




❝开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共3300人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7群均已爆满,开8群近400 9群 200+,开10群PolarDB专业学习群 7月份开课)
OceanBase 光速快递 OB Cloud “MySQL” 给我,Thanks a lot
上次提到了OceanBase 快递给我一个生产数据库兼容MySQL的4.3.5产品,直接开箱即用。最近一直研究Hybrid search 能力,也是下一代数据库应该有的能力,有了OceanBase必然不能放过。一直有人问,公司要搞AI,,没法用MySQL了,用什么替换更好,后续公司引入AI和大量的混合搜索的需求怎么破,但还是希望使用兼容MySQL的操作语法,该怎么应对,要平移所以不考虑PostgreSQL,今天我们就试试平替MySQL的一个好的选择。
研究了一下,此次给我的4.3.5版本是5月份刚发布的最新版本的OceanBase,这里与我关心的Hybrid search 能力非常契合。
4.3.5版本这方面新增和改善的功能有:
新增 Map 数据类型、JSON 半结构化存储及稀疏向量类型,丰富数据处理能力,同时引入 HNSW_BQ 向量索引优化高维数据检索。通过深度 HTAP 能力融合,为高并发事务处理与复杂分析场景提供更安全、高效、智能的分布式数据库解决方案。


这里我模拟商业搜索结果分页显示,获取语义搜索结果的第二页每页10条,返回与查询向量L2距离最近的第11到20条的文档。
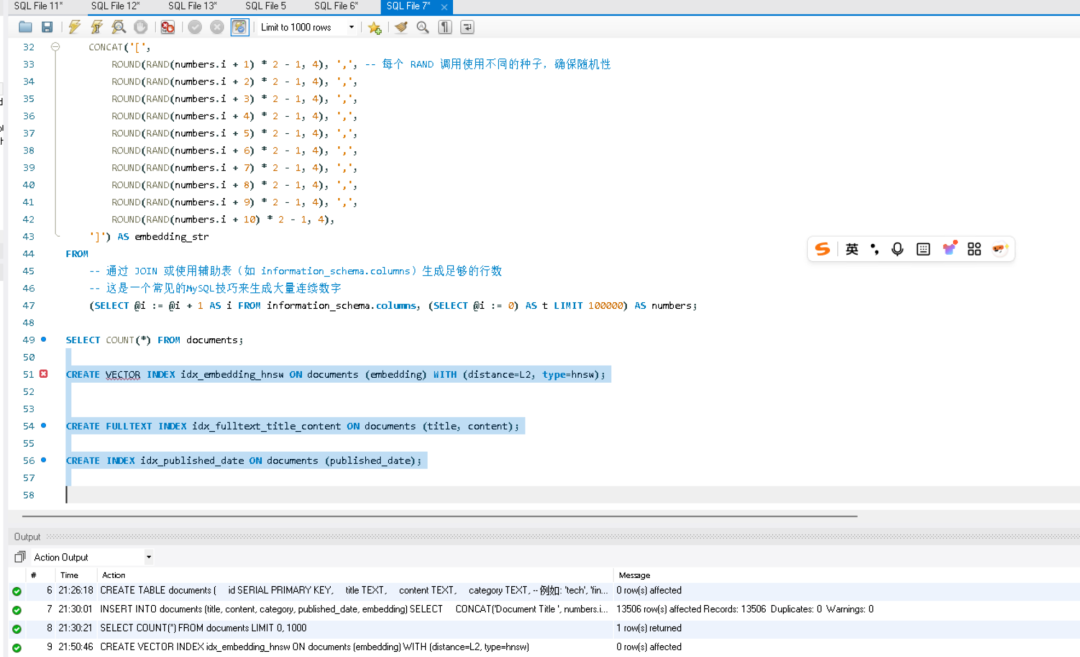
CREATE TABLE documents (
id INT PRIMARY KEY AUTO_INCREMENT,
title TEXT,
content TEXT,
category VARCHAR(50),
published_date TIMESTAMP,
embedding VECTOR(10) -- 10 维向量
);
INSERT INTO documents (title, content, category, published_date, embedding)
SELECT
CONCAT('Document Title ', numbers.i) AS title,
CONCAT('This is the content for document ', numbers.i, '. It covers topics related to ',
CASE numbers.i % 5
WHEN 0 THEN 'technology and innovation.'
WHEN 1 THEN 'financial performance and market analysis.'
WHEN 2 THEN 'marketing strategies and customer engagement.'
WHEN 3 THEN 'legal compliance and regulatory updates.'
ELSE 'human resources management and talent development.'
END) AS content,
CASE numbers.i % 5
WHEN 0 THEN 'tech'
WHEN 1 THEN 'finance'
WHEN 2 THEN 'marketing'
WHEN 3 THEN 'legal'
ELSE 'hr'
END AS category,
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(numbers.i) * 730) DAY) AS published_date, -- 过去两年的随机日期
-- 直接拼接 10 个随机数来构建 10 维向量字符串,避免复杂的子查询
CONCAT('[',
ROUND(RAND(numbers.i + 1) * 2 - 1, 4), ',', -- 每个 RAND 调用使用不同的种子,确保随机性
ROUND(RAND(numbers.i + 2) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 3) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 4) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 5) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 6) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 7) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 8) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 9) * 2 - 1, 4), ',',
ROUND(RAND(numbers.i + 10) * 2 - 1, 4),
']') AS embedding_str
FROM
(SELECT @i := @i + 1 AS i FROM information_schema.columns, (SELECT @i := 0) AS t LIMIT 100000) AS numbers;
创建索引
CREATE VECTOR INDEX idx_embedding_hnsw ON documents (embedding) WITH (distance=L2, type=hnsw);
CREATE FULLTEXT INDEX idx_fulltext_title_content ON documents (title, content);
CREATE INDEX idx_published_date ON documents (published_date);
测试1
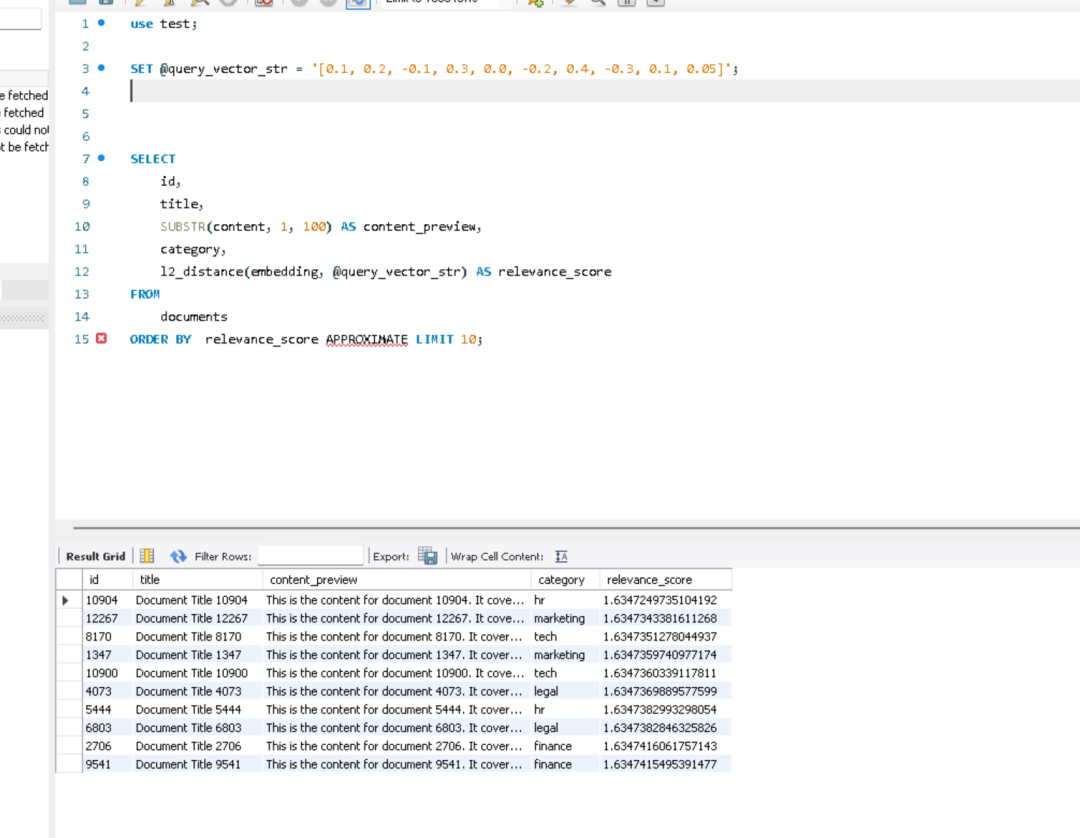
use test;
SET @query_vector_str = '[0.1, 0.2, -0.1, 0.3, 0.0, -0.2, 0.4, -0.3, 0.1, 0.05]';
SELECT
id,
title,
SUBSTR(content, 1, 100) AS content_preview,
category,
l2_distance(embedding, @query_vector_str) AS relevance_score
FROM
documents
ORDER BY relevance_score APPROXIMATE LIMIT 10;
测试2 全文索引查询
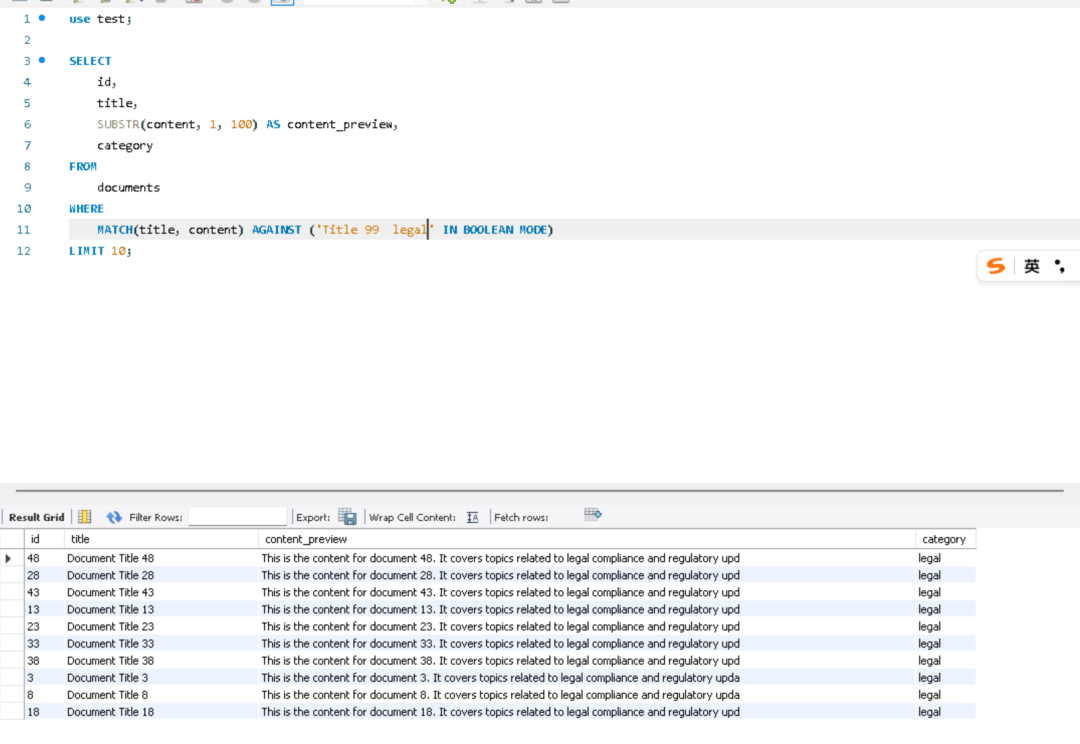
use test;
SELECT
id,
title,
SUBSTR(content, 1, 100) AS content_preview,
category
FROM
documents
WHERE
MATCH(title, content) AGAINST ('Title 99 legal' IN BOOLEAN MODE)
LIMIT 10;
测试 3 向量+全文索引 hybrid search
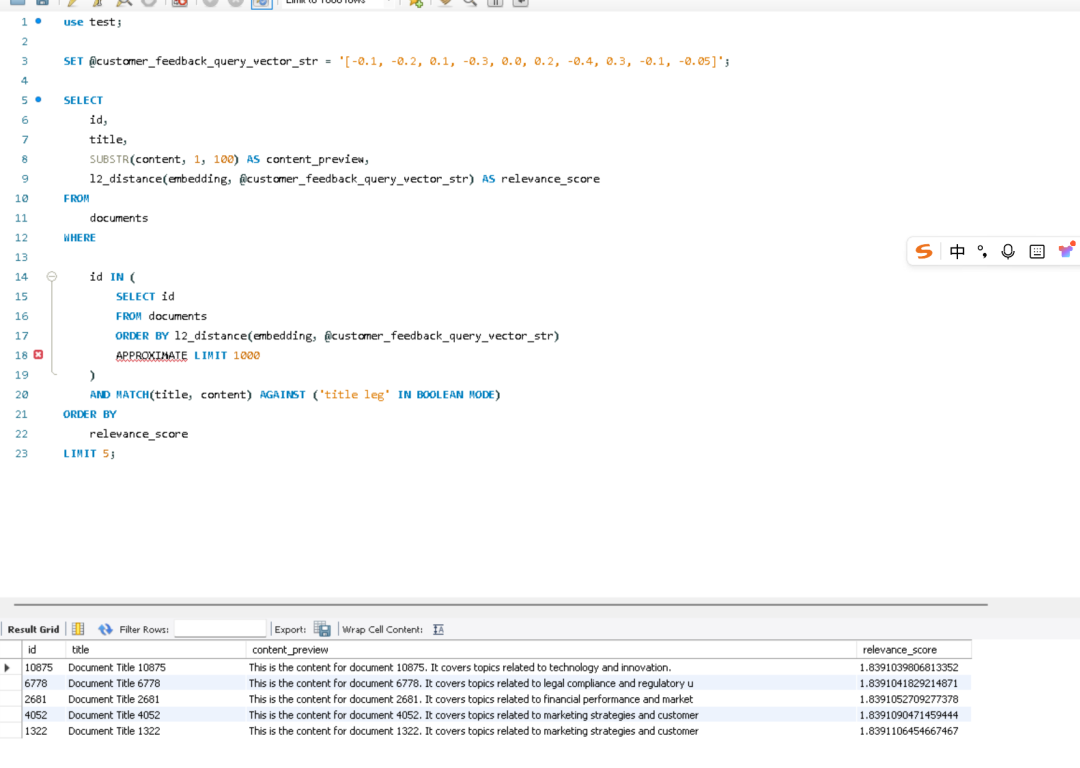
use test;
SET @customer_feedback_query_vector_str = '[-0.1, -0.2, 0.1, -0.3, 0.0, 0.2, -0.4, 0.3, -0.1, -0.05]';
SELECT
id,
title,
SUBSTR(content, 1, 100) AS content_preview,
l2_distance(embedding, @customer_feedback_query_vector_str) AS relevance_score
FROM
documents
WHERE
id IN (
SELECT id
FROM documents
ORDER BY l2_distance(embedding, @customer_feedback_query_vector_str)
APPROXIMATE LIMIT 1000
)
AND MATCH(title, content) AGAINST ('title leg' IN BOOLEAN MODE)
ORDER BY
relevance_score
LIMIT 5;
小结:在进行OceanBase简短的Hybrid search 后,你的公司在云端或是有混合云的打算,且需要Hybrid search能力,但整体的系统希望在兼容MySQL数据库系统上,可以考虑平行迁移到OceanBase MySQL 兼容的云端系统上,因MySQL已经无法再混合搜索,向量搜索再有建树,未来的大量业务将需要向量和hybrid search的能力,如HNSW 等,建议有实力且业务想继续发展的公司可以考虑在往前走一步。
OceanBase MySQL兼容系统,将支持,关系型+向量搜索,支持原生vector数据类型以及HNSW 向量索引,并提供高性能近似最近邻的ANN算法提供相似度查询,
Oracle 2025的"成功",归于转型云厂商,收入增长11%,达到159亿美元
从“小偷”开始,不会从“强盗”结束 -- IvorySQL 2025 PostgreSQL 生态大会
免费PolarDB云原生课程,听课“争”礼品,重塑云上知识,提高专业能力
被骂后的文字--技术人不脱离思维困局,终局是个 “死” ? ! ......
9个群2025上半年总结,OB、PolarDB, DBdoctor、爱可生、pigsty、osyun、工作岗位等
用MySQL 分区表脑子有水!从实例,业务,开发角度分析 PolarDB 使用不会像MySQL那么Low
云数据库产品应改造PostgreSQL逻辑复制槽缺陷--来自真实企业的需求
泉城济南IvorySQL 2025 “雷暴云” 就在云和云原生会场
SQL SERVER 2025发布了, China幸亏有信创!
MongoDB 麻烦专业点,不懂可以问,别这么用行吗 ! --TTL
PostgreSQL 新版本就一定好--由培训现象让我做的实验
删除数据“八扇屏” 之 锦门英豪 --我去-BigData!
写了3750万字的我,在2000字的OB白皮书上了一课--记 《OceanBase 社区版在泛互场景的应用案例研究》
疯狂老DBA 和 年轻“网红” 程序员 --火星撞地球-- 谁也不是怂货
和架构师沟通那种“一坨”的系统,推荐只能是OceanBase,Why ?
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
MongoDB 相关文章
MongoDB “升级项目” 大型连续剧(4)-- 与开发和架构沟通与扫尾
MongoDB “升级项目” 大型连续剧(3)-- 自动校对代码与注意事项
MongoDB “升级项目” 大型连续剧(2)-- 到底谁是"der"
MongoDB “升级项目” 大型连续剧(1)-- 可“生”可不升
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火
PostgreSQL 无服务 Neon and Aurora 新技术下的新经济模式 (翻译)
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
MySQL相关文章

