




PawSQL for Hive 理论基础之二:执行引擎是Hive SQL的“心脏”,负责将SQL语句转化为物理任务并在集群上高效执行。它的选择,直接决定了你的SQL查询是“龟速爬行”还是“快如闪电”!本文深入剖析Hive三大执行引擎(MapReduce, Tez, Spark)的底层机制与性能差异,并教你如何根据业务场景选择最优引擎,轻松实现查询效率数倍乃至百倍提升!
1️⃣ 核心结论
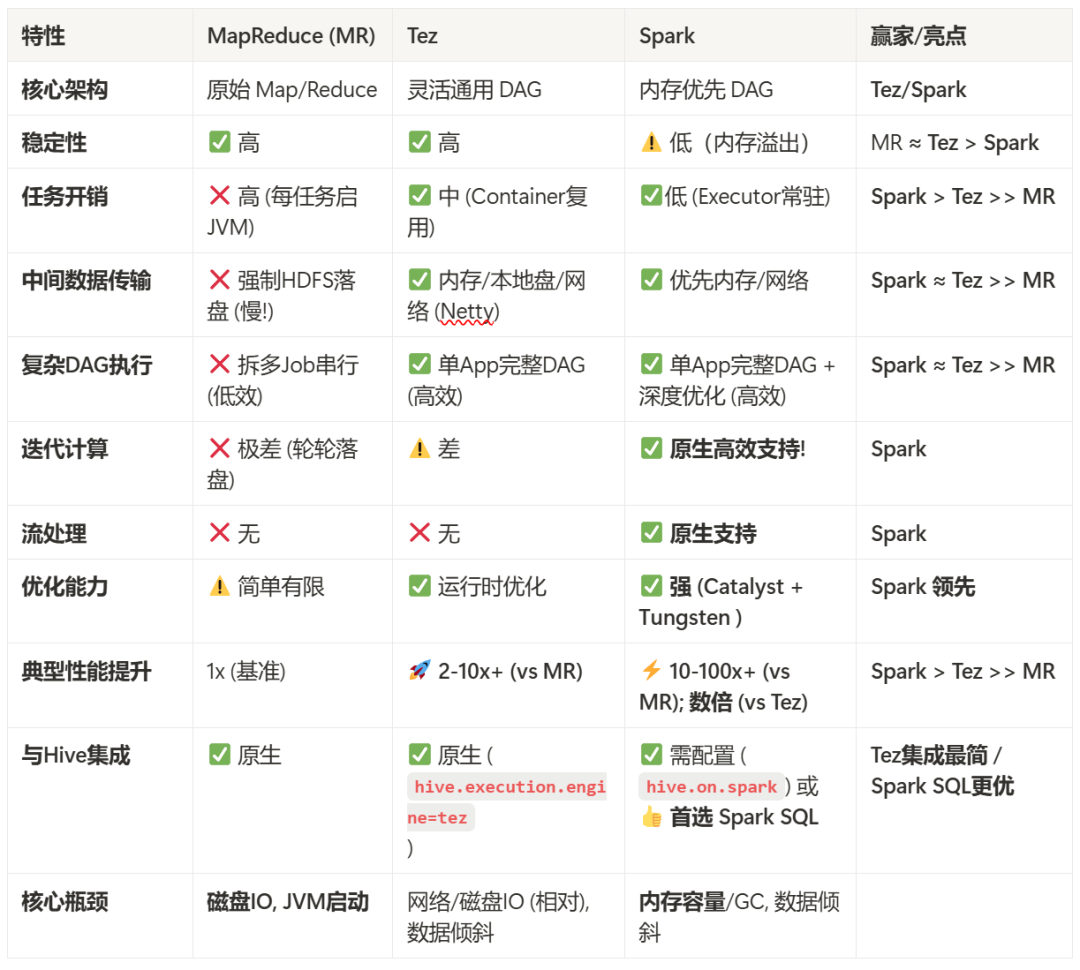
2️⃣ 执行引擎之 MapReduce
严格的 Map 和 Reduce 两阶段模型。 每个 Map 或 Reduce 任务都是一个独立的 JVM 进程。 Map 阶段输出必须写入 HDFS 磁盘,Reduce 阶段再从 HDFS 读取这些数据(大量磁盘 I/O)。 任务间依赖通过 HDFS 传递数据(高延迟)。 任务调度和启动开销大(每个任务启动一个 JVM)。
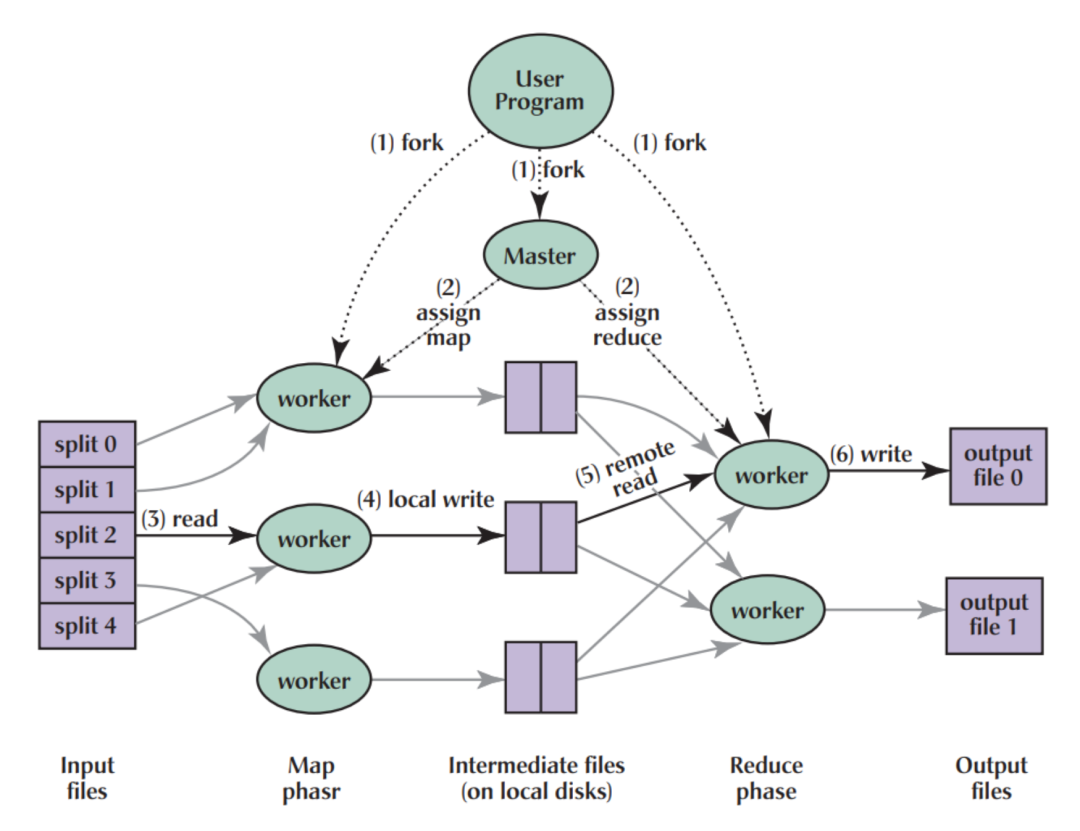
高延迟:频繁的磁盘 I/O(Map 写中间数据,Reduce 读中间数据)是最大的性能杀手。 高开销:启动大量 JVM 进程耗费大量时间和资源(CPU、内存) - 执行效率低:复杂查询会被分解成多个 MR Job,每个 Job 都需要经历完整的调度、启动、写磁盘、读磁盘过程,串联执行效率低下。
- 资源利用率低:JVM 进程启动慢,任务运行时间短时,资源浪费严重;无法在任务间有效共享资源(如 JVM 重用有限)
优化空间受限:在 MR 框架内进行优化(如 Combiner, 特定 Join 算法)效果有限,无法突破其架构的根本限制。
理解 Hive 执行原理。 非常简单的、只有一两个 MR Job 的任务。 对延迟要求极低的离线批量处理(但通常 Tez是更好的选择)。
3️⃣ 执行引擎之 Tez
高效数据传输:
- 内存管道:同一个 Container 内的任务可以通过内存直接传递数据。
- 本地磁盘/SSD:不同 Container 但同一节点上的任务可以通过本地磁盘(或更快 SSD)传递数据。
- Netty 网络传输:跨节点的任务使用高效的 Netty 网络传输。
- 减少 HDFS 落盘:只有当数据需要持久化或跨 Application 传递时才写 HDFS。
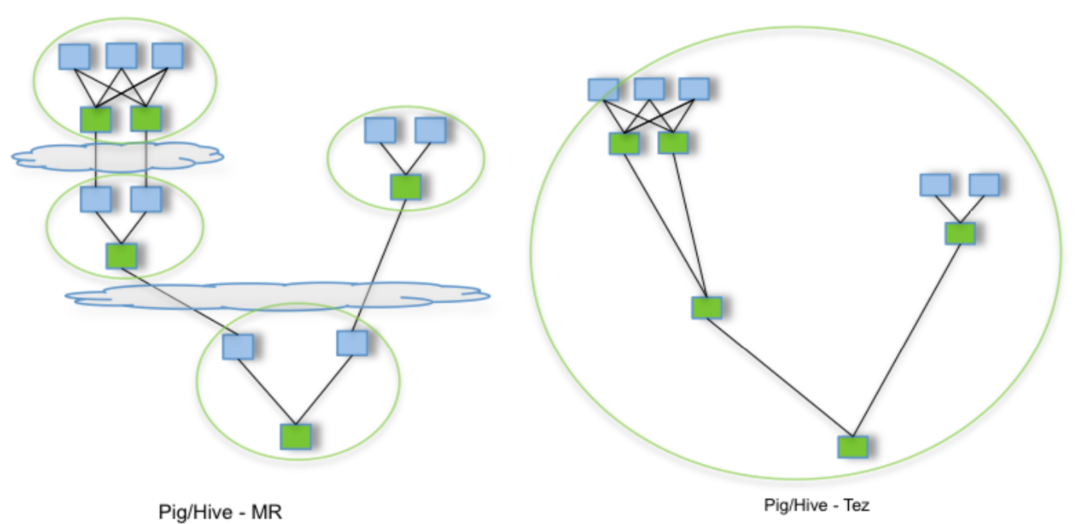
- 通用 DAG 引擎:不再局限于 Map 和 Reduce 阶段,可以表达任意复杂的任务依赖关系图(DAG)。
- 运行时优化:在运行时动态优化物理执行计划(例如,决定任务的并行度、连接顺序等)。
- 容器重用:在同一个 Application Master 管理下,任务(作为
Processor
运行)在 YARN Container 中执行,Container 可以被后续任务复用,避免了反复启动 JVM 的开销。
- 大幅降低延迟:内存、本地磁盘、高效网络传输替代了大部分 HDFS 读写,数据传输速度极快。
- 显著减少开销:Container 重用极大降低了 JVM 启动和资源申请的开销。
- 提高资源利用率:Container 复用和更精细的 DAG 调度使得集群资源利用更充分。
- 复杂查询高效执行:一个复杂的多阶段 Hive SQL 查询可以被编译成一个大的 Tez DAG,在一个 Application 中执行完成,避免了多个 MR Job 串联的开销和中间落盘。
- 运行时优化潜力:Tez 的运行时优化器可以在实际执行时根据数据统计信息等做出更优的决策。
- Tez 是替代 MR 的首选引擎,对大多数 Hive SQL 性能提升非常明显。
需要低延迟响应的交互式查询(相对于 MR)。 批处理任务。
4️⃣ 执行引擎之 Spark
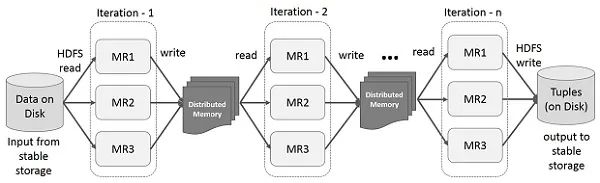
- 内存计算优先:将中间数据和状态尽可能保留在内存中,大大减少磁盘 I/O(但内存不足时仍会 Spill 到磁盘)。
- 弹性分布式数据集:核心抽象是 RDD 或 DataFrame/Dataset,支持基于内存的迭代计算和复杂的数据转换流水线。
有向无环图:同样使用 DAG 描述执行计划,但 Spark DAG 在 Driver 端构建(逻辑计划 -> 物理计划)。 任务调度:使用自己的 DAGScheduler 和 TaskScheduler,任务在 Executor (长期驻留的 JVM 进程) 中执行。 Whole-Stage Code Generation:将整个查询阶段的多个操作(如多个 filter, map)编译成单个函数(JVM 字节码),减少虚函数调用和 CPU 分支预测开销,极大提升 CPU 效率。 Tungsten 优化引擎:使用堆外内存管理、缓存友好的数据布局和编码,进一步提升内存和 CPU 效率。
- 极致速度:内存计算和代码生成在 CPU 密集型、可复用的中间结果场景下带来数量级的性能提升(尤其是多次访问同一数据集时)。
- 高效迭代:原生支持迭代算法(如机器学习训练),性能远超 MR 和 Tez
- 流批统一:Spark Streaming (Structured Streaming) 使用与批处理相同的核心引擎和 API,方便流处理和批处理共享代码与逻辑。
- 高级 API 与生态:Spark SQL (DataFrame/Dataset API) 提供更易用、优化空间更大的编程接口,并与 MLlib, GraphX 等库深度集成。
DAG 优化:Catalyst 优化器执行非常强大的逻辑和物理优化(谓词下推、列裁剪、常量折叠、Join 策略选择等)。
需要极致性能的批处理任务(尤其 CPU 密集型和可复用中间数据)。 迭代计算(机器学习、图计算)或流处理(Structured Streaming)。 需要利用 Spark 强大生态系统(MLlib, GraphFrames 等)的任务。 使用 DataFrame/Dataset API 进行开发的场景。
6️⃣ 实战指南:如何选择合适的执行引擎?
如果你的主要工作负载是 Hive SQL 批处理(尤其是 ETL)和 Ad-hoc 查询。 如果你希望获得显著的性能提升(相比 MR),同时保持与 Hive Metastore 和 HiveQL 语法的紧密集成。 集群资源(特别是内存)相对紧张,或者作业主要是 I/O 密集型而非需要大量内存缓存。 作为从 MR 升级到更现代引擎的第一步。
如果你追求极致的批处理性能(尤其是 CPU 密集型和需要内存缓存中间结果的场景)。 如果你的工作负载包含迭代计算(机器学习、图算法)。 如果你需要流批一体的处理能力。 如果你想利用 Spark 更强大的 DataFrame/Dataset API 和 生态系统 (MLlib, GraphX)。 如果你的集群有充足的内存资源。
7️⃣ 避坑指南:重要注意事项
💬 互动时间
你的团队在用哪个引擎?从MR升级到Tez/Spark后,性能提升了多少倍?遇到过哪些调优挑战?欢迎在评论区分享你的实战经验和见解!
文章转载自PawSQL,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
