




在大数据技术栈不断演进的背景下,Apache Spark 3.0 推出的 Spark Catalog 作为标准化元数据管理接口,彻底革新了异构数据源的协同管理模式。Spark Catalog 通过统一元数据视图、动态 Schema 发现和标准化 API 三大核心能力,实现了跨 OceanBase、HDFS、Iceberg 等数据源的元数据一致性管理。
本文将深度解析 Spark Catalog 与 OceanBase 的集成实践,从架构设计、性能优化到生产环境落地,为企业构建高效的数据处理链路提供完整解决方案。
一、背景与架构概述
📕(一)Spark Catalog 核心价值
Apache Spark 3.0 引入的 Spark Catalog 作为标准化元数据管理接口,通过统一元数据视图、动态 Schema 发现和标准化 API 三大核心能力,实现了跨异构数据源的元数据一致性管理。相较于传统 Hive Metastore,其显著优势体现在:
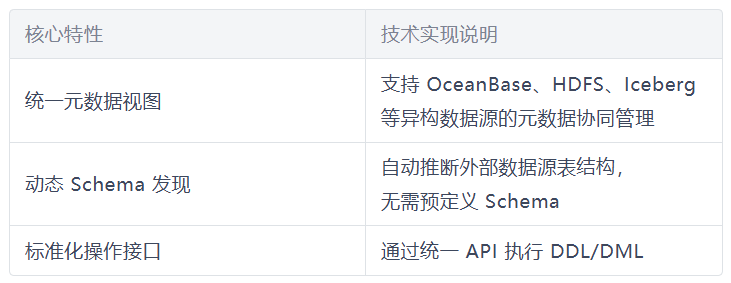
📕(二)OceanBase Connector 适配方案
OceanBase Spark Connector 自 1.1 版本起深度集成 Spark Catalog:
无缝接入:项目完全开源,GitHub 开源地址:
https://github.com/oceanbase/spark-connector-oceanbase
零代码接入:零代码,支持全 SQL 交互。
性能增强:自适应分区、并行读写、谓词下推等优化策略。
跨租户访问:通过 Catalog 映射多租户数据源,实现跨业务单元联合查询。
分区表优化:自动识别 OceanBase 数据库分区表,优化分区表读取性能。
自动 Schema 推断:自动发现推断 OceanBase 数据库表结构。
二、Spark 集群资源配置优化
📕(一)硬件资源规划策略
以 128 核/1TB 内存服务器为例,建议采用以下资源配置策略:
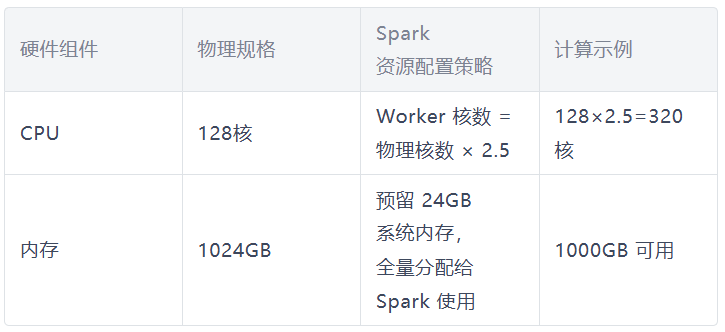
📕(二)关键配置参数调整
1、系统级配置(spark-env.sh):规划硬件资源。
内存资源配置export SPARK_WORKER_MEMORY=1000GCPU 资源配置export SPARK_WORKER_CORES=320
2、作业级配置(spark-defaults.conf):调整 Spark Job 相关参数。
Driver资源配置spark.driver.cores=2spark.driver.memory=4gExecutor资源配置spark.executor.memory=16gspark.executor.cores=4序列化优化spark.serializer=org.apache.spark.serializer.KryoSerializer
📕(三)调优目标验证
通过压力测试验证以下指标:
集群资源利用率 ≥95%
线性扩展能力验证(任务并行度与吞吐量呈正相关)
稳定性测试(72 小时持续负载)
三、OceanBase Catalog 配置实践
📕(一)基础连接配置
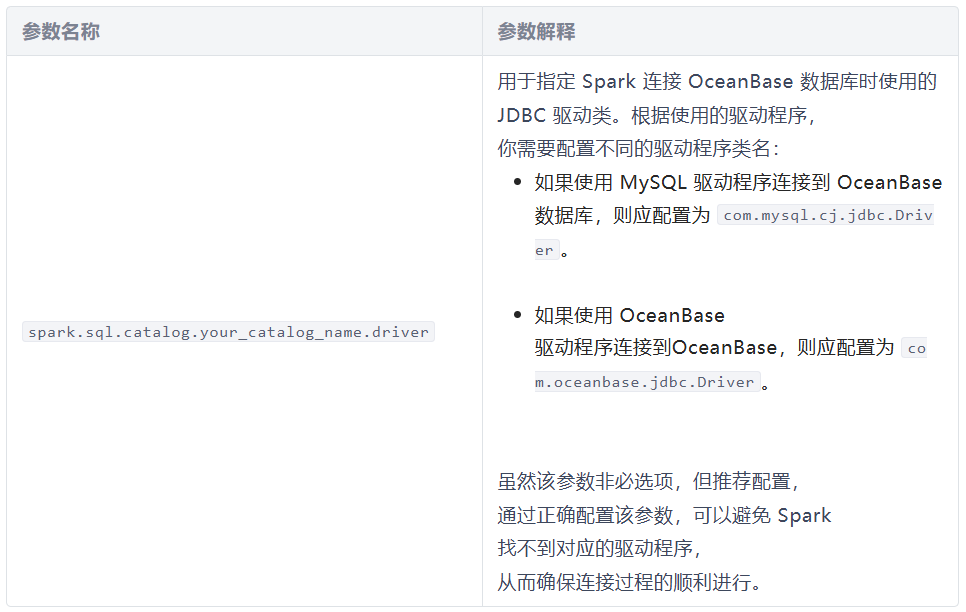
📕(二)读操作优化
根据您实际的硬件规格与资源条件,通过调整以下参数,提升 Spark 从 OceanBase 数据库的读取性能:
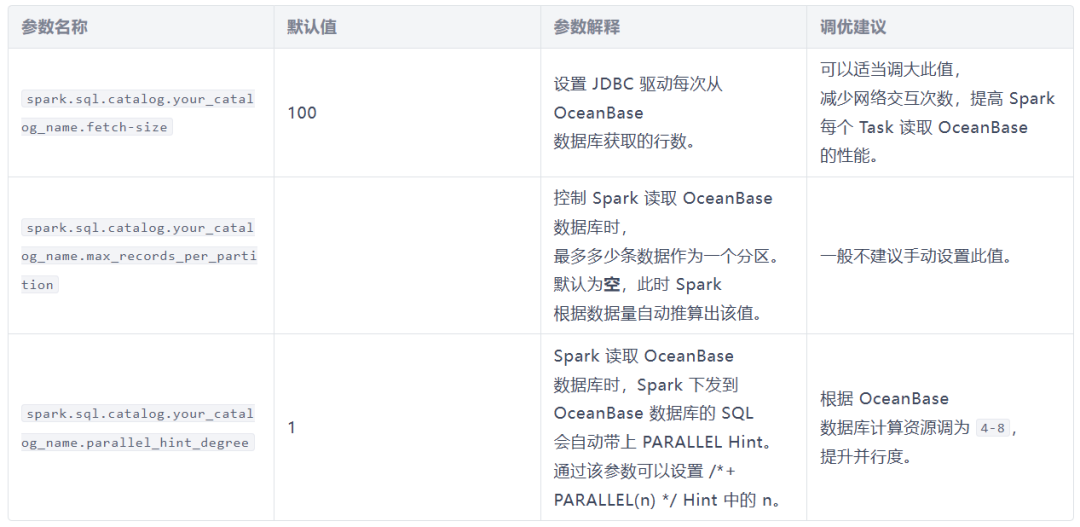
📕(三)写操作优化
通过调整以下参数,提升 Spark 从 OceanBase 数据库的写入性能:
1、JDBC 写入优化

2、旁路导入优化

📕(四)表管理规范
非分区表有两个限制,分别是不支持创建索引以及不能设置列默认值。分区表也有兼容性限制,Spark 仅支持 BUCKET 分区,对应 OceanBase 数据库的 KEY 分区。例如:
CREATE TABLE test.test1 (user_id BIGINT COMMENT 'test_for_key',name VARCHAR(255))PARTITIONED BY (bucket(16, user_id))COMMENT 'test_for_table_create'TBLPROPERTIES('replica_num' = 2, COMPRESSION = 'zstd_1.0');
同时,分区表不支持多级分区,仅允许一级分区。复杂分区表应在 OceanBase 数据库侧直接创建,Spark Catalog 可自动识别现有表结构。
四、生产环境建议
1、参数调优:根据业务负载动态调整 Spark 资源配置和 OceanBase 数据连接参数,关注线程并发、批量大小等关键指标。
2、管理分区:为提升查询效率,考虑根据业务需求对表进行合理的分区。
3、管理权限:确保在 OceanBase 数据库和 Spark 中妥善管理用户权限,防止未经授权的数据访问。
4、管理版本:定期检查更新版本,建议升级到最新版 spark-connector-oceanbase,集成性能优化和新功能。
综上所述,Spark Catalog 与 OceanBase 的深度集成不仅解决了传统元数据管理的异构性难题,更实现了数据处理性能质的飞跃。随着大数据场景对实时性、扩展性要求的不断提升,Spark Catalog 与 OceanBase 的组合将成为企业构建云原生数据平台的核心底座,持续赋能数据价值挖掘与业务创新!
