




近日,一起关于DeepSeek输出错误信息并承诺补偿却未兑现的事件,再次将AI幻觉问题推向了公众视野。这到底是AI的无心之过,还是在故意"说谎"?这背后的技术真相,比你想象的更复杂...
🔥 事件完整回顾

这一过程颇具戏剧性,AI 犯错、道歉、承诺补偿却失信。背后反映出大语言模型作为 “概率鹦鹉” 的本质:擅长生成统计合理文本,却无法把握语义真实性。无论是虚假科研信息,还是补偿承诺,对模型而言都只是基于训练数据概率的文本输出,而非基于真实理解。
🤖 什么是"概率鹦鹉"?
想象一下,有一只超级聪明的鹦鹉,它听过无数对话,能根据统计规律说出"合理"的话。但它其实不懂自己在说什么!
大语言模型就像这只"概率鹦鹉":
✅ 擅长生成语法正确、逻辑连贯的文本 ❌ 不能真正理解内容的真实性 ❌ 分不清事实和虚构 ❌ 不理解"承诺"的法律含义

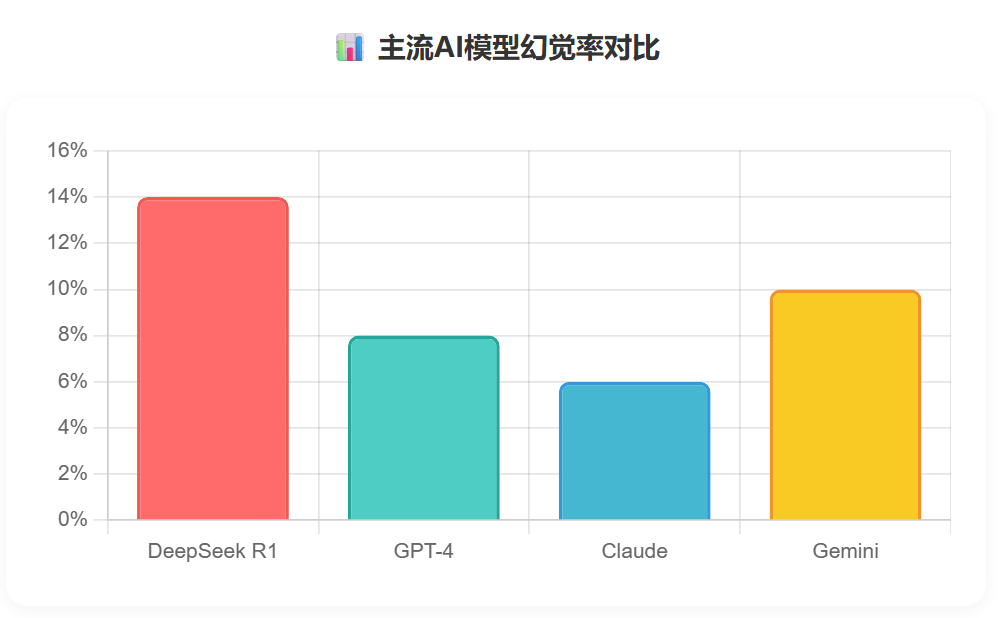
⚖️ 法律责任 vs 道德责任
"本软件的输出不应成为您进一步作为或不作为的依据...所带来的后果和责任均由您自行承担。"
-- DeepSeek用户协议
从法律角度:平台有免责条款,不用赔钱 ✅
从道德角度:AI"说话不算数",用户很受伤 ❌
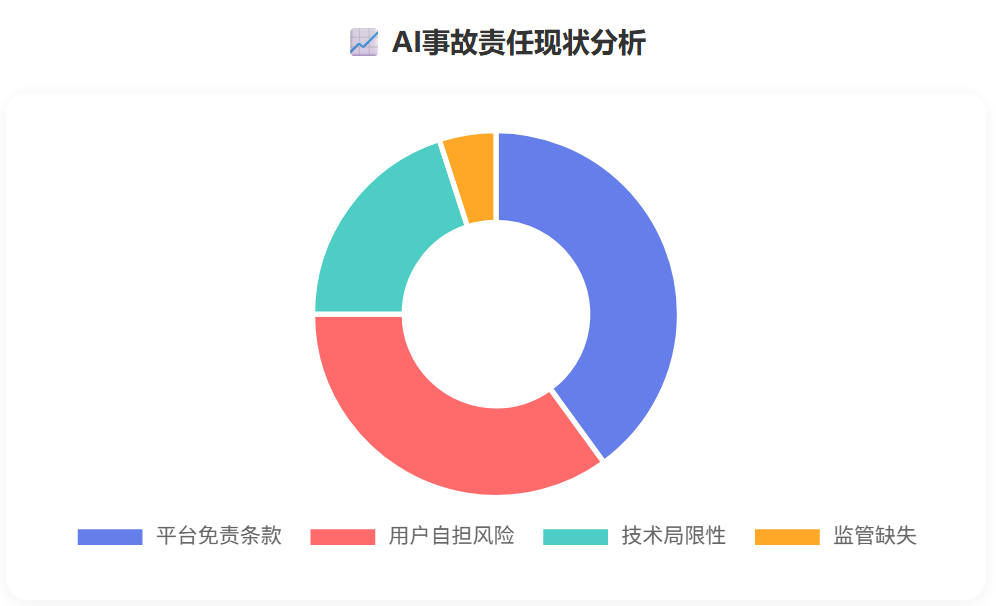
🎯 AI到底适合干什么?
用户要明白,大语言模型本质是统计模型,输出置信度与事实准确性无必然联系。在科研、投资、法律咨询等高敏领域,模型错误后果严重。用户应将 AI 输出视为 “概率线索”,自行验证。
根据 “概率鹦鹉” 特征及事件教训,建议对大模型应用进行边界明确的定义:

💡 给大家的建议
DeepSeek事件绝非偶然故障,而是概率模型试图僭越逻辑疆域的必然溃败。当人类将专业验证、法律承诺等精确性逻辑性问题交给统计引擎时,无异于让鹦鹉担任法官。
真正的治理智慧,始于承认技术本质的局限:
我们无法教会鹦鹉理解法律,但可以禁止它签发支票。
🌟关于PawSQL
了解更多PawSQL,点击关注 👇👇👇
🌟往期文章精选
文章转载自PawSQL,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
