




各位关注 Chat2DB 的朋友们,大家好!
今天,我们怀着无比激动的心情,向大家宣布一个酝酿已久的消息:智能数据客户端的革新者——Chat2DB,正式发布 4.0 版本!
这不仅仅是一次常规的版本迭代,这是一次彻头彻尾的革命。
我们重写了底层架构,带来了高达 10 倍的性能提升;我们拓展了连接边界,让您能在更多元的场景中探索数据;我们登上了行业之巅,用实力证明了在 Text-to-SQL 领域的绝对领先地位。
如果您曾因客户端的卡顿而打断思路,因复杂业务数据的查询而焦头烂额,因 AI 生成 SQL 的不准确而反复修改,那么 Chat2DB 4.0 将是您一直在等待的答案。
准备好了吗?让我们一起拉开这场数据工具革命的序幕!
一、架构焕新:告别 Electron,拥抱 10 倍原生性能
“天下武功,唯快不破。” 在数据工具的世界里,性能就是生命线。每一次点击的延迟,每一次查询的等待,都在无形中消耗着开发者的耐心和创造力。
在过去的版本中,我们和许多流行的桌面应用一样,选择了基于 Electron 的技术栈。Electron 为我们带来了卓越的跨平台开发效率,让 Chat2DB 能够迅速地与 Windows, macOS, Linux 用户见面。但我们深知,这并非没有代价。基于 Chromium 和 Node.js 的封装,使得 Electron 应用在内存占用和执行效率上,始终与原生应用隔着一道“性能墙”。
我们听到了社区的声音,我们感受到了用户的痛点。在追求极致用户体验的道路上,我们绝不妥协。
因此,在 Chat2DB 4.0 的研发周期中,我们做出了一个极其艰难但无比正确的决定:彻底重构客户端架构,完全去除 Electron 依赖!这意味着什么?
这意味着 Chat2DB 4.0 的客户端,已经从一辆舒适但略显沉重的“旅行车”,进化成了一台轻盈、敏捷、动力澎湃的“超级跑车”,基于新的架构我们可以发挥自己的能力做任何扩展。
1. 性能的飞跃:高达 10 倍的提升
“10 倍”不是一个噱头,而是我们经过无数次测试后,自信地写下的数字。这种提升体现在您日常使用的每一个角落:
秒级启动:忘掉漫长的白屏等待。无论是在您性能强劲的工作站,还是在资源有限的笔记本上,Chat2DB 4.0 都能实现近乎瞬时的启动。
毫秒级响应:点击菜单、切换标签页、打开设置,所有 UI 操作都如丝般顺滑,毫无拖泥带水之感。
海量数据渲染不卡顿:当您执行一个返回数万行结果的
SELECT *
查询时,旧版客户端可能会出现滚动掉帧、界面假死的情况。在 4.0 版本中,我们优化了数据网格的渲染引擎,即使面对海量数据,上下滚动、筛选过滤也依然流畅自如。更低的资源占用:与 Electron 版本相比,全新的原生架构在 CPU 和内存占用上实现了断崖式的下降。您可以一边开着 Chat2DB,一边运行着重量级的 IDE 和虚拟机,而无需担心系统资源被“电老虎”吞噬。
这次架构升级,是我们对“快”的极致追求,是对开发者时间的终极尊重。我们希望 Chat2DB 不再仅仅是一个功能强大的工具,更是一个能让您“无感”使用、沉浸于数据世界的“隐形助手”。
2. 体验的升华:原生如斯,更加丝滑
性能的提升,最终服务于用户体验。去除 Electron 后,Chat2DB 4.0 带来了前所未有的“原生感”。它更贴近操作系统的设计语言,拥有更快的窗口渲染和更跟手的交互动画。我们相信,当您第一次打开 Chat2DB 4.0 时,那种轻快、流畅、浑然一体的感觉,会让您再也回不去那个“笨重”的时代。
3. 奠定未来基石:为 AI 的无限可能释放空间 (新增亮点)
然而,这次架构革命的意义,远不止于眼前的“快”和“滑”。它更是一项面向未来的投资,为 Chat2DB 在 AI 能力上的进化,奠定了最坚实的基础。
我们深知,AI 是 Chat2DB 的灵魂。未来的智能数据工具,绝不应仅仅满足于云端大模型的调用。更高效、更私密、更个性化的 AI 能力,需要强大的本地计算能力作为支撑。
过去的 Electron 架构,本身就是一个资源消耗大户,它像一块沉重的铅板,限制了我们在客户端上部署复杂 AI 功能的想象力。任何需要消耗本地算力的 AI 任务,都可能让整个应用变得卡顿,体验大打折扣。
而现在,情况完全不同了。
全新的轻量化原生架构,为我们释放了宝贵的系统资源“净空区”(Headroom)。这片净空区,就是我们为未来 AI 能力预留的广阔舞台。
本地 AI 模型成为可能:我们可以探索在客户端直接运行更小、更高效的本地 AI 模型,实现诸如 SQL 语法实时检查与智能补全、数据隐私脱敏、甚至在离线状态下进行简单 Text-to-SQL 的能力,这在过去是不可想象的。
更复杂的 AI 辅助:未来,我们可以在客户端实现更深度的 AI 融合。例如,在您编写 SQL 的过程中,AI 可以在后台实时分析执行计划,并给出索引优化建议;或者根据您的查询历史和数据内容,主动推荐您可能感兴趣的分析维度。
无缝的 AI 交互体验:当客户端本身轻盈如飞时,我们才能将更多的资源投入到 AI 计算和交互中,而不会牺牲应用的流畅度。无论是未来更丰富的 AI 对话,还是 AI 驱动的数据可视化,都将因为这个坚实的基础而变得更加流畅和智能。
所以说,告别 Electron,不仅是解决当下的性能痛点,更是拆除了未来发展的桎梏。我们在打造一个更快的客户端,更是在构建一个强大的、面向未来的 AI-Native(AI 原生) 平台。这个平台,将有足够的能力承载我们对下一代智能数据工具的远见。
二、连接未来:全面支持 MCP,解锁数据查询新范式
如果说架构升级是 Chat2DB 4.0 的“内功心法”,那么对 MCP (MetaCube Protocol) 的支持,则是我们向外拓展的“绝世招式”。
在企业中,原始的数据库表结构往往是复杂且难以理解的。业务人员,甚至许多后端开发者,都很难直接通过 JOIN
、GROUP BY
来准确地分析业务问题。为此,许多公司构建了“指标平台”或“语义层”,将复杂的业务逻辑封装成易于理解的“指标(Metric)”和“维度(Dimension)".
但是,传统的数据库客户端无法理解这一层抽象。您仍然只能看到底层的表和字段。
MCP 的出现,正是为了打破这堵墙。
MCP 是一种开放的、用于数据分析的元数据协议,它允许 BI 工具和数据应用通过标准化的接口,查询定义在“语义层”中的数据模型。
Chat2DB 4.0 全面拥抱 MCP,为您带来了什么?
查询的不再是表,而是业务本身:当您通过 MCP 连接到支持该协议的数据服务(如 Cube.js 等)时,您在 Chat2DB 左侧看到的,将不再是
table_a
,user_events
这样冰冷的表名,而是“销售额”、“日活跃用户”、“用户注册来源”这样清晰的业务指标和维度。用对话直达业务答案:Chat2DB 强大的 Text-to-SQL 能力与 MCP 结合,产生了奇妙的化学反应。您可以直接用自然语言提问:“按地区展示上个季度的销售额和用户增长趋势”,Chat2DB 将自动理解您的意图,并生成符合 MCP 规范的查询,直接从语义层获取答案,而无需编写任何 SQL。
保证数据一致性:在企业中,不同的人用不同的 SQL 计算同一个业务指标,常常得出不同的结果,造成“数据打架”。通过 MCP,所有的数据查询都指向统一的、经过官方认证的语义层定义。这从根本上保证了数据口径的一致性和权威性。
赋能更多角色:产品经理、运营人员、市场分析师……这些非技术角色,现在也可以通过 Chat2DB,用最自然的方式,安全、准确地自助式探索数据,将数据分析的门槛降至前所未有的低点。
支持 MCP,标志着 Chat2DB 的定位不再局限于一个“数据库客户端”,而是进化为一个真正面向业务、面向未来的智能数据分析与协作平台。
三、巅峰对决:登顶 Spider 榜单,见证 Text-to-SQL 实力
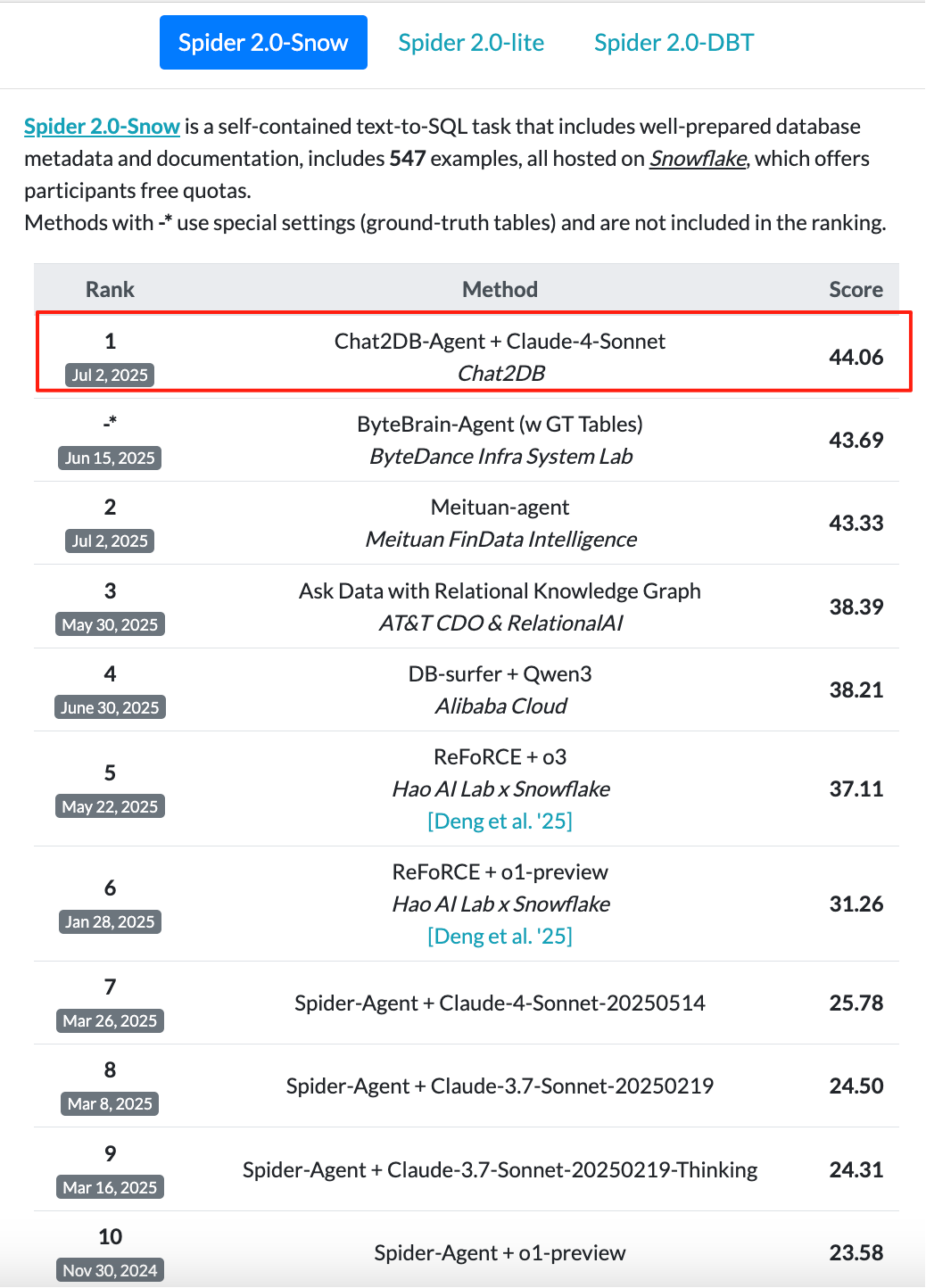
Text-to-SQL(自然语言转 SQL),是 Chat2DB 的灵魂功能,也是我们倾注了最多心血的核心技术。我们始终相信,让每一个人都能通过对话与数据交流,是数据民主化的终极形态。
然而,要将一句口语化的提问,精准地转化为一段复杂的、可执行的 SQL 代码,其技术难度超乎想象。它需要模型深刻理解自然语言的模糊性、上下文的关联性,以及数据库模式(Schema)的复杂结构。
如何衡量一个 Text-to-SQL 模型能力的强弱? 行业内有一个公认的“奥林匹克”赛场—— Spider Benchmark。
Spider 是由耶鲁大学发布的一个大规模、高难度的 Text-to-SQL 数据集。它包含了横跨 138 个不同领域的 200 个数据库,以及超过 10,000 个复杂的自然语言问题和对应的 SQL 查询。这些查询常常涉及多表 JOIN
、嵌套子查询、复杂的 WHERE
条件和聚合函数,被誉为 Text-to-SQL 领域最权威、最具挑战性的评测基准之一。
无数来自全球顶尖高校和科技巨头(如 Google, Microsoft, Salesforce)的 AI 模型,都在 Spider 榜单上激烈角逐。
而今天,我们自豪地宣布:Chat2DB 的核心 Text-to-SQL 引擎,已经成功登顶 Spider 榜单,取得了全球第一的执行准确率!
登顶 Spider 意味着什么?
极致的准确性:这意味着 Chat2DB 生成的 SQL,在面对极其复杂的业务问题时,拥有业界顶尖的准确度。您不再需要反复检查和修改 AI 生成的代码,从而极大地提升了工作效率。
深刻的理解力:无论是“查询每个部门中,在2023年之后入职且薪水高于该部门平均薪水的员工”,还是“找出至少参演过三部评价超过8分的电影的导演”,Chat2DB 都能深刻理解其中的逻辑层次和约束条件,并生成正确的查询。
强大的泛化能力:Spider 涵盖了航班、音乐、体育、医疗等各行各业的数据库。登顶榜单证明了 Chat2DB 的模型具有出色的泛化能力,无论您身处哪个行业,面对何种业务数据库,它都能快速适应并提供高质量的服务。
这一成就,不仅是 Chat2DB 团队技术实力的最佳证明,更是我们对所有用户的承诺:在 Chat2DB,您所体验到的,是世界一流的 AI 数据库交互能力。
四、拥抱开放,共创未来:Chat2DB 新版本即将开源!
最后,也是最重要的消息。
我们深知,一款伟大的工具,离不开一个繁荣的生态和活跃的社区。从诞生之初,Chat2DB 的血液里就流淌着开放与分享的基因。我们收到了来自全球各地用户的宝贵建议,也看到了无数开发者希望参与其中的热情。
我们将把 Chat2DB 4.0 的部分核心代码开源,开放给社区。
我们为什么选择开源?
信任与透明:我们希望用户能够完全信赖 Chat2DB。开源意味着每一行代码都将接受全球开发者的审视,尤其是在数据安全和隐私方面,我们愿意做到绝对的透明。
集智与创新:我们相信,社区的力量是无穷的。开源将吸引更多优秀的开发者加入我们,共同修复 Bug、贡献新功能、适配更多的数据库、探索更多的应用场景。创新的速度将不再受限于一个小团队的边界。
定制与共建:每个企业都有其独特的数据工作流。开源后,您可以自由地对 Chat2DB进行二次开发和定制,将其深度集成到您公司的内部数据平台中,打造最适合自己的数据工具。
构建行业标准:我们希望 Chat2DB 不仅仅是一个产品,更能成为下一代智能数据客户端的事实标准。通过开源,我们邀请所有同行与我们一起,共同推动整个数据工具领域向前发展。
这是一个激动人心的决定,也是一个新的起点。
写在最后:这只是一个开始
Chat2DB 4.0 的发布,是我们过去努力的结晶,更是未来征程的序章。
性能提升 10 倍的丝滑体验,是对您工作效率的承诺。支持 MCP 的广阔连接,是为您解锁数据价值的钥匙。登顶 Spider 的 AI 实力,是您探索数据时最可靠的伙伴。即将到来的全面开源,是我们与您携手共创未来的邀请。
我们深信,数据不应该是冰冷的代码和复杂的报表,它应该是鲜活的、有温度的,能够与每个人轻松对话的智慧源泉。Chat2DB 的使命,就是成为您与数据之间最智能、最高效的桥梁。
立即下载体验 Chat2DB 4.0,感受脱胎换骨的改变!
⚠️ 重要升级提示:请手动下载新版本!
由于 Chat2DB 4.0 对客户端底层架构进行了“拆骨换心”式的彻底重构(告别了 Electron),旧版本的自动升级程序将无法直接升级到 4.0 版本。
为了体验全新的闪电性能和强大功能,所有桌面端用户都需要前往官网手动下载最新安装包进行覆盖安装。
[[ 官方下载链接 ]]
https://chat2db-ai.com/download
关注我们,迎接开源!
开源的准备工作正在紧锣密鼓地进行中。我们诚挚地邀请您:
前往我们的 GitHub 主页,点亮 Star,成为我们的第一批关注者,获取开源的最新动态!
GitHub 地址: [
https://github.com/chat2db/Chat2DB 官网:https://chat2db-ai.com
加入我们的官方社区微信群,与核心开发团队直接交流,分享您的使用体验和宝贵建议。

感谢每一位支持和关注 Chat2DB 的朋友。让我们一起,用技术和热爱,定义数据的未来。
The Future is Now. The Future is Open.
