




编者按:起初我们是想邀请罗敏老师分享一些关于数据库性能优化的思维陷阱,为DBA们的优化工作提供避坑经验。没想到罗老师洞见症结、突破常规思路,并非停留在碎片化的优化技巧而是直接将SQL优化的复杂问题拆解为清晰的两类场景,结合实际案例和具体SQL优化过程,展示了在面对一条SQL语句时应当如何判断优化方向、进而精准运用优化策略。
如果你想知道如何在数据库性能优化中于宏观战略与微观技术之间找到平衡、如何对症下药找到优化再优化的方法,欢迎阅读本文,希望你能有所收获、让传统优化思路焕发新生!
作者简介

罗敏:数据库资深技术专家,《品悟性能优化》、《感悟Oracle核心技术》和《Oracle数据库技术服务案例精选》等数据库畅销书作者。
世上万事都是讲求宏观与微观、战略与战术的结合,在性能优化领域也应追求确定大方向和技术细腻运用的融合,即所谓大气磅礴和精雕细琢的融合。本文先总体梳理OLTP和OLAP两类应用不同特点,以及性能优化中技术运用的差异性,然后通过若干具体SQL语句优化过程的深入刨析,诠释性能优化中大方向定位和精准运用技术这两大要素的同等重要性。
一、性能优化之两大方向
众所周知,IT系统总体上可分为联机交易(OLTP)和联机分析(OLAP)两类系统,OLTP和OLAP在业务特征和技术运用方面都存在差异性,以下对比分析表格既基于业内同行凝结的性能优化方法论和最佳实践经验,也是我自己多年总结的实战体会。
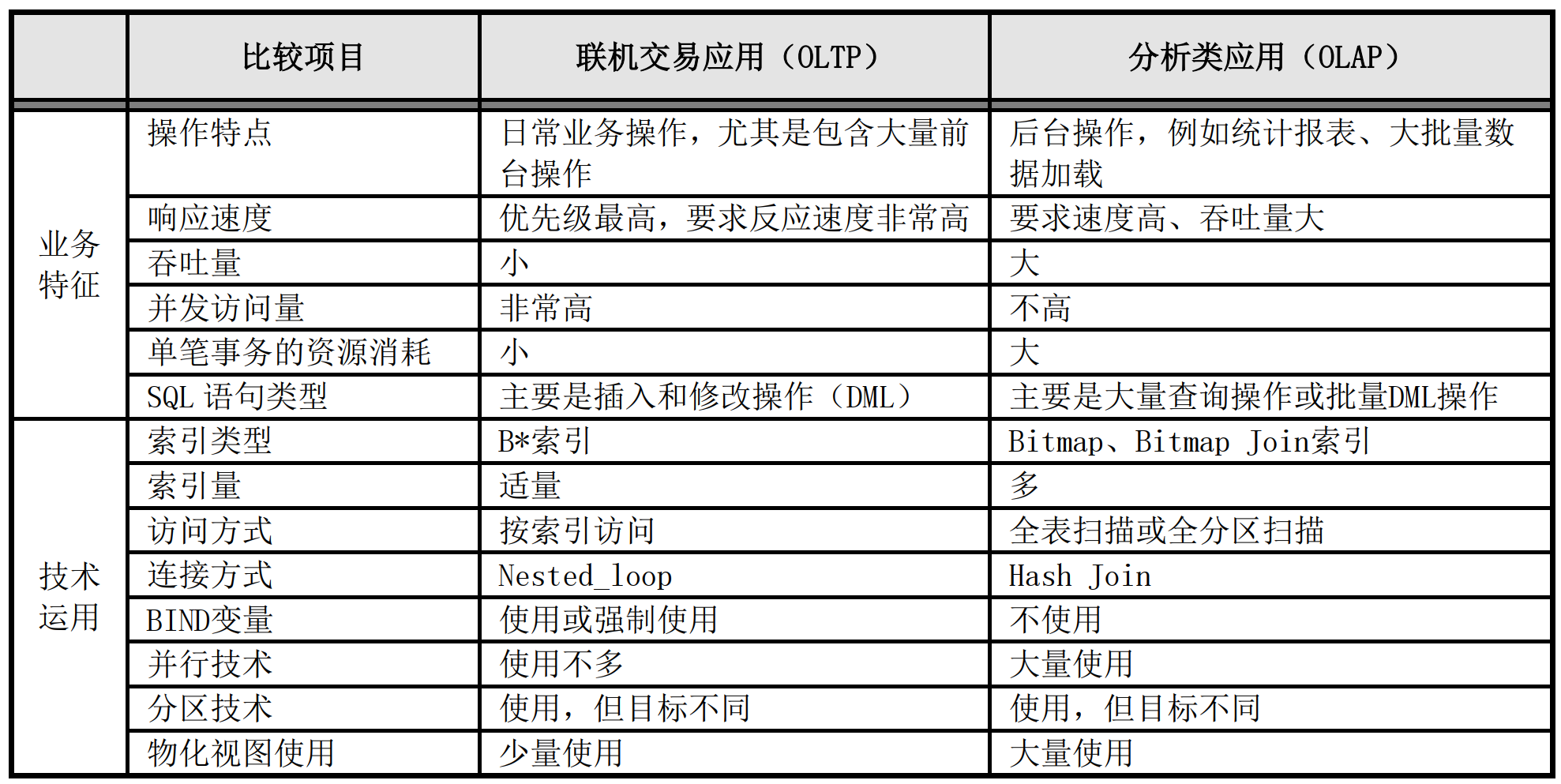
典型的OLTP系统包括银行核心业务系统、网银系统、ATM系统、手机银行系统等,还有电信运行商的CRM系统、计费系统、账务系统等,也包括保险行业的承保系统、赔付系统等,这些系统一大业务特点就是面向广大客户,具有并发量高、单笔事务小的特点,例如都是查询某个客户账号、手机号、保单号的信息。因此在技术运用方面,OLTP系统一个基本策略就是大海捞针,于是索引、分区索引、嵌套循环(Nested_loop)连接技术等就成为了主要的技术策略,还有尽量使用绑定变量,降低高并发语句的硬解析次数,以及不采用并行处理等技术策略。
典型的OLAP系统和应用包括报表系统、统计分析系统、数据集市和数据仓库系统,以及OLTP系统中的夜间跑批、季度结息、年终决算等批处理应用。此类系统的业务方面具有并发量不高、单笔事务大的特点,例如按时间、地区等维度进行全行的存款额统计汇总等。因此在技术运用方面,OLAP系统一个基本策略就是大气磅礴的大吞吐量、大批量处理,于是全表扫描、全分区扫描、哈希连接(HASH JOIN)、并行处理等技术成为了主要的技术策略,而各种索引技术运用并不一定是首选技术。即便使用索引,也是采用Bitmap、Bitmap Join等更适合统计分析的索引技术。另外OLAP应用通常不建议使用绑定变量,目的就是让数据库优化器明明白白地基于常量来确保复杂统计分析语句的执行计划最优化。
总之,联机交易(OLTP)和联机分析(OLAP)两类系统在业务和技术运用方面都各有特点甚至风格迥异。我们在性能优化工作中第一个关注点就应该是明确SQL语句是OLTP还是 OLAP语句,然后心中也就有了该运用哪些技术的大方向,再然后才是不同领域技术运用的精雕细琢。
二、OLTP型优化案例
以下是该语句主要框架:
select *
from (select row_.*, rownum rn
from (SELECT tt.*
FROM (SELECT POST.*,
e.emp_name AS operatorEmpName,
ve.acco_item_code,
ve.acco_item_name
FROM (SELECT DISTINCT *
FROM RFM_POST_VOUCHER t
WHERE t.is_delete = '0'
and (t.is_search != '1' or
t.is_search is null)
and t.account_date >=
to_timestamp(:1,
'yyyymmdd HH24:MI:SS.FF')
and t.account_date <=
to_timestamp(:2,
'yyyymmdd HH24:MI:SS.FF')
and t.voucher_state_code in (:3)
and t.COMP_CODE in (:4)
and t.IS_HANDWORK = :5) POST
left join mdm_employee e
on e.emp_id = POST.operator_code
left join rfm_voucher_entry ve
on ve.voucher_id = POST.voucher_id) tt
WHERE exists (select 1
from (select dbc.sec_value as org_id
from dic_bigsecurity_rcache dbc
where (dbc.sec_role in (:6,
:7,
:8,
...
:317))
and dbc.bussobject_code = 'RMF0001') B
WHERE B.org_id = tt.org_id)
and tt.acco_Item_Code = :318) row_
where rownum <= 10)
where rn > 0
对一个复杂语句的性能分析,我的第一个经验就是先判断其总体架构。原来该语句是RFM_POST_VOUCHER、mdm_employee、rfm_voucher_entry、dic_bigsecurity_rcache四张表的关联查询。其次,该语句既有按时间、单位查询RFM_POST_VOUCHER表,也有按权限查询dic_bigsecurity_rcache表的谓词条件,我们暂且忽略语句中的标志、代码等谓词条件,于是可总体判断出该语句就是典型的OLTP型语句,因此按“索引+ Nested Loop Join”进行访问将是这个语句的主要优化大方向。更进一步,由于RFM_POST_VOUCHER和dic_bigsecurity_rcache都含谓词条件,因此哪个表的过滤条件更强,也就是哪个表成为驱动表是本语句优化的主要关注点。
以下是现有执行计划的示意图:
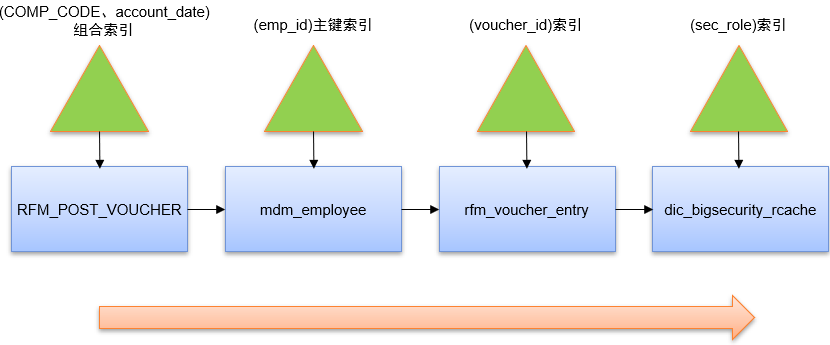
即先按RFM_POST_VOUCHER (COMP_CODE、account_date)组合索引访问RFM_POST_VOUCHER表,再按mdm_employee(emp_id)主键索引访问mdm_employee表,再按rfm_voucher_entry(voucher_id)索引访问rfm_voucher_entry表,最后按dic_bigsecurity_rcache(sec_role)索引访问dic_bigsecurity_rcache表。
优化空间何在呢?我发现目前执行计划中按dic_bigsecurity_rcache(sec_role)索引访问dic_bigsecurity_rcache表的cost达到3006,因此应通过被驱动表(dic_bigsecurity_rcache)的连接字段(org_id)与其谓词字段(sec_role)的组合索引访问dic_bigsecurity_rcache表,即创建dic_bigsecurity_rcache(sec_value,sec_role)组合索引。优化之后按新索引问dic_bigsecurity_rcache表的cost降到306。这就是新执行计划示意图:
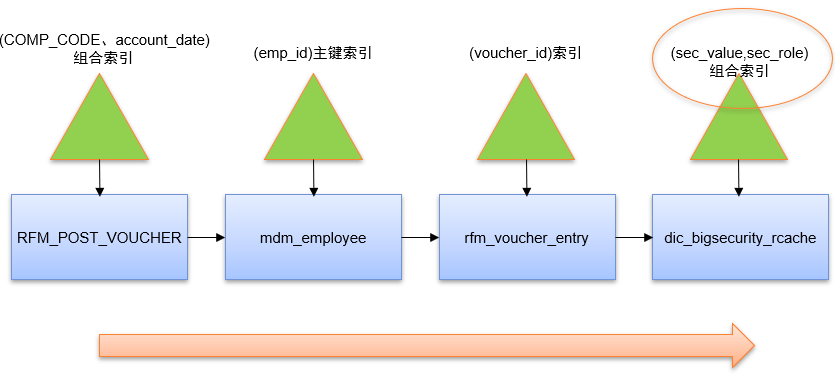
经验总结:应尽量通过被驱动表的连接字段与其谓词字段的组合索引访问被驱动表,除非被驱动表的连接字段已经是主键索引,或者其它谓词字段选择性不高。
但是在上述优化之后,该语句仍然出现在Top-SQL语句之列,于是我通过SQL Monitor工具看到的真实执行计划示意图如下:
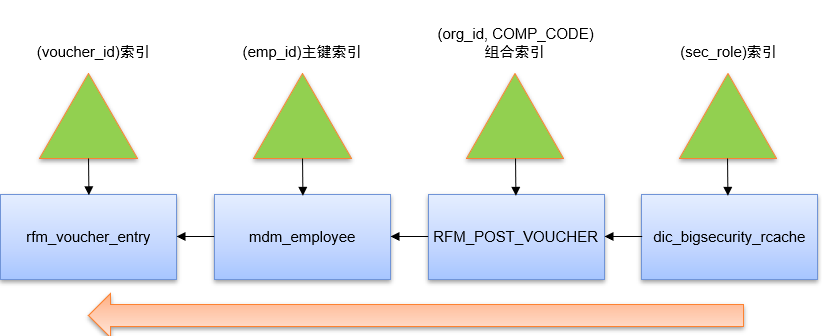
即由于account_date绑定变量值(:1,:2)的取值范围达到3年,于是优化器先按过滤性更强的dic_bigsecurity_rcache(sec_role)索引访问dic_bigsecurity_rcache表,再按RFM_POST_VOUCHER (org_id)索引访问RFM_POST_VOUCHER表,再按mdm_employee(emp_id)主键索引访问mdm_employee表,最后按rfm_voucher_entry(voucher_id)索引访问rfm_voucher_entry表。
那么进一步的优化空间何在呢?原来通过SQL Monitor发现,基于RFM_POST_VOUCHER (org_id)索引访问RFM_POST_VOUCHER表的记录数达到3M,过滤性很差。因此应该在被驱动表RFM_POST_VOUCHER的连接字段org_id和过滤性强的COMP_CODE谓词字段创建RFM_POST_VOUCHER(org_id,COMP_CODE)组合索引。由于account_date查询范围达到3年,过滤性差,因此不设置为组合索引字段。这就是最终优化效果,可见优化效果显著。
这里做一个总结:
- 首先,在大方向上将该语句定位为OLTP型语句,于是技术运用就是在“索引+Nested Loop Join”方面的精雕细琢。
- 其次,该语句关键在于确定以哪个表作为驱动表,并协助优化器在被驱动表的连接字段与其谓词字段上精准设计高效的组合索引来访问被驱动表。本语句中,如果优化器将RFM_POST_VOUCHER作为驱动表,我们就设计了dic_bigsecurity_rcache(sec_value,sec_role)组合索引,如果优化器将dic_bigsecurity_rcache作为驱动表,我们就设计了RFM_POST_VOUCHER(org_id,COMP_CODE)组合索引,即总有一款适合优化器。
- 第三,感叹Oracle ACS功能(Adaptive Cursor Sharing)的强大,即让Oracle优化器能根据客户输入条件的不同,灵活选择不同的驱动表和最佳执行计划。具体而言,如果account_date查询范围小,则以RFM_POST_VOUCHER作为驱动表,否则以dic_bigsecurity_rcache作为驱动表。
最后要总结的是,Oracle优化器目前还无法自动创建索引尤其是组合索引,还需要开发人员和DBA的精准分析,做出合理的组合索引设计,这就是人机互动和人机高度融合。
三、OLAP型优化案例1
以下是该语句文本:
update ZJ_YJH_ZXJL_HIS JL
set F_DJBH =
(select F_DJBH from ZJWBSKXX YW where YW.F_ID = JL.F_DJID)
where JL.F_YWTABLE = :"SYS_B_0"
and JL.F_YWCOL = :"SYS_B_1"
and trim(JL.F_DJBH) is null
and exists
(select :"SYS_B_2" from ZJWBSKXX YW where YW.F_ID = JL.F_DJID)
AND ((F_DATE = TO_CHAR(SYSDATE, :"SYS_B_3") AND F_ZQLX = :"SYS_B_4") OR
(F_DATE = TO_CHAR(SYSDATE, :"SYS_B_5") AND F_ZQLX = :"SYS_B_6"))
以下是SQL Monitor中看到的该语句绑定变量取值情况:
============================================================================= | Name | Position | Type | Value | ============================================================================= | :SYS_B_0 | 1 | VARCHAR2(32) | ZJWBSKXX | | :SYS_B_1 | 2 | VARCHAR2(32) | F_ID | | :SYS_B_3 | 4 | VARCHAR2(32) | YYYYMM | | :SYS_B_4 | 5 | VARCHAR2(32) | YB | | :SYS_B_5 | 6 | VARCHAR2(32) | YYYYMMDD| | :SYS_B_6 | 7 | VARCHAR2(32) | RB | ==============================================================================
即该语句是按时间进行数据update操作,F_date=TO_CHAR(SYSDATE, ‘YYYYMM’) 表示对当月数据进行处理,于是可总体分析出该语句是典型的OLAP大批量数据处理语句,于是分区扫描、Hash Join、并行处理等技术应该是该语句的主要运用技术。而当前的执行计划和示意图如下:
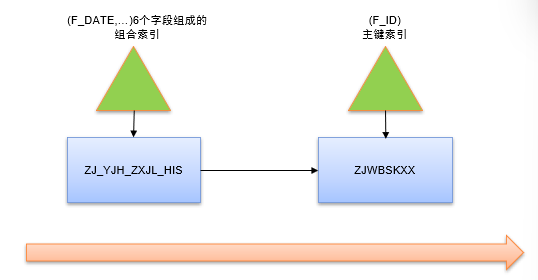
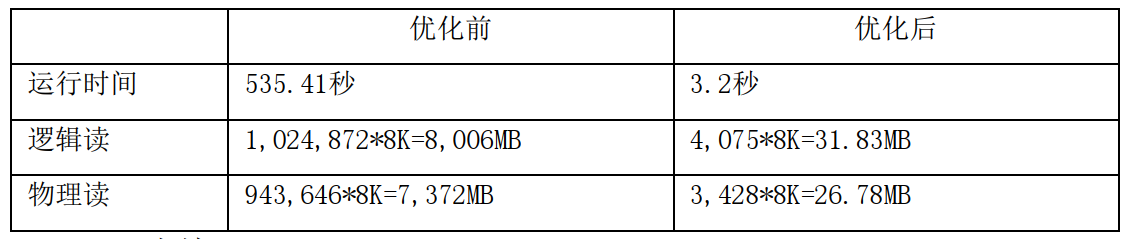
即先按ZJ_YJH_ZXJL_HIS (F_DATE,…)6个字段组成的组合索引访问ZJ_YJH_ZXJL_HIS表,再按ZJWBSKXX (F_ID)主键索引访问ZJWBSKXX表。虽然按索引访问两个表,但存在大量索引回表操作,资源消耗很大,性能并不是很好。这也恰好违背了OLAP型语句的技术运用策略。
优化空间何在?既然是访问当前月整月数据,那么按月实施分区,无需索引、直接通过分区裁剪和分区扫描访问技术,将避免大量索引回表操作。于是,我先对ZJ_YJH_ZXJL_HIS表基于F_DATE字段按月分区,新的执行计划和示意图如下:
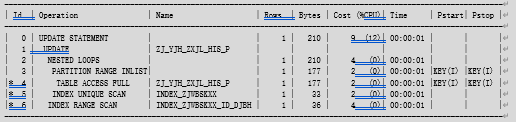
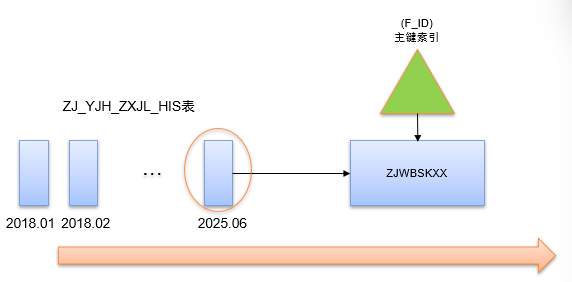
即先基于分区裁剪技术对ZJ_YJH_ZXJL_HIS表的当月数据进行分区扫描,再按ZJWBSKXX (F_ID)主键索引访问ZJWBSKXX表。实际效果是性能有一定提升,但对ZJWBSKXX表依然按索引进行大量数据的回表访问,性能提升有限。
于是我决定对ZJWBSKXX表也基于F_TXDATE字段按月分区,并通过与开发人员进行业务逻辑确认,其实ZJWBSKXX表的F_TXDATE字段与ZJ_YJH_ZXJL_HIS表的F_DATE字段逻辑含义一致,本可在语句中增加JL.F_DATE=YW.F_TXDATE关联条件,通过谓词推入功能,将时间条件带入对ZJWBSKXX表的访问中,但保险起见,我还是直接将语句修改如下:
update ZJ_YJH_ZXJL_HIS_p JL
set F_DJBH =
(select F_DJBH from ZJWBSKXX_p YW where YW.F_ID = JL.F_DJID and (F_txdate = TO_CHAR(SYSDATE, 'YYYYMM') OR F_txdate = TO_CHAR(SYSDATE, 'YYYYMMDD')))
where JL.F_YWTABLE = 'ZJWBSKXX'
and JL.F_YWCOL = 'F_ID'
and trim(JL.F_DJBH) is null
and exists
(select 1 from ZJWBSKXX_p YW where YW.F_ID = JL.F_DJID and (F_txdate = TO_CHAR(SYSDATE, 'YYYYMM') OR F_txdate = TO_CHAR(SYSDATE, 'YYYYMMDD')))
AND ((F_DATE = TO_CHAR(SYSDATE, 'YYYYMM') AND F_ZQLX = 'YB') OR
(F_DATE = TO_CHAR(SYSDATE, 'YYYYMMDD') AND F_ZQLX = 'RB'))
新的执行计划和示意图如下:
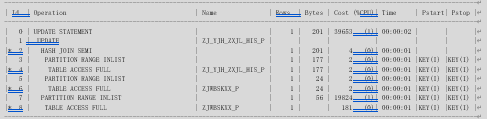
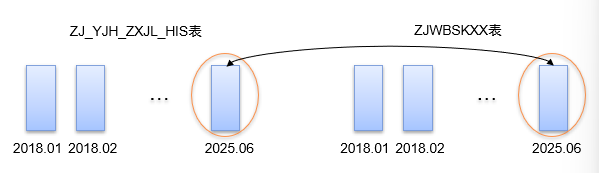
即新的执行计划是先基于分区裁剪技术对ZJ_YJH_ZXJL_HIS表的当月数据进行分区扫描,其次,基于分区裁剪技术对ZJWBSKXX表的当月数据进行分区扫描,最后通过HASH JOIN技术进行两个分区表裁剪之后的关联操作。这就是最终优化效果:
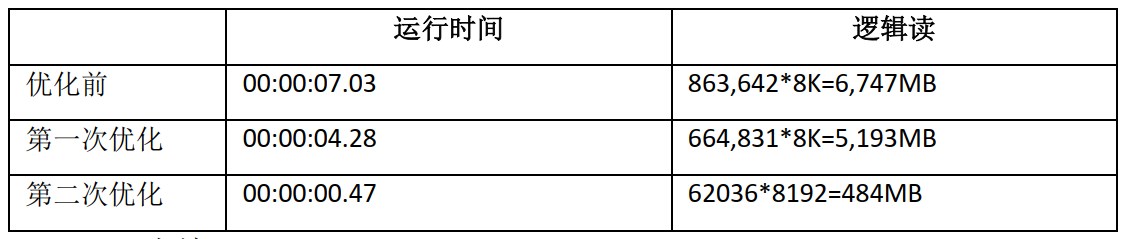
首先需要总结的是在优化大方向上将该语句定位为OLAP型语句,于是在分区设计、分区裁剪、Hash Join等方面下功夫。其次,再次感悟到OLAP型应用应该贯彻大批量、并行处理策略,无需采用通过索引逐条记录处理的蚂蚁搬家方式。
最后打个通俗比方:如果我们要看一本书中的某一页,则需要通过目录进行查找。如果要看一本书的整章内容,就不需要目录,直接翻到该章就可以了。其中目录就是索引,整章就是分区。
四、OLAP型优化案例2
“只要按索引访问了,性能一定不会太差”,我想这是业内很多技术人员的共识,但我认为这也是误区之一。 于是,我决定再分享一个银行季度结息的案例,来帮助大家纠正这个误区。
当年我去某银行现场为其季度结息业务提供现场值守服务,当时季度结息需要熬个通宵的8小时。具体原因是三个:最大的账户类表没有分区,结息应用只跑在RAC一个节点上,采取逐条记录处理模式。本文仅讲述如何通过分区方案的实施,有效提升结息应用速度。
这就是季度结息的简单语句:
select B.KEY_1,
B.TOD_CDEP_TOT_AMT,
... ...
B.LAST_MAINT_STAT
from INVE B
where B.KEY_1 between :b1 and :b2
order by B.KEY_1
执行计划就是按账户表(INVE)的账号(KEY_1)主键索引分段进行访问,示意图如下:
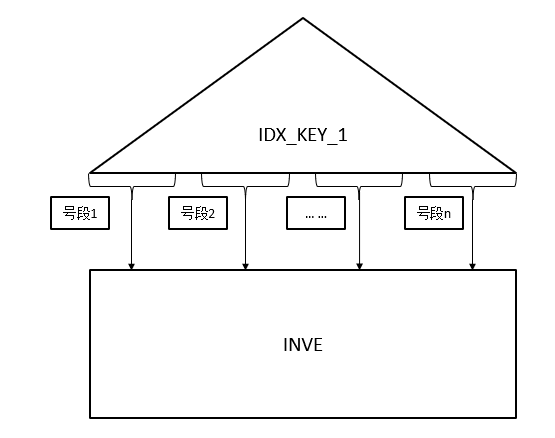
各位看官一定会问:都按主键索引访问了,性能还有提升空间? 我的回答:既然是对所有账号进行访问,何不直接访问账户表(INVE),为什么需要通过索引即便是主键索引进行回表操作呢?
于是,我先将账户表(INVE)按现在的账号分段规则进行范围分区,然后设计了按Local分区索引访问、按分区扫描访问、按分区扫描+并行处理等三个测试案例,这就是测试结果:
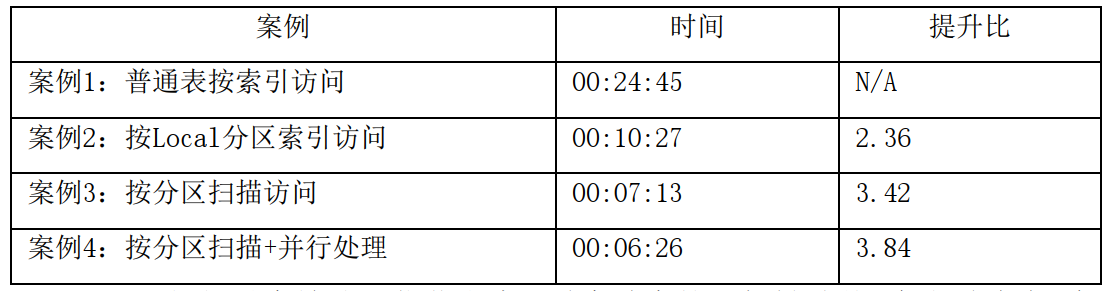
可见,仅仅是实施分区优化方案,季度结息就可轻松地从8个小时降为2个小时之内,银行工作人员和各厂商服务团队都可免去熬夜之苦。
以下是按索引访问示意图:
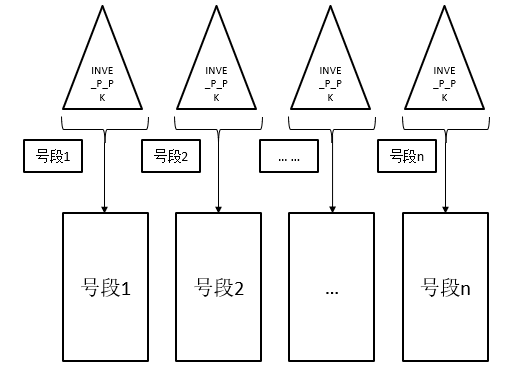
以下是按分区扫描访问示意图:
以下是按分区扫描+并行处理示意图:
总结
大千世界任何事情都应是先确定大方向,然后在每个大方向上精雕细琢,最终达到完美的结果。性能优化也是如此,如果明明是大海捞针式的OLTP语句,我们没有在索引等领域下功夫,而是盲目使用并行处理等技术,岂不是杀鸡用牛刀?反之,如果明明是大批量数据处理的OLAP语句,我们还停留在索引技术运用层级,岂不是小步快跑而失去了大踏步、大刀阔斧地模块化处理的豪迈?
大海捞针也罢,豪迈也罢,最终还是需要细腻的技术落地的。
本文为墨天轮社区特别邀稿,内容原创,仅代表作者观点,欢迎大家交流、讨论。文章现已收录至合辑《墨天轮专家邀稿合辑:论道数据库 解读新发展》,如需转载请联系作者或墨天轮官方。
