




背景
Q2参与某大数据项目入围测试,可支配服务器节点有限,其中测试用例之一需要使用Flink基于特定资源、在特定时间内、将特定数据量写入HBase集群。常规用例方案通常是Flink消费消息队列数据写HBase,受限于上述条件,经过与业主沟通确认,笔者通过实现自定义Flink并发Source算子自生产数据的方式将数据写入HBase。文章首发微信公众号:大数据从业者,其它均为转载,欢迎您点赞关注推荐转发,谢谢!
方案分析
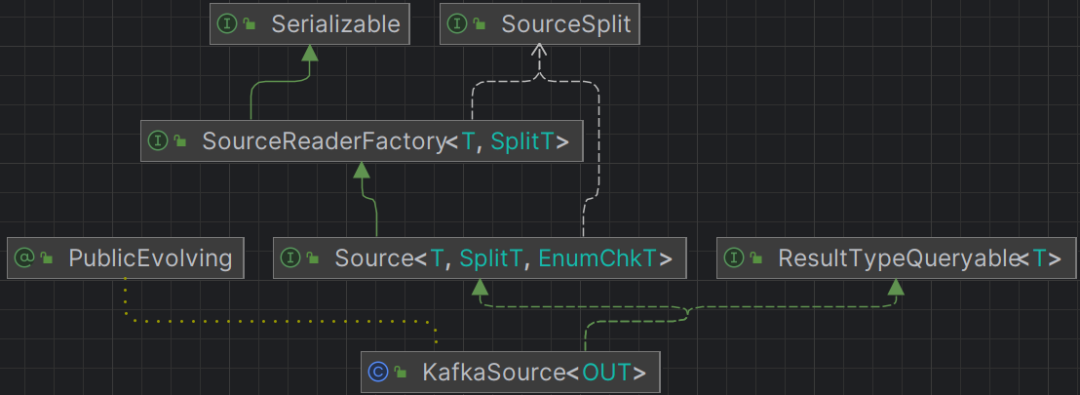
public class KafkaSource<OUT>implements Source<OUT, KafkaPartitionSplit, KafkaSourceEnumState>,ResultTypeQueryable<OUT>
如果参考KafkaSource实现细节,复杂度稍有点高,也有点抽象。因为除了实现KafkaSource类还需要实现SourceSplit接口(如KafkaPartitionSplit)和EnumChkT实体类(如KafkaSourceEnumState),以及KafkaSourceBuilder类。所以,并未采用该方法。
而FlinkKafkaConsumer方式就比较清晰、直接、简单了。除去本文测试用例不涉及的checkpoint相关接口类,只需要继承实现一个 RichParallelSourceFunction即可,如图所示:
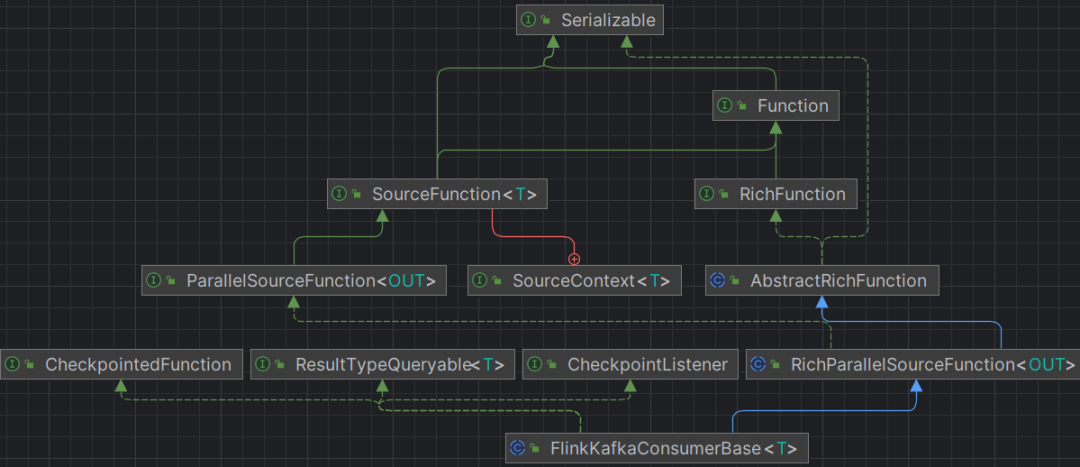
public abstract class FlinkKafkaConsumerBase<T> extends RichParallelSourceFunction<T>implements CheckpointListener, ResultTypeQueryable<T>, CheckpointedFunction
本文最终采用继承实现RichParallelSourceFunction类的方式(注意不要使用RichSourceFunction,不支持多并行度),只需要实现open方法构造测试数据,在run方法实现定时发送数据到Flink内核即可,如下所示:
@Overridepublic void open(Configuration parameters) throws Exception {data = buildData(dataByteSize);}@Overridepublic void run(SourceContext sourceContext) throws Exception {while (isRunning) {sourceContext.collect(data);Thread.sleep(sleepTimeMs);}}
完整示例代码见笔者github:
https://github.com/felixzh2020/felixzh-flink/blob/master/CustomSource/src/main/java/CustomSource.java
CustomSource可以配套任何Flink sink输出算子使用,简单起见这里以内置Print算子为例:
CustomSource customSource = new CustomSource<>(parameterTool.getLong("custom.source.data.size"), parameterTool.getLong("custom.source.sleep.ms"));env.addSource(customSource).returns(Types.STRING).setParallelism(parameterTool.getInt("custom.source.parallelism")).print();
至于HBaseSink算子实现后续文章更新,里面有坑啊!
实践效果
使用CustomSource算子定时定量生产数据,配套Print算子输出:
flink run -t yarn-per-job -d CustomSource-1.0.jar MySource2Print.properties
FlinkUI算子流程如图所示:
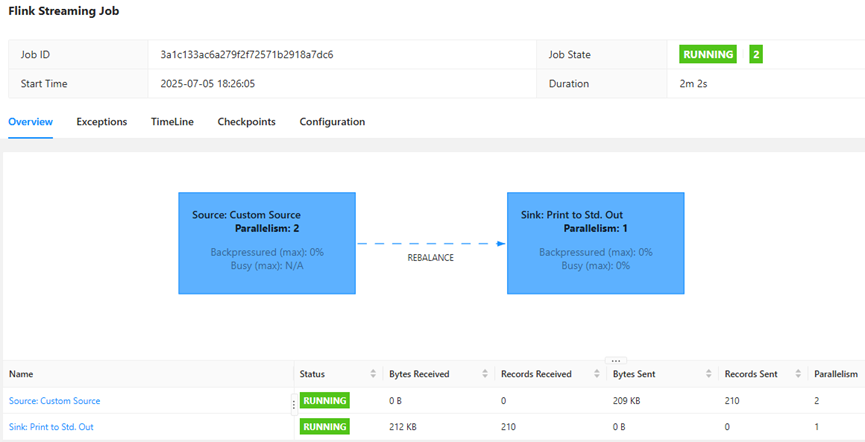
测试数据打印输出到TaskManager标准输出,如图所示:
总结
文章首发微信公众号:大数据从业者,其它均为转载,欢迎您点赞关注推荐转发,谢谢!
