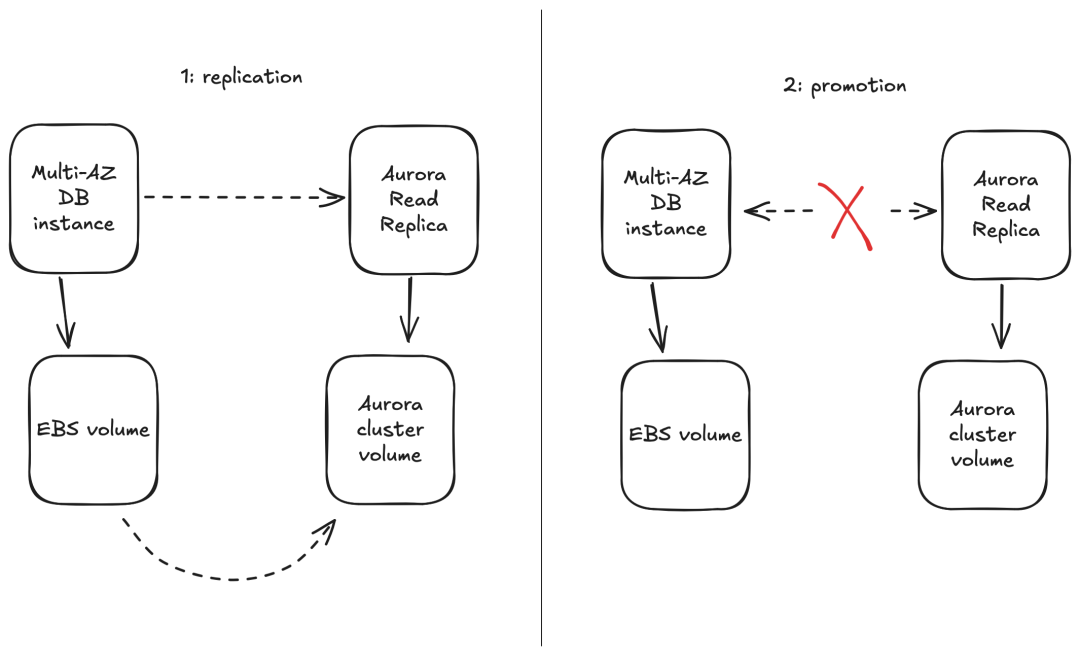
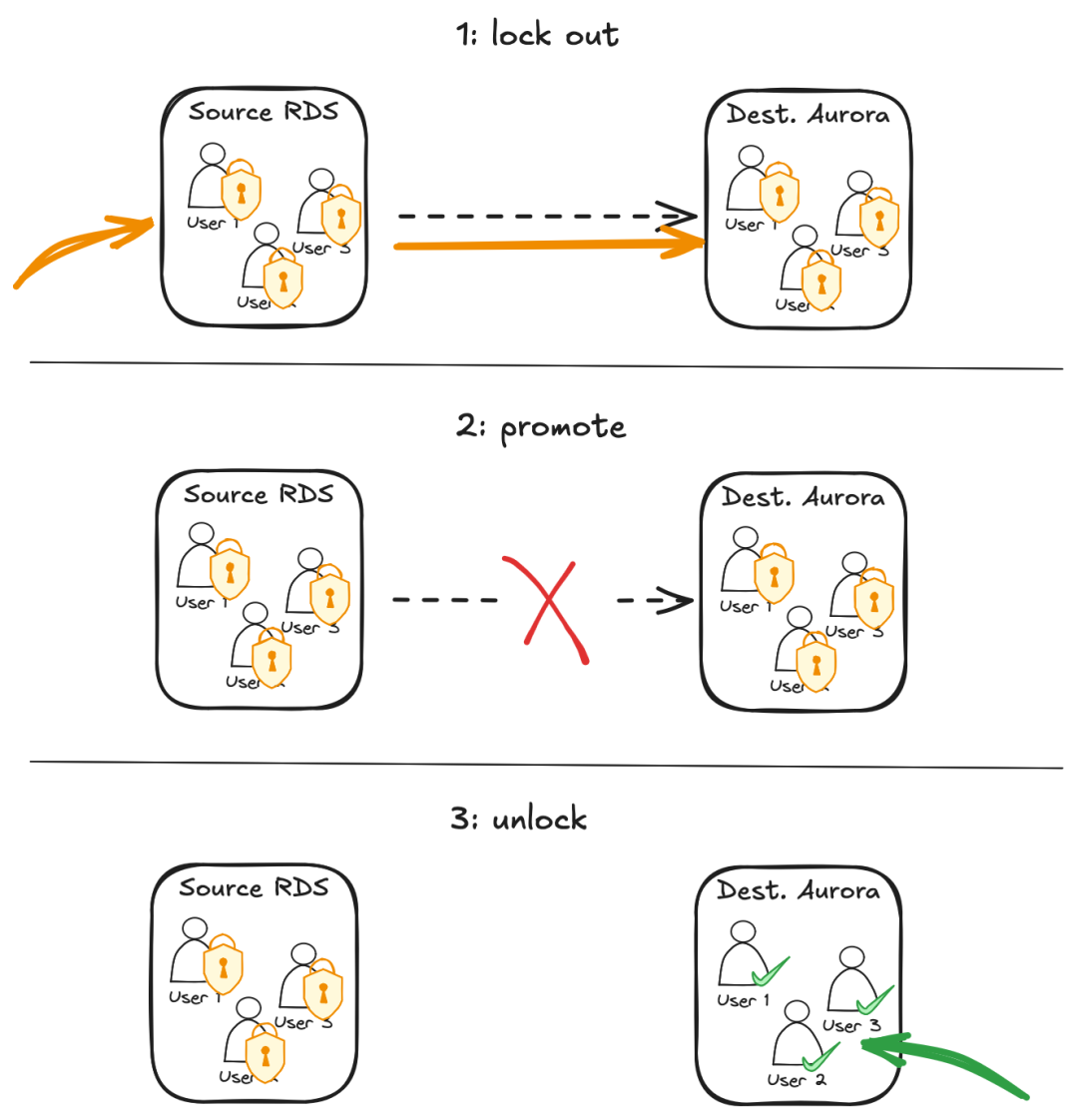
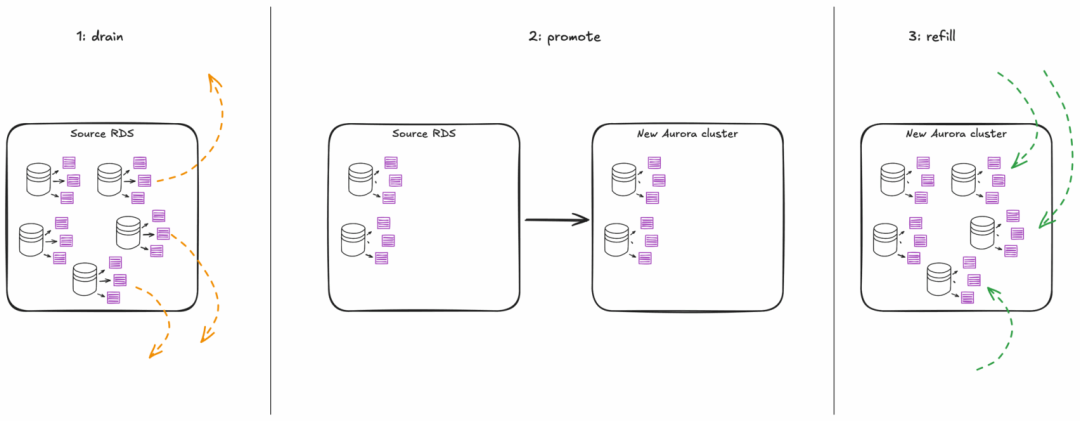
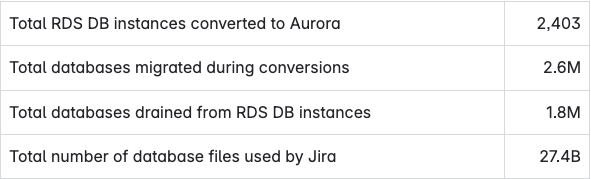
原文地址:https://www.atlassian.com/blog/atlassian-engineering/migrating-jira-database-platform-to-aws-aurora怎样兼顾可靠性、性能和成本效率,以对用户影响小到难以察觉的方式,将四百万个 Jira 数据库迁移至 AWS Aurora?以下是 Atlassian 视角的故事细节与宝贵的经验。在 Atlassian,大规模迁移数据库是日常服务器工作的一部分,保持着 Jira 数据库集群负载的均匀分布。往常平均每天迁移一千个数据库,并不会对客户造成明显的中断。但最近出现了一个新的挑战:Jira 使用 Postgres 数据库存储工单、项目、工作流、自定义字段等所有东西。每个 Jira 租户对应一个数据库,数百万个 Jira 租户就意味着数百万个数据库!选择租户与数据库一一对应这样不常见的架构,是为了在 Atlassian 的大规模下最大化隔离性、可扩展性和操作控制,确保租户的数据不会轻易被另一个租户意外乃至恶意访问;同时可以水平扩展集群、平衡负载,确保规模差异很大的租户都能获得良好的性能。这四百万个数据库分布在全球 13 个 AWS 区域的约 3,000 台 PostgreSQL 服务器上,称作 AWS RDS for PostgreSQL 或 AWS Aurora PostgreSQL 实例。在 Jira 数据库实例集群中迁移数据库,是定期对服务器进行负载均衡的一环。有两种方法执行这些迁移:小型数据库备份后在目标实例上快速恢复;大型数据库则在源实例和目标实例间设置目标数据库的逻辑复制,以在数据库及其租户继续正常运行的同时花时间复制数据。平均每天有一千个数据库迁移,对客户的影响甚微。数据库及其主机实例依据 AWS Well-Architected Framework 所称的 bridge model 而分离:绝大多数租户位于共享基础设施上,少数极大的租户位于专用基础设施上。这些极大的租户需要大量资源,超出了通过 RDS 实例可提供的上限,因此多年来一直被部署在 Aurora PostgreSQL。2023 年底,Jira 数据库集群的其余部分也被尝试重新部署到 Aurora PostgreSQL,以期达到一些大胆的成本、可靠性和性能指标。由于 RDS 配置下一次只能使用一个实例,而在 Aurora 上可以同时访问写入器和读取器实例(如有必要,可以多个读取器),笼统地说,两倍的实例意味着实例大小可以减少一半,更加有效!重新部署后,还能享受 Aurora 更好的 SLA(99.99% 而不是 99.95%),而且峰值负载期间能自动扩展至多 15 个读取器(有时候真的会需要这么多)。鉴于这许多好处,重新部署的工作被积极推进了。除了有期望的结果和一个可循的目标外,还有几个支线目标:2. 通过控制与迁移相关的基础设施数量来最小化成本考虑到这些,最佳方法是,对于每个要迁移到 Aurora 的 RDS PostgreSQL Multi-AZ DB 实例:1. 向实例添加一个数据库实例读取副本,并允许副本将底层数据同步到新的 Aurora 集群卷;这个功能是 RDS 的标准产品。2. 通过将新的读取副本升格为独立的 Aurora 集群,在合适的时间窗口执行切换。这个将 RDS 实例转换为 Aurora 集群的过程,乍一看像是教科书式的方法,但在 Atlassian 的规模下存在复杂性。首先,每个集群最多托管约 4,000 个数据库,每个数据库唯一对应一个 Jira 租户。要升格到新的独立 Aurora 集群,就需要为所有 4,000 个有自己唯一连接端点和凭据的租户统一执行该切换。需要更新运行在 EC2 实例上、连接到这些数据库后端的 Jira 应用程序,以便为每个租户提供新独立集群的新连接端点,并确保不会意外写入错误的(旧的)数据库。为此,切换过程锁定了源数据库实例上的每个 SQL 用户,完成升格到单独集群的操作,然后仅在目标集群解锁所有 SQL 用户。所有这些都通过 AWS Step Function 进行编排,该函数在转换前、期间和之后执行大量安全检查,一旦出现问题就会安全地返回到标准操作。转换完成后数小时内的客户流量将显示是否一切正常。一切准备就绪时,feature flag 立即强制覆盖应用服务器上租户的数据库端点。这样相比于通常的缓慢定期刷新,能实现真正的快速切换;加之初始同步过程能够提前执行,实际切换时间可以被限制在每个不到 3 分钟:即使需要转换的最大实例也完全在 SLA 范围内。太棒了!构建和测试阶段很顺利,没有任何重大麻烦。直到有一天,AWS 的支持团队收到警报,有一个正在同步准备转换的大型 RDS 测试实例,同步已完成但新集群启动失败。AWS console 仍将这个失败的副本实例显示为健康的、复制中的实例,但 AWS control plane 检测到该实例的启动过程已超时。当时尚未明确的超时原因,是源 RDS 数据库实例上有太多文件(因此新目标 Aurora 集群卷上也有太多文件),新的读取副本实例执行枚举所有这些文件的状态检查,因此超时了。文件越多,过程就越长,达到这个启动超时阈值的可能性就越高。而我们有数百万个文件!在 Postgres 中,每个高级数据库对象(如表、索引和序列)都至少存储在磁盘上的一个文件中。数据库 schema 中的表、索引和序列越多,磁盘上的文件就越多。Jira 有大量这样的高级数据库对象,一个 Jira 数据库需要磁盘上约 5,000 个文件。在 Jira 数据库实例上共同托管的大量数据库,导致最终新的 Aurora 集群卷上所创建的文件数量远超任何其他 AWS 客户通常会创建的数量。因此,即使没用完 Aurora 集群卷上可用的全部巨大空间,要是继续以目前的方式安全转换集群,仍然触及了某种边界。AWS 的建议是:要执行安全的 RDS->Aurora 转换,就需要大幅减少 RDS 实例上的文件数量。减少集群卷上文件数量的唯一方法是减少每个数据库的文件数量,或减少给定实例上的数据库数量。前者是不可能的(毕竟需要实际存储租户的表),所以唯一可行的路径是减少要转换的实例上的租户数量,我们称之为「排空」。
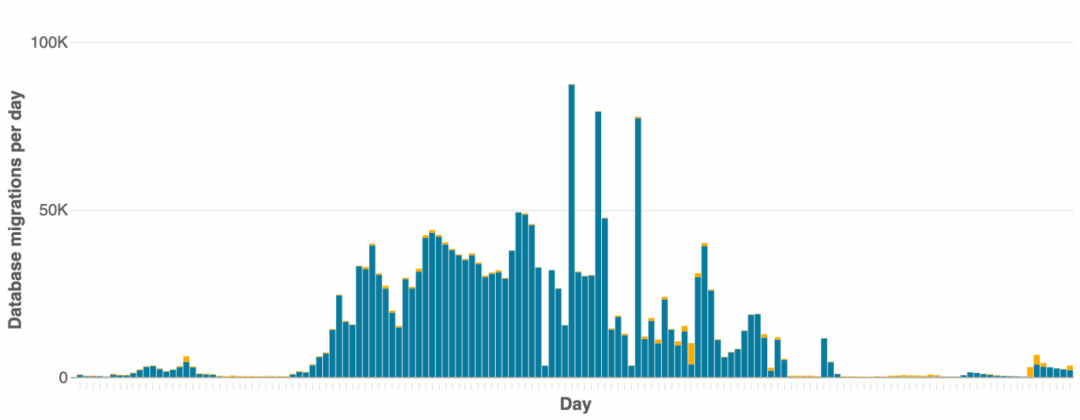
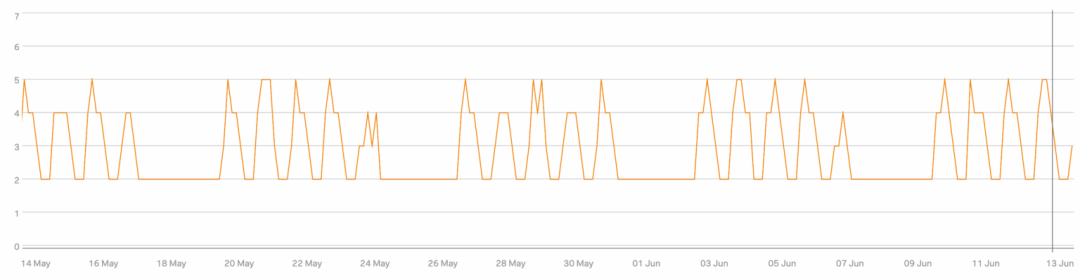
AWS 还表示,一旦 RDS 实例成功转换为 Aurora 集群,就可以再次开始用租户数据库自由填充。这对最小化与迁移相关的基础设施很重要:在集群中只配置足以容纳转换中租户的容量,转换完成后在另一边重新填充它们。3. 从下一个正在排空的实例迁移的租户,将这个新集群作为目标并重新填充这种方法有效地在迁移期间保持了较低的多余基础设施开销。我们按照 AWS 的建议构建了一个更强大的工具来编排日常数据库迁移。我们需要移动数百万个数据库,足以达到文件数量限制,而且不想浪费时间。我们分析了租户分布,优先考虑使用量最少的小租户,以减少需要迁移的数据量(从而增加吞吐量)。新的工具在高峰期平均每天迁移 38,000 个,峰值接近 90,000。相比通常的 1,000 个,这是一个巨大的规模扩展,同时仍然满足我们的高可靠性目标!如果 RDS DB 实例被排空时触及文件数量阈值,就会转移到其他目标;已排空的实例,准备启动数据同步并等待合适的转换期。转换后,源 RDS DB 实例在短暂的安全期后会被自动清理。一旦建立了转换和排空机制,整个流程就只是运转良好的大型数字游戏。源并发数是每个 RDS 实例允许的并行出站数据库迁移数量,目标并发数是每个 Aurora 集群允许的入站迁移数量;控制这两种类型的并发是确保正常迁移的关键。排空吞吐量很大程度上取决于给定区域中有多少个 Aurora 集群。过度增加目标并发性,将远在触及源并发性的限制之前就大幅影响目标集群的性能。由于给定的 Aurora 目标集群吞吐量有上限,为了提高整体吞吐量,就应该有更多的 Aurora 集群。最终,必须在每个区域迁移所需的额外基础设施数量(及成本)与对每个区域所需时间的容忍度之间找到平衡。为了保持吞吐量和简洁性,就需要确保良好的纪律,尽快将已排空的 RDS 实例转换为 Aurora 集群,从而使它们可用作从其他 RDS 实例排空的目标。我们基于实际情况的滑动窗口预测每日目标,根据需要进行调整,最终提前完成了项目!我们按时完成了迁移目标,这给了我们什么启发?分享一个数据点:注意到,我们的 Aurora 集群实例数量几乎是 RDS 数据库实例的三倍;为什么?答案是通过 Aurora,我们能够将实例类大小减少一半,并且仍然获得性能更好的数据库实例。我们的标准实例大小从 RDS 上的 m5.4xlarge 降到了 Aurora 上的 r6.2xlarge:我们保持了相同的内存大小,但减少了 CPU 的数量(和类型)。这种 CPU 的损失重要吗?其实不太重要。回想 Aurora 集群中可以使用所有实例,旧 RDS 配置中则仅使用主实例;会发现实际上 CPU 数量并未缩减,扩展期间反而可能更多!也就是说,高峰时段集群会扩展;非高峰时段则会收缩并大大减少实例占用。图为典型 Jira Aurora 集群中随时间变化的实例数量,其中峰值对应本地工作时间,低谷对应非高峰时段。尽管道阻且长,我们还是实现了艰巨的的成本节约目标,并在此过程中提高了可靠性和性能。这对 Atlassian 的数据库来说是一个巨大的胜利!
Bytebase 3.8.0 - 显著优化 schema 同步/回滚兼容性
活久见,PlanetScale 拥抱 Postgres 了
那些我很希望 MySQL 有,但 Postgres 已经有的功能
开发者前沿 #11|亲眼目睹惠普在 49 天内葬送 12 亿美元收购的 Palm