




背景
检索增强生成(RAG, Retriever Augmented Generation)是一种将检索系统与大语言模型(LLM, Large Language Model)相结合,从而增强大语言模型的一种技术。传统大语言模型由于离线部署、自然语言固有的歧义性等特点,存在缺乏最新信息感知、对私有领域知识不足、幻觉等缺陷,在这个背景下人们提出检索增强生成技术来在实际应用中克服以上缺陷。
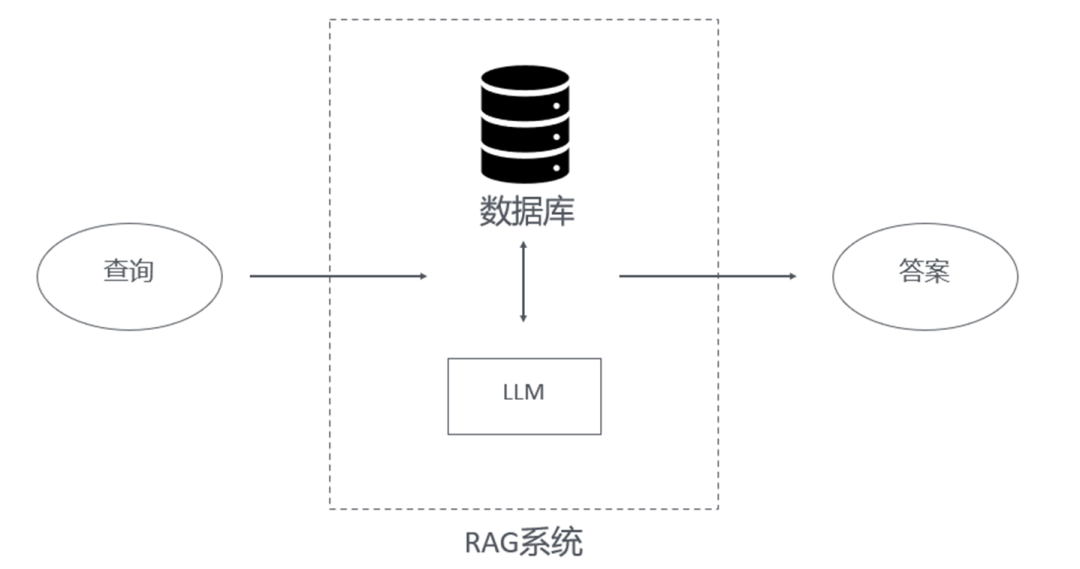
规划与推理是人类高级智能的重要组成部分。在检索增强生成中,规划与推理体现在系统处理复杂查询或任务时,通过制定全局规划或分解问题,在执行过程中进行逻辑推演、整合检索信息等过程。本文接下来就检索增强生成中的规划与推理分别介绍相关方面有代表性的几篇论文。
检索增强生成中的规划
Plan*RAG
Plan*RAG在收到查询之后,会先生成一个静态的 DAG 形式的全局规划。然后在后续的执行中逐步的去解析这个规划,并执行相应步骤需要的检索并生成相应子查询的答案,最终执行完计划图后得到原始查询的答案。
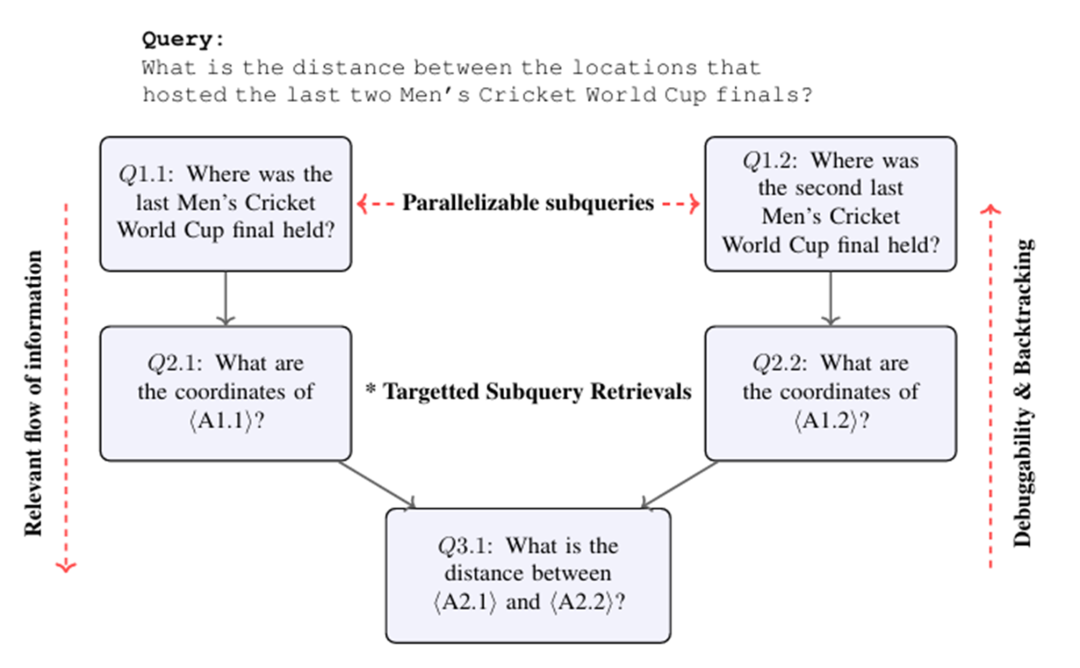
整个方法是 prompt-based 的,在全局规划的生成、子查询的动态解析、基于查询和检索结果的回答生成部分,都使用了 few-shot 技术来引导生成。对于整个方法中最复杂的全局规划生成部分,作者实验中使用了 GPT-4o,但使用经过 LoRA 微调的 Llama3.1-instruct8B 在测试集上也可以达到与 GPT-4o 可比的性能。
LevelRAG
LevelRAG在收到查询后,使用迭代检索的方式实现动态的规划生成。在每一轮中,顶层智能体负责 Decompose/Supplement, Summarize, Verify 步骤。首先进行查询的分解,接着对于得到的原子查询检索相应文档,然后对检索到的文档进行摘要,最后验证检索到的内容是否足以回答原始查询。当 Verify 没有通过时,顶层智能体继续提供额外的补充原子子查询(Supplement),直到完成或者超过最大迭代次数。

这个方法也是 prompt-based 的,使用的基座模型为 Qwen2 7B,在多个问答数据集上与基线方法的比较表示,其方法具有一定优点。
CR-Planner
CR-Planner使用多个小型的评估模型,来对大型基座模型的推理以及检索行为进行规划。相应的状态分为两类:子目标选择阶段,执行阶段。在子目标选择阶段,相应的评估模型决定下一步是推理,还是生成查询或者进行检索。在执行阶段,评估模型负责从多个候选执行结果中,选择最好的一个。

这个方法使用了经过微调的评估模型,生成用的基座模型选择黑箱 gpt-4o-2024-05-13,评估模型在 Skywork-Reward-Llama-3.1-8B 上进行 LoRA 微调。为每个测试用的数据集,相应的评估模型训练用的数据用 MCTS 模拟得到,然后用成对排序损失来优化参数。该评估模型的训练数据由 GPT-4o 得到,所以它适合于相应领域数据的评估以及基座模型为 GPT-4o 的情况,对于基座模型为其他时,论文中发现其存在一定的改进,但不如 GPT-4o 为基座模型时的表现。
检索增强生成中的推理
Search-o1
Search-o1是一个 prompt-based 的方法,其中使用提示词指示模型生成相应的标签,来控制何时进行检索、思考的执行流。考虑到将检索到的文档直接插入上下文会引入过多噪声,作者额外引入一个摘要模块来对检索到的文档进行摘要,然后再合并到上下文中。
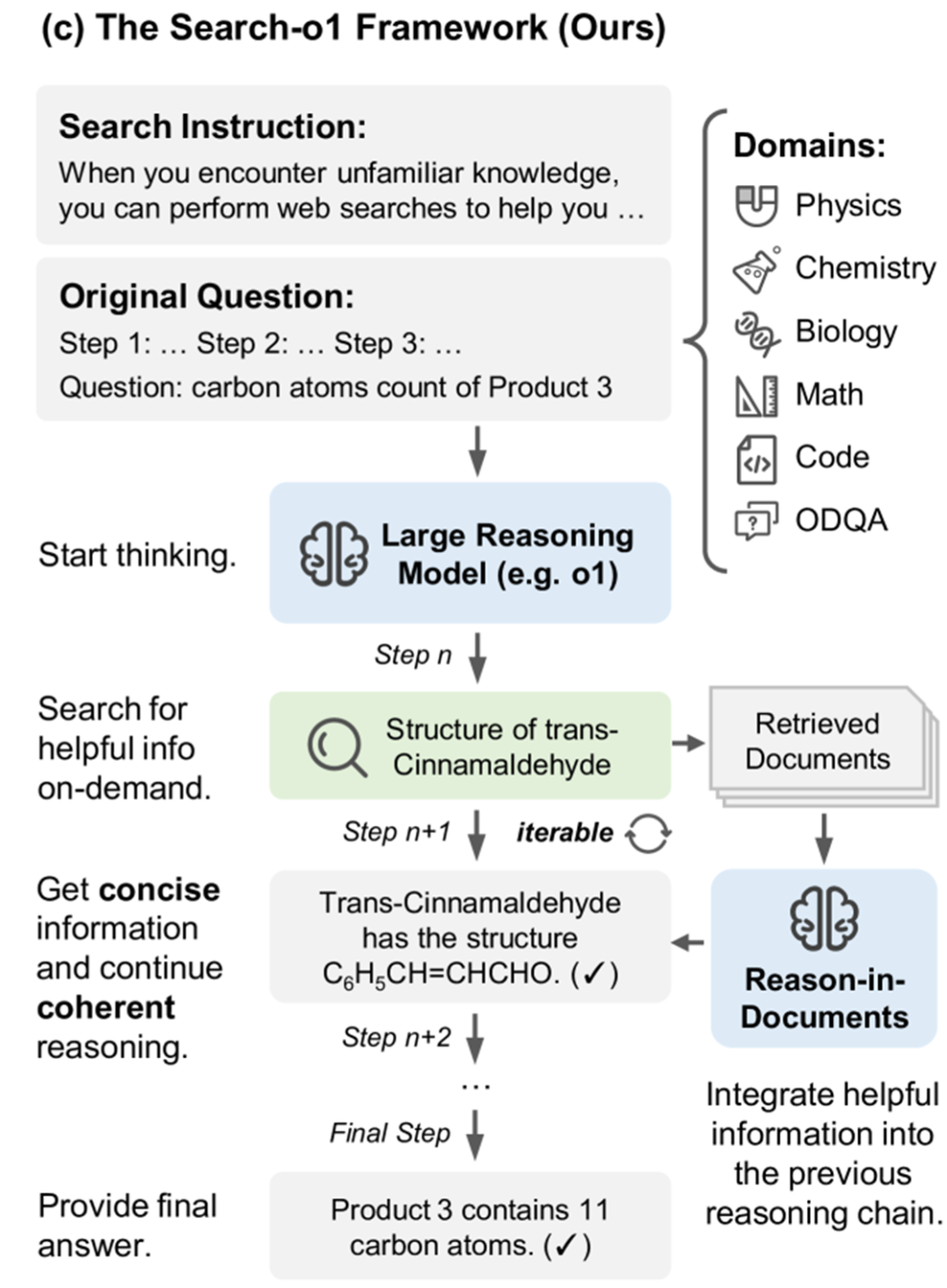
这个方法的实验使用了 QwQ-32B-Preview 以及 Bing Web Search API,相关的基线方法为非 RAG 推理模型,直接使用 RAG,以及没有摘要模块时的 RAG,结果显示大多数情况占优。
Search-R1
Search-R1使用 deepseek-R1 类似的训练方法,将检索和推理能力同时加到基座模型中。论文中实验了 PPO 和 GRPO 两种优化方法,相应的奖励使用基于规则的结果奖励,没有格式奖励,利用基座模型的指令遵从能力来控制执行流。
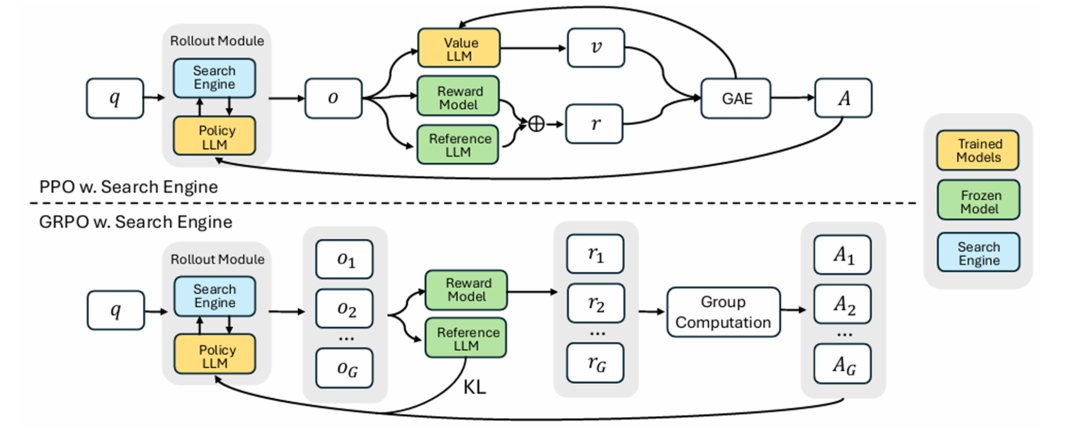
文中使用的基座模型为 Qwen2.5 的 3B, 7B 规模模型,文中对 base 以及 instruct 模型都进行了测试,结果显示 base 模型虽然在训练开始时得到奖励较低,但是能随着训练步数逐渐达到和 instruct 模型同等奖励水平,最终基于 base 模型的训练结果在一些数据集上甚至超过 instruct 模型上得到的结果。
DeepResearcher
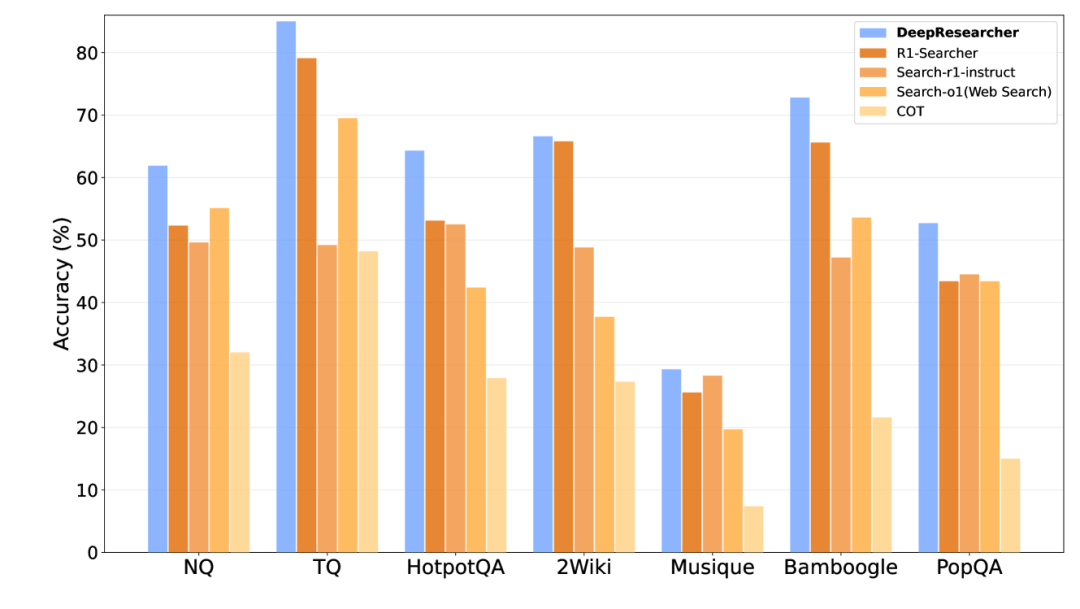
DeepResearch同样采用 deepseek-R1 类似的训练方法,将检索能力加入基座模型中。与 Search-R1 的不同在于,它在训练过程中使用了开放网络环境设置,使用专门的浏览代理从网页中提取信息。作者认为,通过在嘈杂、非结构化和动态的开放网络中进行端到端强化学习训练,最终得到的 DeepResearch 系统能涌现出一些高级认知行为,包括制定规划、来源交叉验证、自我反思以调整研究方向以及在无法找到确切答案时保持诚实。
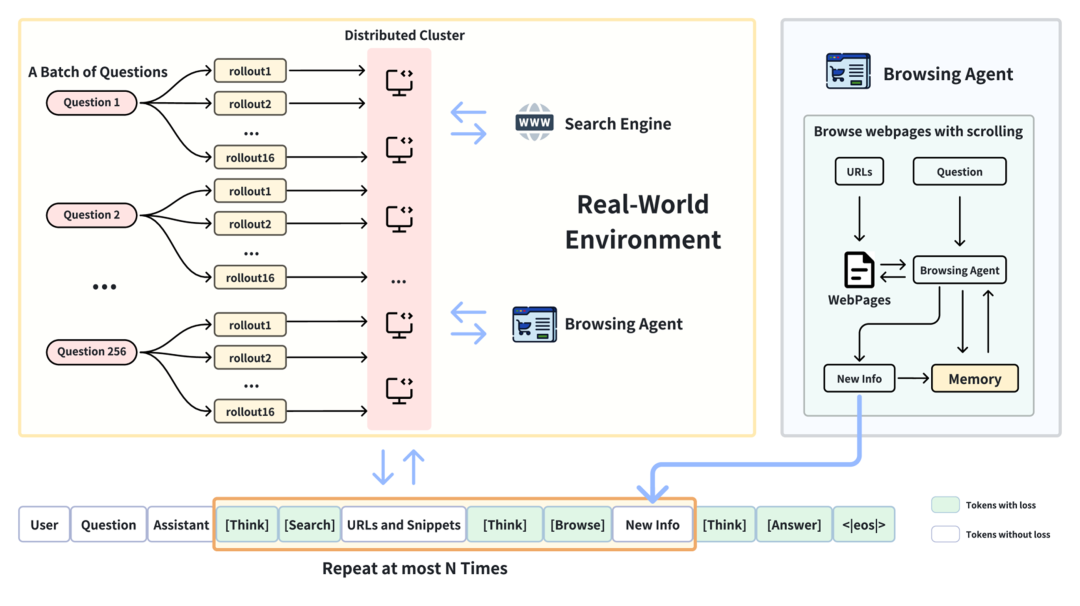
在实现细节上,作者使用 GRPO 进行优化,相应奖励采用基于 F1 分数以及格式惩罚的结果奖励。基座模型为 Qwen2.5-7B-Instruct。作者的结果表明在真实网络环境下的端到端训练不应仅被视为后训练阶段的实现细节,而是构建与实际应用场景相匹配的稳健研究能力的关键要素。
总结
本文首先介绍检索增强生成(RAG)的背景,接着关于该领域内规划和推理相关的工作进行了分享。规划与推理是目前大语言模型突破能力边界的关键路径,通过将复杂问题分解为结构化子任务,并引入逻辑推理机制,规划与推理显著增强了模型解决数学推导、代码编写、多跳问答等困难问题的能力。在检索增强生成的语境下考虑规划与推理,也就是在研究检索到的内容如何更好增强规划与推理,以及如何用规划与推理实现更好的检索。
参考文献
[1]: Verma, Prakhar, et al. "Plan RAG: Efficient Test-Time Planning for Retrieval Augmented Generation." Workshop on Reasoning and Planning for Large Language Models. 2025.
[2]: Zhang, Zhuocheng, Yang Feng, and Min Zhang. "LevelRAG: Enhancing Retrieval-Augmented Generation with Multi-hop Logic Planning over Rewriting Augmented Searchers." arXiv preprint arXiv:2502.18139 (2025).
[3]: Li, Xingxuan, et al. "Can We Further Elicit Reasoning in LLMs? Critic-Guided Planning with Retrieval-Augmentation for Solving Challenging Tasks." arXiv preprint arXiv:2410.01428 (2024).
[4]: Li, Xiaoxi, et al. "Search-o1: Agentic search-enhanced large reasoning models." arXiv preprint arXiv:2501.05366 (2025).
[5]: Jin, Bowen, et al. "Search-r1: Training llms to reason and leverage search engines with reinforcement learning." arXiv preprint arXiv:2503.09516 (2025).
[6]: Zheng, Yuxiang, et al. "Deepresearcher: Scaling deep research via reinforcement learning in real-world environments." arXiv preprint arXiv:2504.03160 (2025).

祝我们的 庞悦博士、李彦增博士、熊云帆硕士、王斐硕士、汪长城硕士毕业快乐!

欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

