




关于作者:

阿喀琉斯之踵(Achilles' Heel),原指阿喀琉斯的脚后跟,因是其身体唯一一处没有浸泡到冥河水的地方,成为他唯一的弱点。阿喀琉斯后来在特洛伊战争中被毒箭射中脚踝而丧命。现引申为致命的弱点、要害。
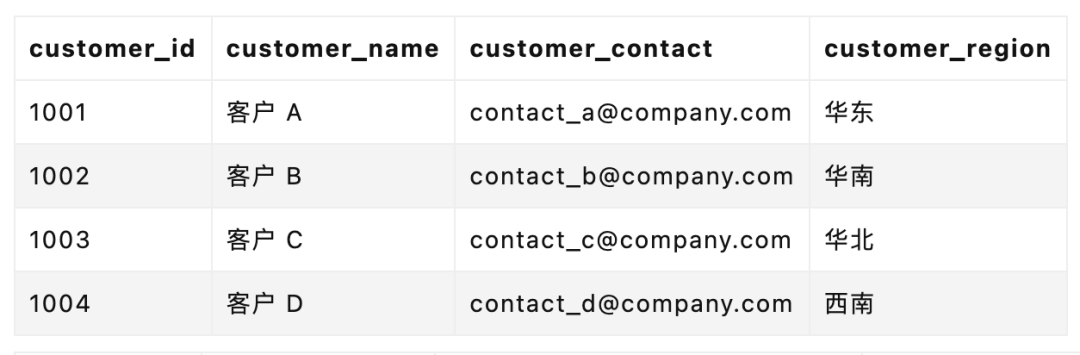
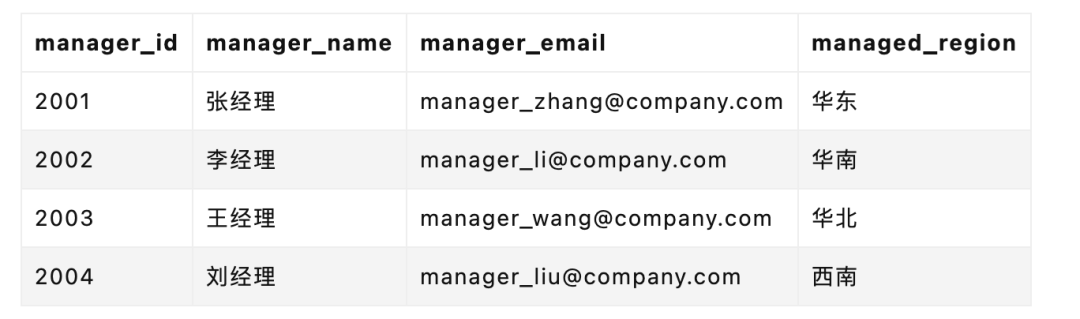
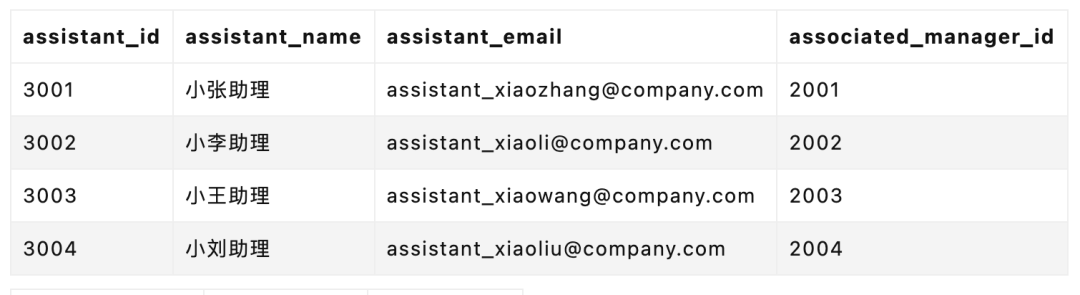
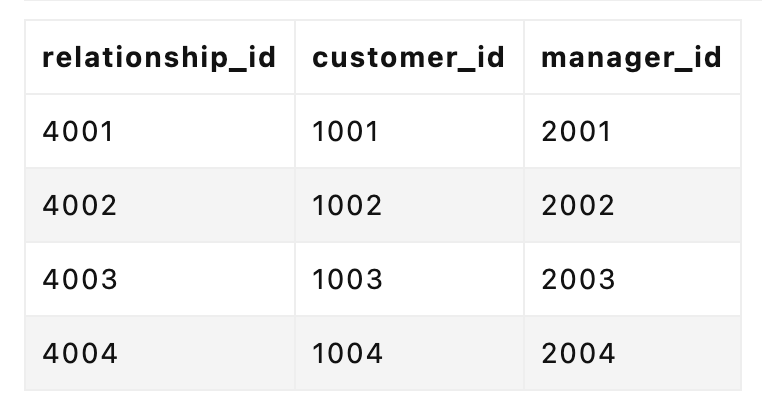
SELECT
c.customer_name AS 客户名称,
m.manager_name AS 客户经理姓名,
ma.assistant_name AS 助理姓名,
m.manager_email AS 客户经理邮箱,
ma.assistant_email AS 助理邮箱
FROM
customers c
JOIN
customer_manager_relationship cmr ON c.customer_id = cmr.customer_id
JOIN
managers m ON cmr.manager_id = m.manager_id
JOIN
manager_assistants ma ON m.manager_id = ma.associated_manager_id
WHERE
c.customer_name = '客户 A';
三张表的 JOIN,就意味着随着数据量的提升,有可能出现查询性能的断崖式下滑。过往很多互联网公司,往往会有不允许超过几张表的 JOIN 的“军规”就是来自于此。
这背后的本质在于,外键无语义描述能力,无法表达关系的强度、类型等属性,难以满足复杂关系的存储需求。即便是如今关系型数据库已经如此强大,仍然有着它们无法有效覆盖到的场景。
然而,人际关系的复杂之处就在于此,我们现实中的人际关系是动态的网状结构,非静态层级,随时可能发生变化,难以用传统的表结构来准确表述——我遇见谁会有怎样的对白,我等的人她在多远的未来。
就比如 Jack Ma 背后有哪些企业和关联人,这些关联的任何企业具体和他又是什么关系,用关系型数据库可以表述,但是在查询时带来的复杂度以及性能开销,都是远超我们想象的。其中任何一环有了变化,都会引起滚雪球一样的修改。
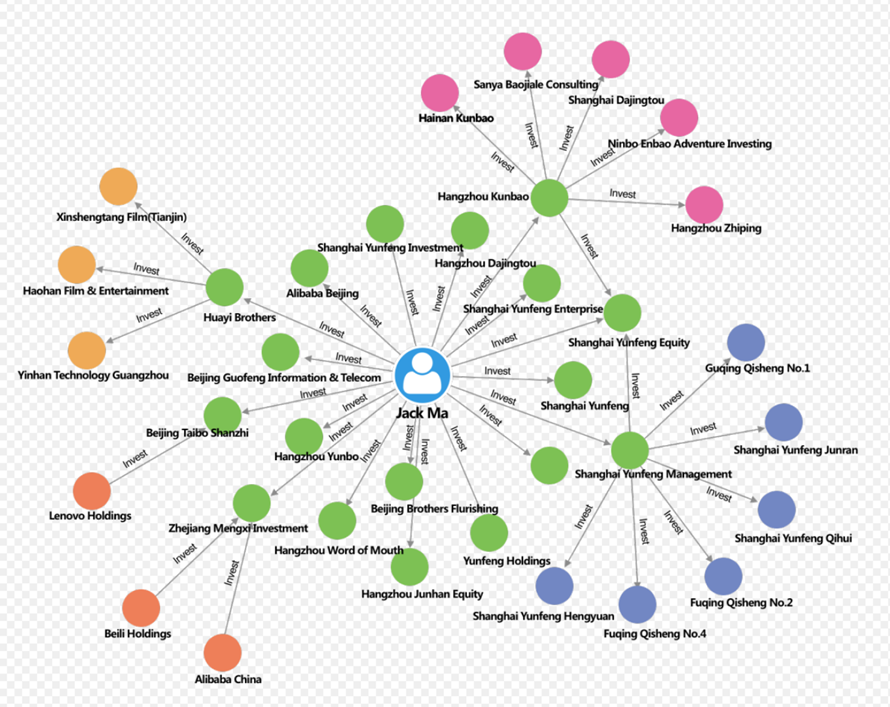
▌二、图数据库:存储逻辑的重构哲学
我们仍然从理论出发,图数据库表达“关系”时,有哪些先天优势。
(一)图数据库三要素天然适配关系
顶点:人/物(携带属性),如姓名、年龄等,是关系的主体。一个顶点有时候更像关系型数据库中的一条记录,包含了属性,同时代表一个确定的实体。
边:关系(可携带权重、类型),如亲密度、时间等,是关系的连接。边在关系型数据库里怎么直接描述?外键或者其他方式的引用,但是图数据库中,一条记录足以,甚至表达更加简练精确。
属性:为顶点和边提供详细信息,丰富关系的语义。顶点和边都可以带属性,比如顶点里人有年龄有身高,边的属性里有关系的走向以及关系的具体定义等等。
那么与关系型数据库相比,图数据库的差异就很明显:
1. 关系表达:关系型数据库采用隐式表达(外键约束),图数据库采用显式(一等公民)直接存储关系。
2. 查询模式:关系型数据库集合操作,图数据库图遍历。
(二)图数据库查询语言深度挖掘隐藏信息
既然关系表达和查询模式存在差异,那么必然就会带来查询语言的不同,SQL 查询作为结构化查询,有着自己先天的优势,但是在面对复杂关系时,就会有自己的局限性。
比如,查询黄晓明和李晨的关系,以及他们有没有共同的朋友或者间接合作的企业,SQL 语言就存在局限:需要显式指定 Join 路径,并且路径固化,难以应对动态关系查询。
那么如果用图数据库语言来查询,不但代码简洁,还可以通过查询关系深度挖掘到更多不同的信息。
此外,在黄晓明和李晨的关系中,深度一度,可以获取他们直接的商业关联,二度还可以发现共同的朋友以及互相的商业关系——这是 SQL 语言不擅长的。
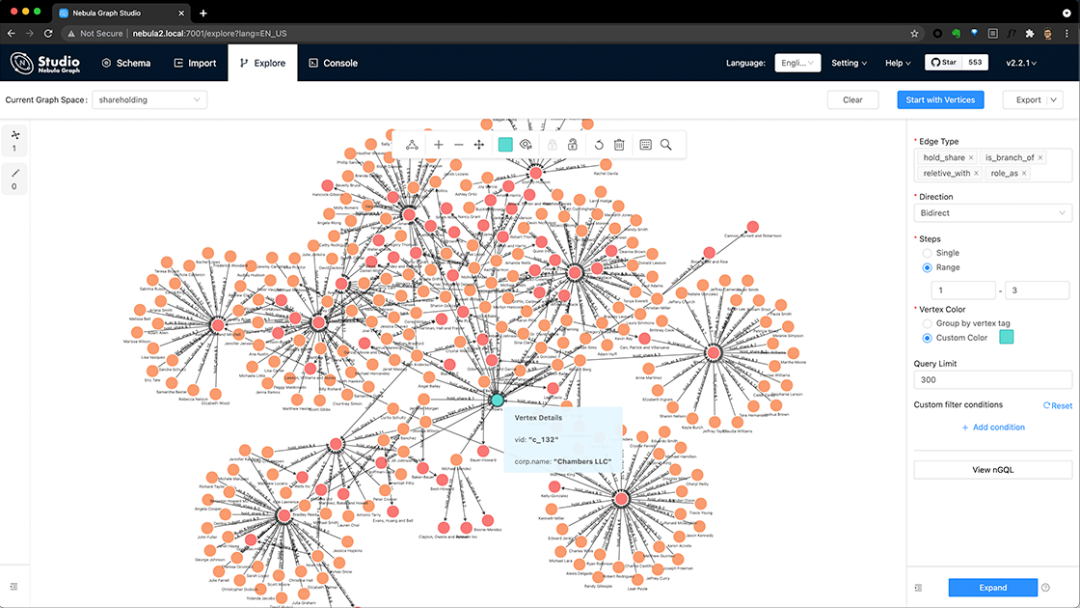
(用 NebulaGraph 进行某公司股权穿透)
-- 查询客户A的客户经理及其助理信息
MATCH (c:Customer {customer_name: '客户A'})-[:Managed_By]->(m:Manager)-[:Assisted_By]->(a:Assistant)
RETURN c.customer_name AS 客户名称, m.manager_name AS 客户经理姓名, a.assistant_name AS 助理姓名, m.manager_email AS 客户经理邮箱, a.assistant_email AS 助理邮箱;
为实现在处理千亿节点万亿条边的超大数据集时,也能提供毫秒级查询的解决方案,NebulaGraph 在核心设计上做出了多项关键努力:
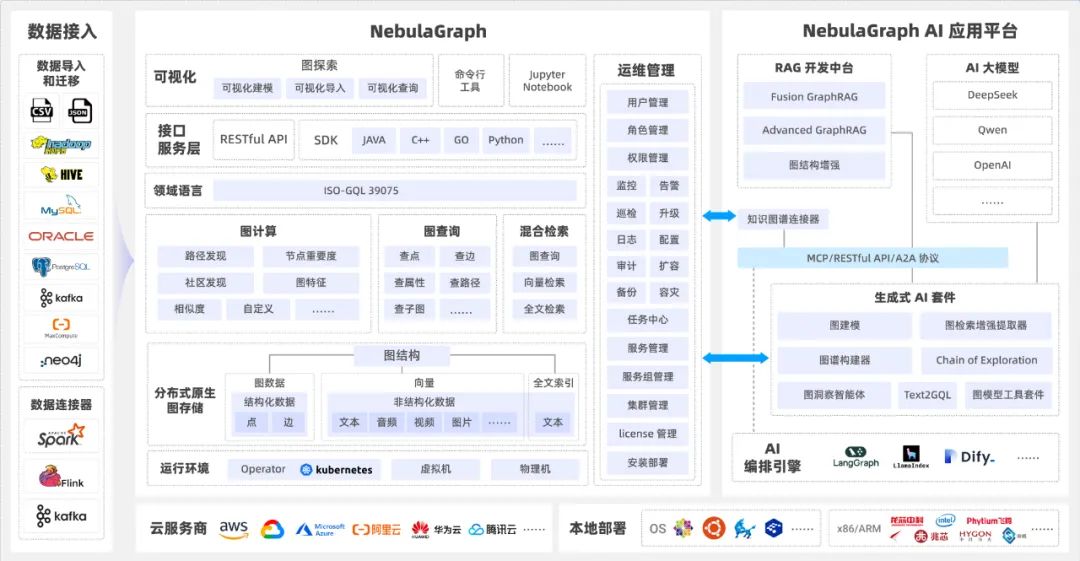
架构层面:采用存算分离架构,支持计算层与存储层的独立、灵活扩缩容,有效应对负载变化与数据增长。
数据模型层面:提供强 Schema 的灵活属性图模型,支持对点、边、及其属性进行便捷的定义、添加与修改,满足复杂业务建模需求。
查询模式层面:基于原生图存储引擎与免索引邻接的核心优势,通过高效的图遍历模式查询,使得在深度关联查询(尤其是多跳查询)场景下,随着数据规模的增长,其性能优势相比传统关系型数据库愈发显著。
在过去的一段时间里,我做了如下探索和测试:
社交网络分析
1. 合规检测:识别洗钱或黑产团伙,通过关联的设备或者账号,在反洗钱方面的应用。
2. 人际关系分析:关键节点挖掘,例如高净值客户识别,通过股权穿透、周围强人际关系等等。
金融风控
1. 实时反欺诈:闭环交易检测,在关系型数据库中不能直观反映的A→B→C→A路径分析。
2. 知识图谱构建:比如企业股权穿透,让多层持股关系可视化。
Graph+AI(规划中)
1. GraphRAG:知识图谱增强大模型推理,这部分具体怎么做还想看看其他同行的探索。
2. Text2 GQL:自然语言转查询语句,目的是让业务部门自助完成各类数据查询工作。
▌五、结语
总之,当你需要处理大规模复杂关系数据并追求高效查询时,NebulaGraph 作为一款开源分布式图数据库,能够有效解决这一核心挑战。
最后依旧要强调,每一种数据库有着自己的擅长的领域与场景,我们去研究关系型数据库、文档数据库、图数据库,最终目的不是为了谁替代谁,而是在不同场景里综合选择当下最合适的方案。
✨更多关系型数据库与图数据库的对比,可查看官网
https://www.nebula-graph.com.cn/posts/graph-database-vs-relational-database
✦
如果你觉得 NebulaGraph 能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例
✦
风控场景:携程|Airwallex|众安保险|中国移动|Akulaku|邦盛科技|360数科|BOSS直聘|金蝶征信|快手|青藤云安全
平台建设:博睿数据|携程|众安科技|微信|OPPO|vivo|美团|百度爱番番|携程金融|普适智能|BIGO
✦
✦



