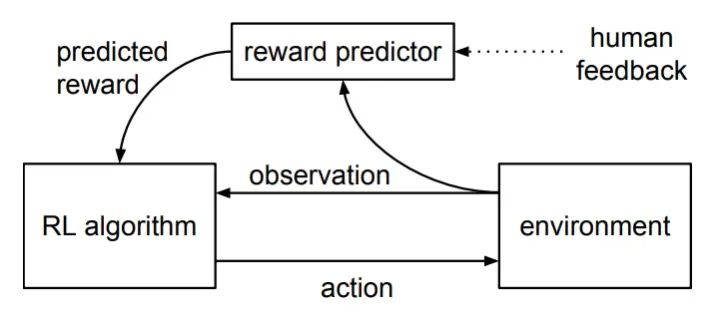
大语言模型(Large Language Models, LLM)领域正在进行着飞速的发展 [1],为许多下游的场景与应用注入了活力。对齐(Alignment)技术是这些发展背后的重要一环,使大语言模型的行为符合人类的准则与价值观。而奖励模型(Reward Models)能作为人类偏好的代理,为对齐过程如基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)提供可量化的信号。此外,奖励模型也在数据、推理侧发挥着重要的作用,因此受到了广泛的关注。本文将对奖励模型的偏好收集方法进行介绍与讨论。
尽管从经验丰富的人类标注者中收集偏好数据直观上更适合人类偏好对齐,但是逐渐增长的成本可能会限制其实用性。而随着大语言模型能力的不断提升,其在评估维度展现了与人类的高度一致性,价格也相对更低 [9]。并且,当 AI 系统在某些任务上超过人类时,人类很难快速而准确地评估超人模型(Superhuman Model)的复杂行为(如生成的项目级别代码、与模拟或现实环境的大量交互数据等),从较弱的教师模型(Teacher Model)引导更强的学生模型(Student Model)将愈发重要 [10]。在这种背景下,基于AI或规则的偏好收集引起了逐渐增多的研究兴趣,并且具有替代人类偏好的潜力。
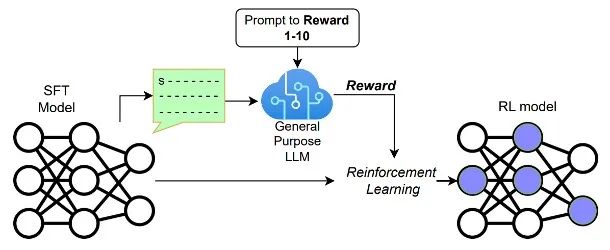
Lee 等人[11] 将基于 AI 反馈的强化学习(Reinforcement Learning from AI Feedback, RLAIF)和 RLHF 进行了比较。对于 RLAIF 框架,即插即用(off-the-shelf)的强 AI 模型既可以被用来标注成对的响应,帮助后续奖励模型的训练,同时也能直接当作奖励模型为强化学习训练提供标量奖励(见下图)。进一步地,从强 AI 模型获取偏好可以结合其它相关技术,例如通过检索增强生成(Retrieve-Augmented Generation)技术从外部获取额外信息作为支撑,通过思维链(Chain-of-Thoughts, CoT)技术获取可解释的推理过程,以及应用测试时扩展(Test-Time Scaling)技术增强偏好判断的准确性。
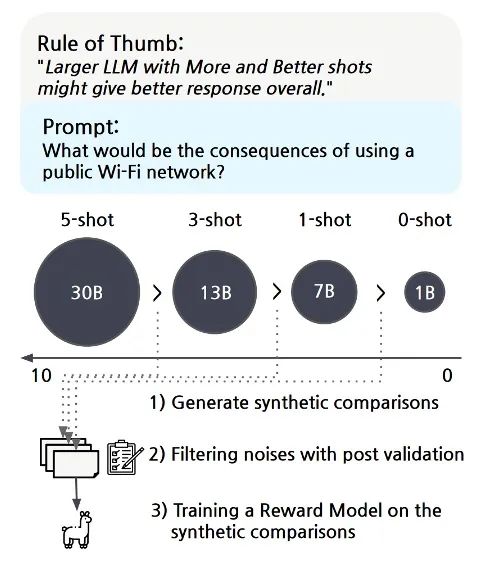
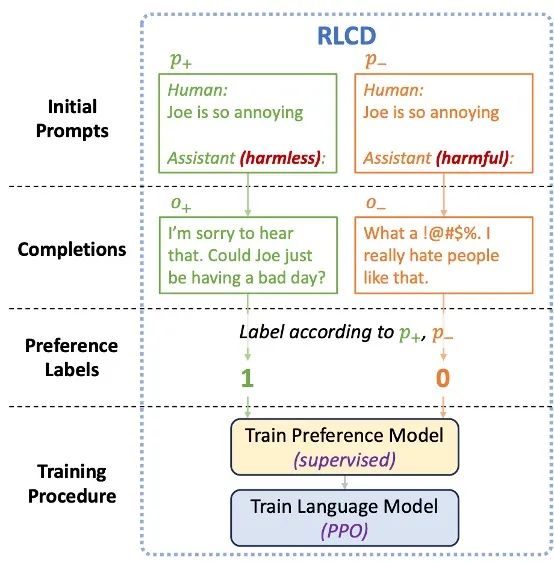
Yang 等人[13] 保持提示的主干部分固定,并在提示的结尾指定智能体助手的风格是无害的(Harmless)或有害的(Harmful),从而便捷地产生成对的偏好样本(见下图)。这种方式能避免直接利用 AI 模型进行判断产生的误差(例如有些样本对的质量相差较小),同时也能保证正负样本的分布尽可能接近,避免引入其它维度的偏差(Bias),如回复的长度、格式等。
随着AI模型能力不断提升,AI 偏好数据的比例会逐渐变大,可以补充与增强人类偏好,但难以完全取代人类偏好。AI 模型难以涵盖伦理、情感等维度,并且在多样性方面不如人类偏好,只能提供通用而普遍的判断。此外,采用 AI 偏好数据迭代式地训练 AI 模型存在模型崩溃的风险。
(2)AI 偏好相比人类偏好的优势只在于成本吗?
AI 偏好较为便宜、并且很容易通过思维链、检索增强生成等技术实现更高的可解释性。并且,AI 偏好的稳定性也相对较高,不会因情绪、疲劳等因素产生波动。但与此同时,AI 偏好可能会在细微条件的限制下出错,且容易受到响应格式、长度等因素的干扰。
(3)偏好收集有哪些潜在的研究方向?
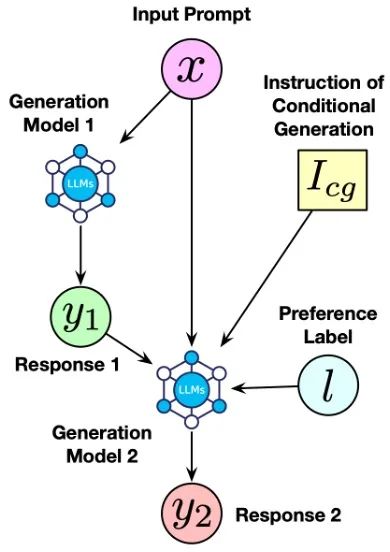
对于 AI 偏好,如何设计规则高效地合成和使用存在较大的研究空间。而对于人类偏好,在有限标注数据下的奖励模型训练较为重要,例如基于少量高质量人类偏好实现奖励模型热启动。此外,从大规模粗粒度人类偏好数据(仅有好坏二元标签)向细粒度人类偏好数据(包含不同评价维度)的蒸馏和迁移将成为减少开销的潜在研究方向。
参考文献
[1]: Tie et al. “Large Language Models Post-training: Surveying Techniques from Alignment to Reasoning.” arXiv preprint arXiv:2503.06072 (2025).
[2]: Ouyang et al. “Training language models to follow instructions with human feedback.” NeurIPS (2022).
[3]: Bai et al. “Training a helpful and harmless assistant with reinforcement learning from human feedback.” arXiv preprint arXiv:2204.05862 (2022).
[4]: Christiano et al. “Deep reinforcement learning from human preference.” NeurIPS (2017).
[5]: Bradley et al. “Rank analysis of incomplete block designs: I. The method of paired comparisons.” Biometrika (1952).
[6]: Biyik et al. “Active preference-based gaussian process regression for reward learning.” RSS (2020).
[7]: Park et al. “SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning.” ICLR (2022).
[8]: Hwang et al. “Sequential preference ranking for efficient reinforcement learning from human feedback.” NeurIPS (2023).
[9]: Gilardi et al. “ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks.” arXiv preprint arXiv:2303.15056 (2023).
[10]: Zhang et al. “LLMaAA: Making Large Language Models as Active Annotators.” EMNLP Findings (2023).
[11]: Lee et al. “RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback.” ICML (2024).
[12]: Kim et al. “Aligning large language models through synthetic feedback.” EMNLP (2023).
[13]: Yang et al. “RLCD: Reinforcement Learning from Contrastive Distillation for LM Alignment.” ICML (2024).
[14]: Shen et al. “Boosting Reward Model with Preference-Conditional Multi-Aspect Synthetic Data Generation.” arXiv preprint arXiv:2407.16008 (2024).
[15]: Zhong et al. “A Comprehensive Survey of Reward Models: Taxonomy, Applications, Challenges, and Future.” arXiv preprint arXiv:2504.12328 (2025).