析表
SYS@phytest1:1411> exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=> 'T1'); PL/SQL procedure successfully completed. Elapsed: 00:00:13.20
- 查看表碎片:555.04MB,增加了400+MB的碎片

- 查看执行计划
SYS@phytest1:1411> set autotrace trace
SYS@phytest1:1411> select count(*) from t1 where object_type='TRIGGER';
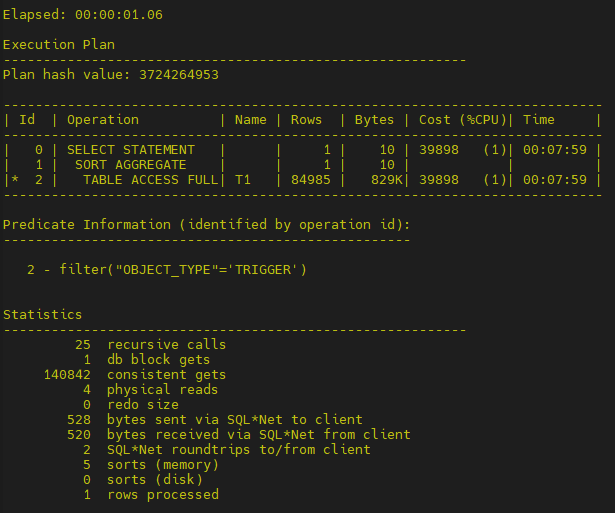
- 只整理数据不回空间
SYS@phytest1:1411> alter table t1 enable ROW MOVEMENT;
Table altered.
Elapsed: 00:00:00.01
SYS@phytest1:1411> alter table t1 shrink space compact;
Table altered.
Elapsed: 00:01:33.96
- 再次分析表
SYS@phytest1:1411> exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=> 'T1'); PL/SQL procedure successfully completed. Elapsed: 00:00:13.20
- 查看碎片情况

- 再次查询观察执行计划
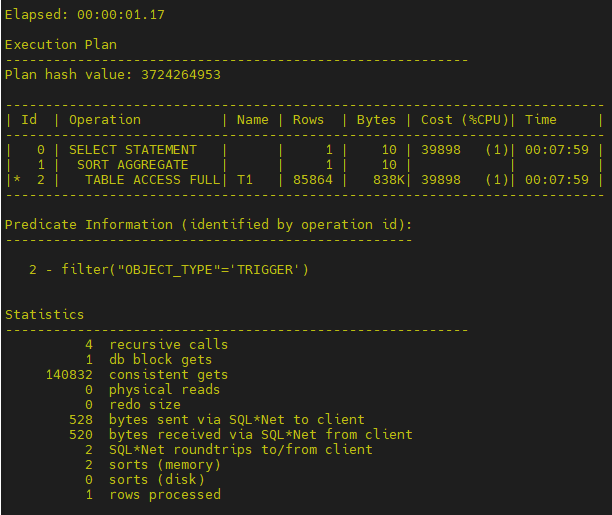
以上结果证明,只整理数据不释放空间对查询没有影响,对于Insert会有提高,可以整理出连续空闲空间。 - 回收空间
SYS@phytest1:1411> alter table t1 shrink space;
Table altered.
Elapsed: 00:00:00.84
SYS@phytest1:1411> alter table t1 disable ROW MOVEMENT;
Table altered.
Elapsed: 00:00:00.01
- 再次收集
SYS@phytest1:1411> exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=> 'T1'); PL/SQL procedure successfully completed. Elapsed: 00:00:08.02
- 查看碎片:仅剩:34.7MB

- 再次查看执行计划
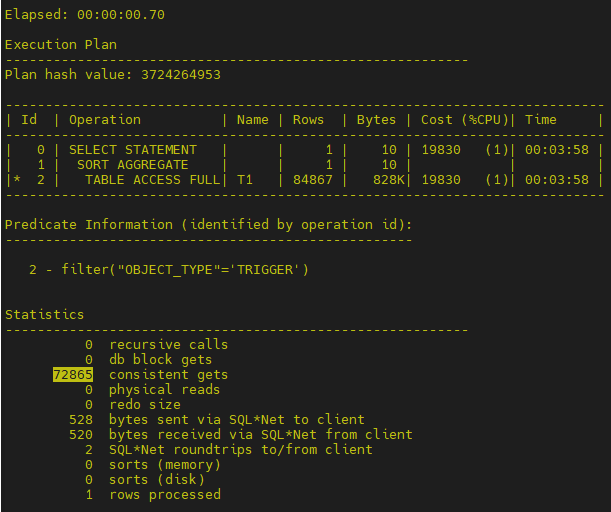
以上执行计划对比,效率提升及逻辑读减少近1倍。
测试小结
- 1、整理碎片不降低高水位释放空间的话,对于查询没有效果;
- 2、仅整理数据,会将小碎片整理出连续的空间,理论上会对Insert 会有提升,未测试;
- 3、Shrink 操作开启行移动,相当于对数据行进行移动整理,大表操作需要关注UNDO空间变化;
- 4、通过上以操作测试对于碎片的整理个人推荐使用dbms_redefinition操作;
欢迎赞赏支持或留言指正

最后修改时间:2025-07-11 08:45:27
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
