




文:3201字 阅读:10分钟
村长脑袋好使,凭自己是村里信息的入口,开了一个小卖部,就像《乡村爱情》中的大脚超市一样,茶余饭后,张家长李家短的事儿,也多半是从这里传开。
小卖部虽然不大,从小刀铅笔田字格到火腿果冻拆盲盒,应有尽有,而平时村里人也好赊个账啥的,都是攒到一定时候一起结。
说数据库的索引,那就要从村长的这个记账本开始,这本账记录了所有人的赊欠和还款记录。因为每天都要登记新的记录,所以需要快速定位到每个人,然后写上新的还钱或是赊欠记录,而为了方便查找,村长还编了目录,索引就是这个作用。用村长媳妇的话说,没多少钱,小账本天天算。
索引的实现方式有很多,常见有三种数据模型:哈希表、有序数组和搜索树。我们从浅入深慢慢说说。
 哈希表
哈希表最开始,每个人的赊欠记录就是按时间顺序来记,格式就像我们的数组。
如果我们想找到大美的记录,那就需要从下标为0的位置开始查找,直至找到为止,数组越大,那所需要消耗的时间就越长,复杂度为O(n).

那为解决这个问题,我们可以将人名作为键,快速定位数据,这就产生了哈希表,哈希表也叫散列表,是根据关键码值(key->value) 存储数据的数据结构,可以通过关键码值映射到表中的一个位置来访问记录,这个映射方法叫散列函数,存放记录的数组叫散列表。
而根据设定的哈希函数和处理冲突的方法进行映射的算法的就叫哈希算法,以前的文章也和大家提到过,常见的hash算法分为MD4、MD5、SHA-1,为了好记忆可以直接缩为”妈的傻“。
将单词转化为大数的过程的哈希化,就像下图宝子哈希化之后是205,然后再采用取余的方法,计算出数组中的位置。
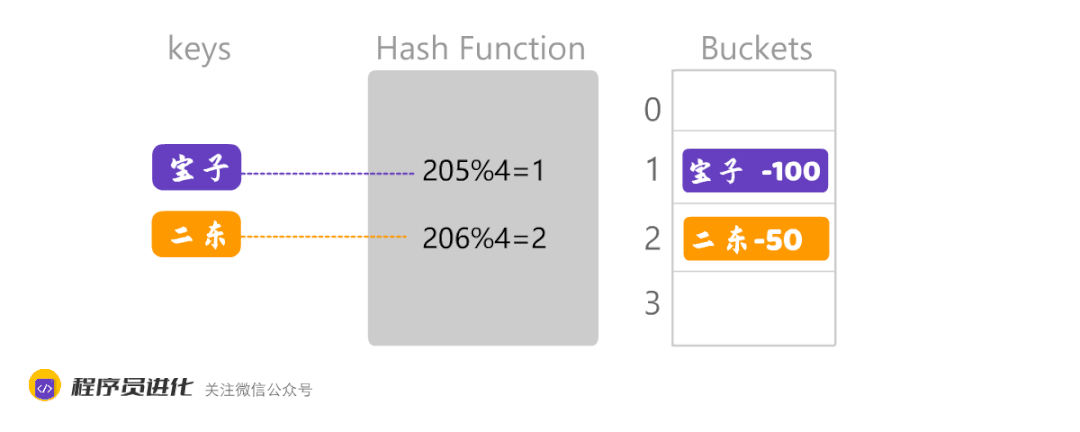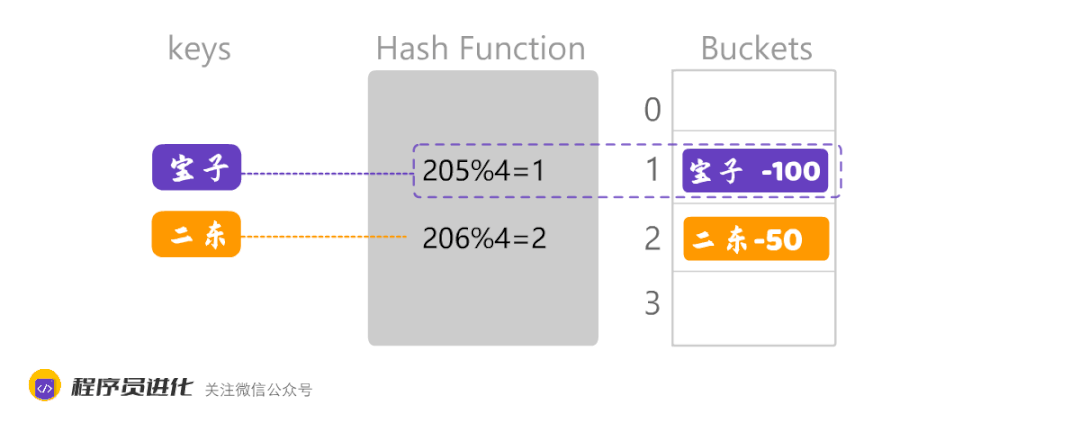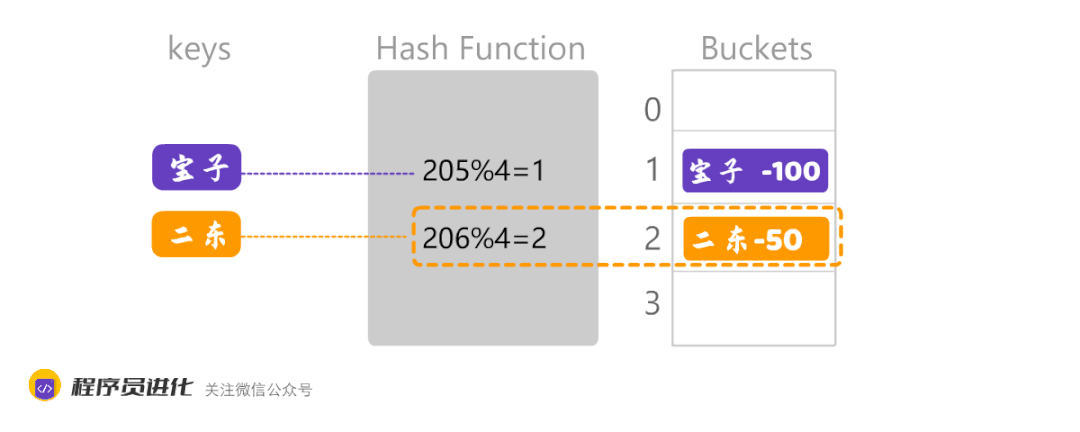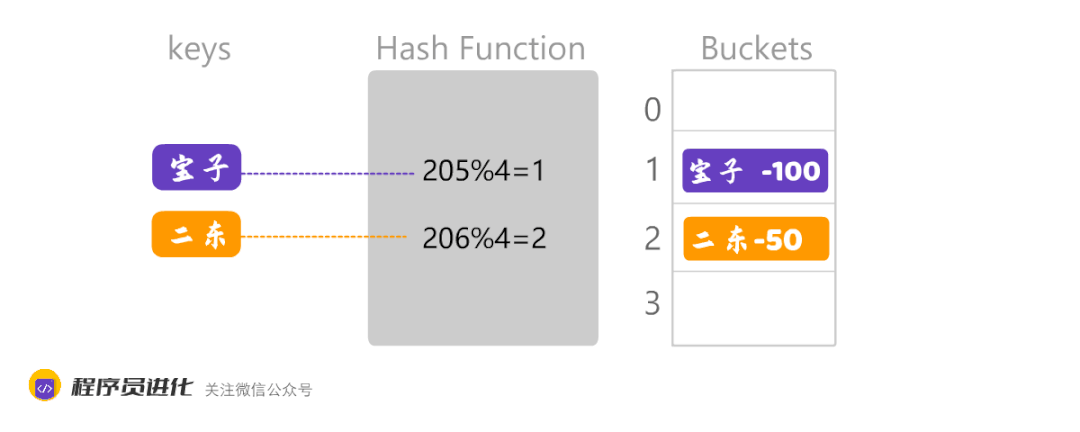
数组越大,数据的分散度就越好。数组越小,就可能出现数据集中,另外,不同的Key经过哈希化后,计算出相同的数组位置,这就会产生了哈希冲突。如下图:
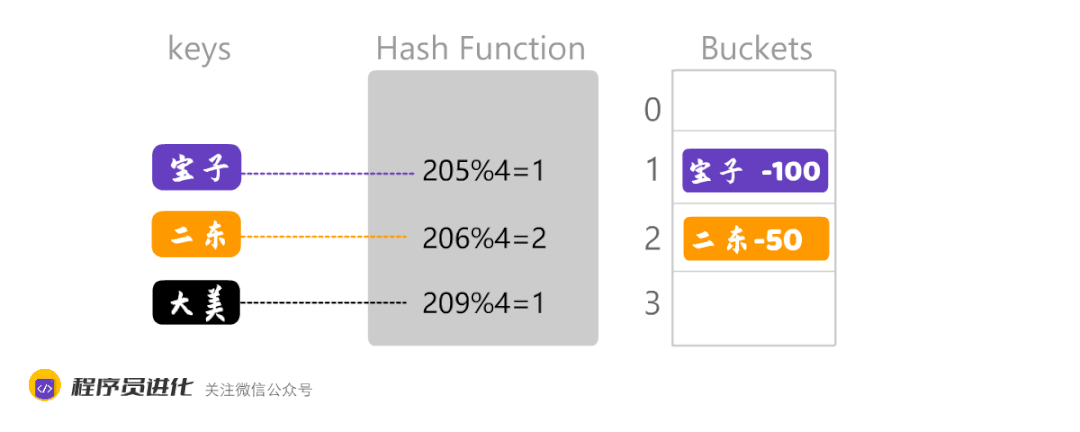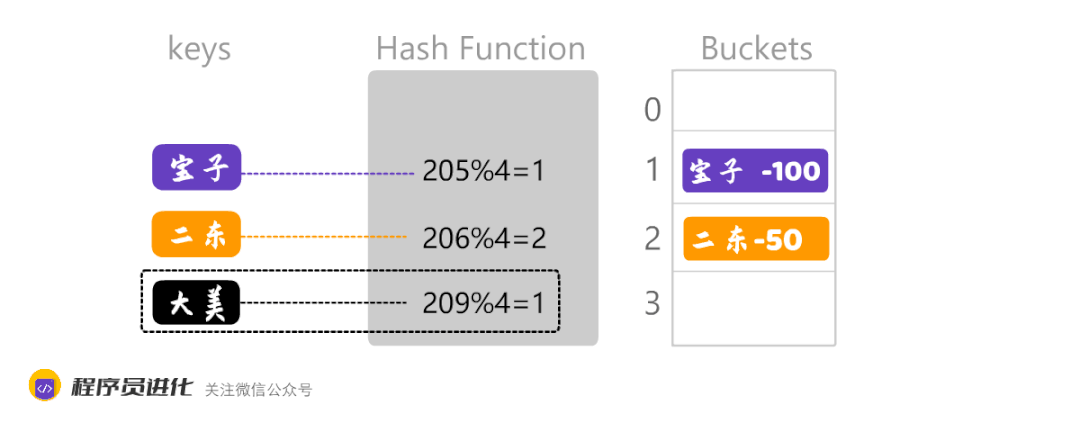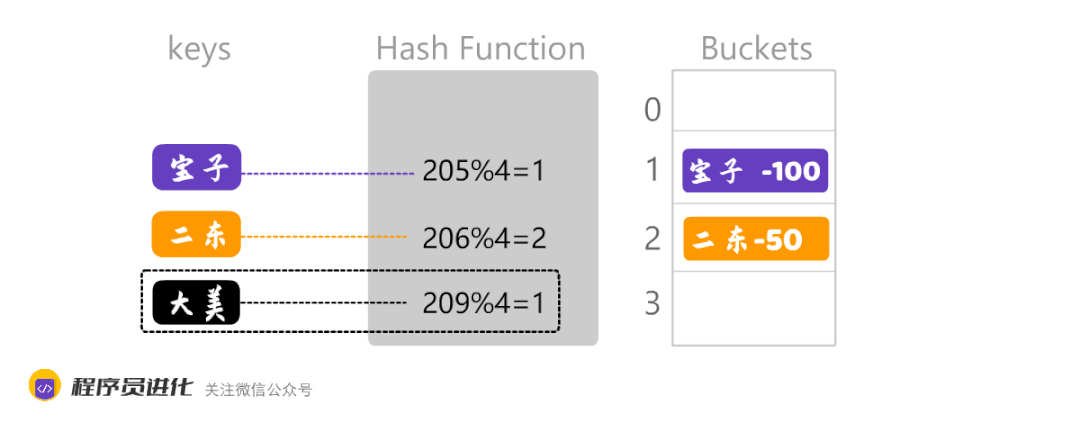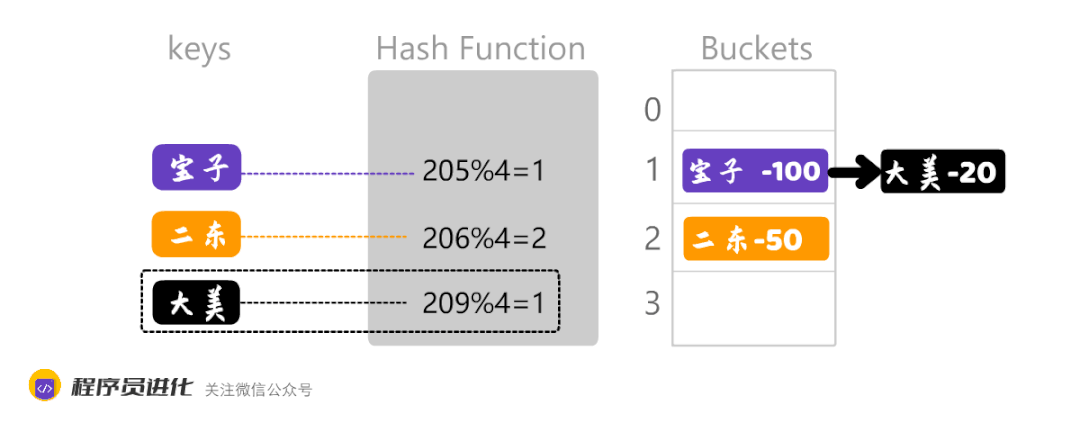
大美和宝子计算出来的数组下标都是1 ,通常处理这种情况有两种方法:一个是开放地址法,另外一个是链地址法。
开放地址法,就是在下标为1的后面,即2存入数据,而链地址法,就是在下标为1的位置生成一个链表,相同哈希值的数据以链表方式存储。
这种方案插入数据仍旧很快,只要在链表后面继续增加数据就可以,缺点因为不是有序的,查询的速度会很慢
当然,你会发现,这有一个很大的漏洞,就是利用哈希冲突,可以让后面的链表越来越长。进而让查询时间非常漫长。所以好的哈希表要有以几个特征:
1. 哈希函数输出比较均匀
2. 有合适的哈希冲突解决方法
3. 性能稳定 ,不能退化的太严重
4. 内存占用合理,可能快速时间插入、删除和查询
哈希表可以在O(1)的时间复杂度下实现数据插入和删除和查找 ,所以哈希表更适合等值查询 ,但是当村长要查询欠100元以上的人时。哈希表就不适合了。

有序数组
有序数组顾名思义,就是一段按一定顺序排列的数组,如:
【1,2,3,4,5,6,7,8】
有序数组非常适合查询,可以使用二分查找。
村长的小卖部举办猜价格活动,村长拿出了一瓶82年的老村长,标价78元。看谁能用最少的次数猜对。
二老懒是村里出了名的懒人,从1元的价格开始猜,一共猜了78次。
而聪明的大美先是喊出50元,然后问村长是高了低了。
”低了“,村长答到
”75元“
”低了“,村长再次回答
”85元“,
”高了“
" 80元”
“高了”
“77元”
“低了”
“79元”
“高了”
“78元”,这次对了。
大美用7次就答对了,这就是二分查找法的生活实例。
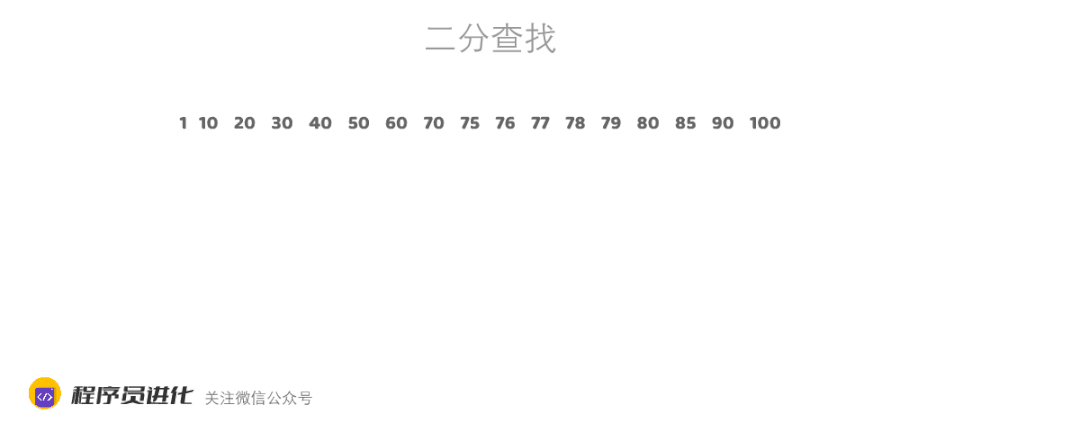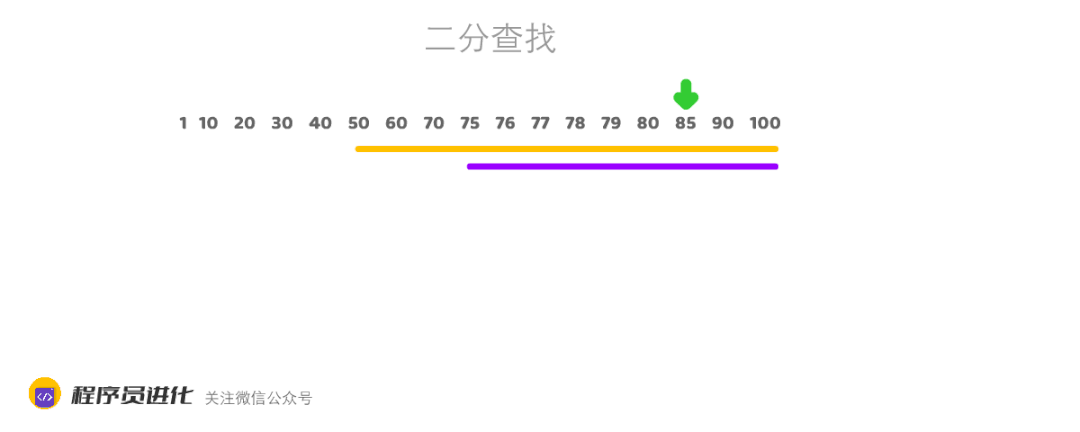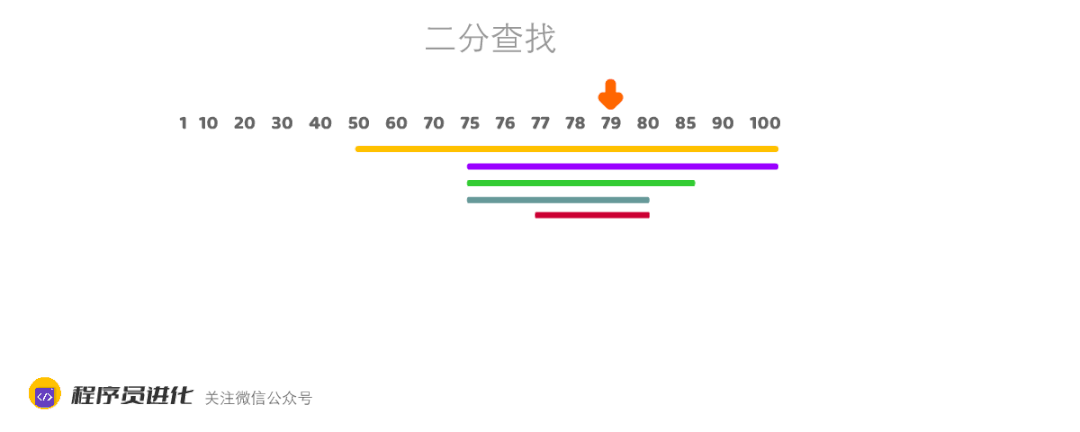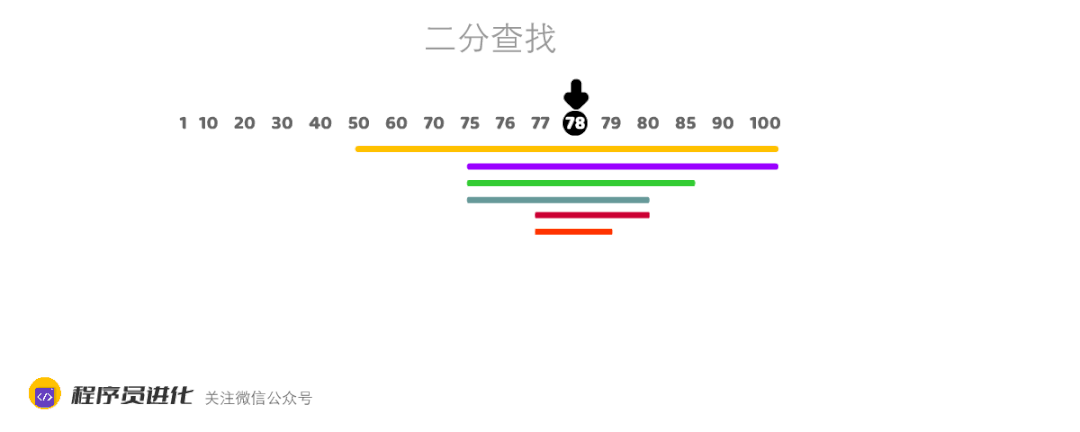
二分查找非常适合有序数组,可实现O(logN)时间复杂度,O(logN)小于O(N). (log代表对数,2的3次方=8,所以log8 =3, 所以在时间复杂度上O(logN) < O(N) )
有序数组优点是查询效率很高,但缺点也很明显,当需要在中间插入新记录时,后面的所有记录都要挪动,成本太高,所以有序数组比较适合静态存储数据,比如人口的身份证信息。

树结构
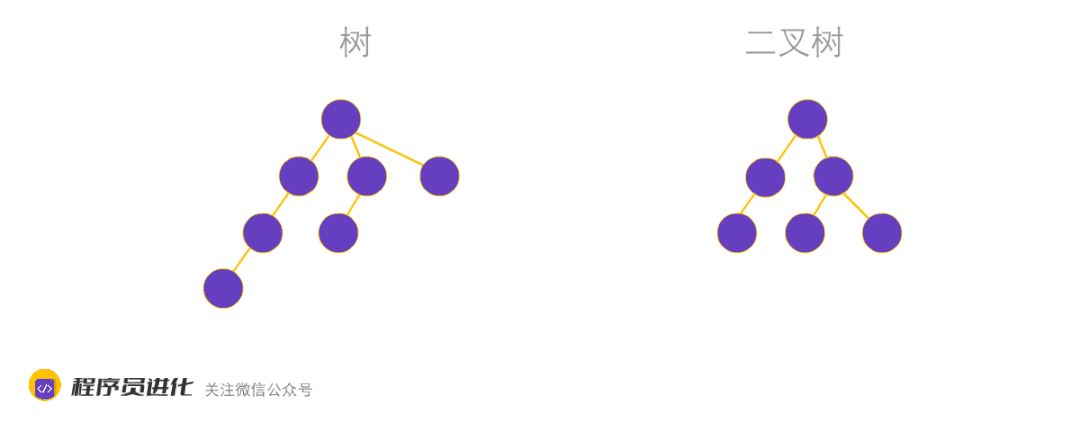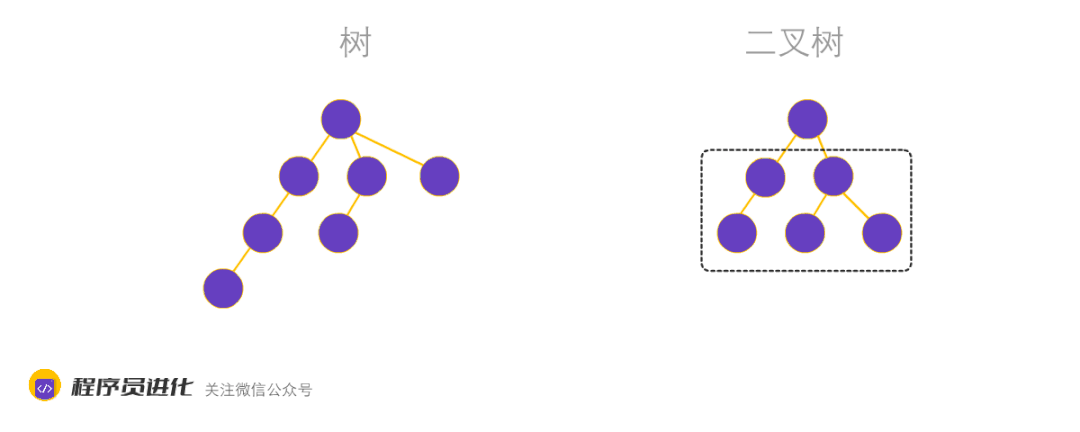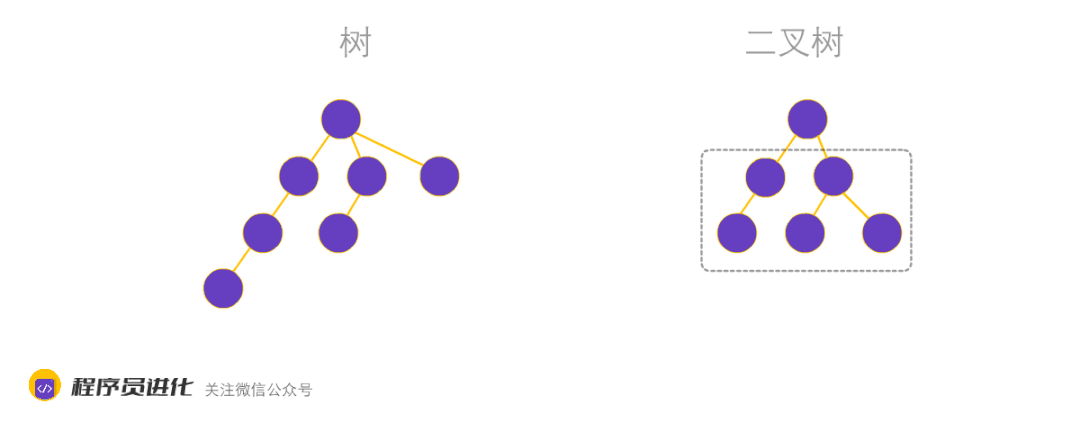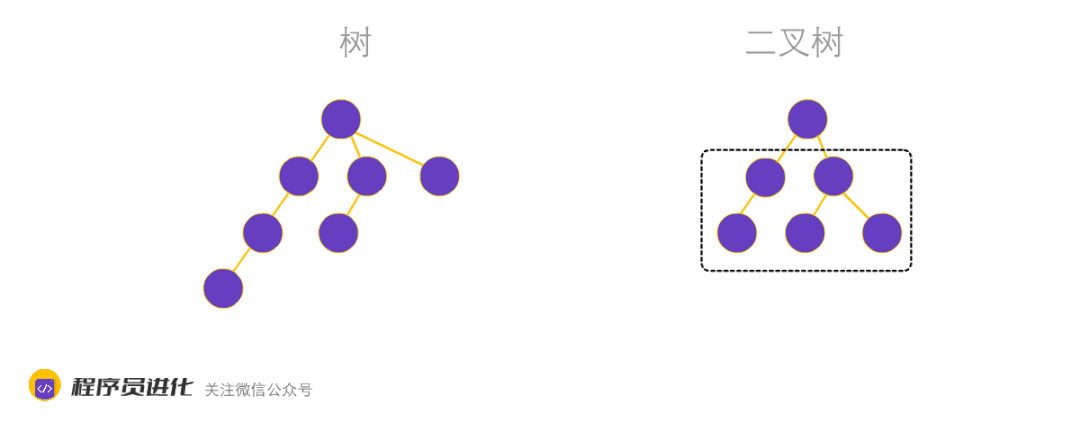
树也是一种常用的数据结构,是由N个(n>1)有限节点组成的,具有上下层关系的集合。树只有一个根节点,并且每个节点都有并且仅有一个父节点,节点间不能形成闭环,
树分为N树和B树,N树就是一个子节点最多拥有N个子节点的树。而二叉树是N树中的一种,是指一个子节点最多拥有两个子节点。
N树与二叉树最大的区别就是子节点所允许的数量不同,数量不同带来的另一层差异就是树的高度不同。
二叉树又分为平衡二叉树、完全二叉树和满二叉树
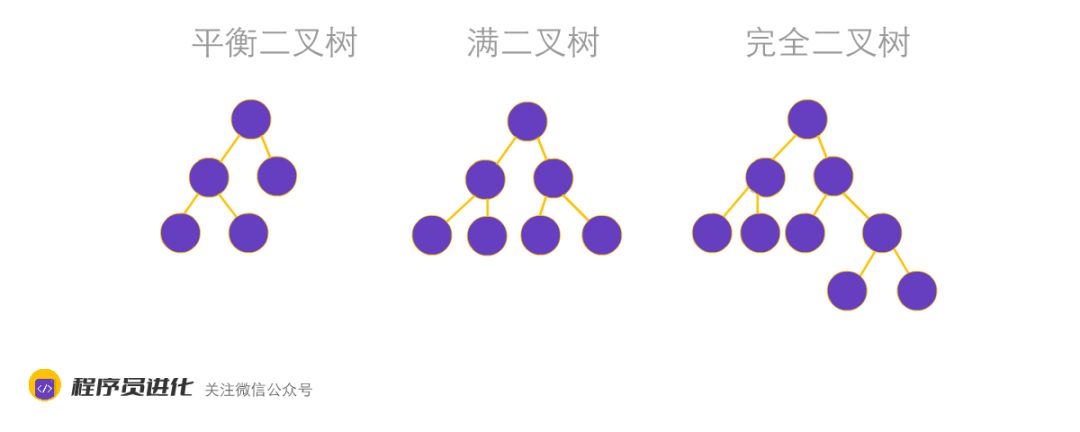
平衡二叉树就是保证树不太倾斜,左右平衡,所以要求左右子树的高度差不能大于1。
满二叉树除了叶子结点,结点的度要么为0(叶子结点),要么为2(非叶子结点),每一层包含最后一层都被填满,并且所有结点都保持向左对齐。
满二叉树的节点计算公式为:高度为h,节点数 = 2^h–1
完全二叉树:一棵二叉树中,只有最下面两层结点的度可以小于2,并且最下一层的叶结点集中在靠左的若干位置上。这样的二叉树称为完全二叉树。
一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。
二叉树的搜索效率高,为什么数据库却不使用二叉树呢,主要原因索引不止存在于内存中,还要从磁盘加载到内存,这就涉及到磁盘寻址加载次数,而且磁盘数据加载到内存,是以页为单位 ,我们知道节点和节点之间的数据是不连续的,所以节点不同,数据就可能分布在不同的磁盘页上。
另外相同量的节点,二叉树的层数可能更高,层高越大,读取磁盘数据消耗的时间就越长。
所以基于这样的问题,我们就要继续对数据结构优化和迭代,产生了B树和B+树。

B树和B+树
B树是专门为了解决磁盘存储而设计的多叉平衡搜索树,也叫B-树(这里-只是连接符,不读B减树哦)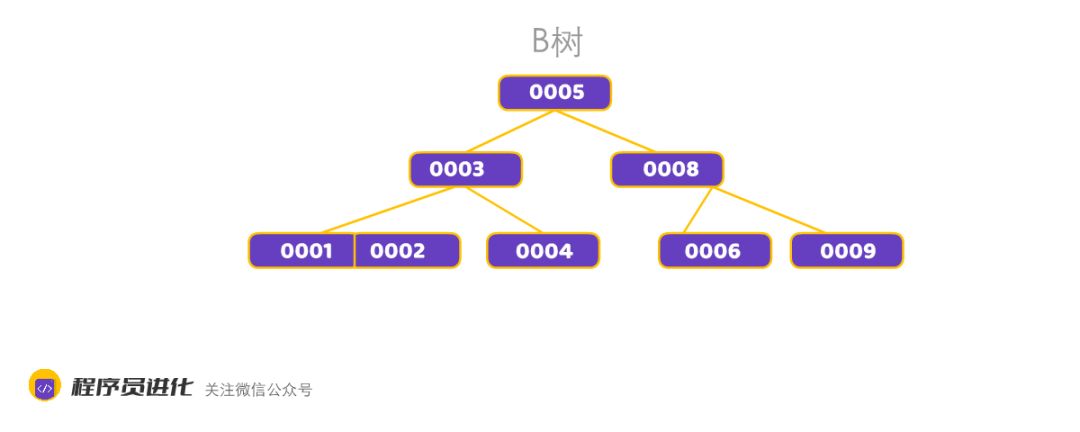
这颗B树是不是很熟悉,比如我们想找0002,那我先从根节点开始,发现小于5,那就找左子树,然后发现小于0003,那再找0003的左子树。这与和我们刚才猜价格的二分查询非常相似。其实B 树是一个查找二叉树,他都是越靠前的子树越小,并且,同一个节点内,关键字按照大小排序;
B树中的B代表balance,平横的意思,所以,B树也是一颗平衡树,平衡树可以让每个节点向上查找都是相同的层级,另外采用多叉其实为了降低树的高度, 提高查找效率。B树结构可能让查找、插入和删除都在O(logN)内完成。
一颗B树有以下特征:
1、根结点至少有两个子女;
2、每个非根节点所包含的关键字个数 j 满足:⌈m/2⌉ - 1 <= j <= m - 1.(⌈⌉表示向上取整) ,例如5阶B树,每个节点至少有3个子树。
3、有k个关键字(关键字按递增次序排列)的非叶结点恰好有k+1个孩子。
4、所有的叶子结点都位于同一层。
B+树,你可以理解成B-的PLUS版,性能更快
B+树特征:
1、每个结点至多有m个子女;
2、非根节点关键值个数范围:⌈m/2<= k <= m-1⌉
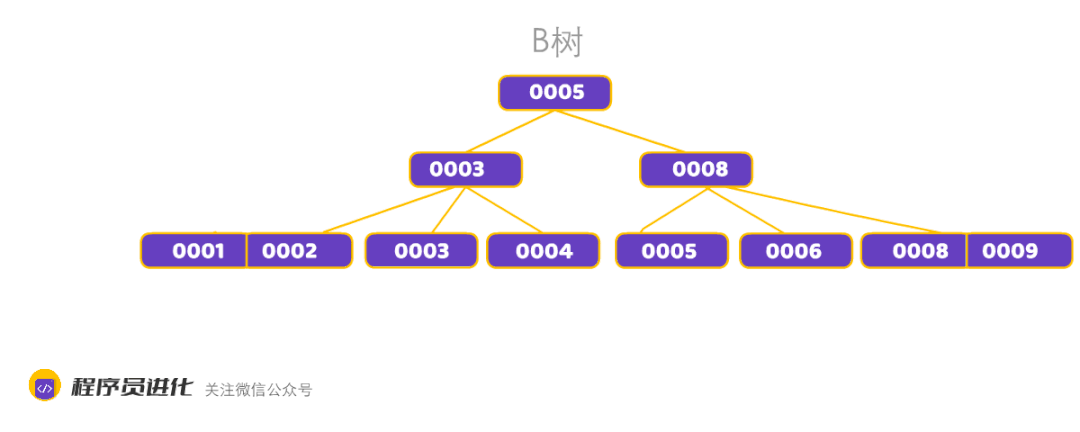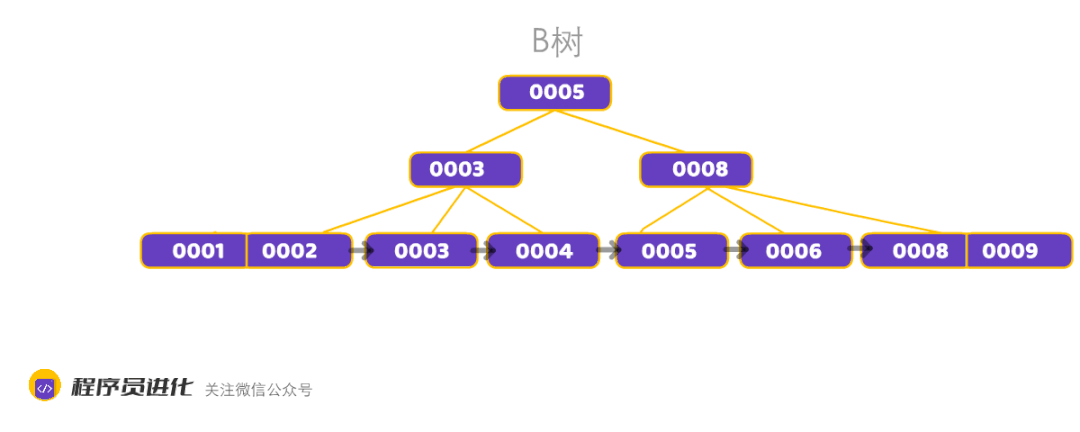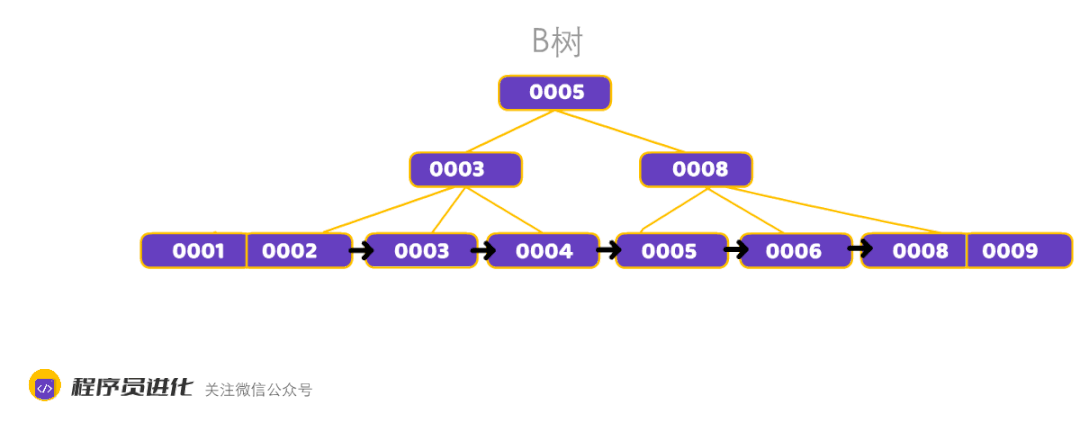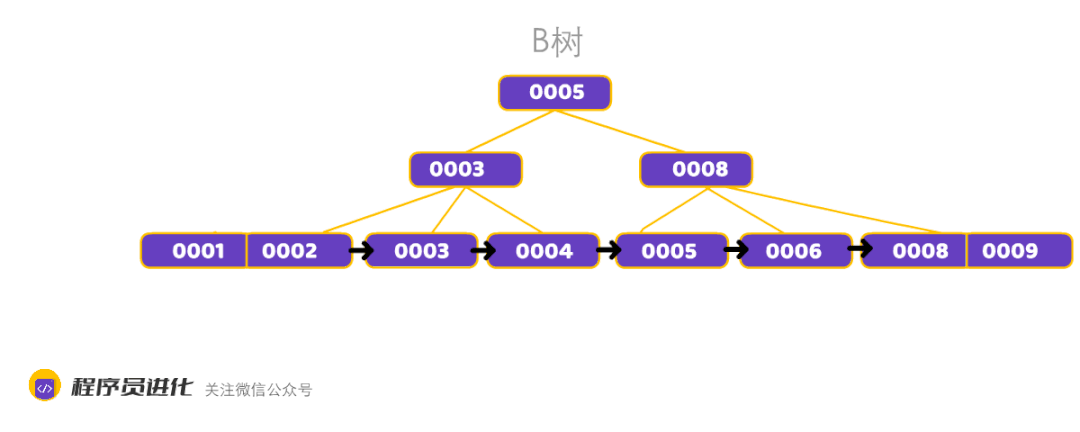
3、相邻叶子节点是通过指针连起来的,并且是关键字大小排序的。
B+树和B树的主要区别:
B+树的扫表能力强,B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据,也就是说B树需要把整棵树都遍历一遍,而B+树只需要遍历所有的叶子节点即可,大大减少了磁盘读取次数。
B+树排序能力强,B+树相邻的叶子节点之间是通过链表指针连起来,并且从左到右递增,这样就可以更方便的支持范围查询 ,同时通过二分查找实现O(logn)级查找,B树却不是。
查找过程中,B树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束
B树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。
好了,讲到这里,面试中常问到的“MySQL为什么使用B+树索引“,“B+树和B树的差别是什么”,这类问题就好回答了。
PS:
一个朋友通过家里相亲的方式就要结婚了,从相亲到结婚前后不到一个月,除了时间短,在结婚流程上也出现了很多分歧。结婚是两个家族观念的融合,多半没有对错,只因立场不同。
结婚之初发生吵架我还会经常问自己:
为什么这件事不能按理来说
为什么我是先说的对不起那个,能不能设一个说哄对方次数的上限,到了上限我们换一换。
现在过了那么多年,我已经不纠结这个问题了,用我媳妇的话来说,我的“情商”变高了,更包容她。
关注我,带你一起进化!
更多面试资料
