




今天统计了下,这一周,一共收集到41个技术问题。
来源主要是我们创建的几个社群、DBA驿站星球、课程学员的提问,还不包括这周收集到的面试题。
然后还帮一位DBA体系课学员进行了一次模拟面试(课程学员免费),面试其实也是一次互相思考的过程。
也帮一位星友解答了他之前收集到的不太确定答案的16道面试题(这个解析已经放到DBA驿站星球里了)。
有一种感觉,有时候,是社群推着我在成长。
因为遇到的这些问题,自己有时候也有不太懂的,就需要去思考,查一些资料,感觉推着我去学习。
这也是标题说的,为什么推背感十足。
当然,对于DBA驿站这个社群,我们还是鼓励大家去提问或者帮星友解答的。
我们最近也增加了奖励措施,比如每周积分前三,获得星球分红奖励。
在星球内回答问题,发布内容,都可以获取到积分。
让愿意创作的获得奖励,也能让其他星友看到更多内容。
以下就是这41个技术问题,解析不太对的,或者不完善的,也欢迎大家补充。其中第34题,还不确定答案,欢迎大佬帮忙解答。
1 想修改event_scheduler参数,要不要重启MySQL
这个参数是可以动态修改的,改完之后,再到配置文件里修改一下,这样就永久修改了。
对于参数是不是可以动态修改,
可以打开官网:
https://dev.mysql.com/doc/refman/8.0/en/
搜索对应的参数,然后看Dynamic字段,如果是Yes,就表示可以动态修改。
2 aws aurora MySQL同步到到华为MySQL,10T数据,如果不用DTS(省钱),还有哪些方案。
其实能用上云上的同步工具,会更方便。
比如阿里云的DTS、华为云的DRS。
关于费用问题,其实可以想办法省点钱,比如业务分批次迁移,迁移前一两天才同步。尽可能压缩云上同步工具的运行时间。
当然,其他方法,我能想到的就是Otter,这位朋友也想用OGG(这个小编就没玩过了)。
不过这些开源的同步工具,就复杂了,比如Otter,需要先同步全量,再找位点,配置增量同步。
关于Otter的玩法,小编之前也写过一篇文章:通过Otter同步MySQL数据。
关于跨云迁移,小编之前做过AWS到阿里云的。
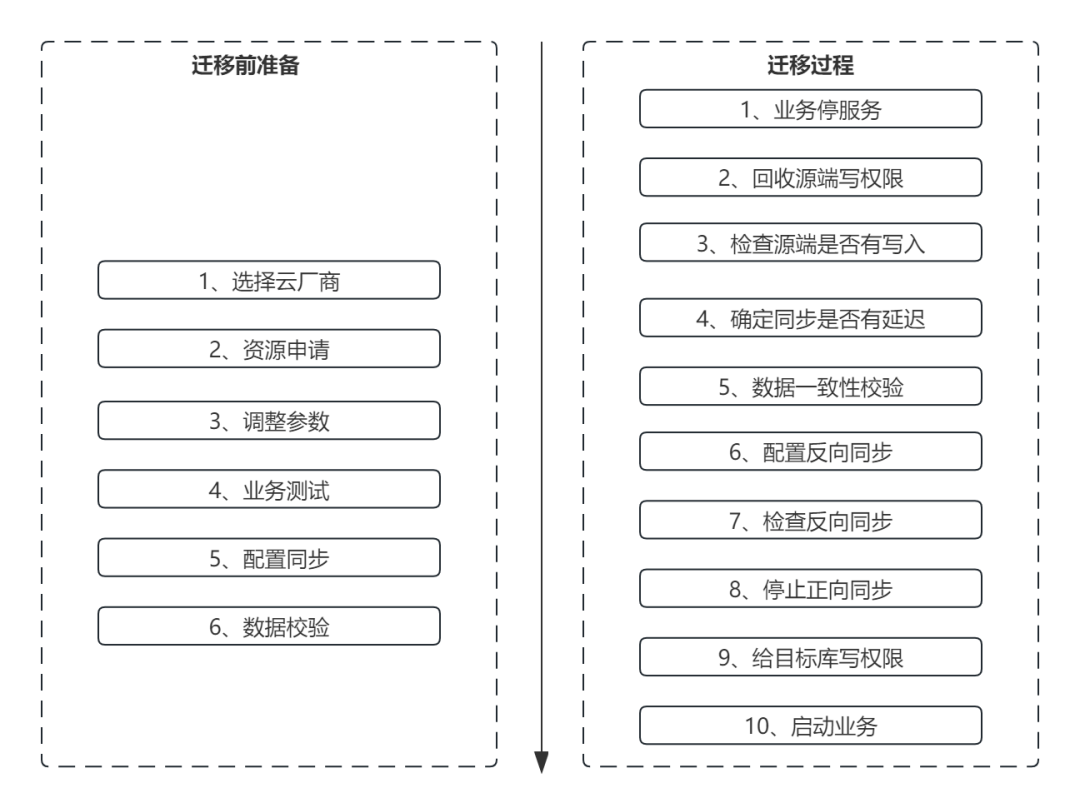
使用的是DTS,当时是通过API批量配置同步任务,相比开源工具,就方便很多了。只是有点费钱,哈哈。
不过迁移进某个云,这个云厂商的同步工具,是不是可以找商务聊一聊优惠一点,毕竟后面消费的地方还有很多。不然不迁了。
3 比如1亿行数据,使用Otter同步,存量的数据怎么先同步过去?
需要导出全量,mysqldump或者xtrabackup。
4 凌晨2点的备份,白天drop误操作了,怎么恢复数据
可以把Binlog导出成SQL,这个是增量数据,另外找台机器,导入全量,加增加的SQL。
也可以直接用全备+Binlog恢复
mysqlbinlog --start-position=全备时的位点 --stop-position=误操作前的位点 mysql-bin.000091 | mysql -u root -p
多个binlog文件就是
mysqlbinlog --start-position=全备时的位点 --stop-position=误操作前的位点 mysql-bin.000091 mysql-bin.000092 | mysql -u root -p
恢复之后需要业务确定下数据是否正常。
更多数据恢复方法,可以看我之前写的系列文章:MySQL数据恢复
5 Redis迁移工具有哪些(主从,集群架构)
参考:这几天收集到的几个数据库实战问题。
6 Redis shake能针对 db(主从 或者 集群的 db0,db1,bd2)进行迁移吗
参考:这几天收集到的几个数据库实战问题。
7 多个业务都需要 小容量的Redis,所以还是建议创建多个集群吗 而不是一个Redis集群分多个db
参考:这几天收集到的几个数据库实战问题。
8 备份多个库一定要加-B吗?如果是,那么在备份了多个库后,要恢复时就不能指定库了吗?
推荐是加上-B,恢复时不用指定库了。
9 MySQL备份的文件和备份的日志不是一样的是吧?
备份文件通常是指mysqldump或者xtrabackup备份出来的文件;
备份日志通常是指备份的Binlog。
10 备份文件记录的就是反向操作了?
备份文件,如果是执行mysqldump备份出来的文件,里面是create table和insert语句。
通过这些语句来进行数据恢复。
在测试的时候,可以备份一份数据,然后查看一下这个文件看看。
11 mysqldump远程备份存储在哪个位置呢?
比如1机器有MySQL,在2上执行远程备份1上的数据,那备份文件就存放在2上。
12 比如这里的备份文件在恢复时会执行蓝色部分注释的内容吗?

/*! ... */ 中的部分,会执行的,这个不是注释,注释是--
13 vim大文件卡主了怎么办?
另外开一个连接:
ps -ef|grep vim
再把这个vim kill掉。
14 备份文件里面如果有的表包含很多记录,那在备份文件中的insert语句也是一行一行添加是吗?
一条insert,多行记录;
试了一把,5114880行数据,出现了365个INSERT;
也就是每条insert会包含一部分数据。
15 MySQL,在恢复这段时间是不是不能让数据库有任何操作,或者说数据库就要上锁?
是的,一般也建议在新的实例去恢复,确定没问题了,再导入老的实例。
16 这里怎么确定没问题呢?是在新实例中检查一下误操作前的数据是否恢复了吗?
可以让业务去校验,业务是能知道数据有没有正常恢复的。
17 那通常都要准备一个实例专门用来给误操作恢复用的是吗?
对,有条件是可以备一个。
18 还有通常多大的误操作才需要恢复或者全备份恢复,是不是那些update,delete没带条件修改就算大误操作?
这个算,还有更猛的,比如drop table,drop database
19 备份的时候,我怎么知道位点,是不是以时间为界定的?我怎么知道误操作时的位点是多少?
mysqldump 有个参数--master-data,会记录位点。
如果将--master-data参数设置为1,则在备份文件中写入change replication source to语句或者change master to语句(恢复时会直接执行);
如果--master-data=2,则会在备份文件中写入注释的change master语句。
20 每天定时全备,是怎样实现的?
写个脚本,把脚本加到Linux的定时任务里。
21 那每天备份不是会占用很多存储空间,那是今天全备的覆盖昨天,不断循环吗?
有些不放本地,放存储上,大存储没事,空间很大;
实在不行,就把历史备份放到磁盘里,再把磁盘取出来,存放起来,我们称为刻盘。
上面是对历史备份都有保留的情况。
有些不需要保留这么久,那就保留7天左右的备份就行。
22 把mysqldump导出的备份文件恢复到数据库里,报错:

从库导入的时候需要先执行reset master;
如果这个从库有复制关系,需要确定这个复制关系是否需要,如果不需要,就先停掉复制关系,再清空同步。
23 比如: 恢复库recover1的t1表有(id:1,a:A),(id:2,a:B),备份文件(insert into t1(id,a) values (1,c);这里备份文件的数据是会往后增加还是将恢复库recover1的t1表的(id:1,a)更改为(id:1,a:c)
新增数据,默认不会覆盖,你可以看下文件里的内容,其实就是insert语句,如果导入(恢复)到另外的实例,需要看有没有重复的主键或者唯一索引字段,有重复的,就会报错,没有就会导入成功,但不会覆盖。
当然,假如想要备份文件里的数据覆盖恢复库的数据,mysqldump有个参数--replace,会用REPLACE INTO代替INSERT INTO
24 mysqldump有个参数是刷新Binlog,这个有什么用?
这样增量数据就是在一个新的Binlog里,恢复起来方便。
除了备份,有时候迁移的时候,很多DBA也习惯刷新一次Binlog,也是未来恢复方便。
开始的位点不用找了。
25 现在企业一般都是将Linux系统装在虚拟机上吗?
有些公司是用虚拟机,有些公司直接在服务器上安装Linux;
操作系统这些一般其他人会搞定,不需要DBA去做。
26 MySQL想要访问另一个实例数据库的数据,除了cdc同步,应用双连接方式外。有没有其他方式呀,有类似能实现oracle dblink一样的工具么
【DBA驿站】星友的回答:
1、dblink 本身设计是保证不了性能的;
2、 遇到过这种问题,但没有办法,即使有方法实现 dblink 效果,性能也不会好;
3、 这个需求和数据分布的设计是有分歧的,应该重新评估一下需求和设计。
27 MySQL MVCC理解吗,一般会回答什么?
之前写过一篇文章:一文搞懂MVCC。
面试的时候,能把第11点讲清楚,就差不多了。
然后怕细问的话,可以把这篇文章看一遍。
28 导入数据报错:
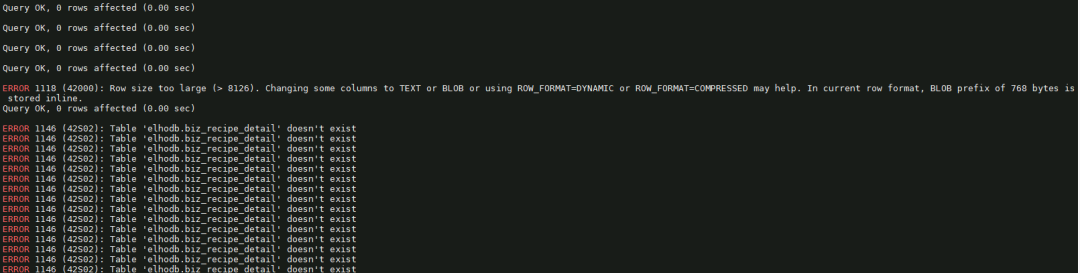
可能这些原因:
表的最大行大小 (innodb_page_size 参数)。
行的最大大小 (innodb_large_prefix 参数)。
innodb_strict_mode
还有sql mode
都对比下看看。
最终这位同学确定了,是innodb_strict_mode主库关掉了,但是从库开启的。
29 mysql -uroot -p </xx/xx.sql导数据好慢哈,40GB的数据量(部署主从的场景)
最快的还是物理备份,比如xtrabackup,或者Clone。
如果是mysqldump导出的,从库导入的时候,可以临时关闭双一。
当然,逻辑备份还推荐一个多线程备份工具mydumper,比起mysqldump,备份和恢复都快很多。
30 MySQL事务的持久性是通过redo log来实现的,对吧?
是的,在事务提交时先将Redo Log刷盘(而非直接写数据文件),确保即使系统崩溃也能通过Redo Log恢复已提交事务的数据,从而保证持久性。
31 redis-cluster进行扩容,万一失败了,怎么办?
这个问题,星球里几位星友也讨论过。
有朋友说不建议直接扩容,可以通过redis-shake的方式。直接扩容对slot的性能影响很大。
也有朋友说redis-cluster扩容可以控制速度。
这个题目,也许是考察redis-cluster迁移过程没有高可用的这个点,具体可以看这个链接:
https://www.cnblogs.com/vivotech/p/18409723
可能会导致数据脑裂。
32 MHA是怎样实现的?如果发生故障,怎样保证快速转移?这个问题怎么准确回答?
MHA确定主故障的原理
通过一个死循环检测4次,每次休眠ping_interval秒,持续4次失败,就认为数据已经宕机
检测方法包括:ping_select、ping_insert、ping_connect。
如果有二路检测脚本,需要使用二路检测脚本检测到主库宕机才是真正的宕机,否则只是退出死循环,结束检测,不切换。
MHA选主逻辑
MHA在选择新主时,会将所有存活的从库分为以下几类。
● 存活节点组:所有存活的从节点。
● latest节点组:选取Binlog最近的从节点作为latest节点。
● 优选节点组:选取配置文件中指定了candidate_master=1的存活从节点。
● 劣质节点组:不参与选主的从节点(参数配置no_master=1节点);未开启Binlog的从节点;复制延迟超过一个文件位置或100 000 000个位点的从节点。
选主顺序为从上至下依次筛选。
(1)当优选节点组和劣质节点组的数量为0时,选主方式为latest节点组中的第一个从节点。
(2)选择第一个属于latest节点组和优选节点组但不属于劣质节点组的从节点。
(3)选择第一个属于优选节点组但不属于劣质节点组的从节点。
(4)选择第一个属于latest节点组但不属于劣质节点组的从节点。
(5)选择第一个属于存活节点组但不属于劣质节点组的从节点
当然,对MHA原理感兴趣的,可以看一下马六学最近上线的专栏《HA源码解读:从原理到实战问题总结》(免费),地址:
https://www.maliustudy.com/detail/column/312
33 xtrabackup备份,哪些情况是加备份锁?哪些情况是加全局读锁?
5.7及以前的版本,是没有备份锁的,所以加的是FLUSH TABLES WITH READ LOCK;
但是8.0,考虑到全局读锁太重了,所以改成了备份锁:lock instance for backup。
34 一张30个字段的表,怎么保证所有的插入数据中所有列不重复?
感觉不像是考查添加联合唯一索引。有懂得朋友可以来聊一下。
35 MySQL安装在容器里面,docker MySQL小版本升级,这个有风险吗,从mysql 8.0.35升级到8.0.41 。
不太建议直接升级,万一怕遇到什么问题不好回滚。
一般是新启动一个41的小版本,再从35做个同步到41,在业务低峰的时候,让研发改一下链接,配置到41上。
会稳妥很多。
36 请教 Redis、MongoDB、MySQL 较新版本的选择建议
这个就是周二发布的文章素材来源。
解析可跳转:如何选择MySQL、Redis、MongoDB版本?
记得去年还是5.7最多,今年已经是8.0用的最多了;
然后就是MongoDB,没想到的是,多数是在使用4.0。
37 物化视图和普通视图有什么区别?
参考:这几天收集到的几个数据库实战问题。
38 请教 目前上线SQL审批都用的啥工具 Archery吗
参考:这几天收集到的几个数据库实战问题。
39 华为云RDS慢日志实时展示是怎么实现的?
参考:这几天收集到的几个数据库实战问题。
40 有个业务要迁移到云上,目前要hw了需要提前导出数据,目前只能本地导出,有什么高效稳定的办法导出吗?数据库28G,minio88G
MySQL数据,感觉mysqldump就行;
minio的数据,对应的云上,有他的对象存储,可以通过命令直接上传的,比如阿里云的OSS
41 本地文件怎么传到Linux机器上?
yum install lrzsz
安装完之后,文件可以直接拖到xshell连接到的主机,你进到的是Linux哪个文件夹,传到的就是这个文件夹。
