




案例背景
某省磐维分布式数据库。
环境描述
OS :bclinux-euler 21.10
数据库版本:PanweiDB_V2.0_S3.0.1_B01
兼容模式:A
数据库架构:分布式
描述
某省磐维分布式业务数据库变成只读, 业务进程在8点25分进行了重启操作。重启后发现从数据库取 JD.I_DATA_INDEX_SUB_SEQ 的seq 进行了回退,回退成之前的seq。导致业务进程无法按序列处理,部分工单积压 延迟处理大概10~20分钟。在9点前业务已经全部恢复。
历史问题记录:3月30日首次发现该问题现象时耗时超过2小时,业务侧进行业务重批补救问题。
分析日志发现应用重启后要重新从数据库中取seq_id,此时取到的JD.I_DATA_INDEX_SUB_SEQ开始 为124949050,而之前还是1253开头的序列,所以导致信管无法按序处理,导致工单延迟。
重启前:seq为1253XXX
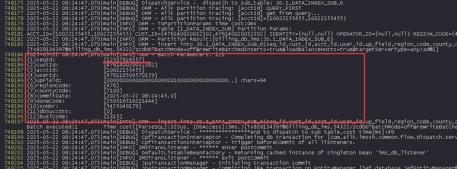
重启后:seq回退到了1249XXX
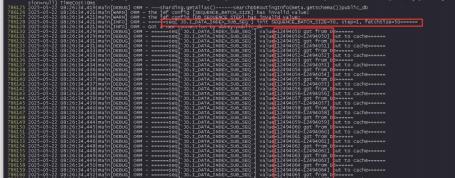
此后业务对dn进行重启测试准备复现问题,在这个dn节点恢复后,查看日志发现应用取到的Sequence从76996622跳到了77164610。
分析
序列Sequence是用来产生唯一整数的数据库对象。序列的值是按照一定规则自增的整数。因为自增所以不重复, 因此说Sequence具有唯一标识性。这也是Sequence常被用作主键的原因。
通过查看序列定义,发现此序列的cache设置为4000,现场业务通过连接池并发访问数据库。每个数据库会话首次获取序列号时,当前会话会缓存4000个序列号,比如1-4000,其他会话获取序列号会缓存4001-8000,8001-12000。 业务程序使用连接池访问数据库并获取序列值,每次尝试获取序列号时,从连接池获取数据库会话,每次取到的会话不同,则会在不同的区间里获取序列值,因此会出现序列值的前跳或者回退。
序列缓存的工作原理
当设置cache n时:
● 磐维数据库会一次性获取n个序列值并缓存在内存中
● 后续请求直接从内存获取,提高性能
● 当缓存用尽时,再获取下一批n个值
并发环境下可能的问题
● 序列不连续
不同会话可能获取不同批次的序列值,导致整体不连续
例如:会话A获取 1-100,会话B获取101-200,实际使用顺序可能是1,101,2,102...
● 事务回滚导致的空洞:
即使事务回滚,已获取的序列值也不会回滚
导致序列值出现"空洞"
● 服务器崩溃导致的序列值丢失:
已缓存但未使用的序列值在服务器崩溃后会丢失
下次启动后从丢失位置后继续分配
● 分布式环境下的更大间隔:
在流复制或分布式环境中,序列值可能会有更大的间隔
何时可以使用缓存序列
缓存序列适合以下场景:
● 不要求严格连续的序列值
● 高性能是关键需求
● 序列值仅用作唯一标识,不表示顺序
● 业务能容忍少量序列值丢失
何时应避免使用缓存序列
不应使用缓存序列的场景:
● 需要严格连续的订单号、发票号等
● 序列值作为业务逻辑的一部分(如按序号处理)
● 需要严格无空洞的ID分配
最佳实践建议
1. 评估业务需求:
如果只是需要唯一ID,缓存序列是安全的
如果需要严格连续,使用CACHE 1
2. 考虑替代方案:
UUID作为唯一标识且不涉及排序的
使用时间戳+随机数组合
应用层生成的ID
3. 调整缓存大小:
根据并发量和性能需求平衡
一般建议CACHE 20-100对大多数应用是合理的
在大多数业务场景中,使用适当大小的序列缓存(CACHE 20-100)是安全且能显著提高性能的,只要业务不依赖序列值 的严格连续性。
若业务获取序列值不是非常频繁,且有严格的排序需求时,建议关闭改序列的cache
关于在oracle库中的区别探讨:
业务反馈在Oracle库中没有出现过类似情况,这是由于Oracle里面SEQUENCE的缓存是实例级别的,他们是实例内共享的,但是磐维数据库里面SEQUENCE的缓存是会话级别的,所以在磐维数据库中高并发下取SEQUENCE就可能会出现跳变的可能。
结论
业务现场 sequences 跳变和回退是由于序列开启了 4000 的cache,且同时使用了连接池技术,不同的连接池有不同的缓存空间,这样业务故障后重连数据库连接池连到不同的会话连接,此会话连接不同于故障时的序列缓存,所以造 成了大幅度的回退或者跳变。
序列缓存有两种方式,可通过服务器缓存,也可以通过客户端进行缓存。所以现场问题建议业务将cache关闭,使用客户端缓存以解决序列性能问题。
ALTER SEQUENCE XXX CACHE 1;
