




(续前文)
5. 查询语言

Dremel的查询语言基于SQL,其实现是定制化设计的,可在列状嵌套存储上高效执行。定义语言严格上不是本文范畴,这里简介一下它的特点。每个SQL语句(被翻译成代数运算)以一个或多个嵌套表格和它们的schema作为输入,输出一个嵌套表格和它的schema。图6描述了一个query例子,执行了投影、选择和记录内聚合等操作(投影-projection,选择-selection,是SQL中的概念,可参考这里,就是SQL select语句中的各个部分)。例子中的query执行在图2中的t = {r1,r2}表格上。字段是通过路径表达式来引用。查询最终根据某种规则产出一个嵌套结构的数据,不需要用户在SQL中指明构造规则。
为了解释query做了什么,需要解释下选择和投影两个操作。在selection操作(where子句)中。可以将一个嵌套记录想象为一个树结构,树中每个节点的标签对应字段的名字。selection操作要做的,就是砍掉不满足指定条件的分支。因此,上述例子中,只有当Name.Url有值且满足正则’^http’才被保留。下一步,在投影操作中,select子句中的每个标量表达式都会投影为一个值,此值的嵌套深度和表达式中重复字段最多的保持一致。所以,Str值的嵌套深度与Name.Language.Code相同。COUNT表达式部分用到了记录内聚合。每个Name子记录都会执行此聚合,将Name.Language.Code出现的COUNT投影为每个Name下的Cnt值,它是一个非负数的64位的整型(uint64)。
此语言支持嵌套子查询,记录内聚合,top-k(排序),joins(多表关联),用户自定义函数等等;下面的实验章节会涉及到其中的一些特性。
6. QUERY的执行
【译者预读】分布式、并行计算是毋庸置疑的,此章节就是描述在数据分布式存储之后,如何尽可能并行的执行计算过程。核心概念就是实现一个树状的执行过程,将服务器分配为树中的逻辑节点,每个层级的节点履行不同的职责,最终完成整个查询。整个过程可以理解成一个任务分解和调度的过程。Query会被分解成多个子任务,子任务调度到某个节点上执行,该节点可以执行任务返回结果到上层的父节点,也可以继续拆解更小的任务调度到下层的子节点。此方案在论文中称为服务树(serving-tree)
简单起见,我们只讨论在只读系统中执行query的核心思路。很多Dremel查询其实是一次性的聚合,因此我们以这种类型的查询作为重点,并且在下一个章节中用它们进行试验。我们暂不讨论joins、索引、updates(更新操作)等,留在将来详述。
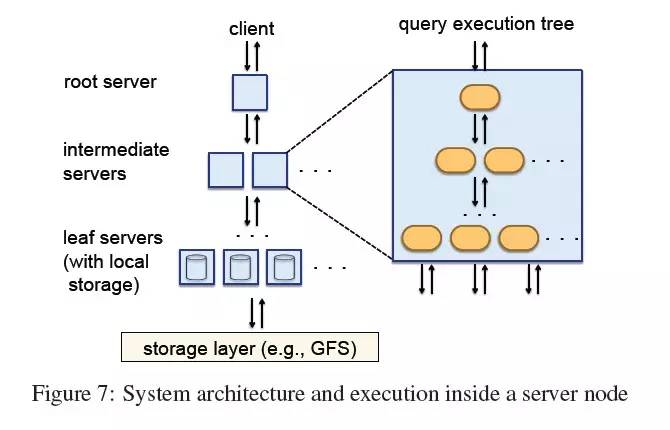
树结构。Dremel使用一个多层级服务树来执行查询(见图7)。一个根节点服务器接收到来的查询,从表中读取元数据,将查询路由到下一层。叶子服务器负责与存储层通讯,或者直接在本地磁盘访问数据。一个简单的聚合查询如下:
SELECT A, COUNT(B) FROM T GROUP BY A
当根节点服务器收到上述查询时,它确定出所有tablet(可以把一个column-stripe理解成一个table,称之为T,table被分布式存储和查询时可认为T进行了水平拆分,tablet就相当于一个分区),重写查询为如下:

【译者注】
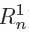
不方便编辑,这里使用R(1/n)来表示
R(1/1)到R(1/n)是树中第1层的(1到n)节点返回的子查询结果(根节点是第0层,下一层就是第1层,依次类推):

T(1/i)可认为是T在第1层的服务器i上被处理时的一个水平分区(tablet)。每一层的节点所做的都是与此相似的重写(rewrite)过程。查询任务被一级级的分解成更小的子任务(分区粒度也越来越小),最终落实到叶子节点,并行的对T的tablet进行扫描。在向上返回结果的过程中,中间层的服务器担任了对子查询结果进行聚合的角色。此计算模型非常适用于返回较小结果的聚合查询,这种查询也是交互式应用中最常见的场景。大型的聚合或者其他类型的查询可能更适合使用并行DBMS和MR来解决。
查询分发器。Dremel是一个多用户系统,也就是说,多个查询通常会被同时执行。一个查询分发器会基于table的分区和负载均衡对query进行调度。它还能帮助实现容错机制,当一个服务器变得很慢或者一个tablet拷贝不可访问时可以重新调度。
每个query的数据处理量通常比可执行的处理单元(slot)的数量要多。一个slot对应一个叶子服务器上的一个执行线程。比如,一个3000个叶子服务器的系统,每个叶子服务器使用8个线程,则拥有24000个slot。所以,一个table分解为100000个tablet,则会分配大约5个tablet到每个slot。在查询执行时,查询分发器会统计各tablet的处理耗时。如果一个tablet耗时较长或不成比例,它会被重新调度到另一个服务器。一些tablet可能需要被重新分发多次。
叶子服务器在列状结构中读取stripe。每个stripe的块被异步预取;预读缓存通常命中率为95%。tablet一般复制三份。当一个叶子服务器失效时,请求会通过故障恢复被调度到其他的拷贝上。
查询分发器有一个重要参数,它表示在返回结果之前一定要扫描百分之多少的tablet,我们最近证明了,设置这个参数到较小的值(比如98%而不是100%)通常能显著地提升执行速度,特别是当使用较小的复制系数时。
每个服务器有一个内部的执行树,就像图7右边部分。内部树对应到一个物理的query执行过程,包括标量表达式求值。通过优化,绝大部分标量方法会被生成为特定类型代码。在一个聚合查询的执行过程中,首先会有一组迭代器对输入列进行扫描,然后投影出聚合和标量函数的结果,结果上标注了正确的重复和定义深度,不断填充并最终装配出查询结果。详细算法请看Appendix D。一些Dremel查询,比如top-k(排序出前多少个)和count-distinct(去重计数),使用一些大家熟知的算法返回近似的结果(比如[4])。
7. 实验
【译者预读】论文少不了实验证明。但是这里的实验不仅是简单的证明Dremel多么厉害,而是在Dremel内也采用了不同的方案进行对比,让读者加深对Dremel内部机制的了解。
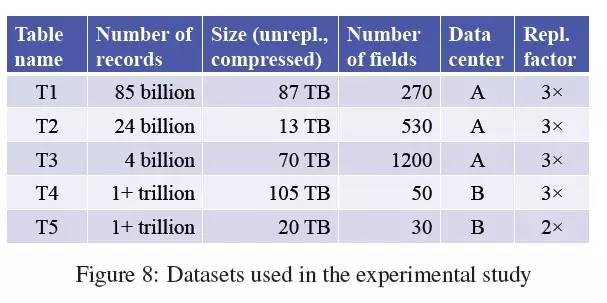
在这个章节里我们利用几个在Google使用的数据集合对Dremel的性能进行评估,以检验嵌套数据的列状存储到底效率如何。图8中描述了实验使用的数据集合的基本信息。数据集合如果不压缩、不复制,大概占据一个PB的空间。所有table是三向复制的,除了一个双向复制的table,tablets大小不一,从100K到800K。我们开始是在单台机器上检验基础数据访问特征,然后展现列状存储如何优于MR执行过程,最后重点分析一下Dremel的性能。实验运行在两个数据中心的系统节点上,和其他常规应用一起运行。除非另有说明,执行耗时一般会由5次结果求平均。下面使用匿名的Table和字段名。
本地磁盘。在第一个实验中,我们检查列状和面向记录两种存储的性能,表T1中有1GB的碎片包含大约300K行数据(见图9),分别用两种技术进行扫描。数据存储在一个本地磁盘,在压缩的列状存储中占用375MB,面向记录存储中使用了更重的压缩,但在磁盘占用空间上是相同的。实验在一个双核Intel机器上完成,磁盘提供70MB/S的查询带宽。两者执行时的系统环境是相同的,互不影响;OS缓存在每次扫描前都被清空。
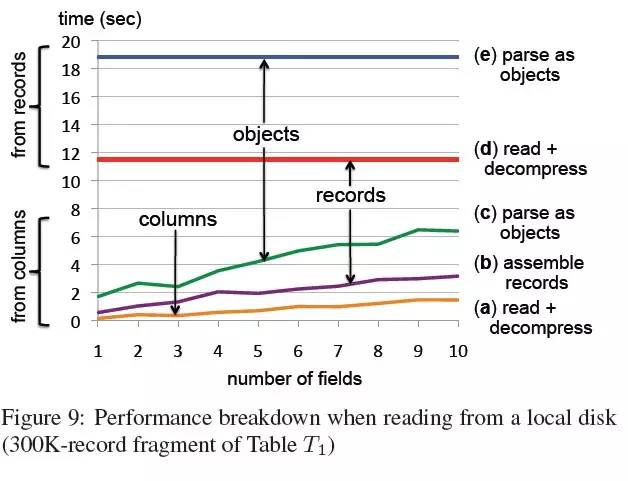
图中有5个曲线,说明了读取、解压数据、装配、解析记录的耗时。曲线(a)-(c)描述了列状存储的结果。这些图中每个数据点都平均通过了30次测量,每一次都随机选择一定数量的列。曲线(a)展现了读取和解压缩耗时。曲线(b)添加了装配嵌套记录的耗时。曲线(c)展现了将记录解析为强类型的c++数据结构的耗时。
曲线(d)到(e)描述了面向记录存储的各个耗时。曲线(d)展示了读取和解压缩时间。大量时间耗费在解压缩上;不过数据压缩确实减少了大约一半的磁盘读取时间。如曲线(e)指示,解析过程在读取和解压缩时间之上又增加了50%。这些耗时消耗在所有字段上,包括那些并不需要的。
这个实验主要的结论是:当只需读取少量列时,列状存储的性能提升了一个数量级,它的耗时与列的数量成正比。记录装配和解析是昂贵的,每个都可能导致执行耗时翻倍。在其他数据集合的实验中我们看到的趋势大致相同。观察曲线的趋势,很自然会想到一个问题:上下曲线何时交叉?交叉之时,也就意味着面向记录存储开始胜过列状存储。根据我们的经验,交叉点通常在几十个fields时出现,不过在不同数据集合中有所不同,跟是否执行记录装配也有关系。
MR和Dremel。下面的实验是在三者之间进行对比:MR+面向记录存储、MR+列状存储、Dremel+列状存储。这个场景只有一个field被访问,让列状存储的性能收益最明显(列的影响已经在图9和上面的实验中讨论过了,本实验就排除列数量的影响)。在这个实验中,我们利用表T1的txtField字段,计算每条记录的平均单词数量。MR使用下面的Sawzall[20]程序:
numRecs: table sum of int;
numWords: table sum of int;
emit numRecsemit numWords
每个记录中,会对input.txtField执行CountWords函数得到单词数量,不断累加得到numWords。在程序运行之后,使用numWords/numRecs得到平均单词数量。在SQL中,这个执行过程可被表示为:
Q1: SELECT SUM(CountWords(txtField)) / COUNT(*) FROM T1
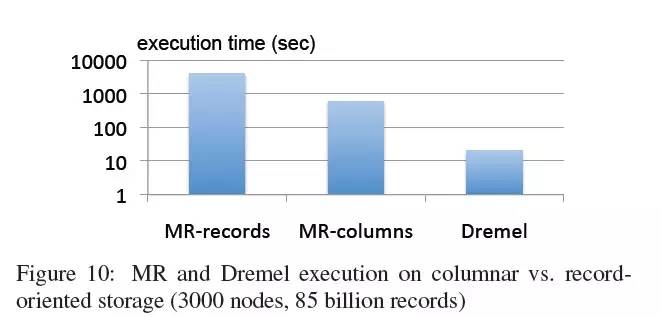
图10展现了两个MR任务和Dremel的执行耗时。两个MR任务被运行在3000个工作节点上。相似的,执行查询Q1的Dremel实例也拥有3000个节点。Dremel和MR+列状存储,读取大约0.5TB的压缩列状数据,MR+面向记录存储读取87TB数据。如图所示,MR从面向记录切换到列状存储后性能提升了一个量级(从小时到分钟)。使用Dremel则又提升了一个量级(从分钟到秒)。
服务树拓扑。在下一个实验里,我们展现了服务树深度对查询执行耗时的影响。对表T2执行两个GROUP BY查询,每个都会对数据进行一次扫描。表T2包含24 billion条嵌套记录。每个记录有一个重复字段item,包含一个数值amount。字段item.amount重复大概40 billion次。第一个查询按country来统计item.amount。
Q2: SELECT country, SUM(item.amount) FROM T2
GROUP BY country
它返回几百条记录,在磁盘上读取了大约60GB压缩数据。第二个查询在一个文本字段domain上执行GROUP BY,并且执行了一个选择条件。它读取大约180GB,产出大约1.1 million条去重的domain:
Q3: SELECT domain, SUM(item.amount) FROM T2
WHERE domain CONTAINS ’.net’
GROUP BY domain
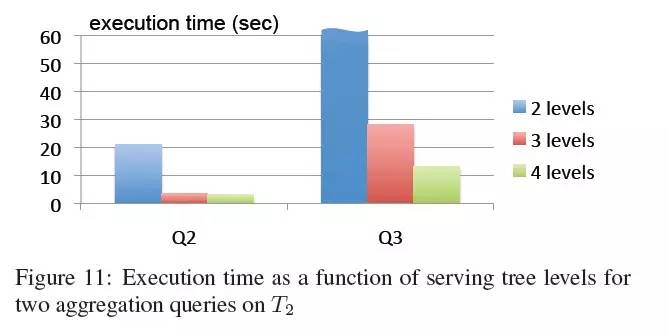
图11展现了两个查询在不同服务器拓扑上的执行耗时。在每个拓扑里,叶子服务器的数量保持在2900,这样我们能假定累积扫描速度是相同的。在2级拓扑(1:2900)中,用一个单一的根节点服务器直接与叶子服务器通讯。在3级拓扑中,比例为1:100:2900,也就是说,根节点和叶子节点之间有100台中间服务器。4级level拓扑是1:10:100:2900.
使用3级拓扑时,查询Q2可以在3秒内完成,增加到4级拓扑时收益就不大了。Q3则不同,从3级到4级耗时减少了一半,因为对于Q3来说4级拓扑可以有效增强它的并行能力。在2级拓扑中,Q3的耗时都超过了图的上限,因为根节点服务器几乎需要顺序的聚合从几千个叶子节点收到的结果(不能并行)。实验证明了当聚合(group by)返回的group越多时(domain有1.1 million条而country只有几百条)多层级服务树的收益就越明显。
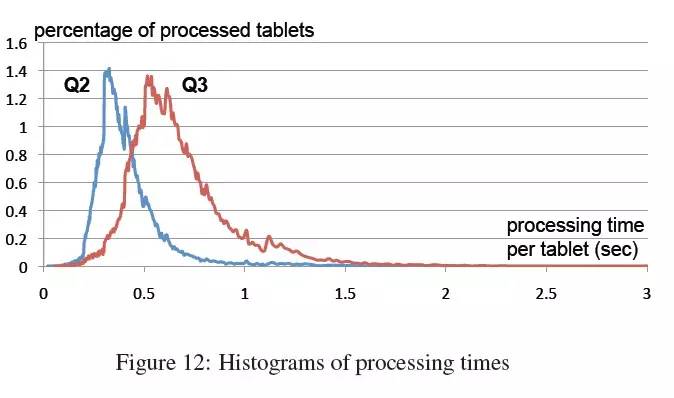
tablet视角的曲线图。为了更深的探寻在查询执行过程中发生了什么,我们统计出了图12。此图展示了叶子节点的服务器执行Q2和Q3时处理tablet的速度。当一个tablet被调度到可用slot上执行时开始计时,也就是说耗时不包括等待任务队列的时间,并且消除了其他并发执行的查询造成的影响。以百分比为值的曲线覆盖的总面积就是100%。如图所示,Q2中99%的tablets在1秒内处理完成,Q3中99%的tablet在2秒内完成。
记录内聚合。这个实验我们将在表T3上执行一个带记录内聚合的查询(Q4):它对a.b.c.d和a.b.p.q.r进行计数分别得到c1和c2,只查询c1大于c2的记录,统计其数量得到最终结果。磁盘中的数据占据70TB,由于column-striping的优势,我们只需读取出13GB,在15秒内就可以完成。没有列状、嵌套等技术的支持,在这样的数据量上运行Q4简直就是噩梦。
Q4 : SELECT COUNT(c1 > c2) FROM
(SELECT SUM(a.b.c.d) WITHIN RECORD AS c1,
SUM(a.b.p.q.r) WITHIN RECORD AS c2
FROM T3)
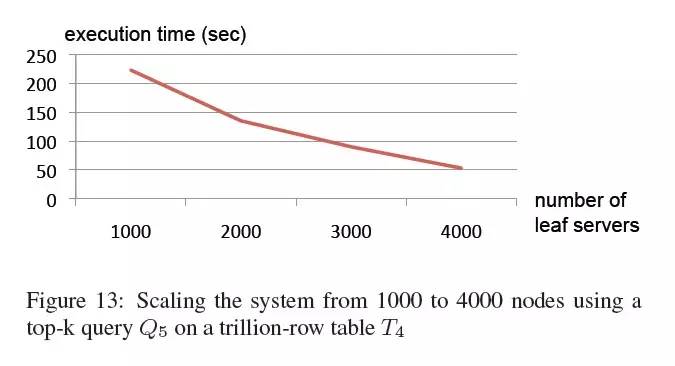
可伸缩性。下面实验证明了Dremel如何在一个万亿级记录的表上实现可伸缩、可扩展。这次执行的查询Q5,将从T4中查询出top-20的aid和它们的计数。查询将扫描4.2TB的压缩数据。
Q5: SELECT TOP(aid, 20), COUNT(*) FROM T4
WHERE bid = fvalue1g AND cid = fvalue2g
我们使用4种配置的系统来执行此查询,节点数量范围从1000扩展到4000。图13显示了执行耗时。在每次运行中,总计CPU消耗时间近似相同,大约300K秒,但用户感知的耗时随着系统节点数量增长而几乎线性的减少。这个结果表明Dremel系统规模增大时并不会降低资源利用率(一般分布式系统规模扩展的越大就会消耗更多的资源在业务处理之外的开销上),而执行过程可以更快。
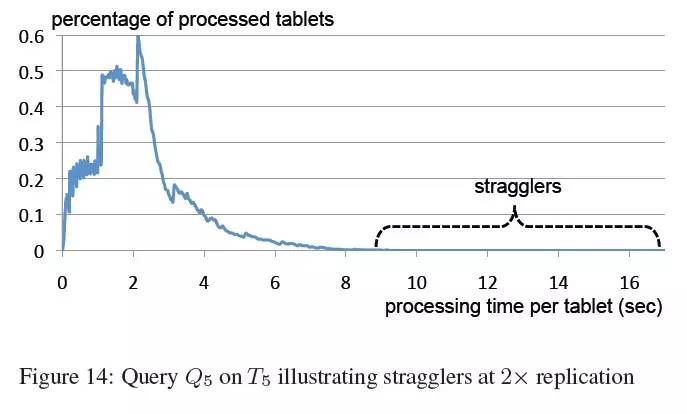
掉队者(Stragglers)。我们最后的实验展示了掉队者的影响。查询Q6将被运行在一个万亿级行数的表T5上。对比其他数据集合,T5只是双向复制的。因此,掉队者减慢执行过程的可能性更高,因为它意味着任务的重新调度。
Q6: SELECT COUNT(DISTINCT a) FROM T5
查询Q6运行在1TB的压缩数据上。待查询字段的压缩比大约是10。如图14所示,每个slot对每个tablet的处理耗时中,99%是低于5秒的。然而,一小部分的tablet花费了非常长的时间,减慢了查询响应时间(从少于一分钟到好几分钟),系统节点规模为2500个。下一章节将对我们的实验结果和教训进行总结。
8. 观察和结论
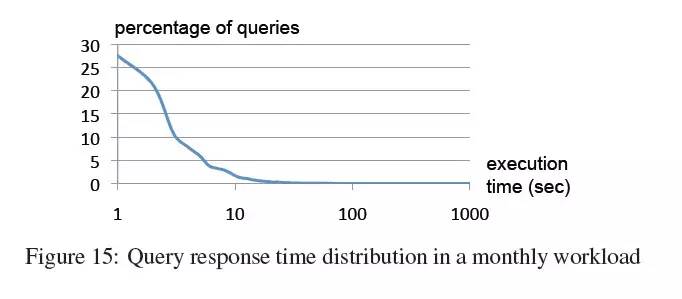
Dremel每个月扫描千之五次方条记录。我们采样了某个月的查询记录,统计出耗时分布曲线。如图15所示,大部分查询低于10秒,在交互型查询的耗时容忍范围内。一些查询会在共享集群上执行接近于100 billion条记录每秒的全量扫描,在专用机器上这个值还要更高。通过对上述实验数据进行观察,我们可以得到如下结论:
我们可以在磁盘常驻的数据集合上对万亿级记录执行基于扫描的查询,并达到交互式速度。
在几千个节点范围内,列数量和服务器数量的可伸缩性、可扩展性是接近线性的。
MR也可以从列状存储中得益,就像一个DBMS。
记录装配和解析是昂贵的。软件层(在查询处理层之上)最好被优化,能够直接消费面向列的数据
MR和查询处理可以互为补充;一个层的输出能作为另一个的输入。
在一个多用户环境,规模较大的系统能得益于高性价比的可伸缩能力,而且本质上改善用户体验。
如果能接受细微的精度损失,查询速度可以更快。
互联网级别的海量数据集合可以做到很快速的扫描,但想要花费更少的时间则很困难。
Dremel的代码库包含少于100K行的C++ Java和 Python 代码
【译者注】后续是“相关工作”和“引用文献”部分,不涉及核心技术内容,这里译者不再赘述了。读者可直接阅读原文。
现任支付宝架构师,负责监控分析域的架构和产品设计。架构时严谨,编码时疯狂。新浪微博:@疯狂编码中的xiaoY
译文链接:http://www.importnew.com/2617.html

