





这里的 “图” 可不是我们日常看到的图片,而是一种抽象的数据结构,由点和边组成。点可以代表各种各样的对象,比如人、地点、事物等;边则用来表示这些对象之间的关系,像是人与人之间的朋友关系、地点与地点之间的道路连接,或者事物之间的某种关联。
简单来说,图就是把现实世界中的各种关系以一种直观的数据形式呈现出来。例如,在社交网络中,每个用户就是一个顶点,用户之间的关注、好友关系就是边,这样整个社交网络就可以用图来表示。
图计算的适用场景非常广泛。在早期阶段,图计算仅限于学术界以及工业界资深的研究机构内部,随着计算机体系架构的发展,图计算在更广泛的行业和场景中得到应用。按照时间维度大体可以把图计算的发展及适用范围分为如下几个阶段:
· 20世纪50—60年代:最短路径算法、随机图理论研究、早期交易系统IBM IMS。
· 20世纪80—90年代:图标签、逻辑数据模型、对象数据库、关系型数据库的关系模型等。
· 20世纪90年代中叶至21世纪前10年:互联网索引技术、网页搜索引擎。
· 21世纪第2个10年:最早的图数据库出现、大数据与NoSQL的蓬勃发展、各类图计算框架及多模式数据库的涌现、社交网络的爆发及社交网络分析。
· 21世纪第3个10年:更广泛的业务场景、创新场景对于图计算及高性能图数据库的应用。
图计算在过去半个多世纪的发展是伴随着其他主流技术的发展而不断迭代的。以最著名的Dijkstra最短路径算法为例,它是位于荷兰阿姆斯特丹的数学中心于1955—1956年间构造的第三代计算机ARMAC,而该机构唯一的计算机程序员迪杰斯特拉在思考荷兰的两座城市鹿特丹与格罗宁根之间的最短路径问题时仅用了20min就想到了解决方案(一种典型的带权重的有向图中的广度优先算法),并在ARMAC上编程验证其算法的准确性。该最短路径算法在寻路、交通、导航、路径及资源规划等场景中广泛应用。

事实上,解决最短路径问题不仅仅局限于Dijkstra算法,还有如Bellman-Ford算法(1955—1959年)、A*算法(著名的A星算法,1968年)、Floyd-Warshall算法(1962年)、Johnson's算法(1977年)等。
以A*算法为例,它是1968年国际斯坦福研究所(SRI International)在研制世界上第一个“通用”移动机器人(the shakey project)时发明的“寻路”算法,属于Dijkstra算法的延展算法。而这些算法所解决的都属于典型的动态规划(DynamicProgramming,DP)问题。在管理科学、经济学、信息生物学、航空航天等领域大量使用动态规划来解决问题,简而言之就是把原始、复杂的问题拆分为较为简单的问题,以某种“递归”的方式解决,在这个过程中找到“最优解”,例如旅行时间最小化、利润最大化、效用最大化等。在动态规划中最核心的是动态规划方程或称贝尔曼方程(bellman equation),有兴趣的读者可以深入研究。
图标号(graph labeling)源自Alexander Rosa在1967年发表的一篇论文。我们可以简单理解为对图中的点、边进行了标识赋值,例如对顶点、边进行具有唯一性的整数赋值,如下图所示。
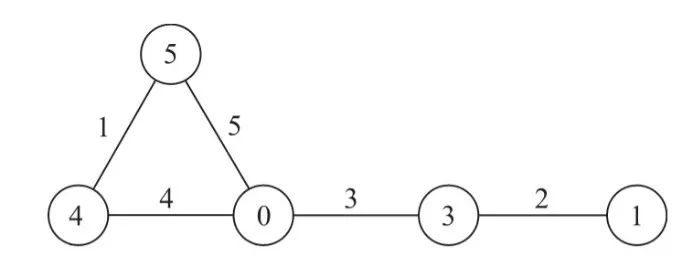
图2:点标号与边标号
这种整型赋值的方式对于人类而言显然是不友好的,因为我们很快就会无法区分到底1~5指的是顶点还是边,所以图上的标号被扩展为支持字符串(在存储数据结构上依然可以对应整数值以获得更高的存储、索引与计算效率),如图3所示。
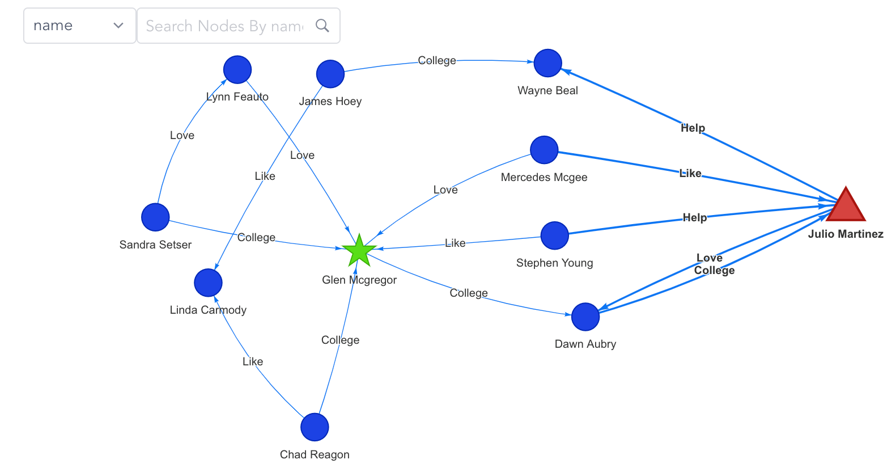
图3:可视化人际关系网络图谱中的标号
图标号的应用场景随着图计算与图数据库的发展变得随处可见。在早期,它最知名的应用场景是地图上色。当我们把地图中的不同国家抽象为点或边的时候,相邻的顶点采用不同的颜色,相邻的边也采用不同的颜色以示区分。另外一个典型的应用场景是使用标签来参与计算的图算法,例如标签传播算法(LPA)、鲁汶社区识别算法以及带权重(标签)的全图出入度计算等。在第4章中会更详细地介绍图标号的应用。
图论的一个重要分支是网络理论,在以前的文章中,笔者就提到的欧拉对于哥尼斯堡七桥的证伪问题就是网络理论最早的证明。网络理论的应用场景非常广泛,从各种网络分析到网络优化场景,例如社会网络分析、生物网络分析、鲁棒性分析、中心性分析、链接性分析等。网页排名算法就是典型的网络链接分析,例如谷歌搜索引擎中核心算法之一的网页排序PageRank(PR)算法、社交及金融反欺诈中的SybilRank排序算法等。
谷歌的PageRank算法把Web上所有网页作为顶点,把网页间的超链接作为边,通过计算每个节点的权重值来表达每个网页的重要性,权重值大小通过当前节点的入边及入边所关联的顶点的权重递归计算而得出。PR算法公式如下:
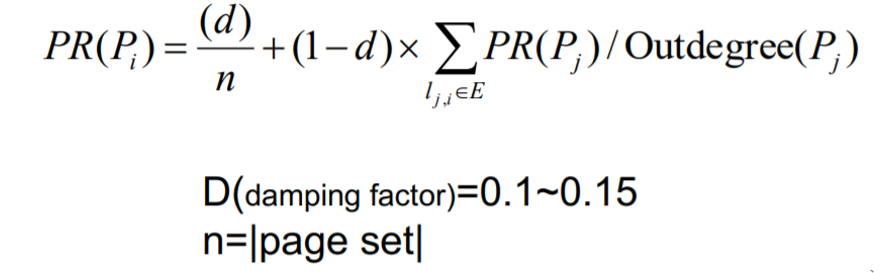
其中,d为阻尼系数,取值范围为0.1~0.15;n为所有页面数;L(j)为页面的出链数。在有的PR算法公式中,d也可能被设为0.85(相当于对d=0.15取余)。为了方便计算,所有网页的初始PR值为1且每次迭代中全部的网页节点都参与计算,在经过足够多次的迭代后(例如5次),PR值会稳定(收敛)下来,也就是说更多次的迭代并没有意义。很多图算法都有类似的特点,例如社区识别中的鲁汶算法,虽然比PR算法的计算复杂度要大得多,但也可以经过一定次数的迭代后让模块化度(louvain modularity)产生收敛。在满足业务需求的精度条件下运行最少次数的迭代来获得图算法结果(输出参数)是图计算的一个重要特点。
二、图计算为何如此重要?
别觉得图计算离我们的生活很远,其实我们每天都在接触和生产很多数据,这里面就有图论的 “研究对象”:
朋友圈是图(每个人是点,好友关系是线);
快递网点是图(仓库是点,运输路线是线);
甚至手机里的通讯录、购物车清单,本质上都能转化成 “图”……
有人可能会问:数组这种零散的数据,跟 “网络” 有啥关系?
这就像一张网,当所有网线都消失,只剩下一堆孤立的网结 —— 这些离散的 “点”,就是数组。同理,关系型数据库像 Excel 表格(二维),而图数据库是能装下表格、数组、网络的 “高维收纳盒”,能轻松兼容低维数据,但想把高维数据硬塞进低维容器,就像把魔方拆成平面贴纸,肯定会乱套。
搞图计算,核心就盯三件事:
1、怎么查、怎么算才顺手(基础模式)!
2、用啥 “容器” 装数据最高效(数据结构)
3、怎样算得又快又准(效率优化)
世界是由无数复杂关系构成的总和,而图计算提供了一种从 “关系” 角度分析问题的强大能力。以往用扁平化视角难以发现的信息,通过图计算就能轻松获取。在大数据时代,数据之间的关联关系愈发重要,很多实际应用场景都离不开图计算,尤其是在图计算逐步融入图数据库后,其应用场景得到了广泛的跨增。

三、图计算的数据结构
在图计算中,数据结构的选择对计算效率至关重要。常见的有相邻矩阵(或关联矩阵)和相邻链表。相邻矩阵访问时间复杂度为 O (1),听起来很不错,就好像你有一个超级快捷的索引,能瞬间找到你要的信息。
但它有个大缺点,就是存储低效。打个比方,如果把一个社交网络用相邻矩阵表示,哪怕只有少数人之间有联系,矩阵中也会有大量的 0(表示没有关系),这就浪费了大量存储空间。
而相邻链表则不同,它对存储空间需求小得多。以 Facebook 的社交图谱为例,其底层技术架构(Tao/Dragon)采用相邻链表,每个顶点代表人,顶点下的链表记录着该人的朋友或关注者,这样就大大节省了空间,在工业界应用广泛。不过,相邻链表也有局限,可能遇到热点问题。比如一个超级网红有 10000 个粉丝,那么遍历这个链表去获取信息的时间复杂度就变成 O (10000),增删改查操作平均复杂度为 O (5000),而且它的并发能力差,无法对链表进行并发写操作,Facebook 的架构中也对此做了相应限定。
四、图计算模型
BSP 计算模型
BSP 计算模型,全称整体同步并行计算模型(Bulk Synchronous Parallel Computing Model),也叫大同步模型或 BSP 模型,是 1992 年由哈佛大学的 L.G. Valiant 教授(2010 年图灵奖得主)提出的。
它把并行计算抽象成处理器集合、全局通讯网络、路障同步机制等模块。并行计算的基本执行单元是超级步(Super Step)。一个 BSP 程序包含多个超级步,每个超级步又由本地计算、全局通信和路障同步三个阶段组成,而且这三个阶段是严格串行的,就像接力赛一样,一个阶段结束,下一个阶段才能开始。所有处理机先完成本地计算,然后统一进行通讯,最后执行同步。
它的特点包括创新地提出超步概念,每个超步都是一次完整并行计算;处理器同步,每个运算单元在一个超步内只能传递或接收一次数据,由 Master 节点协调所有处理机节点;通信方式采用 P2P(点对点),有效避免拥塞,还简化了通信协议。BSP 模型易于编程且性能可预测,不易产生死锁,适用于大规模计算,像图计算、网页排名、社交网络分析、路径规划等领域都有它的身影。例如,Google 的 Pregel 计算模型就是基于 BSP 模型设计的,用来解决 MapReduce 在图计算上的局限性。
Pregel 编程模型
“以顶点为中心的 Pregel 编程模型” 在图计算领域举足轻重,主要用于处理大规模图数据计算任务。
在这个模型里,顶点代表各种实体,每个顶点都有唯一标识符,还能关联可修改的用户定义值(属性)。边则代表顶点间的关系,有向边与源顶点关联,有自己的属性值,还记录着目的顶点 ID。
Pregel 模型以顶点为中心,每一轮迭代中,顶点处理上一轮收到的消息,再给其他顶点发消息,同时更新自身状态和拓扑结构。它通过消息传递在顶点间通信,所有顶点计算并行,都执行用户定义的同一函数。顶点有活跃和非活跃两种状态,初始时都为活跃,没收到消息或不再发消息时变为非活跃,收到新消息又会被激活。
执行过程是先输入有向图,初始化图并设置顶点为活跃状态,接着运行一系列超步,在超步中顶点并行计算,修改自身信息、收发消息,甚至改变图拓扑结构,当所有顶点都达到非活跃状态且无消息传送时,计算结束,最后输出顶点显式输出的一组值。
Pregel 模型适用于 PageRank、最短路径、图遍历等各种图算法计算任务,能高效处理大规模图数据,在分布式环境下实现并行计算。
Subgraph - centric(以子图为中心)模型
Subgraph - centric 模型关注图中的子图结构,以子图作为图计算基本单位。与以顶点为中心的模型不同,它将子图视为核心,这样有助于捕捉图中的局部结构和模式,也非常适合并行计算,通过并行处理多个子图提高计算效率,还具有很高的灵活性,开发者能根据不同应用场景和需求定义、选择子图结构。
其工作原理一般是先将大规模图数据划分为多个较小子图,然后对每个子图进行独立计算,包括子图内顶点和边的更新等操作,最后将各个子图计算结果合并得到最终图计算结果,合并过程可能涉及子图间通信和数据交换。
在社交网络分析中,通过分析子图结构能发现社交群体、社区结构等;在推荐系统里,利用子图结构分析用户行为和兴趣,为用户精准推荐产品;在金融风险评估中,通过分析金融交易网络中的子图,评估风险等,应用十分广泛。
五、图计算的发展趋势
随着数据量持续增长和数据复杂性不断提高,图计算就像一把神奇的钥匙,帮我们打开理解复杂世界关系的大门,在未来,它必将在更多领域发挥巨大作用,深刻改变我们的生活和工作方式。


