




今天下午在搜索 gpfdist 相关资料的时候,根据 "gp_external_max_segs" 关键字进行搜索的时候,看到了这样一个链接,于是怀着查资料的初衷,点进去瞅了一下,这不查不知道,一查真是吓一跳啊 🫥,必须得抒发一下情怀 ~

这个界面我简直太熟悉了,相信 Greenplum 的相关从业人员也一眼就认出来了。
让我们"深度"对比一下,如下是 Greenplum 6 的中文文档:https://docs-cn.greenplum.org/v6/admin_guide/admin_guide.html:[1]
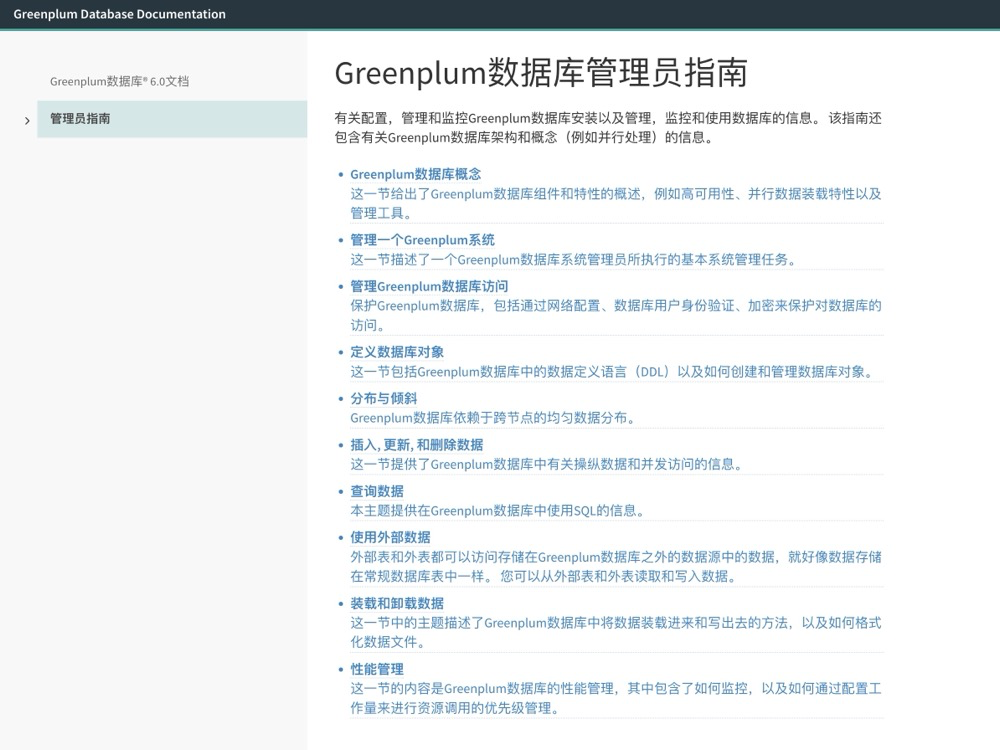
如下是某国产数据库的文档,本来想着打个码的,但是无奈要打的地方太多了..
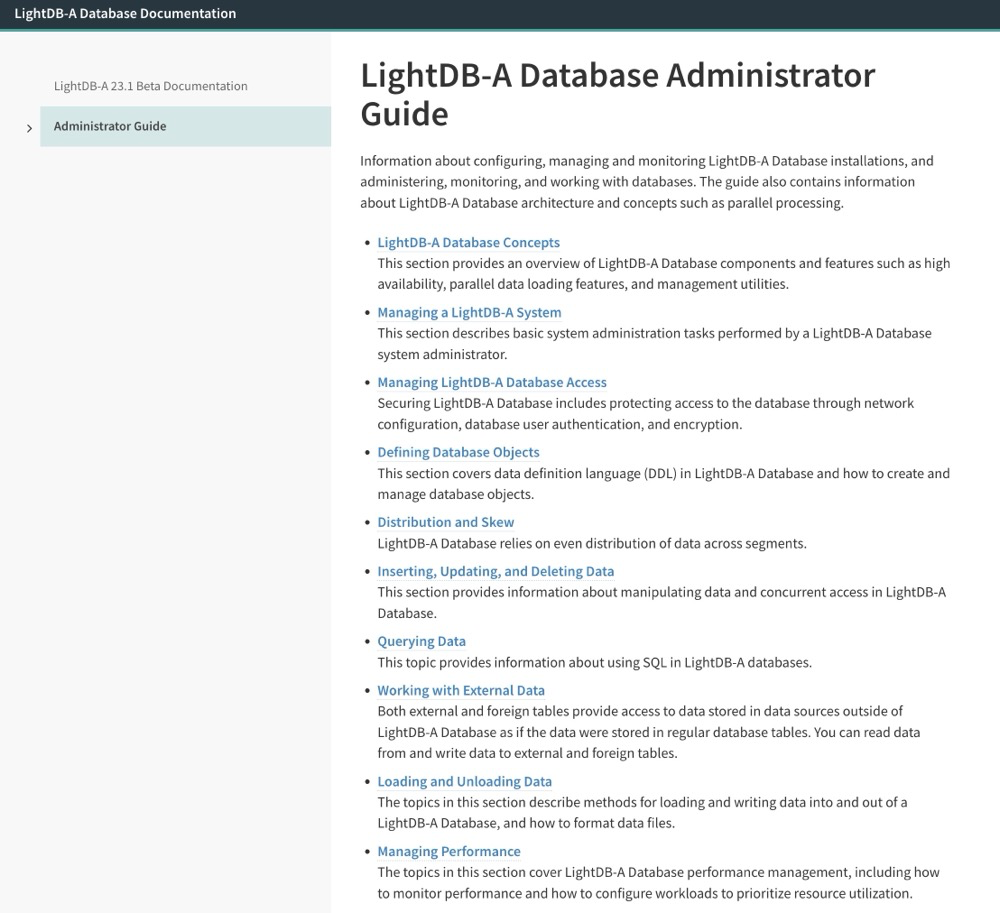
这用"相差无几"可能都不合适,这你妹的简直是一毛一样啊!要我判断,估计就是做了一个 sed 全局替换,临时赶鸭子上架赶出来的,你既然要做替换,好歹要替换干净吧,随意翻看这份产品文档,可以看到,全文中大量包含着 "VMware"、"Tanzu" 等字眼,甚至 rpm 包名字都不带换一下的,合计着我用此国产数据,我还得去 VMware 下载,真是蚌埠住了。
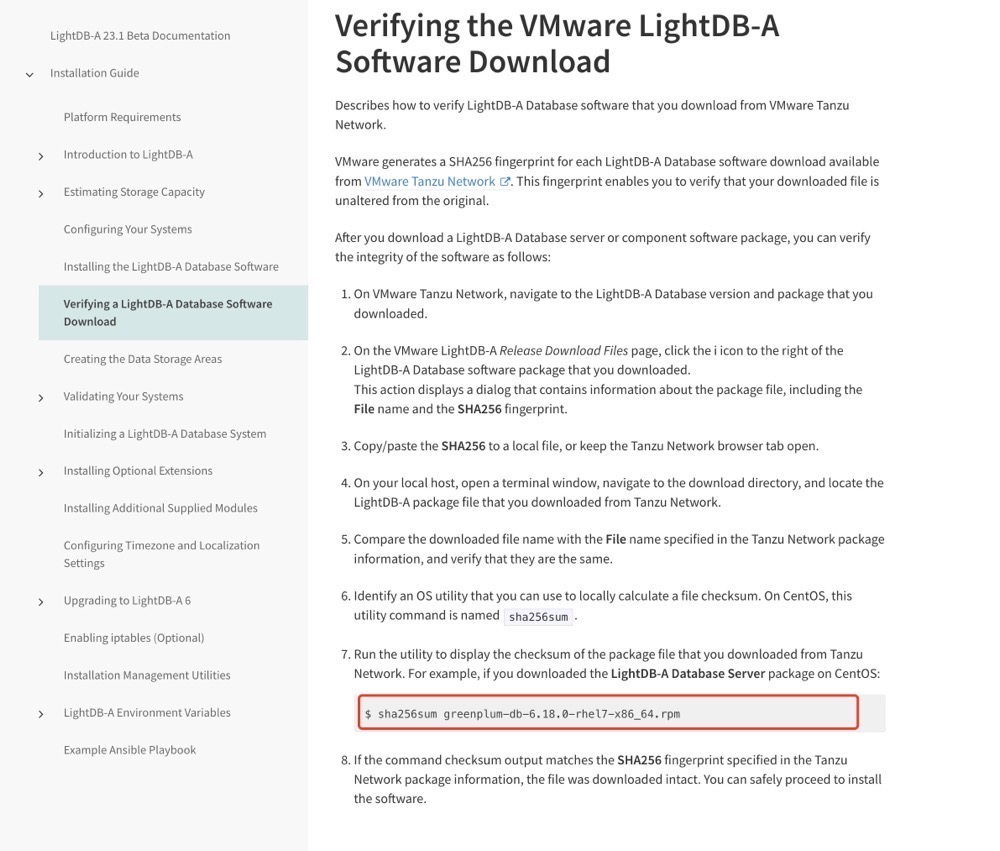
所以真相是什么,相信各位都已经十分清楚。
对于国产数据库的研发,到底是要纯自研,还是基于开源做二次开发,一直以来就争论不断。
•对于纯自研路线,研发周期 & 资金消耗大:需要重走一次成熟内核的多年演进之路,其次生态冷启动难:驱动、ORM、监控、第三方工具要重新适配,还有技术债:Bug 密度、边角特性、SQL 标准完整度都要自己填坑,不过自研路线能拉高"护城河",但也要避免闭门造车:拥抱开源、建立公共 SIG、吸引外部贡献者是长期生命线•第二种,则是基于开源,继承数十年验证过的稳定内核,站在巨人的肩膀上,与全球生态保持同步,社区 Bug 修复、特性演进可直接"拿来",其次人才供给充足(PG / MySQL DBA 与开发者转化成本低),但是缺点是同质化严重,差异化卖点有限,价格竞争激烈,进而扭曲市场规则,将"优胜劣汰"变成了"低价为王",另外在"国产替代"定标中,由于非"自研",ZC 得分相对低,所以导致一些国产数据库厂商们不愿意参加一些开源数据库的各类大会,参加不就等于变相承认?•第三种则是基于开源深度魔改,自成一派,与上游逐步"分叉"后,同步成本陡增;版本越老,后向兼容越难
据信通院统计(2021),约 2/3 国产关系型产品属于“基于开源”,其中不少被圈在“换皮/套壳”区间

基于开源并不是什么原罪,但 长期竞争力 必须来自:
•技术深水区:在存储格式、事务/并发、执行引擎或 AI Native 等方向做扎实创新;•持续回馈上游:保持与社区同步,才能把“开源势能”转化为自身护城河;•场景化解决方案:用国产硬件、行业法规、本地运维经验打造差异化价值;
...
否则如果换皮套壳只是为了快速占坑的话,那么 “套壳”只是 商业发行版 的起点,而绝不会是终点。
本篇文章仅记录本人在技术实践中的所见所思,对"国产数据库 套壳换皮"现象的一点吐槽与反思,读者请以独立判断为准,共同推动技术生态的良性发展。毕竟笔者也就一名普通打工族,也是国产数据库的一名从业者,文中提及的产品、厂商或案例,仅为说明问题所需 (手动保命)
