





Flink State 是 Apache Flink 中用于存储任务状态信息的关键机制。在许多场景都需要通过查询任务快照中的 State 获取有效线索:
State元信息可视化,可以根据State的信息进行排查,优化大状态问题。 CDC等同步任务,State查询可以协助任务迁移,手动设置起点为State里位移信息即可 数开可以对State中间结果数据进行数据探查,对任务各个算子处理后数据进行分析,解决FlinkSQL 状态过期,业务逻辑问题等。 部分场景下,开发可以对任务出现异常时,可以通过查询任务State获取有效线索。
相比传统的脚本方式,可视化的操作界面能够更加直观和易用,大幅降低了用户的学习成本。通过与实时计算平台深度集成,提供一站式解决方案。此外,该功能还具备极高的灵活性,支持通过SQL查询State数据,能够满足不同用户的多样化需求。
1.1 适用使用者
开发者:需要排查任务异常、优化任务性能。 数据工程师:需要分析任务中间结果,验证业务逻辑。 运维人员:需要监控任务状态,确保任务稳定运行。
1.2 核心优势
降低使用门槛:通过可视化界面和 SQL 查询方式,降低用户使用 State 探查功能的门槛。 提升运维效率:帮助用户快速定位问题,减少故障排查时间。 增强任务可控性:通过 State 数据探查,用户可以更好地掌控任务运行状态。 支持业务扩展:为任务迁移、性能优化等场景提供数据支持,助力业务发展。
1.3 指标数据查询
实时计算任务在实际运行过程中,某个小时窗口内的聚合结果异常(例如:订单总金额突然暴跌)为了验证问题,可以使用 Flink State 可视化功能进行问题排查。
(1)进入状态探查入口
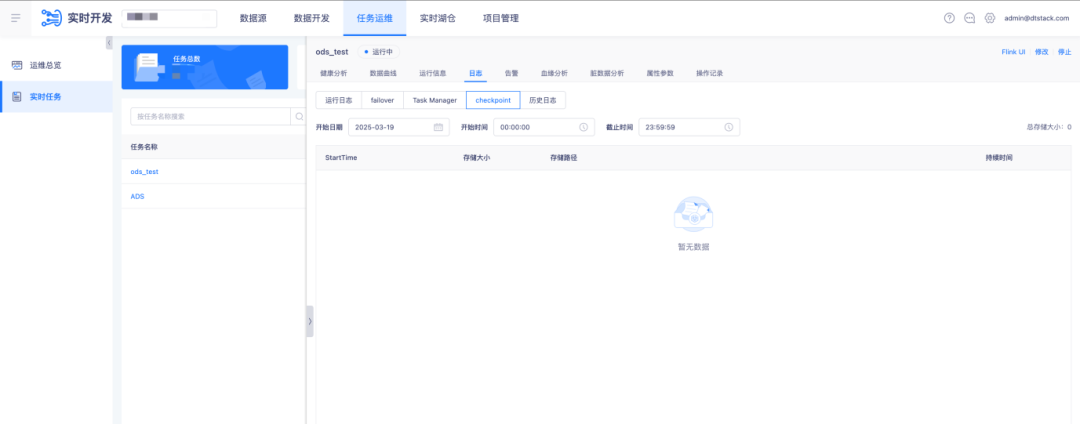
在实时计算平台,进入「任务运维」页面。 在任务列表中,选择目标任务,点击「CheckPoint」选项。 选择一个最近的 CheckPoint(CK),点击「状态探查」按钮。
(2)启动状态探查

系统显示状态探查的运行状态为「等待提交」。 提交后,状态变为「探查中」,存储路径旁的按钮变为蓝色,表示正在探查。
(3)查看探查结果
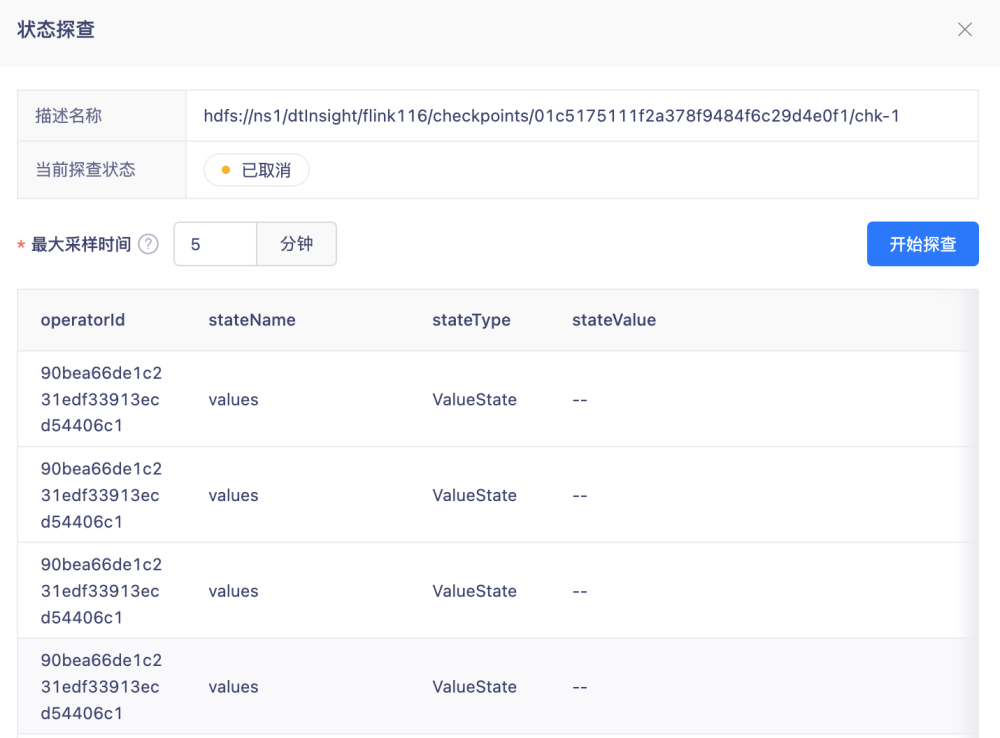
探查完成后,状态变为「探查完成」。 页面实时刷新显示State页面最新「状态结果」 。 State 中记录着窗口的累计值。此时可以检查:是否有窗口状态数据丢失或异常(例如:某个窗口内的总金额为负值或远低于预期)
(4)定位问题根因
通过对最近的几次checkpoint进行探查,可以定位到哪次checkpoint开始出现异常信息,并根据对应checkpoint里的source位点信息,可以尝试回溯对应位点信息开始的数据,通过对比正常窗口与异常窗口的 State 数据,可以判断问题可能出在:
数据异常:上游 Kafka 数据中存在脏数据或错误订单。 聚合逻辑问题:窗口状态更新过程中出现异常,导致部分订单未被累计或被错误计入负值。
最后结合 State 可视化的直观展示,可以迅速定位异常窗口,并进一步分析数据流转情况,从而采取相应的优化措施,例如在 SQL 语句中增加数据校验逻辑(如 WHERE amount >= 0)或对上游数据进行预处理。

方法二:自定义模式探查
相比于可视化的方式,自定义模式更适合具有特殊需求的数据开发者,使用者可以使用链接FlinkState-Connector,实现更多自定义功能。
2.1 操作方式
实时平台支持通过 SQL 查询 State 数据,满足不同用户的需求,以下是在实时开发平台FlinkSQL脚本模式使用 FlinkState-Connector 示例,支持在实时平台通过 FLinKSQL 方式查询 flinkstate-x插件作为 Source 端的状态信息:
CREATE TABLE source(operatorID STRING,--算子idstateName STRING,--状态名称stateType STRING,--状态类型(Listoperator)serializerType STRING,--state序列化方式stateValue STRING,--具体的state值`key` STRING,--keyState里key的值keySerializer Type STRING,--keyState里key的序列化方式namespace STRING--命名空间)WITH('connector'='flinkstate-x','path'='hdfs://ns1/dtInsight/flink112/checkpoints/9b7a4505edd19a1217d1ab16ccf0d31e/chk-276','properties.hadoop.fs.defaultFS'='hdfs://ns1','properties.hadoop.dfs.ha.namenodes.ns1'='nn1,nn2','properties.hadoop.dfs.namenode.rpc-address.ns1.nn2'='172.16.23.232:9000','properties.hadoop.dfs.namenode.rpc-address.ns1.nn1'='172.16.23.231:9000','properties.hadoop.dfs.nameservices'='ns1','properties.hadoop.dfs.client.failover.proxy.provider.ns1'='org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider');
FlinkState 参数:
名称 | 是否必选 | 默认值 | 含义 |
path | 是 | 无 | checkPoint路径 |
properties.hadoop | 否 | 默认flink运行环境对应的hdfs集群 | checkpoint所在hdfs配置信息 |
just-metadata | 否 | false | 只读取state元数据信息,不读取具体值 |
运行获取的结果详情:
|operatorID|stateName|stateType|serializerType|stateValue|key|keySerializerType|namespace|RowKind||cbc357ccb763df2852fee8c4fc7d55f2|topic-partition-offset-states|ListState|org.apache.flink.api.java.typeutils.runtime.TupleSerializer|(KafkaTopicPartition{topic='user_behavior',partition=0},-915623761774)|null|null|null|INSERT|
未来计划新增对 WindowState、BroadcastState 等状态类型的支持,同时提供 State 数据导出为 CSV 格式的功能以方便离线分析和存档,并具备告警功能,在 State 过大或异常时及时通知用户,全面满足多样化的场景需求。


