




以前我常说,在 SQL 性能诊断方面,OB 有个大杀器:SQL 审计视图(名字:gv$ob_sql_audit
),能够记录 OB 数据库里跑过的所有 SQL,不管是执行成功还是执行失败或报错。这个视图的字段也随着版本的迭代越来越丰富,通过业务提供的性能问题线索,搜索这个视图(对应 OCP 里租户的 SQL 诊断功能),大概率能定位到业务说的性能慢问题,特别是过去某个时间点慢的问题。
有人说不对,过去的 SQL 可能查不到。说这话的确实是用过的人。
这个视图本质上是内存中的一个队列(FIFO
),其大小跟变量 ob_sql_audit_percentage
(默认值是 3%
)相关,其淘汰算法还有点复杂,通常不用管(但是OBCP会考,以后介绍),只需记得如果 QPS 很高或者租户内存不大的时候,SQL 确实很容易从视图里淘汰掉了。不过 OCP 的Agent 会定时采集这个 SQL。只要租户的内存能维持里面记录保留时间在 3 分钟以上,那大概率能被 OCP 采集到,事后再在 OCP 里分析也行。
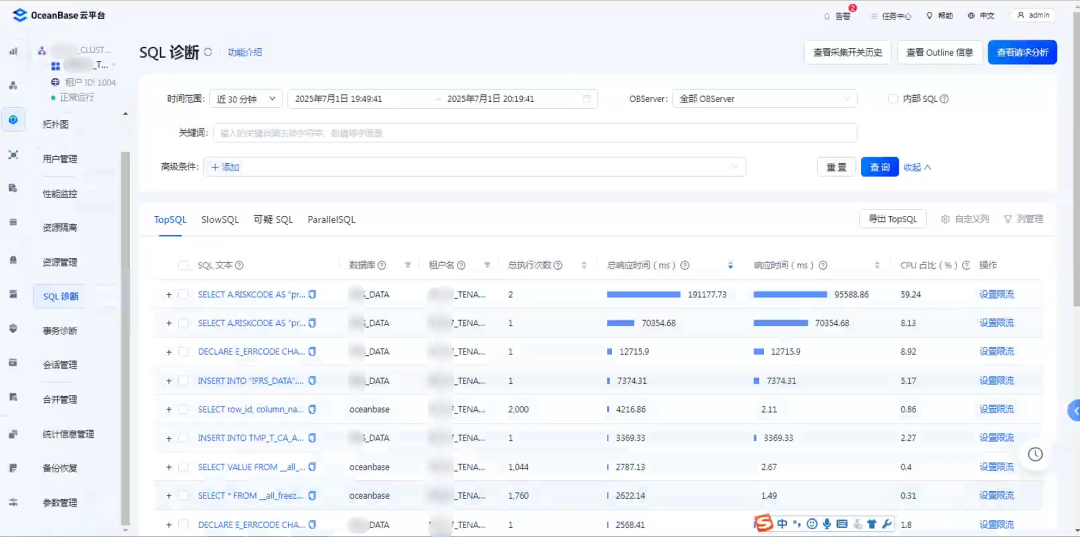
右边的列管理可以显示很多字段,对应的多是视图 gv$ob_sql_audit
的字段。
这个查询输出的结果信息分丰富,再结合对应的 SQL 执行计划,基本上能快速定位到 SQL 慢的原因。
查看租户活跃会话
不过这个诊断方法并不是万能,有一种常见场景用这个方法没有用。
那就是正在运行的慢 SQL 性能分析。如果一个慢 SQL 要运行很长时间,比如说 10 分钟。业务认为正常情况下几秒就应该返回。这种场景下由于 SQL 还没有执行完,它根本就还没有进入视图gv$ob_sql_audit
中。这是 OB 内核的行为。其实它可以先记录 SQL 后更新运行时信息。不过 OB 内核选择只有在 SQL 执行结束了才记录。内核的这个行为我们就不讨论,现实特点如此也只能接受。
客户端慢 SQL 如下:

这个慢 SQL 没有跑完,还不知道要跑多久,因此看 SQL 审计视图就没有用。 此时就需要看活跃会话。
select svr_ip, id, command, time, state, host, USER_CLIENT_IP , sql_id, TRACE_ID ,substr(info ,1,50) info_sql
from GV$OB_PROCESSLIST
where state <>'SLEEP' and info not like '%GV$OB_PROCESSLIST%'
;
输出结果如下:
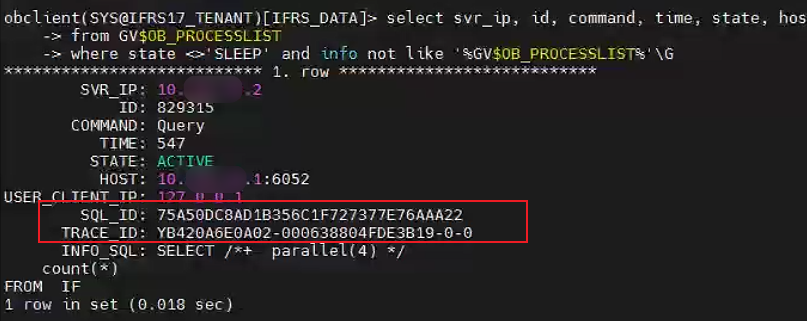
在 OCP 租户的活跃会话管理也有类似查询。
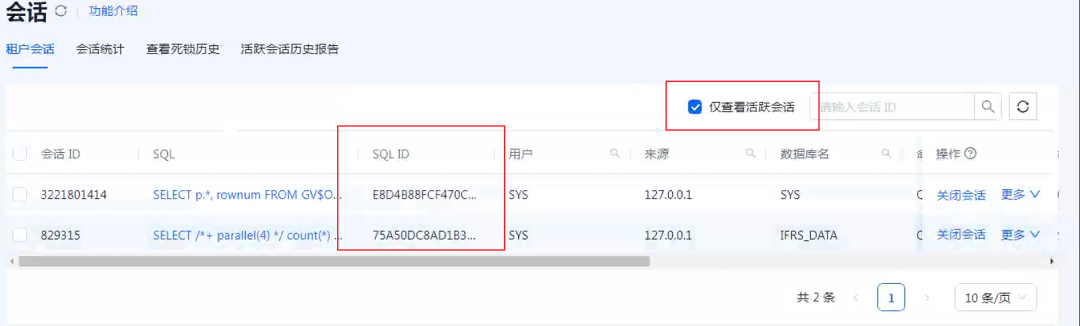
从字段info
的片段可以定位到用户反馈的客户端慢 SQL 所在会话的关键信息:
user_client_ip
:客户端真实 IP,跟用户核实客户端信息。‘svr_ip`:慢 SQL 在运行的 OB 节点,负载落在这个节点上。 host
: 客户端所连接的 ODP IP。sql_id
:这个 SQL 在执行计划缓存中的唯一标识,可以用来查询实际物理执行计划。trace_id
:这个 SQL 有关的 trace 信息标识,既可用于 OB 运行日志里定位相关信息,也可以用于跟踪这个慢 SQL 的执行计划的执行细节信息。
后面这两个 ID 对后面分析很有用。
查看实际执行计划
OB 不同版本查询 SQL 实际执行计划的方法不尽相同,越往后越方便。
先看最早的查询 SQL 实际执行计划的方法。根据 SQL_ID 找到执行计划的统计信息。
select tenant_id, svr_ip, type, db_id, query_sql, PLAN_HASH , FIRST_LOAD_TIME , LAST_ACTIVE_TIME , avg_exe_usec, EXECUTIONS , SLOWEST_EXE_USEC , SLOWEST_EXE_TIME , SLOW_COUNT , OUTLINE_DATA , HINTS_INFO , PLAN_STATUS
from GV$OB_PLAN_CACHE_PLAN_STAT
where sql_id='79C8E9AE9F921F844075D44A0B3009DF'
;
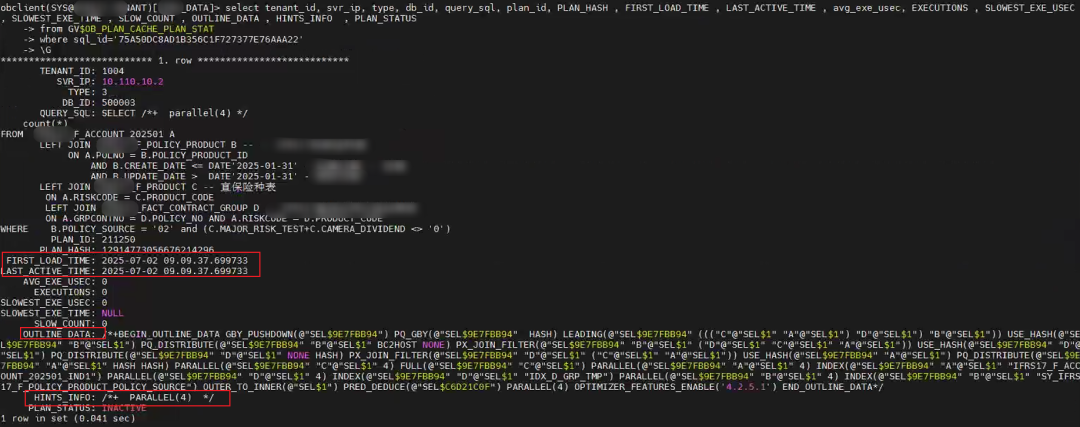
从这个记录里可以确认:
FIRST_LOAD_TIME
:这笔执行计划首次解析时间LAST_ACTIVE_TIME
:这笔执行计划最后一次运行时间,跟前面一样,说明这个 SQL 只运行一次。EXECUTIONS
:这笔执行计划的执行次数,为 0 估计就是 SQL 还没有执行成功结束。query_sql
:生成执行计划时的用户 SQL 。
上面这几个信息可以再次跟用户反馈的信息(时间点)对应上。我们需要的是里面的svr_ip
和plan_id
信息,这两个用于后面定位实际执行计划用。
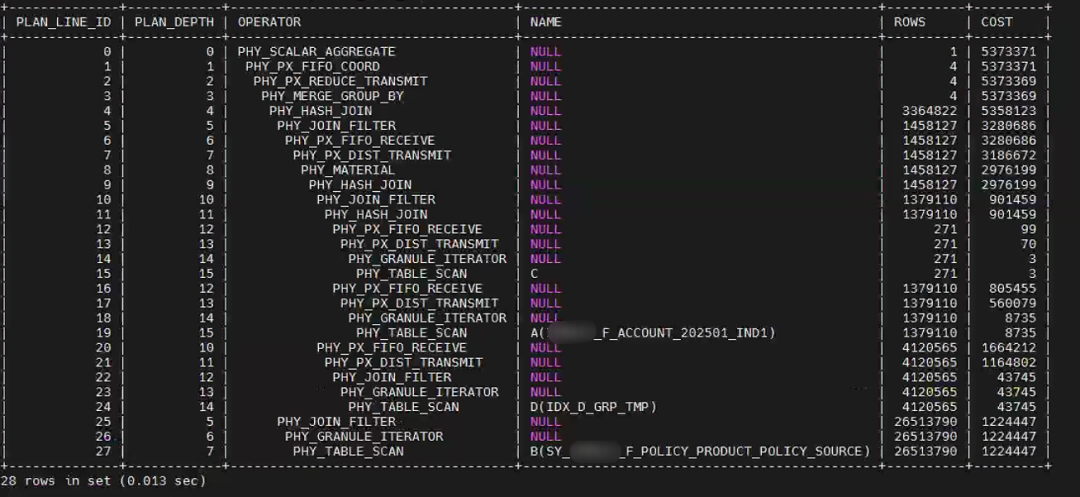
select PLAN_LINE_ID , PLAN_DEPTH ,OPERATOR ,NAME , "ROWS", "COST", "PROPERTY"
from GV$OB_PLAN_CACHE_PLAN_EXPLAIN
where (tenant_id, svr_ip, svr_port, plan_id) = (1004, '10.110.10.2', 2882, 211250)
order by PLAN_LINE_ID ;
输出如下图(为了展示方便,我去掉了 property
字段内容,实际上这个字段包含了每一步执行计划算子细节内容。
最近版本的 OB 查看实际执行计划支持多个函数直接获取。
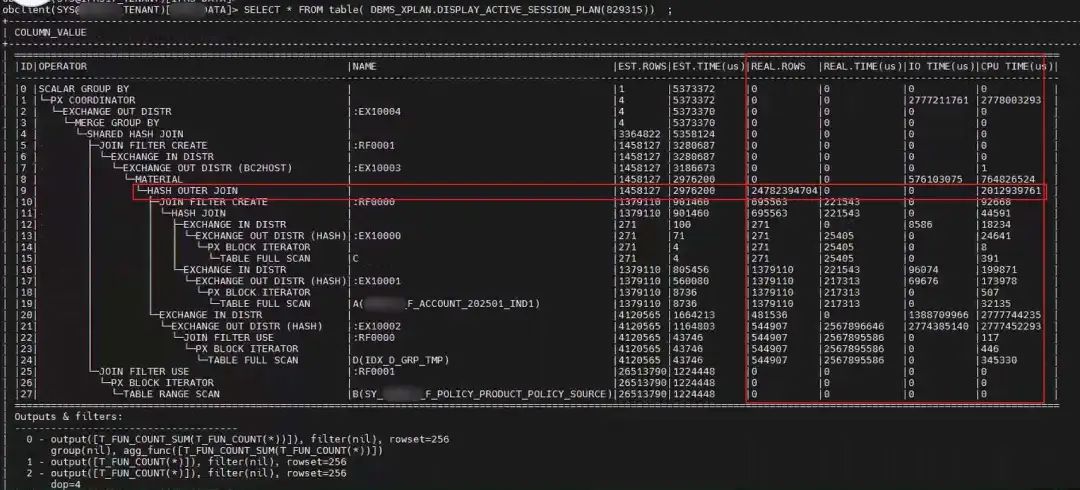
方法一是根据会话 ID 获取 SQL 实际执行计划:
SELECT * FROM table( DBMS_XPLAN.DISPLAY_ACTIVE_SESSION_PLAN(829315)) ;
方法二是根据执行计划的plan_id
查看。
SELECT * FROM TABLE (DBMS_XPLAN.DISPLAY_CURSOR(211250)) ;
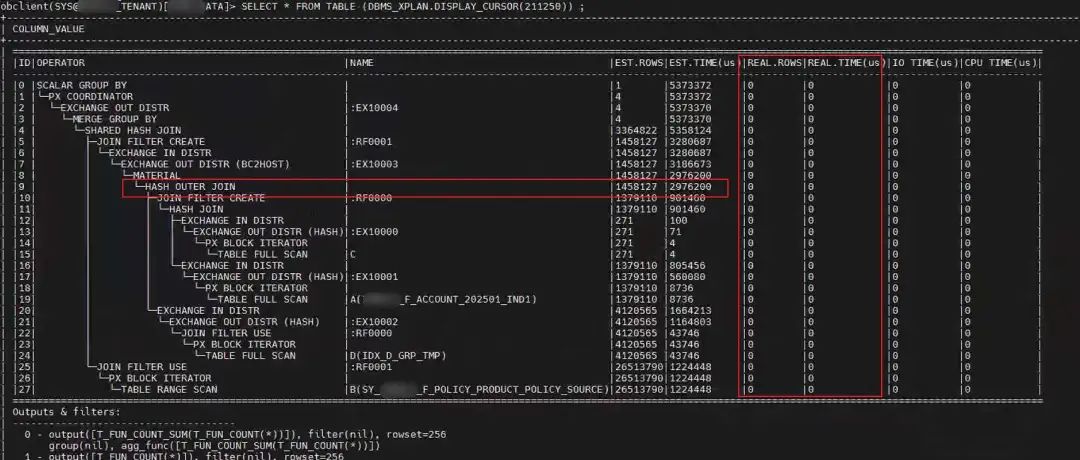
这两个方法都属于包 DBMS_XPLAN的功能,每个函数还有更多详细的参数,参数的细节可以查看官方文档。这体现了 OB SQL 引擎在执行计划方面的功能越来越丰富和完善,或者说越来越强大(这也是为什么我认为 OB 是能媲美 ORACLE/DB2 的数据库的一个原因)。
当然如果你仔细比对这两个执行计划的图还是能看到一些细节。第二个图里还看不到执行计划每步算子的实际输出行数,而第一幅里能看出。如果你眼光足够敏锐,你就能看到第一个执行计划的第9步里输出行数是:24782394704
行。这是 200亿的输出。这个执行计划肯定有性能问题。难怪用户会反馈它很慢。
慢 SQL 的问题
用户反馈的原始业务 SQL 实际上比我这里写的 SQL 更复杂,SELECT 里有大量的字段,前面还有个 INSERT INTO XXX 。这个 SELECT 是跟在 INSERT 后面的子语句。实际执行计划的输出信息更多,包括下面的 Output & Filters 信息。 分析这样复杂的 SQL 的执行计划需要几十分钟,并且保持高度专注不被打搅。这工作只有干过的 DBA 才能体会。
果然用户客户的查询 SQL 最终还是报错了。

这里报的是临时空间达到限制了。这个是集群参数 temporary_file_max_disk_size
控制。
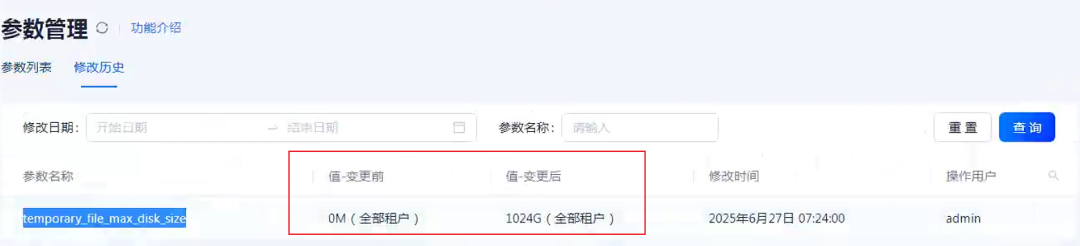
最早客户跑原始 SQL 的时候实际上时间更久,最后导致 OB 数据文件空间耗尽。 这个客户 OB 的数据文件大小设置我一般是设置一个初始化大小(1TB),以及递增大小(1GB),还有最大大小(10TB)。当这个问题出现后,出问题的这个节点的数据文件直接撑到 10TB,而其他两个节点还只有 1TB 大小。 在 OB 的运行日志里也找到了数据文件空间耗尽的提示。
2025-06-25 03:08:32.044939|ERROR|USING_LOG_PREFIX|OB_SHARE_OUTOF_DISK_SPACE|-4184|1004|682616|T1004_PX_G0|YB420A6E0A02-00063258EC06F9A5-0-0|check_space_full|ob_local_device.cpp:1424|"disk is almost full. resuired size is 2097152 and used percent is 90%. [suggestion] Increase the datafile_size or datafile_disk_percentage parameter. "
这就是为什么我在以前的 OB 部署文章里说数据文件大小不建议用那个参数“datafile_disk_percentage” ,这个参数默认一下子就把磁盘文件系统空间占用了,然后面对这种问题你就很难从外部文件系统里看出数据文件内部空间暴涨过。
空间问题不是本文的主题,这里只是说这个慢 SQL 的影响导致数据空间耗尽过,所以我立即设置了参数temporary_file_max_disk_size
限制临时文件大小为 1TB 。避免以后再出现这种问题。
慢 SQL 的问题和优化
问题现象和初步原因定位到了,接下来就是解决。
优化 SQL 首先从业务需求开始。
首先即使不知道业务需求,通过 WHERE 条件也能一眼看出这里面的 LEFT JOIN 用错了,实际效果等于 JOIN 。既然如此,就要用 JOIN 。 该用 JOIN 的时候用了 LEFT JOIN,OB SQL 引擎有可能会生成别的执行计划。
同时再跟业务确认用 LEFT JOIN 的理由是什么。大部分业务开发说不出为什么,只是觉得别人就是这么写的。这个问题很常见,每次给客户培训我会解释。
于是改变 SQL 看一下解析执行计划。
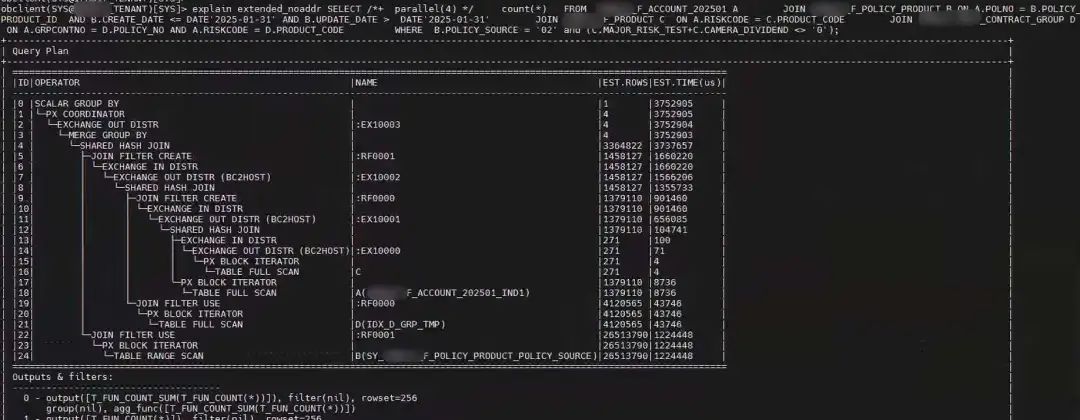
看这个执行计划,有人会说好像跟前面实际执行计划没有多大区别。
是的,初步看表的执行计划算法和顺序确实没有变化。但这并不是说 LEFT JOIN 就不该改为 JOIN。LEFT JOIN 是 SQL 实现业务需求时写法错误问题,SQL 优化的前提是 SQL 先写对。错误的 SQL 让人优化是耽误时间。
再在客户端运行改进后的 SQL,通过会话 ID 查看实际执行计划。
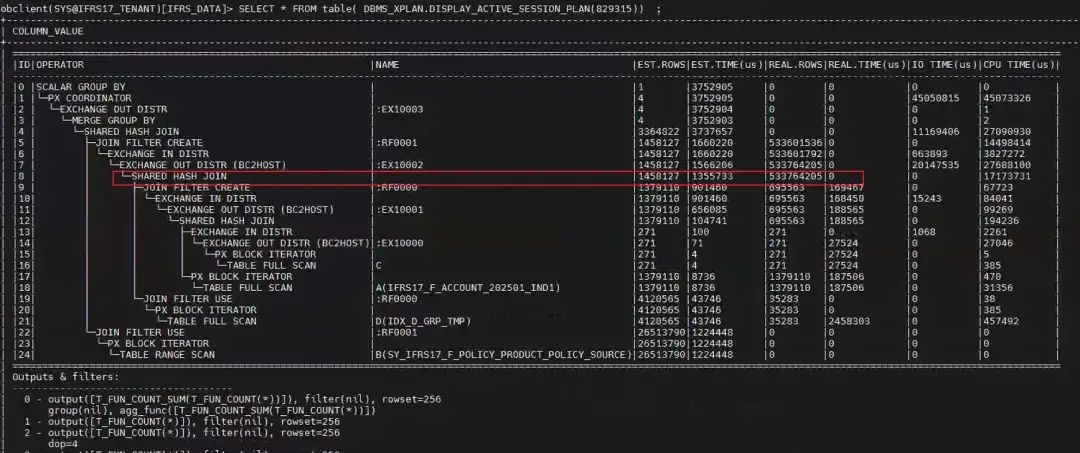
这时候可以看到第 8 行的实际输出行数预估在 533764205(5个亿),比之前小很多了。这次应该不会报临时空间问题(后面会被打脸)。不过还是很慢,还要进一步优化。
但是在命令行下分析这个复杂的执行计划实在太费精力。好在新版本的 ODC 提供了“SQL执行画像”功能,可以图形化展示这个执行计划的细节信息。需要在 ODC 里运行这个 SQL ,即使 SQL 执行中没有返回,也能查看执行画像信息。
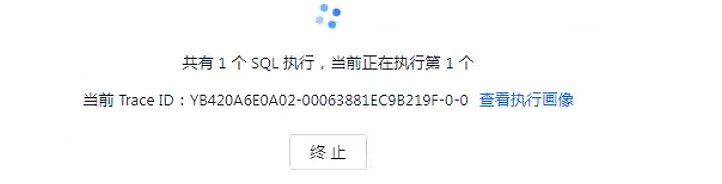
点开 SQL 执行画像,可以看到执行计划的图形化细节图。这个图会实时刷新。 运行一段时间后可以看到最耗时的步骤。
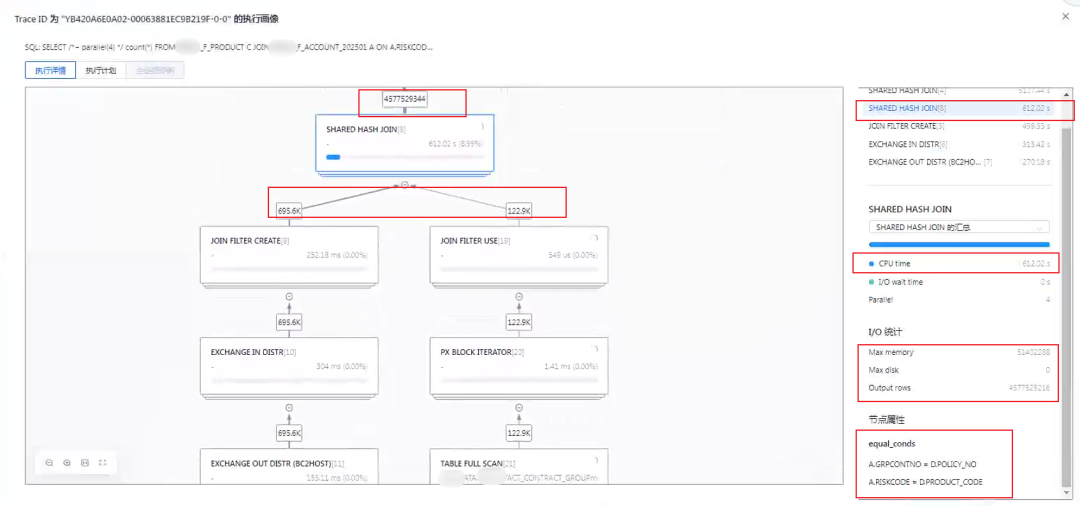
如图中这个 SHARED HASH JOIN 最好时,它的两个输入的结果集分别是 695.6K 和 112.9K ,但是输出却高达 40多亿,且还在增长。
看来前面解析执行计划估算的也不是很准。解析执行计划跟实际执行计划里表 HASH JOIN 的顺序不一样。 目前这个情形执行下去,还是很可能导致临时表空间膨胀突破限制进而报错。这个算子也是有性能问题的。
所以,终止这个查询,继续优化 SQL。这个时候就要从业务逻辑角度去优化了。
首先查看了一下这 4 个表的统计信息。
SELECT owner, table_name, partition_name, partition_position, object_type, num_rows, blocks, avg_row_len, scan_rate, sample_size, last_analyzed, global_stats, user_stats
FROM DBA_TAB_STATISTICS
WHERE owner IN ('IFRS_DATA')
AND table_name IN ('*****_FACT_CONTRACT_GROUP','*****_F_PRODUCT', '*****_F_POLICY_PRODUCT','*****_F_ACCOUNT_202501');

这个小表 C 的记录很准,273 条。大表的记录数是采样估计的,数据规模是准的,数据量绝对值误差 50% 左右。统计信息这个以后再专门研究。至少大小表关系能看出来。当然严格来说,HASH JOIN 不是看表的大小,而是看结果集大小,即表被过滤后的记录数。这里 A 表和 D 表的结果集直接进行 HASH JOIN ,肯定是不合适的。
第二步优化就是调整 FROM 后的表顺序,用 HINT /*+ ordered */ 指定表的 JOIN 顺序。
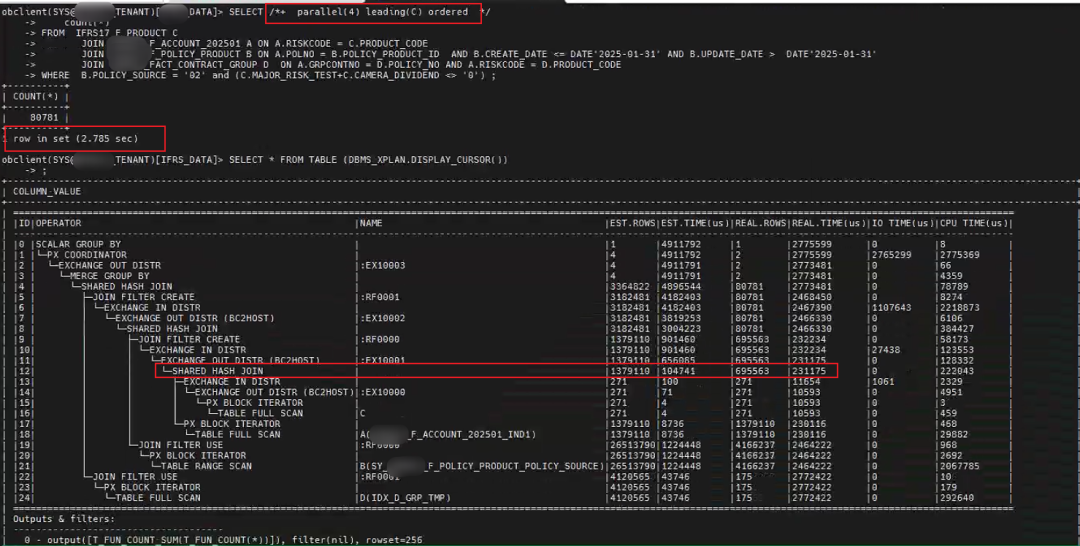
可以看出,执行性能很快,3秒不到就出结果了。 从实际执行计划细节里也能看出原因。关键的那个 SHARED HASH JOIN 输出行数一直很正常,不会翻倍。
细心的朋友肯定看到了,这个时候我用 DBMS_XPLAN.DISPLAY_CURSOR 方法又能输出算子的实际行数。为什么前面不行这里可以呢,只有内核研发同学自己知道了。 还有,为什么我这里不展示 ODC 的 SQL 执行画像了呢?因为 SQL 执行的太快结束了,本来跑完的 SQL 也可以看执行画像,但是这个新版本估计还是测试不充分啊。

OB 的新功能就是这样,很好用,但是可能有 BUG 。好在影响不大,却非常实用,还能接受!不容易~~~
SQL 执行画像原理
上面 ODC 打开执行画像入口报错提示:参数 trace id
值不能为空。这恰好提示了 SQL 执行画像的获取原理,就是跟 trace id 去查视图 GV$SQL_PLAN_MONITOR
的。这个 trace id
就是前面从活跃会话里查询出来的。
select con_Id tenant_id, request_id, key, status, svr_ip, FIRST_REFRESH_TIME , LAST_REFRESH_TIME , FIRST_CHANGE_TIME , LAST_CHANGE_TIME , REFRESH_COUNT ,PROCESS_NAME ,SQL_EXEC_START, SQL_CHILD_ADDRESS ,PLAN_PARENT_ID ,PLAN_LINE_ID , plan_depth, PLAN_OPERATION , PLAN_OBJECT_OWNER , PLAN_OBJECT_NAME ,PLAN_OBJECT_TYPE ,
PLAN_IO_COST , PLAN_CPU_COST , db_time, USER_IO_WAIT_TIME ,OTHER_WAIT_TIME , PLAN_TEMP_SPACE ,starts, OUTPUT_ROWS , SKIPPED_ROWS_COUNT , WORKAREA_MEM , WORKAREA_MAX_MEM ,WORKAREA_TEMPSEG ,WORKAREA_MAX_TEMPSEG
from GV$SQL_PLAN_MONITOR
where TRACE_ID ='YB420A6E0A02-000638804FDAD1B3-0-0'
order by con_id, PLAN_LINE_ID ;
这个视图的记录很多,有兴趣的可以研究官方文档。
总结
最后总结一下本文的要点:
大表的统计信息默认是按比例估算的,跟实际数据量可能有很大出入。 复杂 SQL 的解析执行计划跟实际执行计划很可能有出入,特别是有线索表示 SQL 执行很慢的时候。 OB 里多表 JOIN 提升性能常用技巧用并行,可以用 HINT 指定,也可以用默认自动并行。为了避免偏题,本文没有展开这个。以后再说了。 OB 里多表 JOIN 时有大表参与的时候,执行计划里表的 JOIN 顺序非常重要。顺序不一样,性能可能天差地别。 OB 集群的临时文件空间大小默认可能是没有限制的,碰到大表慢 SQL 有可能出现临时空间将数据文件内部空间用尽的问题。当然 SQL 报错后,临时空间会释放返还。但是数据文件的肚子已经被撑大了。要缩容也可以,稍微麻烦一点(见参考文章)。 ODC 的 SQL 执行画像功能非常实用,对于 ODC 里跑过的 SQL 都能展示。但是对于其他场合跑的 SQL,就看 OCP 以后会不会在 SQL 诊断里加上这个功能。 OB 以及相关产品新功能很实用(很吸引人),不过大小问题多少还是会有的。谨慎升级。
