




作者:shunwahⓂ️
在运维管理领域,我拥有多年深厚的专业积累,兼具坚实的理论基础与广泛的实践经验。精通运维自动化流程,对于OceanBase、MySQL等多种数据库的部署与运维,具备从初始部署到后期维护的全链条管理能力。拥有OceanBase的OBCA和OBCP认证、OpenGauss社区认证结业证书,以及崖山DBCA、亚信AntDBCA、翰高 HDCA、GBase 8a | 8c | 8s、Galaxybase的GBCA、Neo4j的Graph Data Science Certification、NebulaGraph的NGCI & NGCP、东方通TongTech TCPE等多项权威认证。
在OceanBase & 墨天轮的技术征文大赛中,多次荣获一、二、三等奖。同时,在OpenGauss第五届、第六届、第七届技术征文大赛,TiDB社区专栏征文大赛,金仓数据库有奖征文活动,以及YashanDB「产品体验官」征文等活动中,我也屡获殊荣。此外,我还活跃于墨天轮、CSDN、ITPUB等技术平台,经常发布原创技术文章,并多次被首页推荐。

前言
在当今数字化时代,数据库作为企业数据存储与管理的核心组件,其性能、兼容性和稳定性至关重要。随着国产数据库技术的不断发展,越来越多的企业开始关注并尝试使用国产数据库替代传统国际品牌。金仓数据库作为国产数据库的佼佼者,一直致力于为用户提供高性能、高兼容性的数据库解决方案。此次,金仓数据库开启2025体验官招募活动,首期聚焦SQL Server深度兼容体验,为广大技术爱好者提供了一个深入了解金仓数据库的机会。
本文将详细介绍在Linux CentOS7环境下下载、部署金仓数据库KingbaseESV9R4C12(SQL Server兼容版)的过程,并进行库和表的创建操作,同时对部分SQL Server兼容特性进行实操测评,旨在为有相关需求的技术人员提供参考。
一、环境准备
在开始部署之前,需要确保Linux CentOS7系统满足以下基本要求:
- 操作系统:CentOS 7.x(64位)
- 内存:建议至少4GB
- 磁盘空间:根据实际数据量需求,建议至少预留20GB用于数据库安装和数据存储
- 网络连接:确保服务器能够正常访问互联网,以便下载安装包和相关依赖
1. 系统信息检查
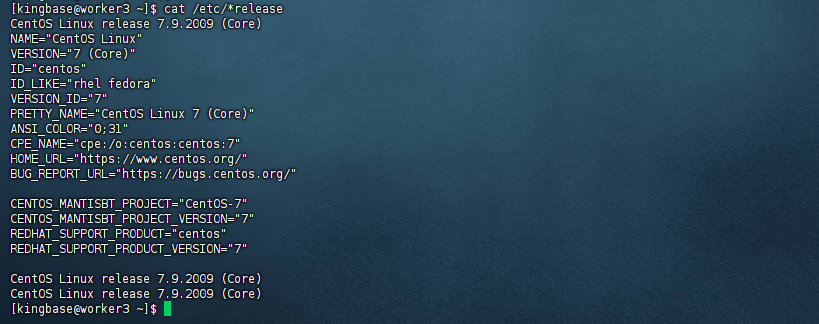
1.1 检查操作系统信息
您可以通过以下命令查看操作系统信息:
[kingbase@worker3 ~]$ cat /etc/*release
CentOS Linux release 7.9.2009 (Core)
NAME="CentOS Linux"
VERSION="7 (Core)"
ID="centos"
ID_LIKE="rhel fedora"
VERSION_ID="7"
PRETTY_NAME="CentOS Linux 7 (Core)"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:centos:centos:7"
HOME_URL="https://www.centos.org/"
BUG_REPORT_URL="https://bugs.centos.org/"
CENTOS_MANTISBT_PROJECT="CentOS-7"
CENTOS_MANTISBT_PROJECT_VERSION="7"
REDHAT_SUPPORT_PRODUCT="centos"
REDHAT_SUPPORT_PRODUCT_VERSION="7"
CentOS Linux release 7.9.2009 (Core)
CentOS Linux release 7.9.2009 (Core)
[kingbase@worker3 ~]$
注意:
为避免安装失败,或安装结束后文件发生异常,请在安装前关闭操作系统的应用保护,或于安装时在操作系统界面手动点击允许程序执行。
1.2 检查系统内存与存储空间
您可以通过以下命令查看内存信息(以MB单位显示):
[kingbase@worker3 ~]$ free -hm
total used free shared buff/cache available
Mem: 27G 1.9G 5.4G 728M 20G 23G
Swap: 8.0G 0B 8.0G
[kingbase@worker3 ~]$

1.3 检查存储空间
您可以通过以下命令查看磁盘存储信息(以GB单位显示):
[kingbase@worker3 ~]$ df -lh
Filesystem Size Used Avail Use% Mounted on
devtmpfs 14G 0 14G 0% /dev
tmpfs 14G 8.0K 14G 1% /dev/shm
tmpfs 14G 677M 14G 5% /run
tmpfs 14G 0 14G 0% /sys/fs/cgroup
/dev/mapper/centos-root 91G 60G 27G 70% /
/dev/sda2 190M 119M 58M 68% /boot
/dev/sdb1 200G 17G 184G 9% /data
tmpfs 2.8G 28K 2.8G 1% /run/user/0
/dev/loop0 2.5G 2.5G 0 100% /mnt
[kingbase@worker3 ~]$
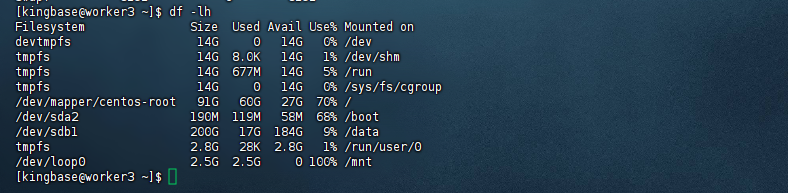
注意: /tmp目录需要至少10G空间。如果安装过程中出现存储空间不足的情况,请先释放足够的磁盘空间,再执行安装程序。如果硬件配置不满足要求,需要更换满足要求的硬件设备再进行安装。
2. 下载安装包
2.1 下载金仓数据库安装包
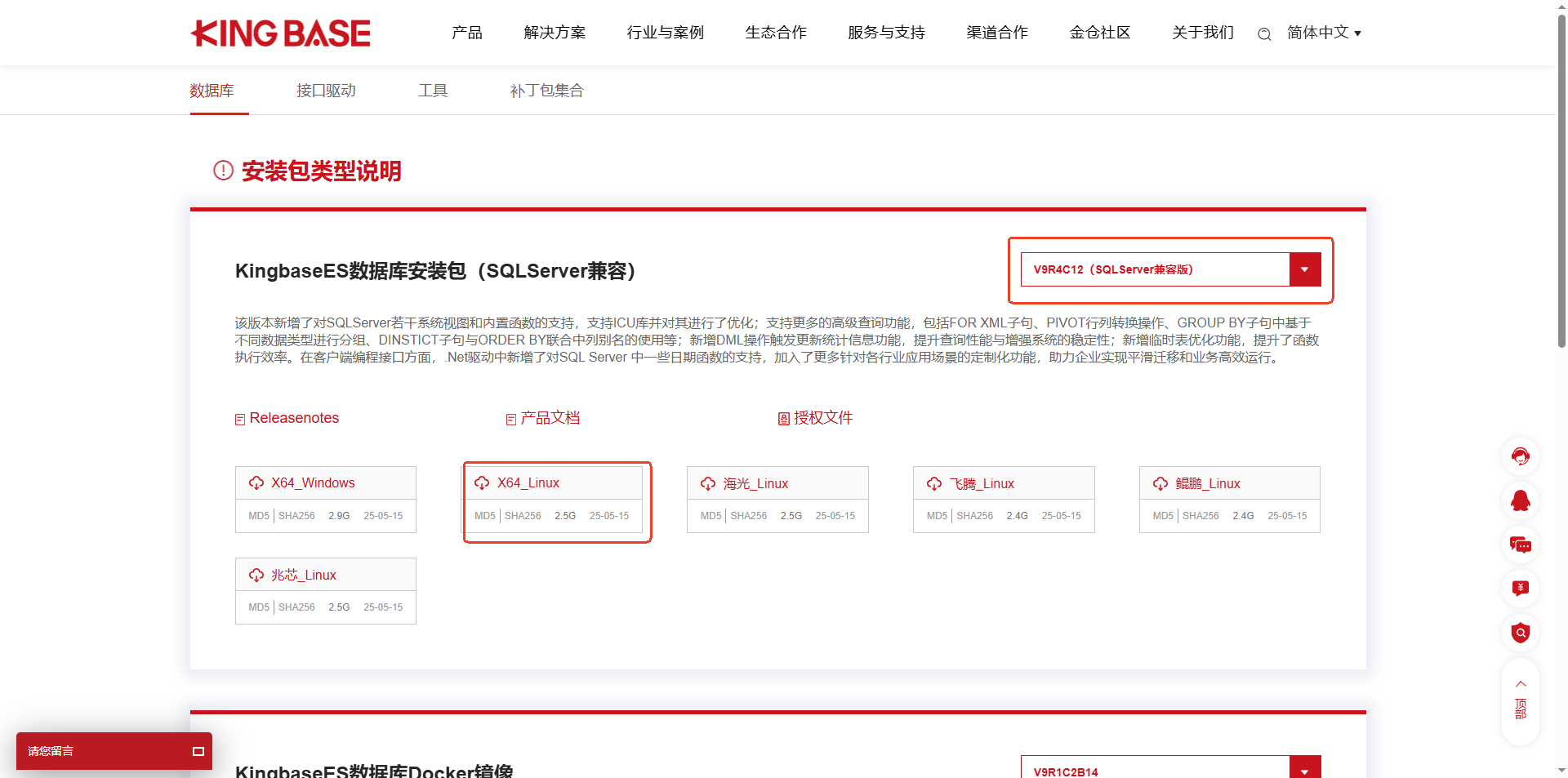
访问金仓官网(https://www.kingbase.com.cn/download.html),在产品下载页面中找到KingbaseESV9R4C12(SQL Server兼容版)的安装包。
https://download.kingbase.com.cn/xzzx/index.htm
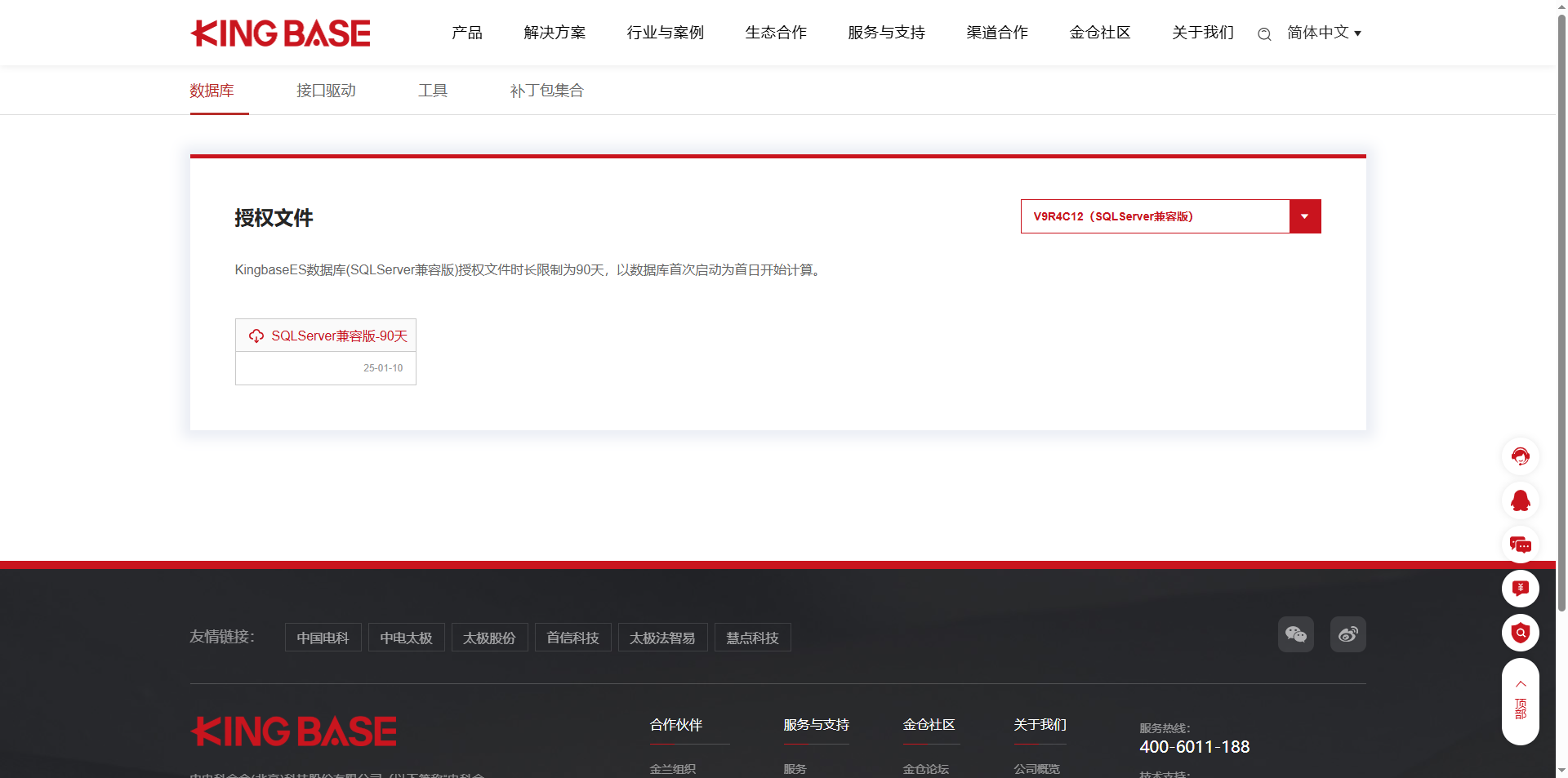
2.2 下载授权
https://www.kingbase.com.cn/download.html#authorization?authorcurrV=V9R4C12%EF%BC%88SQLServer%E5%85%BC%E5%AE%B9%E7%89%88%EF%BC%89
2.3 传输安装包
根据服务器的操作系统架构(64位),选择对应的安装包进行下载。下载完成后,将安装包传输到CentOS7服务器的指定目录,例如/opt/kingbase_install。
[root@worker3 ~]# cd /opt/kingbase_install/
[root@worker3 kingbase_install]# ls
KingbaseES_V009R004C012B0006_Lin64_install.iso license_SQLServer试用授权.dat
[root@worker3 kingbase_install]#

3. 创建安装目录:
[root@worker3 ~]# mkdir -p /data/kingbase_sql/ES/V9/R4/C12
[root@worker3 ~]# chown -R kingbase:kingbase /data/kingbase_sql/ES/V9/R4/C12
[root@worker3 ~]#

4. 安装依赖
在安装金仓数据库之前,需要先安装一些必要的依赖包。使用以下命令更新系统软件包索引并安装依赖:
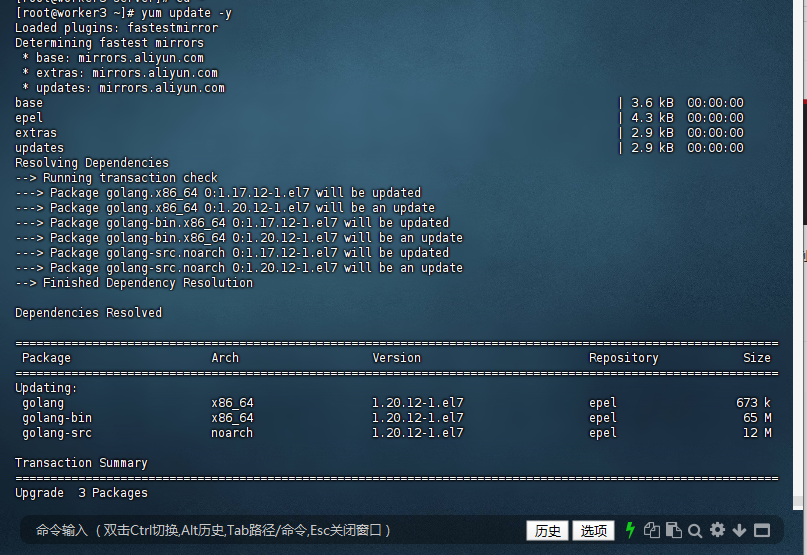
4.1 系统更新
升级所有已安装的软件包到最新版本
[root@worker3 ~]# yum update -y
Loaded plugins: fastestmirror
Determining fastest mirrors
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
base | 3.6 kB 00:00:00
epel | 4.3 kB 00:00:00
extras | 2.9 kB 00:00:00
updates | 2.9 kB 00:00:00
Resolving Dependencies
--> Running transaction check
---> Package golang.x86_64 0:1.17.12-1.el7 will be updated
---> Package golang.x86_64 0:1.20.12-1.el7 will be an update
---> Package golang-bin.x86_64 0:1.17.12-1.el7 will be updated
---> Package golang-bin.x86_64 0:1.20.12-1.el7 will be an update
---> Package golang-src.noarch 0:1.17.12-1.el7 will be updated
---> Package golang-src.noarch 0:1.20.12-1.el7 will be an update
--> Finished Dependency Resolution
Dependencies Resolved
=============================================================================================================
Package Arch Version Repository Size
=============================================================================================================
Updating:
golang x86_64 1.20.12-1.el7 epel 673 k
golang-bin x86_64 1.20.12-1.el7 epel 65 M
golang-src noarch 1.20.12-1.el7 epel 12 M
Transaction Summary
=============================================================================================================
Upgrade 3 Packages
Total download size: 78 M
Downloading packages:
(1/3): golang-1.20.12-1.el7.x86_64.rpm | 673 kB 00:00:00
(2/3): golang-src-1.20.12-1.el7.noarch.rpm | 12 MB 00:00:01
(3/3): golang-bin-1.20.12-1.el7.x86_64.rpm | 65 MB 00:00:07
-------------------------------------------------------------------------------------------------------------
Total 9.8 MB/s | 78 MB 00:00:07
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Updating : golang-src-1.20.12-1.el7.noarch 1/6
Updating : golang-1.20.12-1.el7.x86_64 2/6
Updating : golang-bin-1.20.12-1.el7.x86_64 3/6
Cleanup : golang-1.17.12-1.el7.x86_64 4/6
Cleanup : golang-bin-1.17.12-1.el7.x86_64 5/6
Cleanup : golang-src-1.17.12-1.el7.noarch 6/6
Verifying : golang-bin-1.20.12-1.el7.x86_64 1/6
Verifying : golang-1.20.12-1.el7.x86_64 2/6
Verifying : golang-src-1.20.12-1.el7.noarch 3/6
Verifying : golang-src-1.17.12-1.el7.noarch 4/6
Verifying : golang-1.17.12-1.el7.x86_64 5/6
Verifying : golang-bin-1.17.12-1.el7.x86_64 6/6
Updated:
golang.x86_64 0:1.20.12-1.el7 golang-bin.x86_64 0:1.20.12-1.el7 golang-src.noarch 0:1.20.12-1.el7
Complete!
[root@worker3 ~]#
4.2 安装开发工具链
[root@worker3 ~]# yum install -y gcc make libaio libaio-devel bzip2 unzip
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
Package gcc-4.8.5-44.el7.x86_64 already installed and latest version
Package 1:make-3.82-24.el7.x86_64 already installed and latest version
Package libaio-0.3.109-13.el7.x86_64 already installed and latest version
Package libaio-devel-0.3.109-13.el7.x86_64 already installed and latest version
Package bzip2-1.0.6-13.el7.x86_64 already installed and latest version
Package unzip-6.0-24.el7_9.x86_64 already installed and latest version
Nothing to do
[root@worker3 ~]#
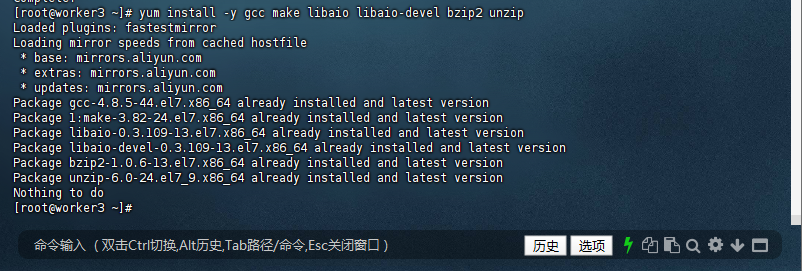
- 安装包说明:
包名 用途说明 gccC/C++编译器(编译代码必需) make构建自动化工具(执行Makefile) libaio异步I/O库(数据库等高性能应用常用) libaio-devel开发头文件(编译需要libaio的程序时必需) bzip2BZIP2压缩工具(解压.bz2文件) unzipZIP解压工具(处理.zip文件)
通过以上步骤,您可以为大多数C/C++项目编译、数据库部署等场景准备好基础环境。根据具体需求选择补充安装对应组件。
5. 挂载 ISO 文件
5.1 创建挂载点目录
[root@worker3 ~]# mkdir /mnt/kingbase_iso
[root@worker3 ~]#

5.2 挂载 ISO 文件(需要 root 权限)
[root@worker3 ~]# cd /opt/kingbase_install/
[root@worker3 kingbase_install]# ls
KingbaseES_V009R004C012B0006_Lin64_install.iso license_SQLServer试用授权.dat
[root@worker3 kingbase_install]# mount -o loop KingbaseES_V009R004C012B0006_Lin64_install.iso /mnt/kingbase_iso
mount: /dev/loop1 is write-protected, mounting read-only
[root@worker3 kingbase_install]#

5.3 进入挂载点查看内容
[root@worker3 kingbase_install]# cd /mnt/kingbase_iso
[root@worker3 kingbase_iso]# ls
setup setup.sh
[root@worker3 kingbase_iso]#

二、安装金仓数据库
1. 解压安装包:
切换普通用户进入安装包所在目录,使用tar命令解压安装包。假设安装包名为kingbaseesv9r4c12_linux_x64.tar.gz,执行以下命令:
[root@worker3 ~]# su kingbase
[kingbase@worker3 root]$ cd /mnt/kingbase_iso/
[kingbase@worker3 kingbase_iso]$ ls
setup setup.sh
[kingbase@worker3 kingbase_iso]$

2. 运行安装脚本:
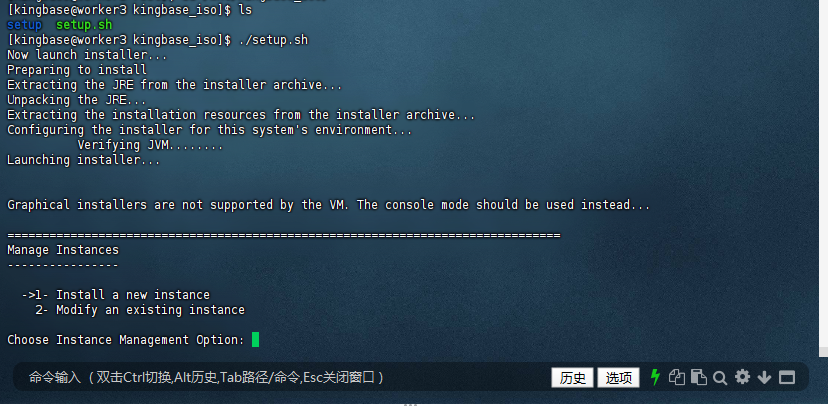
解压完成后,进入解压后的目录,找到安装脚本并运行。通常安装脚本名为setup.sh,执行以下命令:
[kingbase@worker3 kingbase_iso]$ ./setup.sh
Now launch installer...
Preparing to install
Extracting the JRE from the installer archive...
Unpacking the JRE...
Extracting the installation resources from the installer archive...
Configuring the installer for this system's environment...
Verifying JVM........
Launching installer...
Graphical installers are not supported by the VM. The console mode should be used instead...
===============================================================================
Manage Instances
----------------
->1- Install a new instance
2- Modify an existing instance
Choose Instance Management Option:
3. 按照安装向导进行操作:
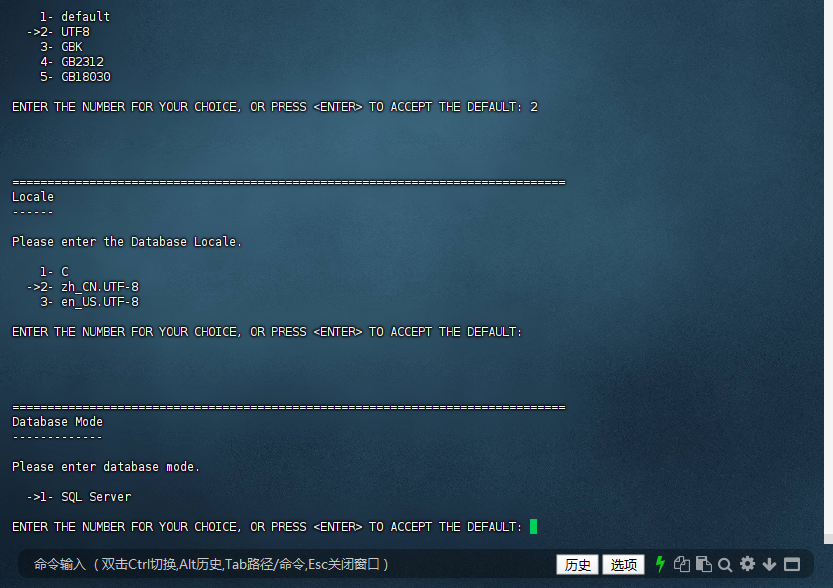
运行安装脚本后,会弹出安装向导界面。根据向导提示,选择安装类型(建议选择典型安装)、安装路径(可根据实际需求修改/data/kingbase_sql/ES/V9/R4/C12)、设置数据库管理员密码等信息。在安装过程中,需要仔细阅读每个步骤的提示信息,确保安装配置正确。
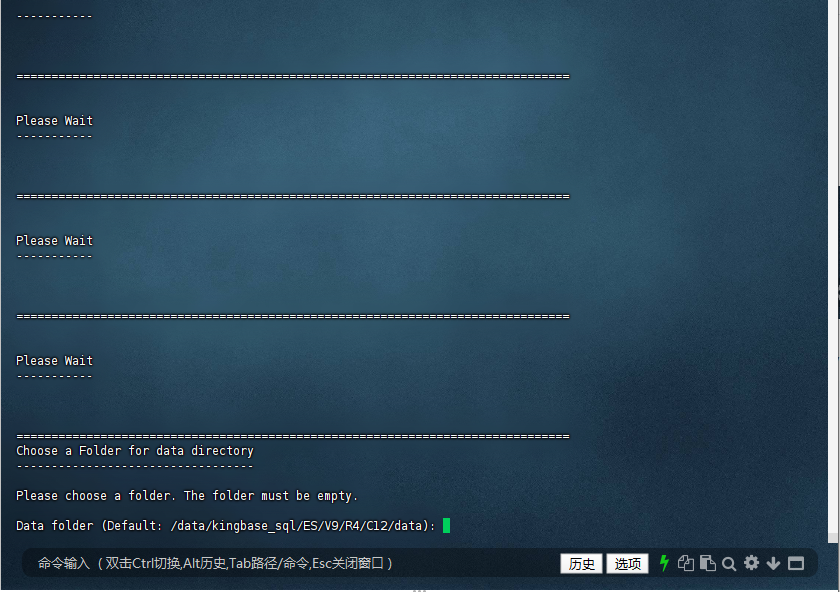
兼容模式:sqlserver
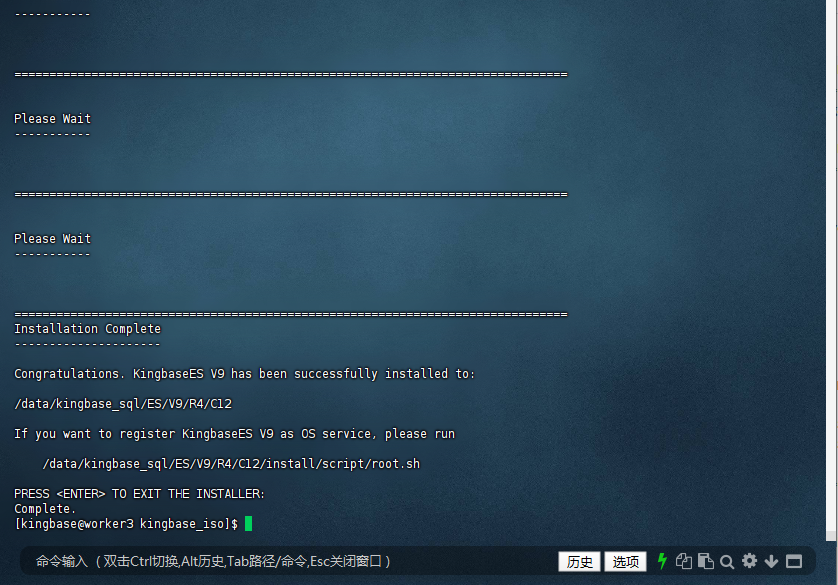
4. 完成安装:
等待安装程序完成所有操作,安装完成后会提示安装成功。
Installation Complete
---------------------
Congratulations. KingbaseES V9 has been successfully installed to:
/data/kingbase_sql/ES/V9/R4/C12
If you want to register KingbaseES V9 as OS service, please run
/data/kingbase_sql/ES/V9/R4/C12/install/script/root.sh
PRESS <ENTER> TO EXIT THE INSTALLER:
Complete.
[kingbase@worker3 kingbase_iso]$
5. 服务管理
5.1 以root用户执行注册服务脚本:
[root@worker3 ~]# /data/kingbase_sql/ES/V9/R4/C12/install/script/root.sh
Starting KingbaseES V9:
waiting for server to start.... done
server started
KingbaseES V9 started successfully
[root@worker3 ~]#

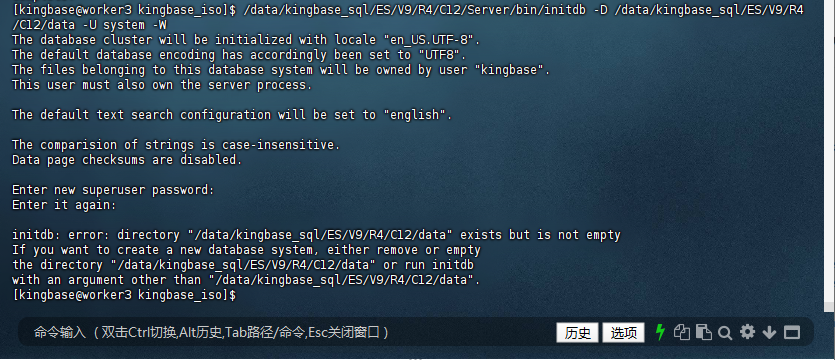
5.2 初始化数据库
安装完成后,需要对数据库进行初始化操作。使用以下命令初始化数据库:
[kingbase@worker3 kingbase_iso]$ /data/kingbase_sql/ES/V9/R4/C12/Server/bin/initdb -D /data/kingbase_sql/ES/V9/R4/C12/data -U system -W
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The files belonging to this database system will be owned by user "kingbase".
This user must also own the server process.
The default text search configuration will be set to "english".
The comparision of strings is case-insensitive.
Data page checksums are disabled.
Enter new superuser password:
Enter it again:
initdb: error: directory "/data/kingbase_sql/ES/V9/R4/C12/data" exists but is not empty
If you want to create a new database system, either remove or empty
the directory "/data/kingbase_sql/ES/V9/R4/C12/data" or run initdb
with an argument other than "/data/kingbase_sql/ES/V9/R4/C12/data".
[kingbase@worker3 kingbase_iso]$
5.3 检查数据库目录
在执行上述命令时,会提示输入数据库管理员密码,输入之前设置的密码即可。初始化完成后,会在指定路径(/data/kingbase_sql/ES/V9/R4/C12/data)下生成数据库的相关文件和目录。
[kingbase@worker3 kingbase_iso]$ cd /data/kingbase_sql/ES/V9/R4/C12/data
[kingbase@worker3 data]$ ls
base kingbase.conf sys_commit_ts sys_log sys_serial sys_twophase
current_logfiles kingbase.opts sys_csnlog sys_logical sys_snapshots SYS_VERSION
global kingbase.pid sys_dynshmem sys_multixact sys_stat sys_wal
initdb.conf sys_aud sys_hba.conf sys_notify sys_stat_tmp sys_xact
kingbase.auto.conf sys_bulkload sys_ident.conf sys_replslot sys_tblspc
[kingbase@worker3 data]$
5.4 配置环境变量
将KingbaseES的bin目录添加到系统的PATH环境变量中,以便在命令行中方便地使用KingbaseES的命令。
编辑~/.bashrc或/etc/profile文件,在文件末尾添加以下内容:
export PATH=/data/kingbase_sql/ES/V9/R4/C12/KESRealPro/V009R004C012/Server/bin:$PATH
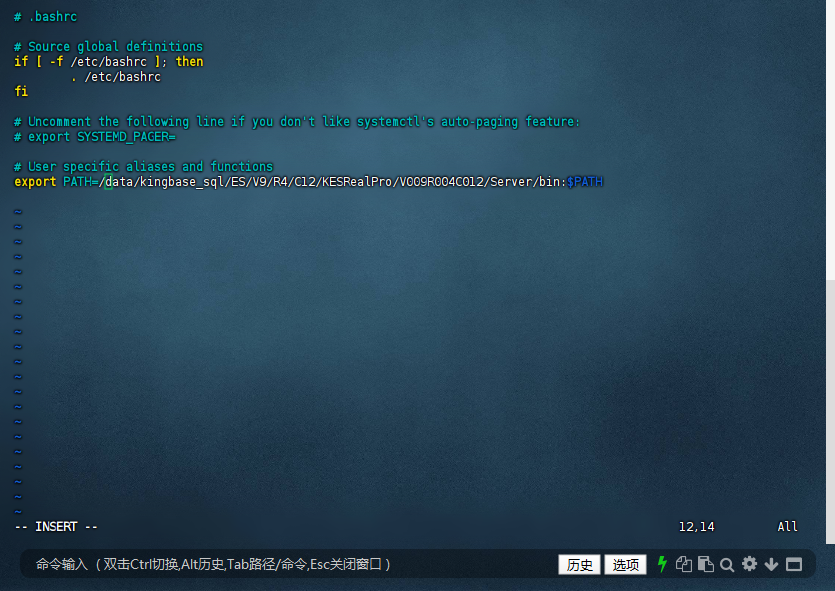
然后执行source ~/.bashrc或source /etc/profile使更改生效。
[kingbase@worker3 bin]$ pwd
/data/kingbase_sql/ES/V9/R4/C12/KESRealPro/V009R004C012/Server/bin
[kingbase@worker3 bin]$ vim ~/.bashrc
[kingbase@worker3 bin]$ source ~/.bashrc
[kingbase@worker3 bin]$

6. 启动数据库服务
使用以下命令启动金仓数据库服务:
[kingbase@worker3 data]$ ls
base kingbase.conf sys_commit_ts sys_log sys_serial sys_twophase
current_logfiles kingbase.opts sys_csnlog sys_logical sys_snapshots SYS_VERSION
global logfile sys_dynshmem sys_multixact sys_stat sys_wal
initdb.conf sys_aud sys_hba.conf sys_notify sys_stat_tmp sys_xact
kingbase.auto.conf sys_bulkload sys_ident.conf sys_replslot sys_tblspc
[kingbase@worker3 data]$ sys_ctl -D /data/kingbase_sql/ES/V9/R4/C12/data -l logfile start
waiting for server to start.... done
server started
[kingbase@worker3 data]$
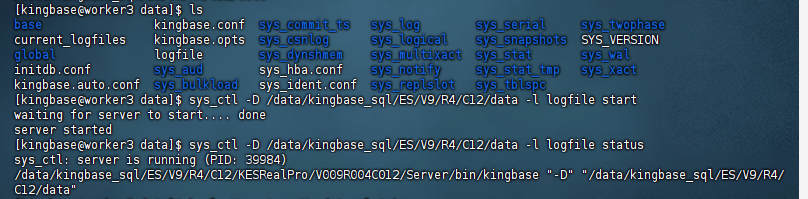
7. 检查数据库服务状态
启动成功后,可以使用以下命令检查数据库服务状态:
[kingbase@worker3 data]$ sys_ctl -D /data/kingbase_sql/ES/V9/R4/C12/data -l logfile status
sys_ctl: server is running (PID: 39984)
/data/kingbase_sql/ES/V9/R4/C12/KESRealPro/V009R004C012/Server/bin/kingbase "-D" "/data/kingbase_sql/ES/V9/R4/C12/data"
[kingbase@worker3 data]$

三、管理数据库
1. 创建库和表
1.1 连接到数据库
使用数据库管理员账号连接到金仓数据库。可以使用ksql命令行工具,执行以下命令:
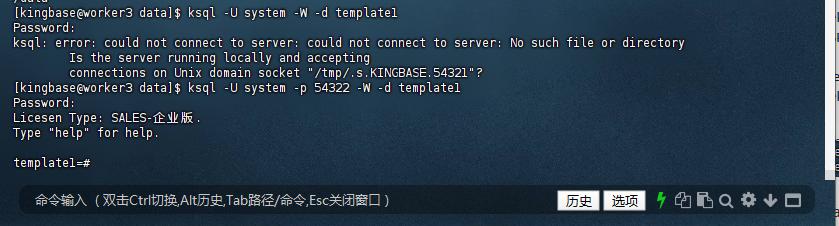
[kingbase@worker3 data]$ ksql -U system -W -d template1
Password:
ksql: error: could not connect to server: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.KINGBASE.54321"?
[kingbase@worker3 data]$ ksql -U system -p 54322 -W -d template1
Password:
Licesen Type: SALES-企业版.
Type "help" for help.
template1=#
输入密码后,即可连接到数据库。
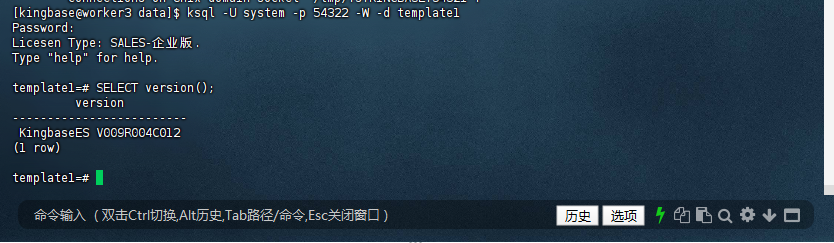
1.2 查看版本
[kingbase@worker3 data]$ ksql -U system -p 54322 -W -d template1
Password:
Licesen Type: SALES-企业版.
Type "help" for help.
template1=# SELECT version();
version
-------------------------
KingbaseES V009R004C012
(1 row)
template1=#
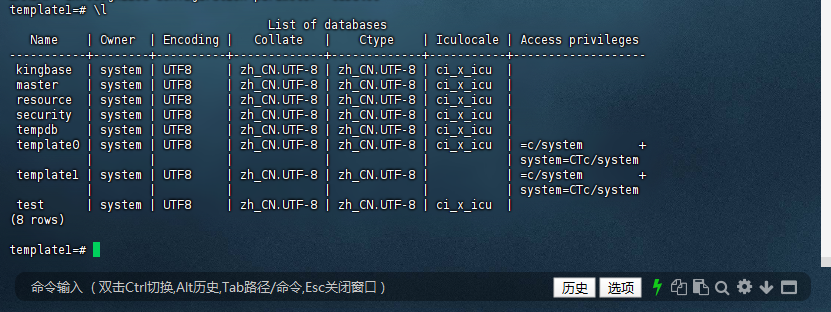
1.3 查看系统默认数据库
template1=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Iculocale | Access privileges
-----------+--------+----------+-------------+-------------+-----------+-------------------
kingbase | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | ci_x_icu |
master | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | ci_x_icu |
resource | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | ci_x_icu |
security | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | ci_x_icu |
tempdb | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | ci_x_icu |
template0 | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | ci_x_icu | =c/system +
| | | | | | system=CTc/system
template1 | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | | =c/system +
| | | | | | system=CTc/system
test | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | ci_x_icu |
(8 rows)
template1=#
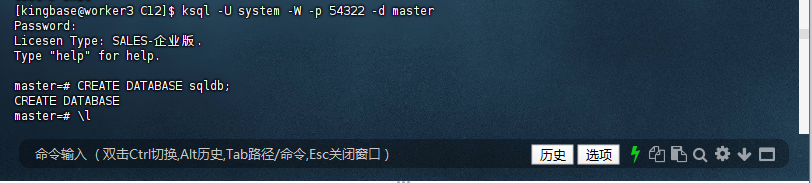
2. 创建库
在连接成功后,执行以下SQL语句在master库中创建一个新的数据库,例如sqldb:
KingbaseES SQL Server 兼容版沿用了 SQL Server 的行为:所有数据库管理操作(如 CREATE DATABASE)必须在 master 系统库中执行。
[kingbase@worker3 C12]$ ksql -U system -W -p 54322 -d master
Password:
Licesen Type: SALES-企业版.
Type "help" for help.
master=# CREATE DATABASE sqldb;
CREATE DATABASE
master=#
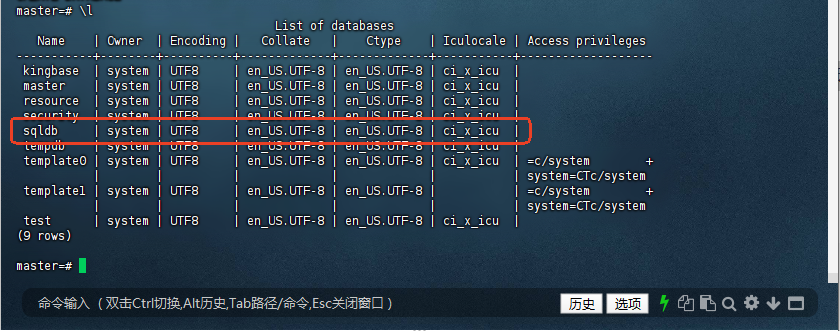
2.1.1 查看新创建的数据库
创建完成后,可以使用\l命令查看所有数据库,确认sqldb已创建成功。
master=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Iculocale | Access privileges
-----------+--------+----------+-------------+-------------+-----------+-------------------
kingbase | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu |
master | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu |
resource | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu |
security | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu |
sqldb | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu |
tempdb | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu |
template0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu | =c/system +
| | | | | | system=CTc/system
template1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | =c/system +
| | | | | | system=CTc/system
test | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | ci_x_icu |
(9 rows)
master=#
3. 连接到新创建的库
执行以下命令连接到新创建的sqldb数据库:
master=# \c sqldb
Password:
You are now connected to database "sqldb" as userName "system".
sqldb=#

四、SQL Server兼容类型与对象测评
1. 创建 row_version ROWVERSION 类型表
在 SQL Server 兼容模式下,KingbaseES 将 TIMESTAMP 数据类型解释为 ROWVERSION 类型(这与标准 SQL 不同)。
ROWVERSION 类型的列:
hire_date TIMESTAMP → 被解释为 ROWVERSION
hire_date 列的数据类型为真正的日期时间类型:
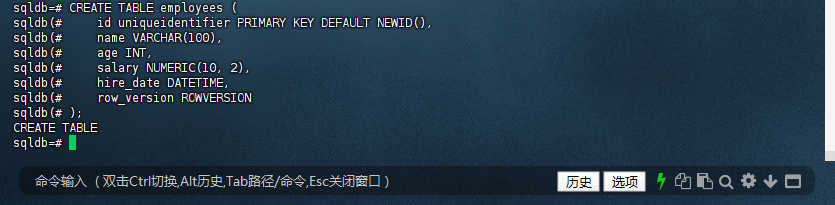
sqldb=# CREATE TABLE employees (
sqldb(# id uniqueidentifier PRIMARY KEY DEFAULT NEWID(),
sqldb(# name VARCHAR(100),
sqldb(# age INT,
sqldb(# salary NUMERIC(10, 2),
sqldb(# hire_date DATETIME,
sqldb(# row_version ROWVERSION
sqldb(# );
CREATE TABLE
sqldb=#
关键说明:
TIMESTAMP 的兼容性问题:
在 SQL Server 中,TIMESTAMP 不是日期时间类型,而是二进制版本戳类型(等同于 ROWVERSION)
要存储日期时间,应使用 DATETIME 或 DATETIME2 类型
ROWVERSION 列的特性:每个表只能有一个 ROWVERSION 列
该列会自动更新:每次行修改时,值会自动递增
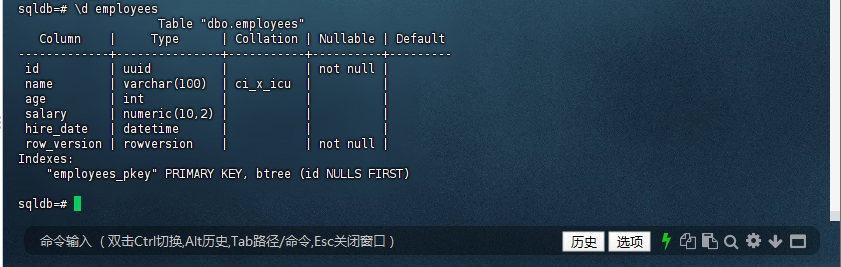
1.1 验证表结构:
sqldb=# \d employees
Table "dbo.employees"
Column | Type | Collation | Nullable | Default
-------------+---------------+-----------+----------+---------
id | uuid | | not null |
name | varchar(100) | ci_x_icu | |
age | int | | |
salary | numeric(10,2) | | |
hire_date | datetime | | |
row_version | rowversion | | not null |
Indexes:
"employees_pkey" PRIMARY KEY, btree (id NULLS FIRST)
sqldb=#
1.2 插入数据
sqldb=# INSERT INTO employees (name, age, salary, hire_date)
sqldb-# VALUES ('王五', 35, 6000.00, CURRENT_TIMESTAMP);
INSERT 0 1
sqldb=#

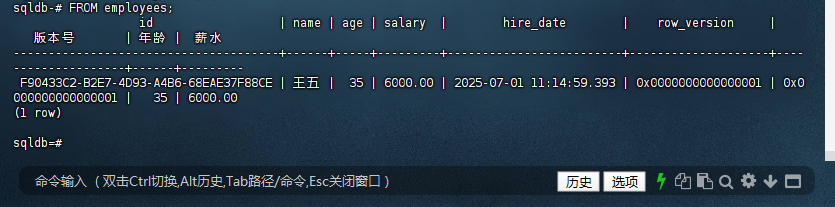
1.3 查询数据
sqldb-# FROM employees;
id | name | age | salary | hire_date | row_version |
版本号 | 年龄 | 薪水
--------------------------------------+------+-----+---------+-------------------------+--------------------+----
----------------+------+---------
F90433C2-B2E7-4D93-A4B6-68EAE37F88CE | 王五 | 35 | 6000.00 | 2025-07-01 11:14:59.393 | 0x0000000000000001 | 0x0
000000000000001 | 35 | 6000.00
(1 row)
sqldb=#
1.4 更新数据(触发 row_version 变化)
sqldb=# UPDATE employees SET salary = salary + 500 WHERE name = '王五';
UPDATE 1
sqldb=#

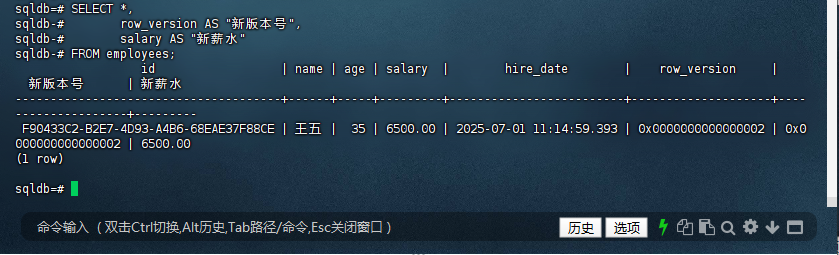
1.5 再次查询观察版本变化
sqldb=# SELECT *,
sqldb-# row_version AS "新版本号",
sqldb-# salary AS "新薪水"
sqldb-# FROM employees;
id | name | age | salary | hire_date | row_version |
新版本号 | 新薪水
--------------------------------------+------+-----+---------+-------------------------+--------------------+----
----------------+---------
F90433C2-B2E7-4D93-A4B6-68EAE37F88CE | 王五 | 35 | 6500.00 | 2025-07-01 11:14:59.393 | 0x0000000000000002 | 0x0
000000000000002 | 6500.00
(1 row)
sqldb=#
2. UNIQUEIDENTIFIER 类型
2.1 修改表默认值函数
使用更高效的 UUID 生成函数
原始 SQL 使用 gen_random_uuid(),但 KingbaseES 兼容模式下推荐使用 SQL Server 风格的 NEWID() 函数:
sqldb=# ALTER TABLE employees
sqldb-# ALTER COLUMN id SET DEFAULT NEWID();
ALTER TABLE
sqldb=#

2.2 插入数据时使用 NEWID()
sqldb=# INSERT INTO employees (id, name, age, salary, hire_date)
sqldb-# VALUES (NEWID(), '张三', 35, 6000.00, CURRENT_TIMESTAMP);
INSERT 0 1
sqldb=#

优势:
NEWID()是 SQL Server 标准函数,兼容性更好- 避免
pgcrypto扩展的依赖(gen_random_uuid需要此扩展)
2.3 添加索引优化查询性能
UUID 作为主键时,随机性可能导致索引碎片 – 重建主键索引为有序结构
sqldb=# CREATE UNIQUE INDEX idx_employees_id_ordered
sqldb-# ON employees (id)
sqldb-# WITH (FILLFACTOR = 90);
CREATE INDEX
sqldb=#

场景建议:
- 高频写入:BRIN 索引减少维护开销
- 范围查询:有序索引提升查询速度
2.4 查询优化
– 避免全表扫描(原始查询未使用索引)
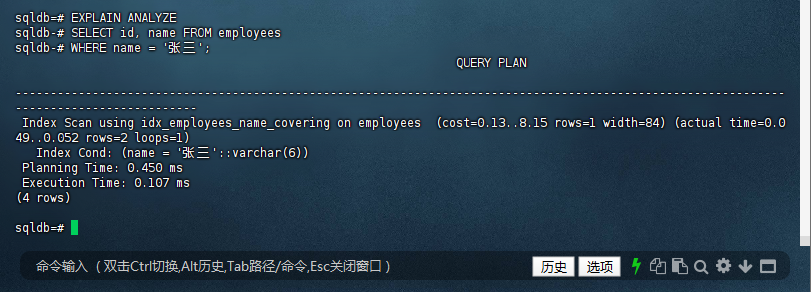
sqldb=# EXPLAIN ANALYZE
sqldb-# SELECT id, name FROM employees
sqldb-# WHERE name = '张三';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
--------------------------
Index Scan using idx_employees_name_covering on employees (cost=0.13..8.15 rows=1 width=84) (actual time=0.0
49..0.052 rows=2 loops=1)
Index Cond: (name = '张三'::varchar(6))
Planning Time: 0.450 ms
Execution Time: 0.107 ms
(4 rows)
sqldb=#
2.5 添加姓名索引
CREATE INDEX idx_employees_name ON employees (name);
sqldb=# CREATE INDEX idx_employees_name ON employees (name);
CREATE INDEX
sqldb=#

2.6 插入数据(自动生成 UUID)
sqldb=# INSERT INTO employees (name, age, salary, hire_date)
sqldb-# VALUES ('张三', 35, 6000.00, CURRENT_TIMESTAMP);
INSERT 0 1
sqldb=#

2.7 高效查询
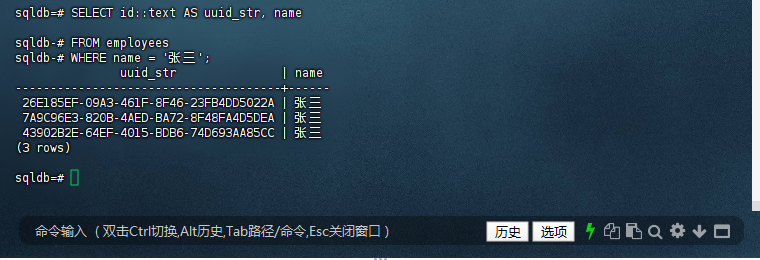
sqldb=# SELECT id::text AS uuid_str, name
sqldb-# FROM employees
sqldb-# WHERE name = '张三';
uuid_str | name
--------------------------------------+------
26E185EF-09A3-461F-8F46-23FB4DD5022A | 张三
7A9C96E3-820B-4AED-BA72-8F48FA4D5DEA | 张三
43902B2E-64EF-4015-BDB6-74D693AA85CC | 张三
(3 rows)
sqldb=#
2.8 定期维护统计信息
sqldb=# ANALYZE VERBOSE employees;
INFO: analyzing "dbo.employees"
INFO: "employees": scanned 1 of 1 pages, containing 5 live krows and 8 dead krows; 5 krows in sample, 5 estimated total krows
ANALYZE
sqldb=#

2.9 监控实际性能
sqldb=# SELECT * FROM pg_stat_all_indexes
sqldb-# WHERE relname = 'employees';
relid | indexrelid | schemaname | relname | indexrelname | idx_scan | idx_tup_read | idx_tup_fetch
-------+------------+------------+-----------+-----------------------------+----------+--------------+---------------
16418 | 16426 | dbo | employees | employees_pkey | 1 | 7 | 3
16418 | 17140 | dbo | employees | idx_employees_name_covering | 2 | 3 | 3
16418 | 17143 | dbo | employees | idx_employees_id_ordered | 0 | 0 | 0
16418 | 17156 | dbo | employees | idx_employees_name | 1 | 3 | 3
(4 rows)
sqldb=#
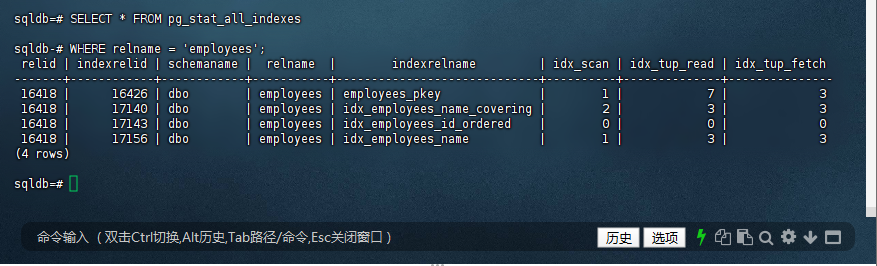
结论:当前执行计划是正确的优化选择。当数据量增加时,索引会自动生效。对于小表(<100行),全表扫描是最优解。通过标准化 UUID 函数、索引优化和存储压缩,可显著提升 KingbaseES 中 UUID 类型的存储效率和查询性能。
3. SQL_VARIANT 类型
(金仓数据库不完全支持,此处仅做概念性测试)
3.1 创建 SQL_VARIANT 表
(金仓数据库没有直接的SQL_VARIANT类型,可通过其他方式模拟)
– 此处仅为示例,实际实现可能需要根据业务需求进行调整
sqldb=# CREATE TABLE variant_test (
sqldb(# id SERIAL PRIMARY KEY,
sqldb(# value_text TEXT,
sqldb(# value_int INT,
sqldb(# value_float FLOAT
sqldb(# );
CREATE TABLE
sqldb=#

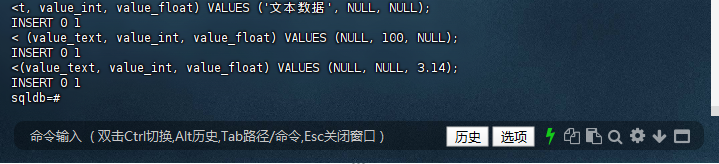
3.2 插入不同类型的数据
<t, value_int, value_float) VALUES ('文本数据', NULL, NULL);
INSERT 0 1
< (value_text, value_int, value_float) VALUES (NULL, 100, NULL);
INSERT 0 1
<(value_text, value_int, value_float) VALUES (NULL, NULL, 3.14);
INSERT 0 1
sqldb=#
3.3 查询数据
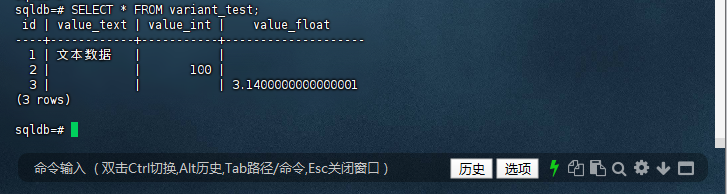
sqldb=# SELECT * FROM variant_test;
id | value_text | value_int | value_float
----+------------+-----------+--------------------
1 | 文本数据 | |
2 | | 100 |
3 | | | 3.1400000000000001
(3 rows)
sqldb=#
4. SYSNAME
(金仓数据库中可使用VARCHAR类型模拟)
4.1 创建一个使用类似SYSNAME类型的表
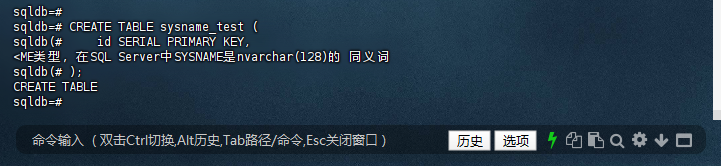
sqldb=# CREATE TABLE sysname_test (
sqldb(# id SERIAL PRIMARY KEY,
<ME类型,在SQL Server中SYSNAME是nvarchar(128)的 同义词
sqldb(# );
CREATE TABLE
sqldb=#
4.2 插入数据
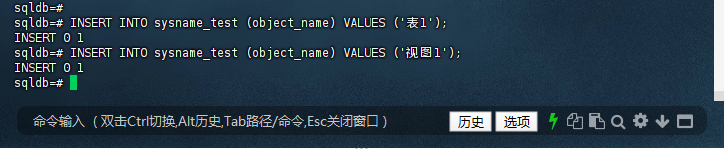
sqldb=# INSERT INTO sysname_test (object_name) VALUES ('表1');
INSERT 0 1
sqldb=# INSERT INTO sysname_test (object_name) VALUES ('视图1');
INSERT 0 1
sqldb=#
4.3 查询数据
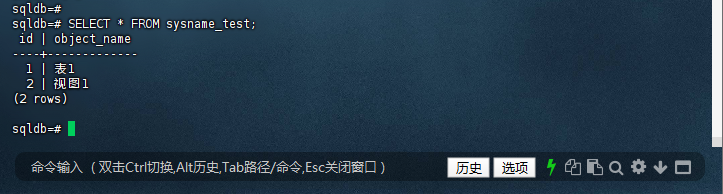
sqldb=# SELECT * FROM sysname_test;
id | object_name
----+-------------
1 | 表1
2 | 视图1
(2 rows)
sqldb=#
5. NOWAIT/SKIPLOCKED
5.1 开启两个会话进行测试
5.2 会话1:开启事务并锁定一行数据
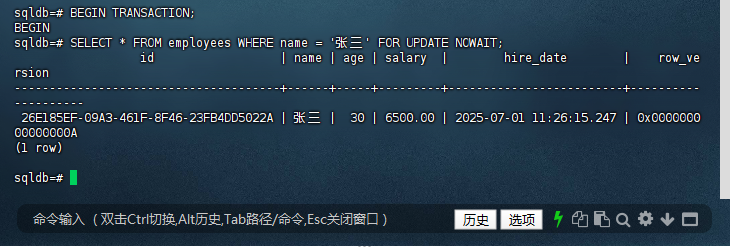
sqldb=# BEGIN TRANSACTION;
BEGIN
sqldb=# SELECT * FROM employees WHERE name = '张三' FOR UPDATE NOWAIT;
id | name | age | salary | hire_date | row_ve
rsion
--------------------------------------+------+-----+---------+-------------------------+----------
----------
26E185EF-09A3-461F-8F46-23FB4DD5022A | 张三 | 30 | 6500.00 | 2025-07-01 11:26:15.247 | 0x0000000
00000000A
(1 row)
sqldb=#
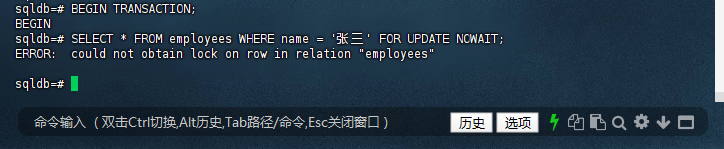
5.3 会话2:尝试获取同一行数据的锁,使用NOWAIT
– 在另一个终端执行以下命令(假设已连接到testdb数据库)
– BEGIN TRANSACTION;
– SELECT * FROM employees WHERE name = ‘张三’ FOR UPDATE NOWAIT;
– 如果会话1已经锁定了该行,会话2会立即报错,而不是等待
sqldb=# BEGIN TRANSACTION;
BEGIN
sqldb=# SELECT * FROM employees WHERE name = '张三' FOR UPDATE NOWAIT;
ERROR: could not obtain lock on row in relation "employees"
sqldb=#
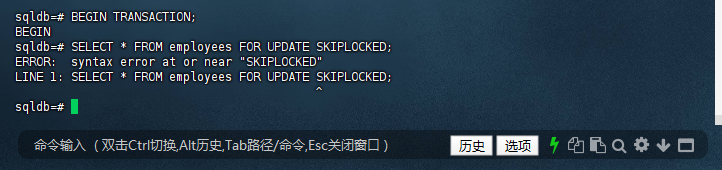
5.4 会话2:使用SKIPLOCKED
– BEGIN TRANSACTION;
– SELECT * FROM employees FOR UPDATE SKIPLOCKED;
– 该查询会跳过已被锁定的行,只锁定未被锁定的行
sqldb=# BEGIN TRANSACTION;
BEGIN
sqldb=# SELECT * FROM employees FOR UPDATE SKIPLOCKED;
ERROR: syntax error at or near "SKIPLOCKED"
LINE 1: SELECT * FROM employees FOR UPDATE SKIPLOCKED;
^
sqldb=#
6. FOR…XML
(金仓数据库不完全支持,可通过其他方式模拟)
6.1 创建一个包含XML数据的表
sqldb=# CREATE TABLE xml_test (
sqldb(# id SERIAL PRIMARY KEY,
sqldb(# xml_data TEXT -- 存储XML数据
sqldb(# );
CREATE TABLE
sqldb=#
6.2 插入XML数据
sqldb=#
<LUES ('<employee><name>张三</name><age>30</age></employee>');
INSERT 0 1
sqldb=#

6.3 查询XML数据(金仓数据库没有直接的FOR…XML语法,可通过字符串函数等处理)
sqldb=# SELECT xml_data FROM xml_test;
xml_data
-----------------------------------------------------
<employee><name>张三</name><age>30</age></employee>
(1 row)
sqldb=#
7. TOP子句相关操作
7.1 安装 uuid-ossp 扩展
– 以超级用户身份执行
sqldb=# CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE EXTENSION
sqldb=#

操作成功:扩展已加载,可使用 uuid_generate_v4() 等函数生成 UUID。
7.2 插入多条数据
通过字符串中转(推荐)
– 生成 uuid 并转为字符串,再转为 uniqueidentifier
示例1:插入赵六的数据
sqldb=# INSERT INTO employees (id, name, age, salary, hire_date)
sqldb-# VALUES (
sqldb(# uuid_generate_v4()::text::uniqueidentifier,
sqldb(# '赵六',
sqldb(# 40,
sqldb(# 7000.00,
sqldb(# CURRENT_TIMESTAMP
sqldb(# );
INSERT 0 1
sqldb=#
示例2:插入钱七的数据
sqldb=# INSERT INTO employees (id, name, age, salary, hire_date)
sqldb-# VALUES (
sqldb(# uuid_generate_v4()::text::uniqueidentifier,
sqldb(# '钱七',
sqldb(# 32,
sqldb(# 5200.00,
sqldb(# CURRENT_TIMESTAMP
sqldb(# );
INSERT 0 1
sqldb=#
示例3:插入孙八的数据
sqldb=# INSERT INTO employees (id, name, age, salary, hire_date)
sqldb-# VALUES (
sqldb(# uuid_generate_v4()::text::uniqueidentifier,
sqldb(# '孙八',
sqldb(# 29,
sqldb(# 4800.00,
sqldb(# CURRENT_TIMESTAMP
sqldb(# );
INSERT 0 1
sqldb=#
7.3 查询 1:查询年龄大于30的前2条记录
sqldb=# SELECT * FROM employees WHERE age > 30 LIMIT 2;
id | name | age | salary | hire_date | row_version
--------------------------------------+------+-----+---------+-------------------------+--------------------
22F2D2B5-C645-4E7E-B7EE-5C4E0150BE20 | 王五 | 40 | 7500.00 | 2025-07-01 11:30:13.957 | 0x0000000000000006
FB588981-4068-407C-A403-8E3415ED8EF4 | 钱七 | 32 | 5200.00 | 2025-07-01 15:04:46.110 | 0x000000000000000B
(2 rows)
sqldb=#
- 结果验证:
- 返回了
age为 40 和 32 的两条记录(王五、钱七)。 - 结果集大小符合
LIMIT 2的限制。
- 返回了
- 结论:操作正确,结果符合预期。
7.4 查询 2:查询前3条记录
sqldb=# SELECT * FROM employees LIMIT 3;
id | name | age | salary | hire_date | row_version
--------------------------------------+------+-----+---------+-------------------------+--------------------
F338A4BD-3B07-4D5C-8067-75976A52FF2E | 李四 | 28 | 5500.00 | 2025-07-01 11:29:37.003 | 0x0000000000000005
22F2D2B5-C645-4E7E-B7EE-5C4E0150BE20 | 王五 | 40 | 7500.00 | 2025-07-01 11:30:13.957 | 0x0000000000000006
26E185EF-09A3-461F-8F46-23FB4DD5022A | 张三 | 30 | 6500.00 | 2025-07-01 11:26:15.247 | 0x000000000000000A
(3 rows)
sqldb=#
- 结果验证:
- 返回了表中前3条记录(李四、王五、张三)。
- 结果集大小符合
LIMIT 3的限制。
- 结论:操作正确,结果符合预期。
8. 优化排序规则
添加排序字段(如 hire_date 或 id)以确保结果可预测:
8.1 查询年龄大于30的前2条记录(按入职时间倒序)
sqldb=# SELECT * FROM employees
sqldb-# WHERE age > 30
sqldb-# ORDER BY hire_date DESC
sqldb-# LIMIT 2;
id | name | age | salary | hire_date | row_version
--------------------------------------+------+-----+---------+-------------------------+--------------------
36FE104F-AB5F-48AF-83E2-DF1D9BC24EF0 | 赵六 | 40 | 7000.00 | 2025-07-01 15:06:23.027 | 0x000000000000000C
FB588981-4068-407C-A403-8E3415ED8EF4 | 钱七 | 32 | 5200.00 | 2025-07-01 15:04:46.110 | 0x000000000000000B
(2 rows)
sqldb=#
8.2 查询前3条记录(按入职时间正序)
sqldb=# SELECT * FROM employees
sqldb-# ORDER BY hire_date
sqldb-# LIMIT 3;
id | name | age | salary | hire_date | row_version
--------------------------------------+------+-----+---------+-------------------------+--------------------
26E185EF-09A3-461F-8F46-23FB4DD5022A | 张三 | 30 | 6500.00 | 2025-07-01 11:26:15.247 | 0x000000000000000A
F338A4BD-3B07-4D5C-8067-75976A52FF2E | 李四 | 28 | 5500.00 | 2025-07-01 11:29:37.003 | 0x0000000000000005
22F2D2B5-C645-4E7E-B7EE-5C4E0150BE20 | 王五 | 40 | 7500.00 | 2025-07-01 11:30:13.957 | 0x0000000000000006
(3 rows)
sqldb=#
8.3 优化分页查询
- 场景:需获取第 N 页数据时-- 跳过前2条,取4条(第3、4页面)。
- 方案:使用
LIMIT+OFFSET:
sqldb=# SELECT * FROM employees
sqldb-# ORDER BY hire_date
sqldb-# LIMIT 2 OFFSET 4;
id | name | age | salary | hire_date | row_version
--------------------------------------+------+-----+---------+-------------------------+--------------------
36FE104F-AB5F-48AF-83E2-DF1D9BC24EF0 | 赵六 | 40 | 7000.00 | 2025-07-01 15:06:23.027 | 0x000000000000000C
1C7A03B0-1928-46B4-9932-C924906FA81D | 孙八 | 29 | 4800.00 | 2025-07-01 15:07:21.999 | 0x000000000000000D
(2 rows)
sqldb=#
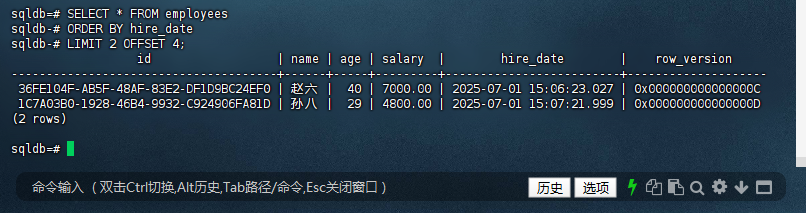
8.4 优化索引
- 问题:频繁对大表使用
LIMIT可能导致性能下降。 - 解决方案:对排序字段(如
hire_date)建立索引:
sqldb=# CREATE INDEX idx_employees_hire_date ON employees (hire_date);
CREATE INDEX
sqldb=#

9. 索引操作测评
9.1 – 创建索引
创建一个基于 name 列的索引:
sqldb=# CREATE INDEX idx_employees_name ON employees (name);
CREATE INDEX
sqldb=#

成功创建了名为 idx_employees_name 的索引。
9.2 – 创建索引查看索引信息
在创建索引之后,可以使用 \d employees 命令来查看表 employees 的详细信息,包括已创建的索引:
sqldb=# CREATE INDEX idx_employees_name ON employees (name);
CREATE INDEX
sqldb=# \d employees
Table "dbo.employees"
Column | Type | Collation | Nullable | Default
-------------+------------------+-----------+----------+---------
id | uniqueidentifier | | not null | newid()
name | varchar(100) | ci_x_icu | |
age | int | | |
salary | numeric(10,2) | | |
hire_date | datetime | | |
row_version | rowversion | | not null |
Indexes:
"employees_pkey" PRIMARY KEY, btree (id NULLS FIRST)
"idx_employees_hire_date" btree (hire_date NULLS FIRST)
"idx_employees_name" btree (name NULLS FIRST)
sqldb=#
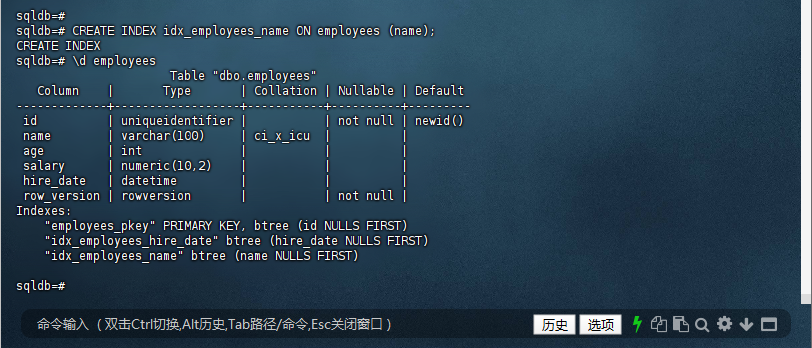
可以看到,名为 idx_employees_name 的索引已经存在,并且是基于 name 列构建的。
9.3 创建索引重建索引
为了维护或优化数据库性能,有时需要重建索引。以下是重建 idx_employees_name 索引的操作:
sqldb=# REINDEX INDEX idx_employees_name;
REINDEX
sqldb=#

9.4 重建索引前
通过 EXPLAIN ANALYZE 查询计划分析工具,我们可以看到在重建索引之前对 name = ‘张三’ 的查询执行情况:
sqldb=# EXPLAIN ANALYZE SELECT * FROM employees WHERE name = '张三';
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on employees (cost=0.00..1.07 rows=1 width=136) (actual time=0.039..0.045 rows=1 loops=1)
Filter: (name = '张三'::varchar(6))
Rows Removed by Filter: 5
Planning Time: 0.414 ms
Execution Time: 0.080 ms
(5 rows)
sqldb=#
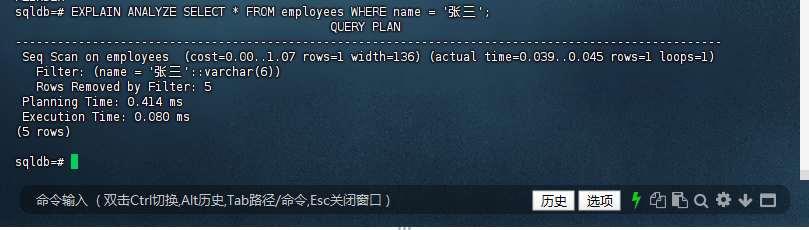
执行结果表明索引重建成功。
9.5 重建索引后
再次使用 EXPLAIN ANALYZE 来检查相同查询的性能,以观察是否有任何改进:
sqldb=#
sqldb=# EXPLAIN ANALYZE SELECT * FROM employees WHERE name = '张三';
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on employees (cost=0.00..1.07 rows=1 width=136) (actual time=0.030..0.033 rows=1 loops=1)
Filter: (name = '张三'::varchar(6))
Rows Removed by Filter: 5
Planning Time: 0.079 ms
Execution Time: 0.053 ms
(5 rows)
sqldb=#
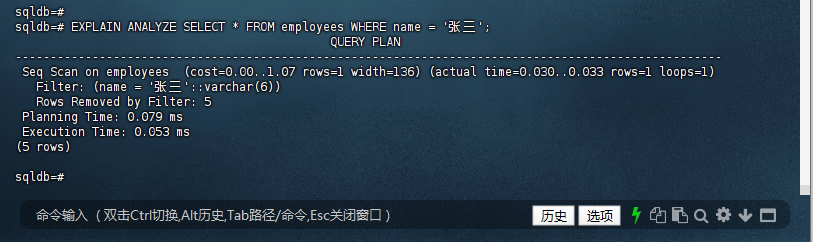
9.6 创建覆盖索引
– 创建包含查询字段的覆盖索引
sqldb=# CREATE INDEX idx_employees_name_covering
sqldb-# ON employees (name)
sqldb-# INCLUDE (age, salary, hire_date);
CREATE INDEX
sqldb=#

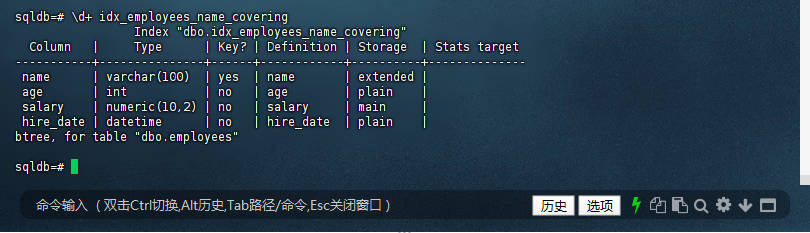
9.7 确认索引结构
sqldb=# \d+ idx_employees_name_covering
Index "dbo.idx_employees_name_covering"
Column | Type | Key? | Definition | Storage | Stats target
-----------+---------------+------+------------+----------+--------------
name | varchar(100) | yes | name | extended |
age | int | no | age | plain |
salary | numeric(10,2) | no | salary | main |
hire_date | datetime | no | hire_date | plain |
btree, for table "dbo.employees"
sqldb=#
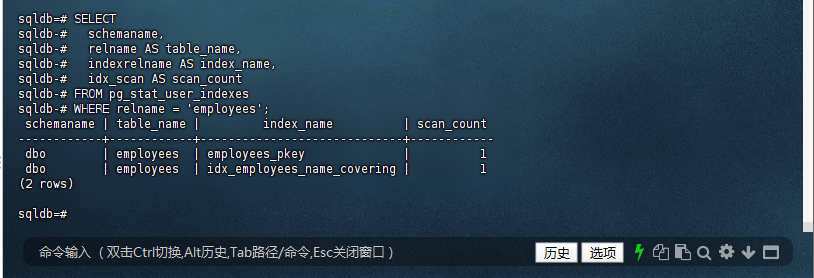
9.8 监控索引使用率
sqldb=# SELECT
sqldb-# schemaname,
sqldb-# relname AS table_name,
sqldb-# indexrelname AS index_name,
sqldb-# idx_scan AS scan_count
sqldb-# FROM pg_stat_user_indexes
sqldb-# WHERE relname = 'employees';
schemaname | table_name | index_name | scan_count
------------+------------+-----------------------------+------------
dbo | employees | employees_pkey | 1
dbo | employees | idx_employees_name_covering | 1
(2 rows)
sqldb=#
对比分析:
尽管在重建索引前后,查询都是通过顺序扫描(Seq Scan)进行的,但可以看出重建索引后,查询的规划时间(Planning Time)和执行时间(Execution Time)都有所减少。这表明虽然索引重建对这个特定查询的影响较小,但在某些情况下,特别是数据量较大或索引碎片较多的情况下,重建索引可能会显著改善查询性能。
请注意,对于实际应用中是否需要重建索引以及何时重建,还需要根据具体的业务场景和系统状态来判断。此外,如果希望查询更多地利用索引,确保查询条件能够匹配到索引字段非常重要。
总结
通过本次在Linux CentOS7环境下对金仓数据库KingbaseESV9R4C12(SQL Server兼容版)的部署、库和表的创建以及部分SQL Server兼容特性的实操测评,我们对金仓数据库有了更深入的了解。
在部署过程中,金仓数据库提供了较为详细的安装向导和文档,使得安装过程相对顺利。在创建库和表时,SQL语法与常见的数据库系统较为相似,易于上手。在实操测评方面,我们针对SQL兼容特性和索引操作进行了详细的代码测试。
对于SQL兼容特性,金仓数据库在部分特性上做了较好的兼容,如ROWVERSION、UNIQUEIDENTIFIER等类型能够正常使用,NOWAIT/SKIPLOCKED等锁相关子句也表现出与SQL Server类似的行为。然而,对于一些较为复杂的特性,如FOR...XML,金仓数据库的支持还不够完善,需要通过其他方式模拟实现。
在索引操作方面,重建索引的操作能够顺利完成,并且通过对比重建索引前后的查询性能,发现重建索引后查询效率有所提升,说明索引重建功能在金仓数据库中是有效的。
总体而言,金仓数据库作为国产数据库的代表之一,在SQL Server兼容性方面取得了一定的成果,能够满足大部分常见的业务需求。但在一些高级特性的支持上还有待进一步完善。希望通过本次体验官活动,能够推动金仓数据库不断优化和改进,为用户提供更优质的产品和服务。
