




作者:吴文超 Shopee 大数据工程师
导读:
本文整理自 Shopee 公司 Data Infra 实时团队吴文超的技术分享,介绍了 Paimon 数据湖技术在 Shopee 的实践经验,包含与 StarRocks 结合后的应用成效。
Shopee 通过 Paimon + StarRocks 构建了准实时数仓,并在对账系统中进一步探索将 StarRocks 作为查询引擎,直接查询 Paimon 宽表,为对账平台提供实时结果。
文章内容涵盖关键使用场景、架构设计与演进、落地过程中的挑战应对及未来规划。
一、Paimon 使用场景概览
目前 Paimon 在 Shopee 的使用场景主要有以下三个方面:
基于 Paimon 和 StarRocks 构建准实时数仓。
Partial Update 应用:使用 Paimon 的 Partial Update 引擎替换双流 Join。传统双流 Join 需要保存大状态并消耗较多资源来保证匹配率,而使用 Paimon 的 Partial Update 可以省略 Join 过程,直接在数据落地时完成 Join 工作。
ODS 层升级加速:基于 Paimon 的日切功能来升级和加速已有 ODS 层,提高数据链路的时效性并优化存储空间。
二、准实时数仓搭建
任务诊断系统
首先要介绍的场景是基于 Paimon 搭建任务诊断准实时链路,该链路主要为 Flink 实时平台的所有任务提供诊断功能,在平台页面展示任务的背压、资源使用、延迟等情况,帮助用户直观判断任务状态。
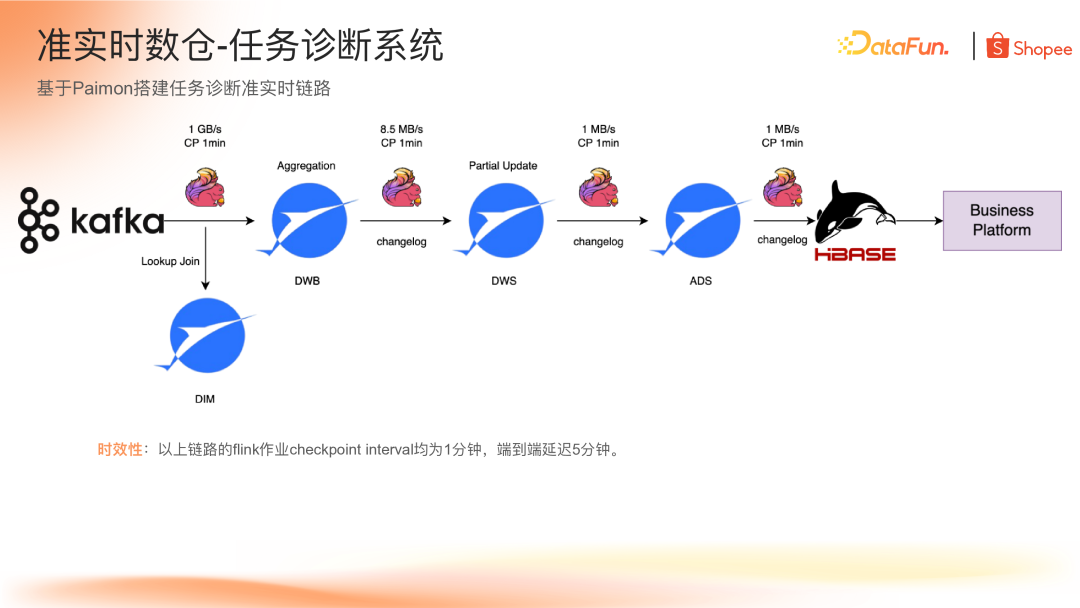
包括维表在内整个链路都是基于 Paimon 构建,利用 Paimon 原生支持的 Lookup Join 功能以及可配置的缓存更新时间构建维表。由于业务系统主要是点查需求,最终数据落到 HBase,为平台提供点查能力。同时可以看到图中 Paimon 表之间是基于 Changelog 来传递更新的。在此场景下,Paimon 的 Changelog 的 Producer 为 Full-Compaction,因为从每个层级我们只需要获取到最新的数据变化就可以了。通过 Changelog 的配置,可以达到流量收敛的效果。
上图中可以看到,每个层级的流量都在递减,整个链路中每个 Flink 作业的 checkpoint 周期都是 1 分钟,端到端的延迟大概在 5 分钟,能够满足前端页面展示的需求。接下来,详细介绍每个流程都是基于 Paimon 的哪些能力去构建的。
(1)消费 Kafka 创建 DWB 表
在 DWB 层中,将所有 Flink 任务的 metrics 数据上报到 Kafka,然后消费 Kafka 数据并 Lookup Join 到 Paimon 维表。由于同一个 Application 的指标非常多,且不同 Application 之间指标类型不一样,需要将一个 Application 的所有指标汇集到一条数据写成一张大宽表。
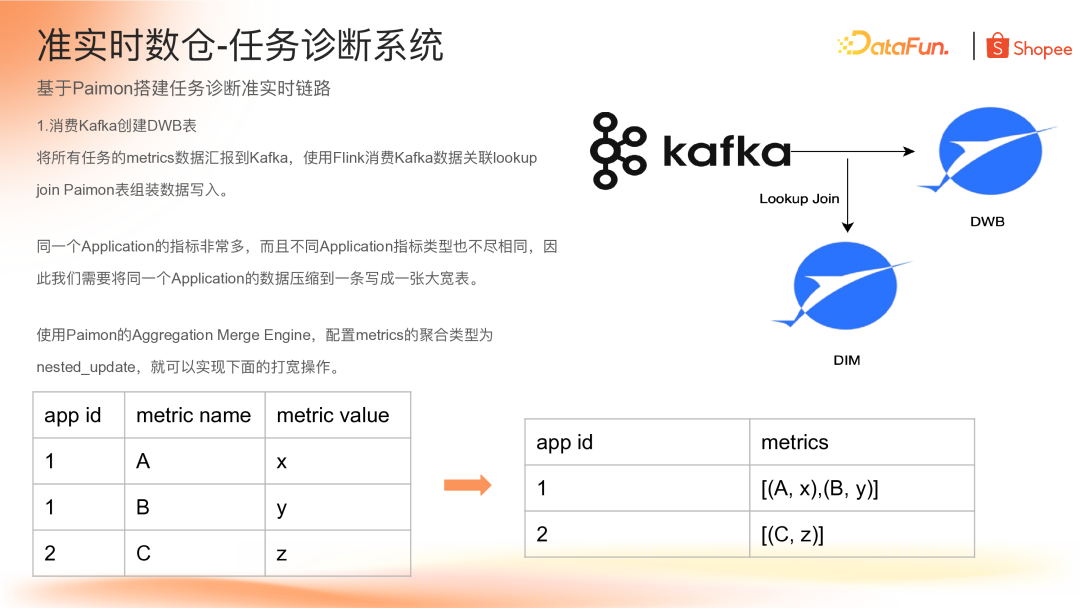
为了实现这一效果,我们使用了 Paimon 的 Aggregation Merge 引擎,可以将同一主键的字段进行聚合。聚合函数使用了 nested_update,将同一个 Application 的 metrics 字段合并到一个 Rowkind 类型数组中。同时这一层也用到了 Paimon 的 Lookup Join 功能,DIM 表是直接使用 Flink 消费 binlog 来落的一张维表,配置 5 分钟的刷新时间,从而能够实现将数据关联写到 DWB 层。
(2)消费 DWB Changelog 构建 DWS 表
DWS 层需要将 Application 的指标按不同维度分析,例如将 connector 和 system 的相关指标分别抽取出来进行计算,最后写入同一张 Paimon 表。
在设计 DWS 层时,使用了 Paimon 的 Partial Update 合并引擎,可以实现将同一个主键保留字段的最后一个非空值。通过此功能,将拆分后的 metrics 再 union 起来,直接写入 Paimon 表即可实现关联。
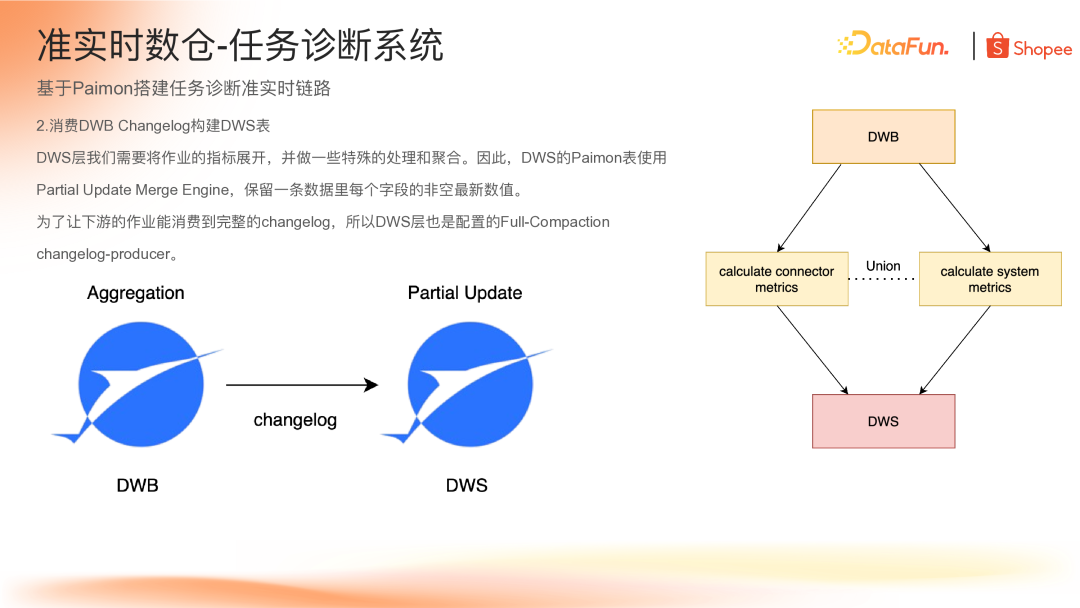
为了让下游能消费到两次 commit 之间的变化数据,DWS 层配置 Changelog Producer 为 Full-Compaction。
(3)消费 DWS Changelog 构建 ADS 表
在 ADS 层,需要将 DWS 层中每个 Application 的 metrics 指标提取出来,根据业务为指标设置的不同属性(如延迟、GC、资源使用、背压等)计算健康分,结果写入 ADS 层,最后通过 Flink 导入 HBase 供业务系统查询。
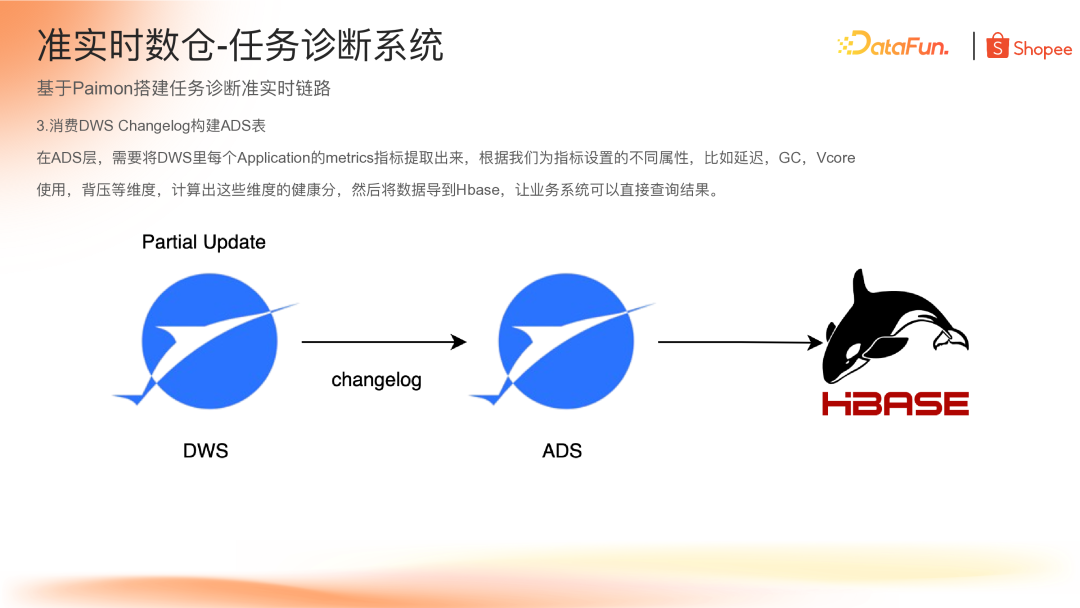
整个准实时任务诊断链路的端到端延迟约 5 分钟,通过 Paimon 的各种特性实现了数据收敛。
对账系统
第二个场景是基于 Paimon + StarRocks 构建的对账系统,用于业务金额对比。用户原有的数据链路虽然能保障时效和查询速度,但存在两个问题:
烟囱式开发导致大量重复功能和代码
缺乏数据资产积累,无法灵活计算更多指标
因此,尝试使用 Paimon + StarRocks 搭建对账系统,使用 StarRocks 查询引擎直接查询 Paimon 宽表,为对账平台提供实时结果。

该链路的关键步骤包括:
使用 Flink 实时消费 binlog,清洗后写入 ODS 层表。为保证 Kafka 数据正常消费,Paimon 的 bucket 数量与 Kafka 分区数一致。
通过 Flink 流任务处理 ODS 表中的增量数据,关联 ODS 表组装数据写入 DWM 层。由于业务场景特殊,无法直接使用 Partial Update,而是使用传统的双流 Join。为节省计算资源,设置 TTL 为一天,来保证两天的数据新鲜度。
使用 Flink 批作业检查历史数据是否有遗漏。考虑到窗口机制可能导致延迟数据丢失的情况,在 ODS 层到 DWM 层、DWM 层到 DWS 层的数据流中,分别部署 Flink 批处理作业,检查过去一年的数据是否有遗漏,并自动将缺失数据补录至对应的表中,以此保障 DWM 层与 DWS 层数据始终处于最新状态。
在 StarRocks 中挂载 Paimon Catalog,直接查询 Paimon 表。StarRocks3.3 版本后支持基于 Paimon 表构建物化视图,进一步提升查询速度。
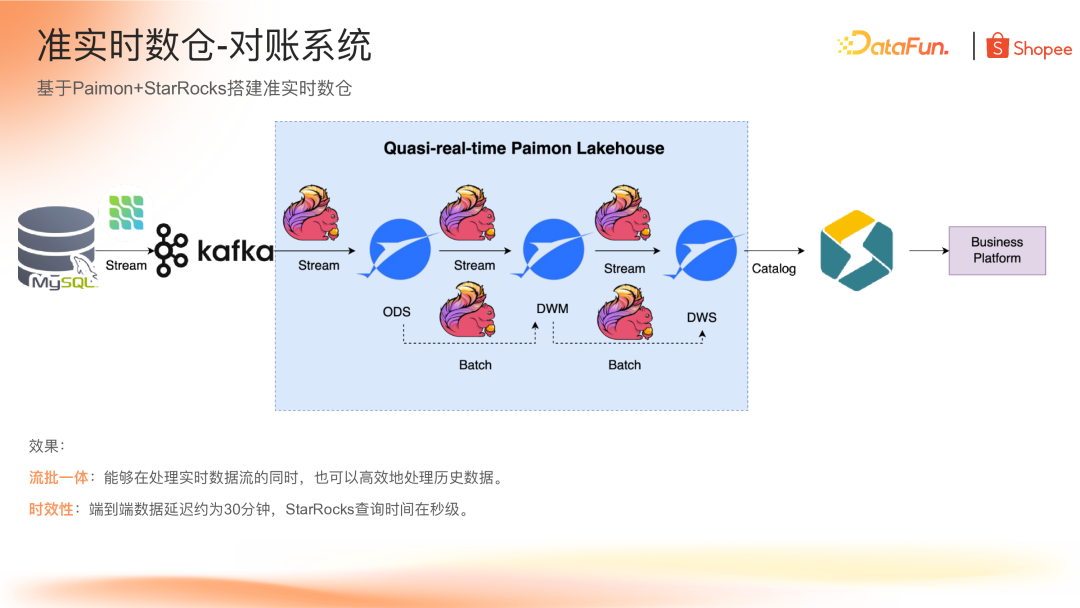
该方案通过 Flink 流批一体架构构建实时数仓,实现了端到端约 30 分钟的延迟以及 StarRocks 秒级查询响应,帮助业务积累了准实时数仓建设经验和数据资产,避免烟囱式开发的同时提升了开发效率。
三、ODS 层升级加速
现有 ODS 层构建的挑战
当前业务生成 ODS 层表时有两个主要要求:
按数据时间保留每天的数据切片
迟到数据需补充到对应数据切片
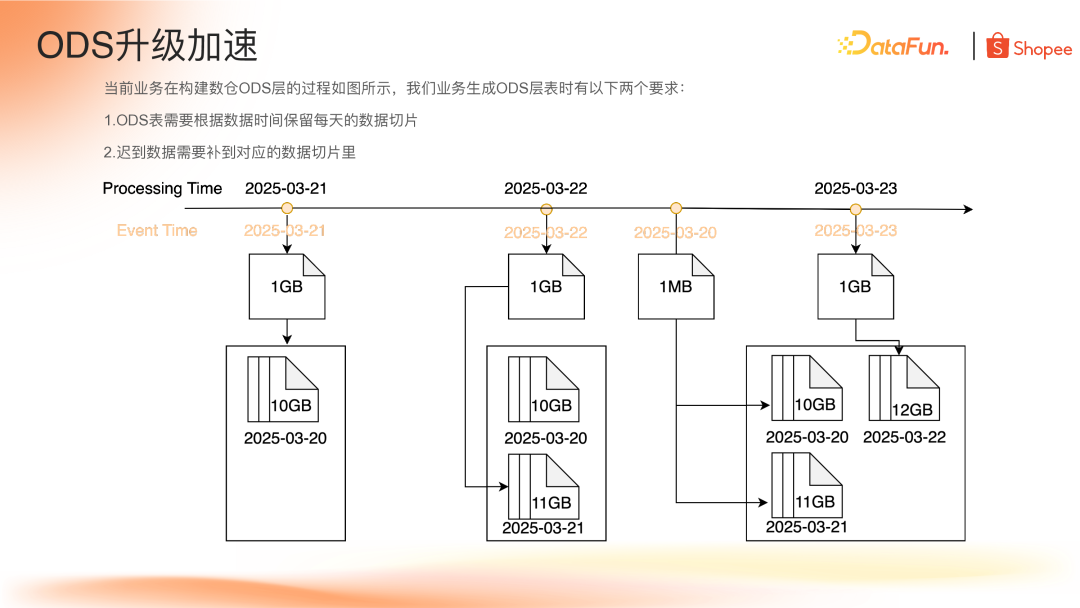
在这些要求下,业务面临两个主要问题:
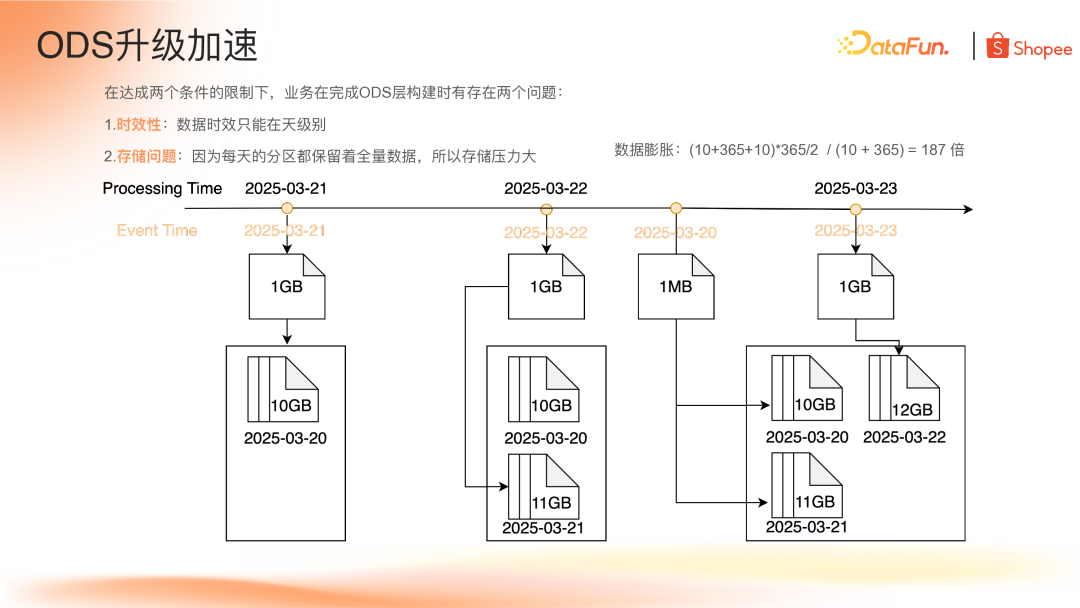
(1)时效性问题:数据只能在天级别调度;
(2)存储问题:每天分区需保留全量数据,存储压力大(计算表明,保留一年分区的数据膨胀率达 187 倍)。此外,批任务合并增量数据到老分区也会增加计算资源消耗。
Paimon 解决方案
针对上述两个问题,Paimon 的存储和 Branch 特性提供了对应的解决方案。
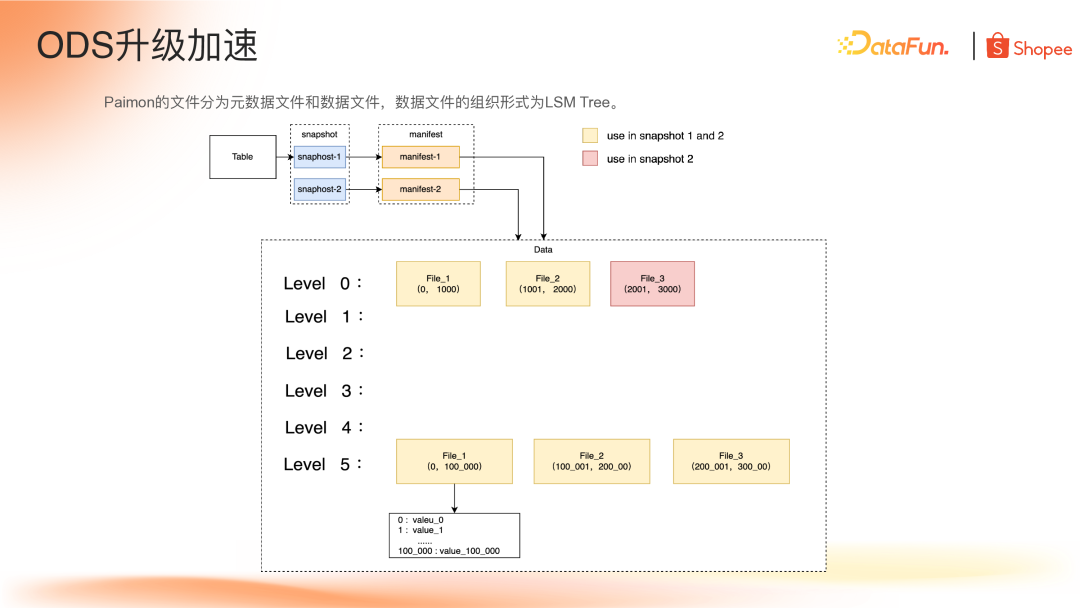
(1)文件结构特性
Paimon 文件分为三类:Snapshot 文件、Manifest 文件和 Data 文件。文件结构为 LSM Tree,其特点为增量数据只会在 level0 层增加,新数据会通过一定的合并策略(如对比数据量、对比层级之间的数据)来决定上层的文件合并到哪一层,这种结构使得不同 Snapshot 之间共享大量数据文件,如下图 snapshot2 和对比增加了一个 level0 文件,其余 5 个文件都是和 snapshot1 共享的,正式由于 Paimon 天然的 Snapshot 和 LSM Tree 结构,有效地解决了保留全量数据切片导致的数据冗余问题。
(2)Branch 功能
Paimon 在 0.9 版本推出 Branch 功能,基于现有 Tag 和 Snapshot 生成依附于主表的分支表。虽然 Branch 表和分支表都在同一个命名空间,但是用户可依对其进行独立的读写操作,共享底层数据文件。
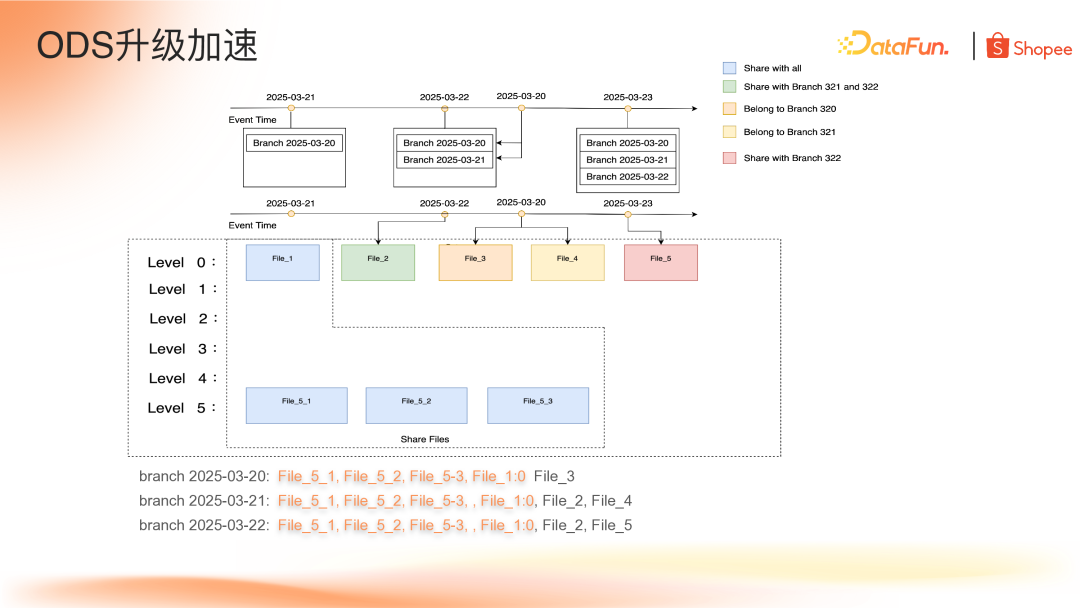
如上图所示,创建 Branch Table 表实际上是将 Paimon 的 Snapshot 和 Schema 文件拷贝一份到 branch 的目录下。因为 Paimon 的元数据组织管理是依赖 Snapshot 文件,所以基于 Snapshot 单独的命名空间与主表做一个数据隔离的读写操作。
Shopee 的工作
(1)日切功能实现
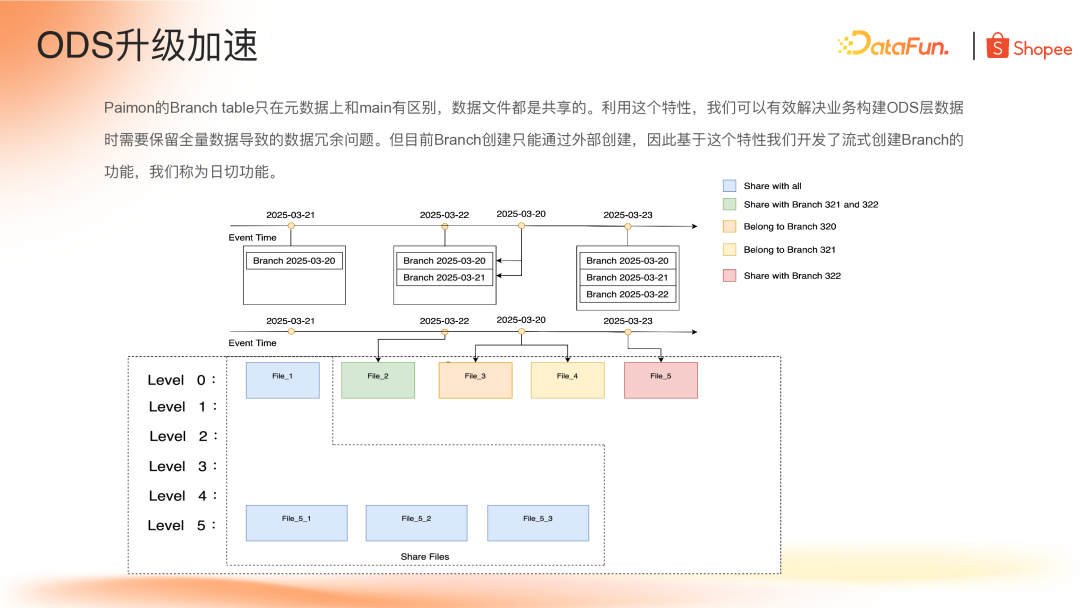
基于这些特性我们可以解决构建 ODS 层的数据冗余问题,但是目前 Branch 只能通过外部去调用 action 构建,于是基于当前的 Branch 特性 Shopee 开发了流式 Branch 功能,称为"日切功能",实现了根据事件时间创建数据切片,根据事件时间选择对应切片回填迟到数据,所有功能在一个实时任务中完成。
如下图,当前时间 3 月 21 日,流任务会创建出 3 月 20 日的 Branch,蓝色部分的文件对应 3 月 20 日分支的数据,同时也是主表的数据。当时间到了 3 月 22 日,类似地,流任务会创建 3 月 21 日的分支。假设 3 月 22 日只增加了 File_2 文件(绿色部分),这个文件作为 3 月 21 日分支的文件;假设当天有 3 月 20 日迟到的数据,在同一个流任务里检测到这部分数据,会将这部分数据单独地回填到 3 月 20 日分支和 3 月 21 日分支对应的文件,如前面提到 Paimon 的 Branch 可以单独的读取数据。3 月 23 日,流任务会生成 3 月 22 的 Branch。
(2)实验分析
开发日切功能过程中进行了一项对比实验,计算 Paimon 运行 100 天之后的数据与 Hive 表的节省率。实验的前置条件是:
Paimon 表初始数据为 0,从 0 开始写;
使用 Fixed-Bucket 分桶;
数据写入都是 Insert 操作,且无重复,每天的数据量恒定;
Flink的checkpoint 的周期设置为 10 分钟;
从 0 开始跑 100 天,创建 100 天的日切(日切包含的文件锁住不能删)。
实验分析可见,在跑到 80 天之后,数据节省率可以达到 90%,通过前面对 Paimon 文件结构的了解,如果数据写入都是 Insert 操作,底层数据文件基本不会变化,只有当数据有 overlap 时,底层文件才会被选出来 rewrite。
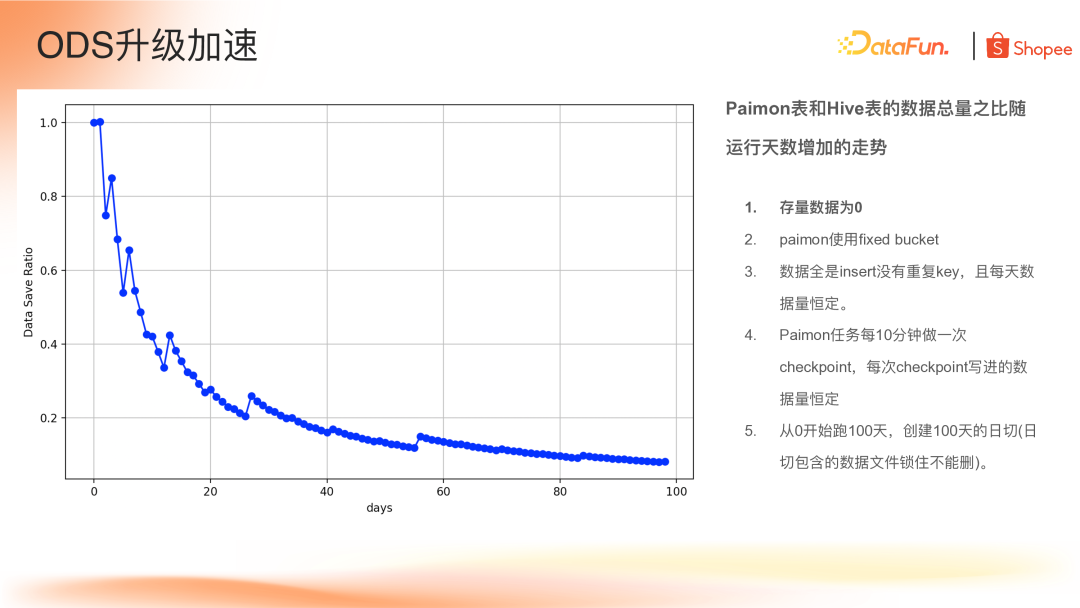
用 Paimon 来替换传统的 Hive 构建 ODS 层之后,首先是从批任务转为流任务,时效从天级降至分钟级;然后从存储上看,Paimon 能够节约高达 95% 的存储空间。
(3)新老链路丝滑切换
在 Paimon 日切功能的支持下,在一个实时任务里面,同时支持根据事件时间来创建数据切片,以及根据事件时间来选择对应的切片进行回填。但在基于老的链路去升级的话,肯定会考虑到对下游链路的影响。这里我们基于 Paimon 的 Hive Catalog 和 Tag to Partition 的特性,在生成数据切片的时候,会自动将这些数据切片对应回原有的 Hive 表的分区,即 Paimon 表可以当做普通的 Hive 表去查询。所以在原有的 Hive 表替换为 Paimon 表之后,下游的作业无论是用 Spark、Presto 还是 Flink,其查询语句都不需要改变,极大地减少了链路升级带来的副作用。

四、未来规划
Paimon 在数据时效性与存储成本方面已带来显著收益,未来我们将进一步探索其多元使用场景,尤其聚焦于 Paimon 1.x 版本新增的功能与优化能力,Shopee 也会持续拓展其应用边界。
目前正着力将 Paimon 作为统一存储格式推广,除本次介绍的主键表 Upsert 场景外,其 Append Only 表相较 Hive 在性能上也更具优势,可广泛适用于数仓各层级的构建,为数据存储与处理提供更高效、灵活的解决方案。
关于 StarRocks
StarRocks 是隶属于 Linux Foundation 的开源 Lakehouse 引擎 ,采用 Apache License v2.0 许可证。StarRocks 全球社区蓬勃发展,聚集数万活跃用户,GitHub 星标数已突破 10000,贡献者超过 450 人,并吸引数十家行业领先企业共建开源生态。
StarRocks Lakehouse 架构让企业能基于一份数据,满足 BI 报表、Ad-hoc 查询、Customer-facing 分析等不同场景的数据分析需求,实现 "One Data,All Analytics" 的业务价值。StarRocks 已被全球超过 500 家市值 70 亿元人民币以上的顶尖企业选择,包括中国民生银行、沃尔玛、携程、腾讯、美的、理想汽车、Pinterest、Shopee 等,覆盖金融、零售、在线旅游、游戏、制造等领域。


行业优秀实践案例
泛金融:中国民生银行|平安银行|中信银行|四川银行|南京银行|宁波银行|中原银行|中信建投|苏商银行|微众银行|杭银消费金融|马上消费金融|中信建投|申万宏源|西南证券|中泰证券|国泰君安证券|广发证券|国投证券|中欧财富|创金合信基金|泰康资产|人保财险|随行付
互联网:微信|小红书|滴滴|B站|携程|同程旅行|芒果TV|得物|贝壳|汽车之家|腾讯大数据|腾讯音乐|饿了么|七猫|金山办公|Pinterest|欢聚集团|美团餐饮|58同城|网易邮箱|360|腾讯游戏|波克城市|37手游|游族网络|喜马拉雅|Shopee|Demandbase|爱奇艺|阿里集团|Naver|首汽约车
新经济:蔚来汽车|理想汽车|吉利汽车|顺丰|京东物流|跨越速运|沃尔玛|屈臣氏|麦当劳|大润发|华润集团|TCL |万物新生|百草味|多点 DMALL|酷开科技|vivo|聚水潭|泸州老窖|中免集团|蓝月亮|立白|美的|伊利|公牛|碧桂园
