




导读
前两天遇到一个主从延迟问题, 准备修改下相关参数(slave_parallel_type,slave_parallel_workers)来处理. 在此之前得先在测试环境对比下修改前后的区别.
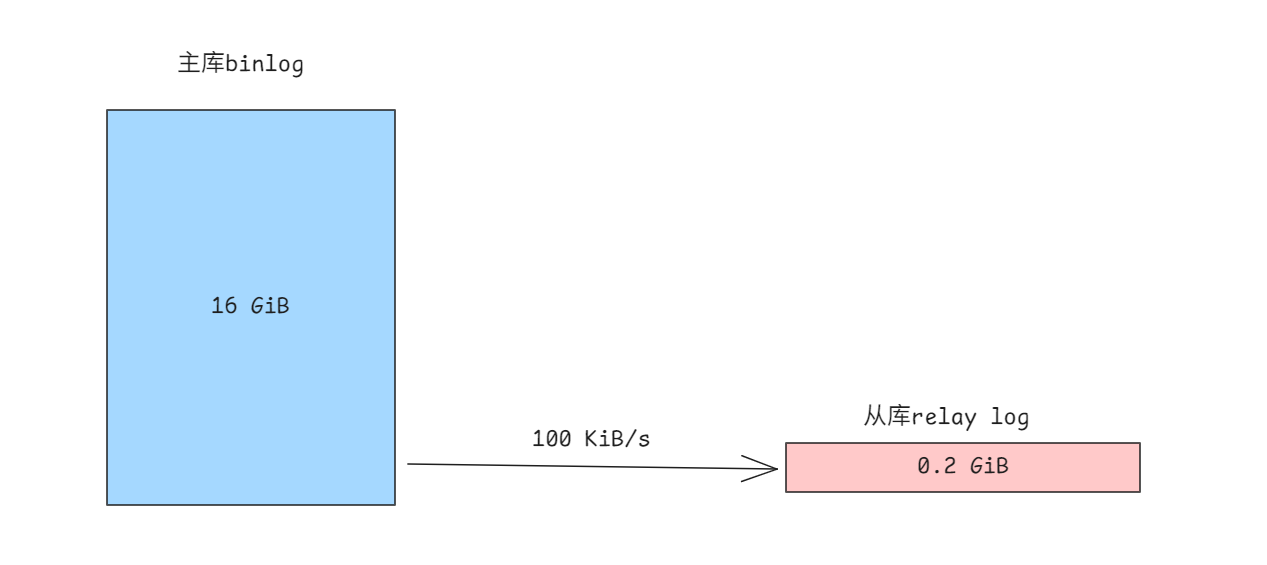
于是开发在测试发起了相关测试, 从库的延迟一路高歌猛进, 很好, 和生产差不多, 模拟出来了. 但是我当时有使用show processlist查看, 感觉sql线程比较闲, 明明延迟都那么大了. 却很少看到sql线程回放sql语句(binlog_rows_query_log_events=ON). 于是看了下relay log信息, 发现从库只有不到100MB的binlog和relay log; 主库那边已经产生了10+GB的日志啊, 查看从库接受的binlog位置还对应主库的第一个Binlog.
也就是说从库只收到了几十MB的主库日志.
分析过程
我们先来看下主从同步的逻辑: 主库发送binlog给从库的io_thread, io_thread写入relay log, 然后sql线程去回放相关relay log
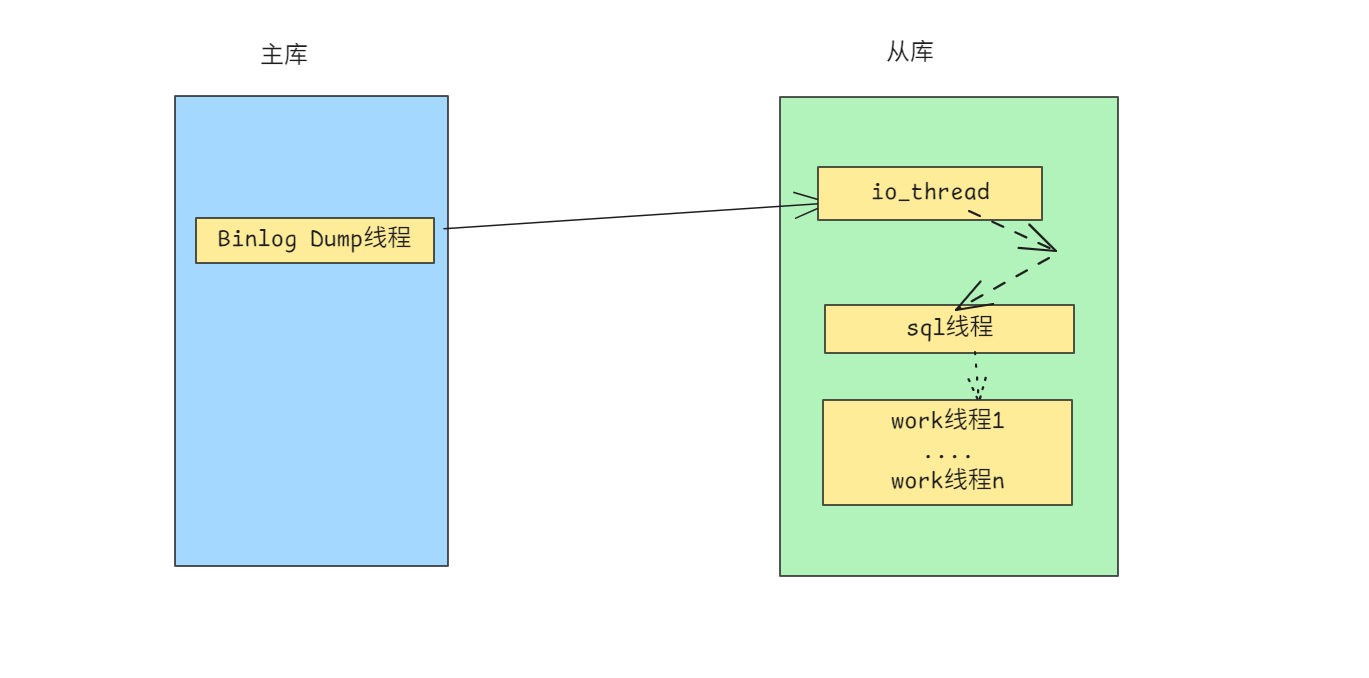
现在的情况是 io_thread 接收binlog的速度就非常慢了, 还没到回放那一步.
怀疑网络问题
传得慢, 那当然首先怀疑是网络的问题了. 我们使用dstat发现网速只有100 KB/s
于是使用如下几种方式进行验证
# 使用scp验证网速
scp MASTER:/binlog SLAVE/relay_log
# 使用wget验证3306附近端口的速度
wget MASTER:3307/binlog/xxxx
# 使用mysqlbinlog远程拉主库的binlog
mysqlbinlog --read-from-remote-server --raw --host=master --user='xx' --password='xx' --result-file=RELAY_DIR
上述验证下来速度均达到几百MB/s 这不但验证了网速, 还顺便验证了IO, 但均未发现异常. 一下就把路都走死了.(wget甚至能达到900MB/s)
堆栈分析
本来准备使用perf的, 但是遇到报错"Dazed and confueds. but tring to continue", 于是手动gdb
# 先找到io_thread的thread id
mysql -e 'select name,thread_os_id from performance_schema.threads where name like "%slave_io%"'
# gdb调试mysqld进程
gdb -p `pidof mysqld`
info threads #查看进程信息
thread 33 # 切换到io_thread线程
bt # 查看堆栈信息
大概信息如下:
fsync() os_file_fsync_posix() os_file_flush() ... MYSQL_BINLOG_COMMIT::commit ha_commit_trans()
这明显是在提交的时候刷盘的啊. 尝试了好几次均为这种状态. 而且把sql_thread线程停了之后, 每次抓也是处于这个fsync阶段.
使用strace看下了也是主要是在write(relay log fd), 就又回到了IO问题上.
修改了relay_log_info_repository为FILE也不行.
万能的重启大法
遇事不决, 先重启.
于是重启了主从复制进程, 无果.
再重启了mysqld进程, 无果.
最后重启了OS, 还是TM的无果.
perf分析
万能的重启大法虽然失败了, 但是perf却可以使用了, 所以也不算完全失败.
于是我们使用如下命令采样2分钟并分析
# 采样
perf record -F 100 -p `pidof mysqld` -- sleep 120
# 下载画图软件(可选)
wget https://github.com/brendangregg/FlameGraph/archive/refs/tags/v1.0.tar.gz
tar -xvf v1.0.tar.gz
cd FlameGraph-1.0
# 画图
FLAMEGRAPH_DIR='/root/flamegraph/FlameGraph-1.0'
perf script -i perf.data | ${FLAMEGRAPH_DIR}/stackcollapse-perf.pl | perl ${FLAMEGRAPH_DIR}/flamegraph.pl > perf_test_io_thread.svg

下图为模拟的, 非测试环境的.

实际情况干扰项会少很多
可以看到耗时是在两阶段提交刷盘上, 也就是还是卡在IO上.
再度怀疑IO
既然性能又回到IO上, 那我们就再次测下IO吧. 我们可以使用如下python脚本简单测试下IO
#!/usr/bin/env python
import time
import os
FILENAME = '/tmp/test_io_20250711.bin'
FILESIZE = 1*1024*1024*1024
BLOCKSIZE = 4*1024
data = b"x"*BLOCKSIZE
start_time = time.time()
with open(FILENAME,'wb') as f:
for x in range(FILESIZE//BLOCKSIZE):
f.write(data)
f.flush()
os.sync()
stop_time = time.time()
print('FILE SIZE:',FILESIZE,'COST TIME:',round(stop_time-start_time,2),'sec')
print('IOPS:',round(FILESIZE//BLOCKSIZE//(stop_time-start_time),2) )
print('RATE:',round(FILESIZE/(stop_time-start_time),2))
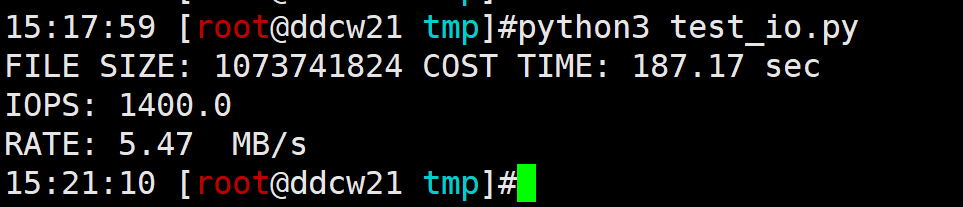
这里是基于4KB来算的, 因为解析binlog发现很多小事务, 平均下来4KB左右.
我这IOPS虽然有1400, 但实际场景是远不到这个值的. 也就是说iops很低, 刷盘又很频繁, 于是就刷不过来了.
主库也测试过, 和从库IOPS差不多.
关双1
既然刷盘刷得慢, 那就不刷盘了! 于是我们直接关闭双1
set global innodb_flush_log_at_timeout = 0;
set global sync_binlog = 0;
不需要重启, 直接观察dstat, 发现网速飙到了200+, 然后就没了(因为已经传输完了).
从库接受到事务后, 会更新mysql.slave_relay_log_info, 这张表是innodb表, 每次提交都得走双1. 浪费了为数不多的IOPS
延迟也很快降下来了(在双1关闭之后). 所以问题基本上算是结了.
总结
原因: 大量小事务 + 从库的低IOPS 导致本次从库的延迟增大.(刷盘刷得慢,网络接受得也就慢了).
解决方法: 关闭从库双1, 减少IO.
合并小事务为相对较大的事务理论上也是可行的, 但还在验证中. 合并为多大的事务合适呢? 我们可以通过上面测试iops的脚本来测试, 比如我的环境:
4KB每次IO的时候, 速度为:5.47 MB/s
4MB每次IO的时候, 速度为: 579.42 MB/s
20MB每次IO的时候, 速度为: 601 MB/s
40MB每次io的时候, 速度为: 568 MB/s
也就是每次刷盘在某个值的时候,io带宽能达到最大值. 具体多少得直接测试了. 不同的环境是不同的. 这样每次提交的事务都按照这个来的话, 理论上就能最大程度利用IO(这是针对于跑批之类的能改变事务大小的场景来说的. 觉得麻烦的话, 直接关从库的双1, 让OS去考虑吧.)
思考: 主库IOPS也是差不多啊, 为啥这么多小事务跑得还挺快的(相对于从库来说)?
