




最近大数据界迎来了新的开源项目Apache Arrow(http://arrow.apache.org/),Arrow为列式内存分析提供了一种高性能跨系统数据层。
(1) 它采用了向量计算、列式存储等技术优化数据分析效率;
(2) 它是一个跨系统数据存储层(中间件),并支持多种编程语言,包括Java、C++等;
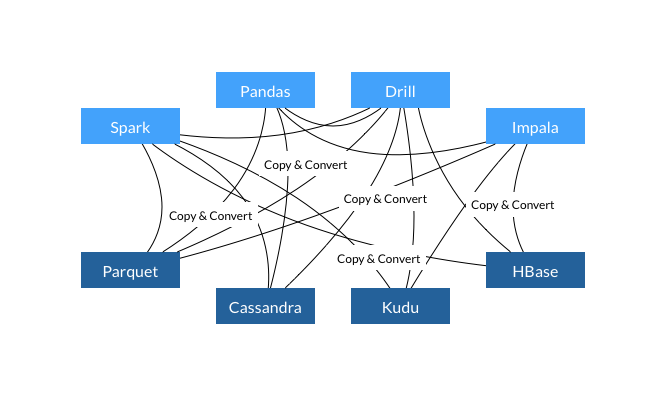
(3) 它的引入,有望解决不同大数据系统(比如Cassandra、HBase、Kudu、HDFS等)之间数据交换效率低下的问题(主要时间花在序列化和反序列化上)。欢迎大家关注这个新项目。
跨系统数据交换现状:
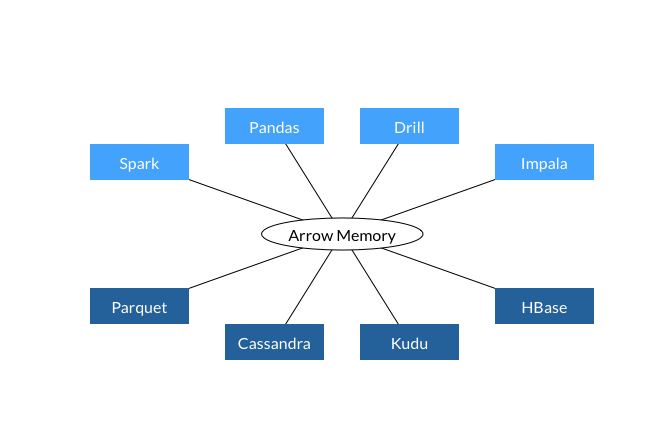
引入Arrow后,跨系统数据交换方式:
Apache Arrow官方网站:http://arrow.apache.org/
Apache Arrow源代码:https://github.com/apache/arrow

文章转载自hadoop123,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
