




大数据项目对接交付过程中,经常遇到客户业务数据架构需要用到Flink消费消息队列写入到HBase集群。但是,Flink官方只提供了Table API级别HBase连接器,并没有DataStream API级别的HBase连接器,官方文档:
部分客户参考Table级别实现过DataStream级别HBaseSink,因为原生Table级别连接器自身实现问题,其实效果并不是很理想。本文从HBase源码入手,结合Flink自定义算子实现方式,总结三种常见HBaseSink实现方案。文章首发微信公众号:大数据从业者,其它均为转载,欢迎您点赞关注推荐转发,谢谢!
方案1:原生HBaseSinkFunction
Table级别连接器提供了原生HBaseSinkFunction实现类,可以直接拿到自己项目DataStream使用。该sink类使用BufferedMutator接口/BufferedMutatorImpl实现类,支持定时定量触发写数据到HBase。其中定时是通过open方法启动的ScheduledExecutorService线程池周期触发,之所以这么做的原因是因为早期HBase1.x版本BufferedMutator只支持定量触发还不支持定时触发。
该方案的实现示例为入口主类Kafka2HBase、HBaseSinkFunction实现类,完整代码见github:
https://github.com/felixzh2020/felixzh-flink/blob/master/Kafka2HBase/src/main/java/Kafka2HBase.javahttps://github.com/felixzh2020/felixzh-flink/blob/master/Kafka2HBase/src/main/java/HBaseSinkFunction.java
编译打包之后,执行命令:
flink run -t yarn-per-job -c Kafka2HBase -d Kafka2HBase-1.0.jar Kafka2HBase.properties
方案2:BufferedMutator
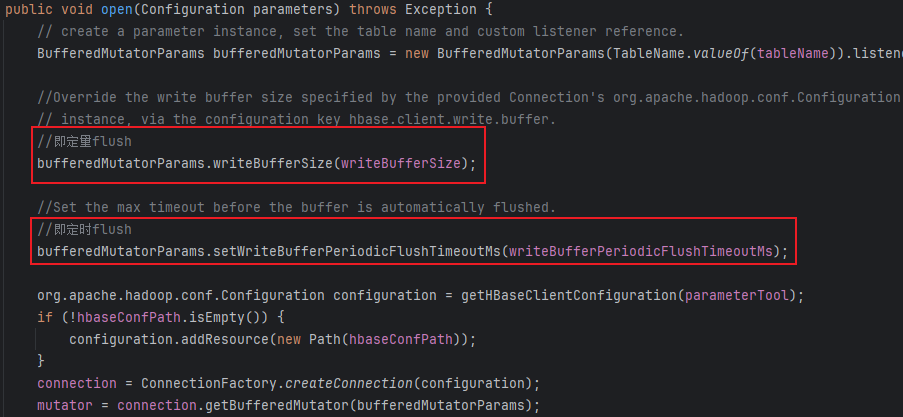
与方案1类似,有些许差别,同样基于BufferedMutator,定时定量的设置方式通过BufferedMutatorParams设置,使用示例代码如图所示:
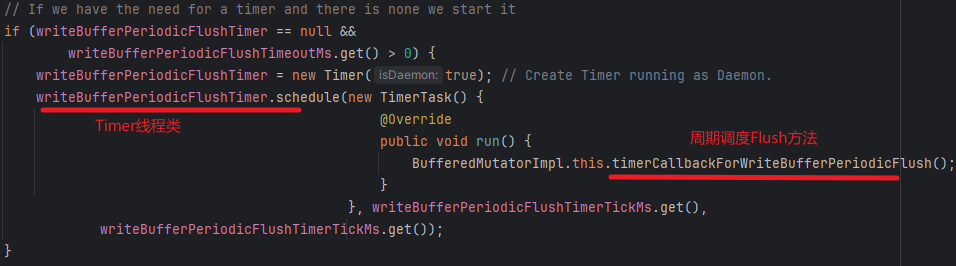
但是定时触发通过BufferedMutatorImpl内置的Timer类型线程writeBufferPeriodicFlushTimer周期调度timerCallbackForWriteBufferPeriodicFlush方法实现,该方法内部调用doFlush(true)强制触发写HBase,相关源码如图所示:
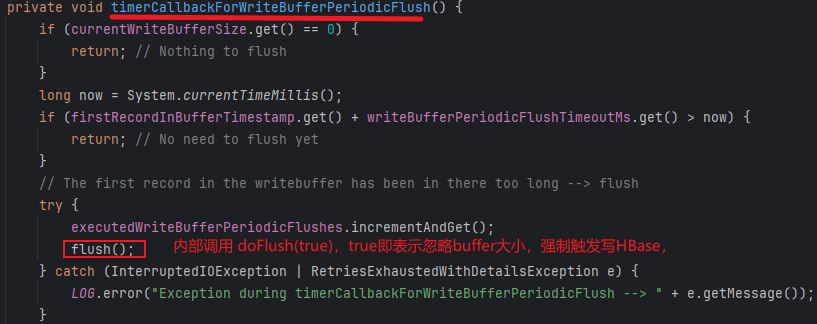
而定量触发就是mutate方法中调用doFlush(false)内部通过判断是否达到buffer大小,以决定是否触发写HBase。而最终定时定量触发机制都通过构建AsyncProcessTask任务,然后同步阻塞等待结果来实现,相关核心源码如图所示:
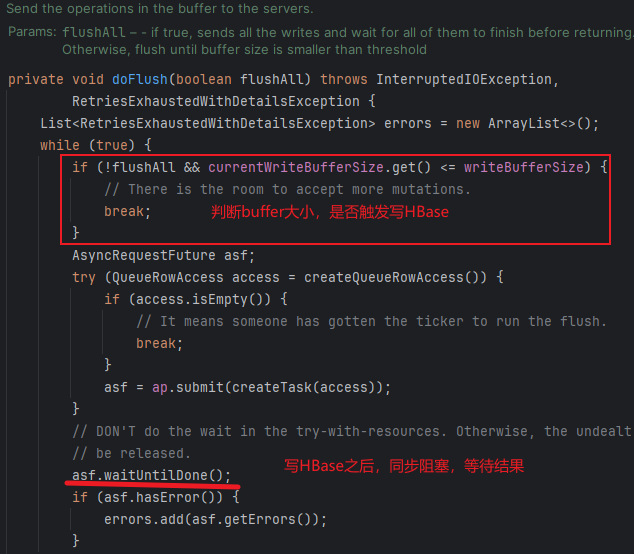
该方案的实现示例为入口主类Kafka2HBaseV2、HbaseSinkFunctionV2实现类,完整代码见github:
https://github.com/felixzh2020/felixzh-flink/blob/master/Kafka2HBase/src/main/java/Kafka2HBaseV2.javahttps://github.com/felixzh2020/felixzh-flink/blob/master/Kafka2HBase/src/main/java/HBaseSinkFunctionV2.java
编译打包之后,执行命令:
flink run -t yarn-per-job -c Kafka2HBaseV2 -d Kafka2HBase-1.0.jar Kafka2HBaseV2.properties
方案3:AsyncBufferedMutator
相比于方案1和方案2的同步阻塞方式写HBase,该方案采用异常非阻塞方式写HBase,具体实现基于AsyncBufferedMutator接口、AsyncBufferedMutatorImpl实现类。同样支持定时定量触发写HBase,定时不再使用JDK Timer线程类而是基于Netty内置HashedWheelTimer线程类实现。定时定量的判断逻辑都在mutate方法中,然后通过调用internalFlush方法触发写HBase,相关源码如图所示:
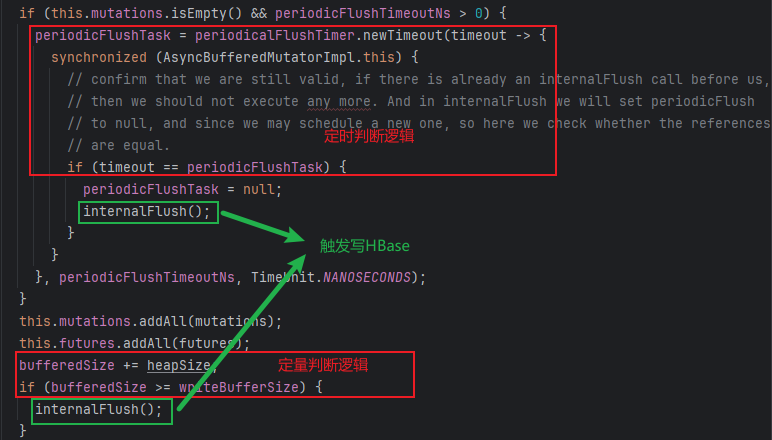
定时定量触发都通过AsyncTable接口类AsyncTableImpl实现类的batch方法批量异常非阻塞写HBase,相关源码如下:
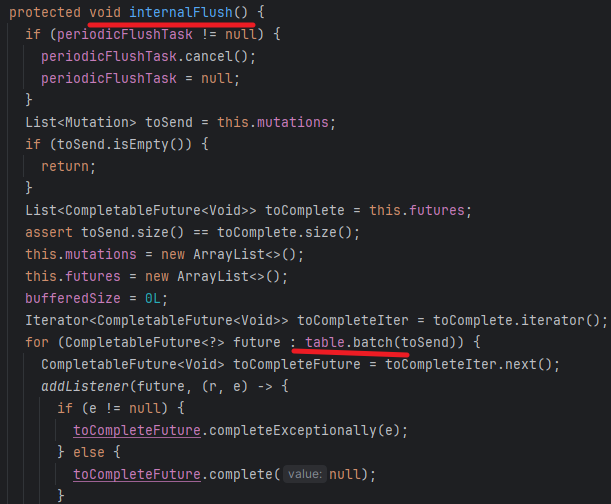
该方案的实现示例为入口主类Kafka2HBaseV3、HbaseSinkFunctionV3实现类,完整代码见github:
https://github.com/felixzh2020/felixzh-flink/blob/master/Kafka2HBase/src/main/java/Kafka2HBaseV3.javahttps://github.com/felixzh2020/felixzh-flink/blob/master/Kafka2HBase/src/main/java/HBaseSinkFunctionV3.java
编译打包之后,执行命令:
flink run -t yarn-per-job -c Kafka2HBaseV3 -d Kafka2HBase-1.0.jar Kafka2HBaseV3.properties
结束语
本文从HBase源码入手,结合Flink自定义算子实现方式,总结三种常见HBaseSink实现方案。文章首发微信公众号:大数据从业者,其它均为转载,欢迎您点赞关注推荐转发,谢谢!
