




1 MySQL数据库的优化器追踪
学习和研究Oracle优化器时会遇到10053事件,这是Oracle数据库中的一个跟踪事件,用于捕获优化器(CBO)的决策过程信息,这个事件是理解Oracle优化器的工作原理,分析和诊断SQL执行计划问题必不可少的工具。
MySQL也提供了类似的技术手段,MySQL优化器包含了执行追踪的能力,使用优化器追踪的接口通过一系列optimizer_trace_xxx系统变量和INFORMATION_SCHEMA.OPTIMIZER_TRACE表提供。基本步骤如下
1)激活优化器追踪
SET OPTIMIZER_TRACE="enabled=on",END_MARKERS_IN_JSON=on;
2)执行要追踪的SQL语句
下面这条语句也是本文要解析的SQL语句,是一个in条件的子查询
SELECT class_num, class_name
FROM class
WHERE class_num IN
(SELECT class_num FROM roster);
3)查询OPTIMIZER_TRACE表
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
反复执行步骤2和3,默认一条语句的追踪会覆盖前一条追踪结果,可以通过optimizer_trace_offset和optimizer_trace_limit系统变量调整,保存多条语句的追踪结果,举例如下
--显示刚才执行的5条语句的追踪结果。
SET optimizer_trace_offset=-5, optimizer_trace_limit=5
4)关闭优化器追踪
SET OPTIMIZER_TRACE="enabled=off"
2 json解析工具
追踪MySQL优化器产生的文件是json格式的,简单语句的追踪文件也有上百行,复杂的语句的的追踪计划几百行上千行也不罕见。如果不借助合适的工具,分析起来十分困难,比如对齐、操作之间的关系等很难理清。好在有不少json的解析工具可以使用,这些工具中有离线的,不如sublime text里的pretty json扩展,也有在线的,这篇文章介绍一个比较好用的在线工具,以及如何使用这个工具分析、解析,从而理解MySQL的执行计划。这个工具的地址如下
json在线解析格式化
网页如下
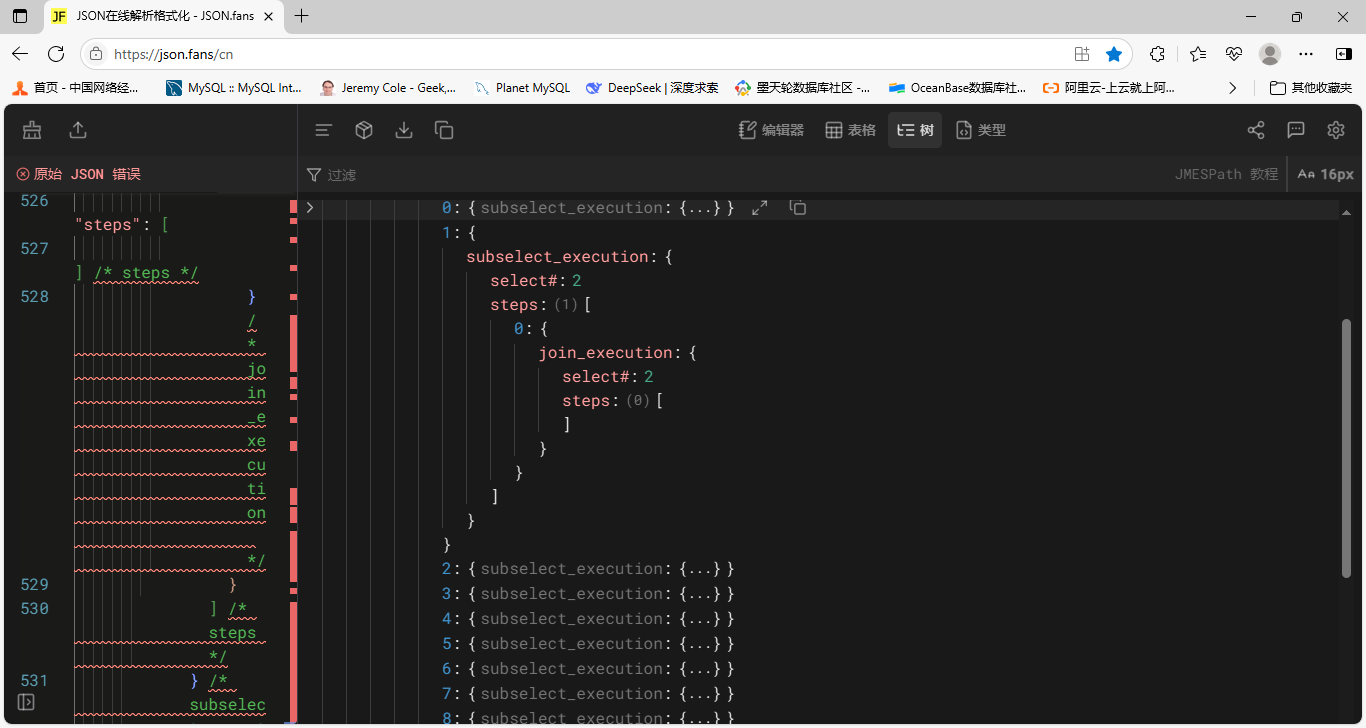
左边栏内有一个向上的箭头,点击可以上传json文件,也可以将文件内容直接复制粘贴到左边的内容框内。右边栏内点击图标树,以树形结构显示json文件,鼠标指向一行时,如显示向左的小箭头则可以点击展开此行,显示向下的小箭头则可以将此行的下级内容收起。
3 语句的执行计划
语句中查询的两个表的行数
mysql> select count(*), 'class' from class
-> union
-> select count(*), 'roster' from roster;
+----------+--------+
| count(*) | class |
+----------+--------+
| 10 | class |
| 3000 | roster |
+----------+--------+
2 rows in set (0.00 sec)
查看这条语句是,关闭了MySQL的半连接转换,优化器执行的典型的关联子查询语句的执行计划
mysql> explain SELECT class_num, class_name FROM class WHERE class_num IN (SELECT class_num FROM roster);
+----+--------------------+--------+------------+----------------+---------------+-----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+--------+------------+----------------+---------------+-----------+---------+------+------+----------+-------------+
| 1 | PRIMARY | class | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | roster | NULL | index_subquery | class_num | class_num | 4 | func | 600 | 100.00 | Using index |
+----+--------------------+--------+------------+----------------+---------------+-----------+---------+------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
这是一个典型的关联子查询,执行计划有两个查询,第一个查询是对class表的全表扫描,然后以扫描出的每一行为条件,执行第二个关联子查询,使用索引class_num对roster进行访问。
mysql> show warnings;
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `airportdb`.`class`.`class_num` AS `class_num`,`airportdb`.`class`.`class_name` AS `class_name` from `airportdb`.`class` where <in_optimizer>(`airportdb`.`class`.`class_num`,<exists>(<index_lookup>(<cache>(`airportdb`.`class`.`class_num`) in roster on class_num))) |
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
上面显示的优化器对查询执行的转换,可以看出,优化器将in操作转换成了exists,还可以看到的一点是,优化器对子查询进行了物化(将查询结果存在内存中)。使用tree格式显示执行计划也可以看到这一点
mysql> explain analyze SELECT distinct class.class_num, class.class_name FROM class INNER JOIN roster WHERE class.class_num = roster.class_num;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Table scan on <temporary> (cost=7.47..9.84 rows=10) (actual time=0.989..0.991 rows=5 loops=1)
-> Temporary table with deduplication (cost=7.21..7.21 rows=10) (actual time=0.987..0.987 rows=5 loops=1)
-> Nested loop inner join (cost=6.21 rows=10) (actual time=0.273..0.895 rows=5 loops=1)
-> Table scan on class (cost=1.25 rows=10) (actual time=0.0393..0.0472 rows=10 loops=1)
-> Limit: 1 row(s) (cost=6.4 rows=1) (actual time=0.0761..0.0761 rows=0.5 loops=10)
-> Covering index lookup on roster using class_num (class_num=class.class_num) (cost=6.4 rows=600) (actual time=0.0758..0.0758 rows=0.5 loops=10)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
从执行计划可以看出,外表执行的全表扫描,返回10行数据,子查询执行的索引扫描,执行了10次。
4 执行计划追踪文件解析
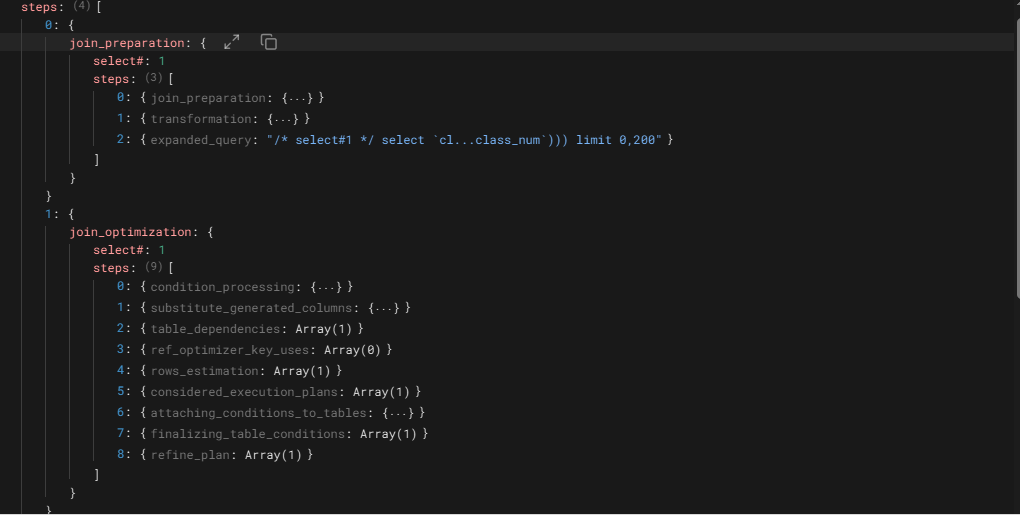
将语句的优化器追踪文件上传到上面的在线解析工具网站,可以看到以树形结构显示的执行计划,将二级一下的内容都收起,只显示到执行计划的第二级,如下图
4.1 整体分析
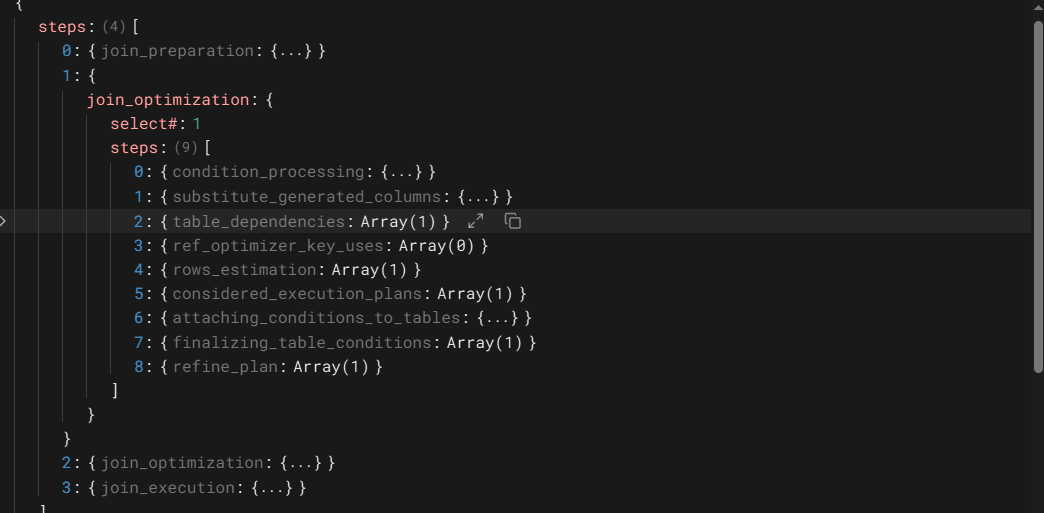
1
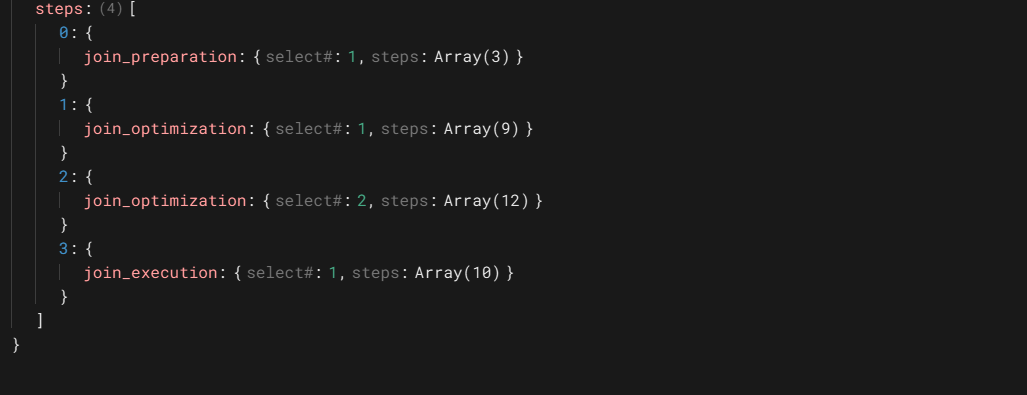
从上图看出这个执行计划共有四个步骤。join_optimization有两个,这个应为这条语句包含一个子查询的缘故。还可以看到每个步骤的操作对象,select#:n,这里的n是同执行计划里的id相对应的。另外还可以看到的是每个步骤下的有几个子步骤,如join_preparation是3步。
4.2 主要步骤分析
4.2.1 join_preparation
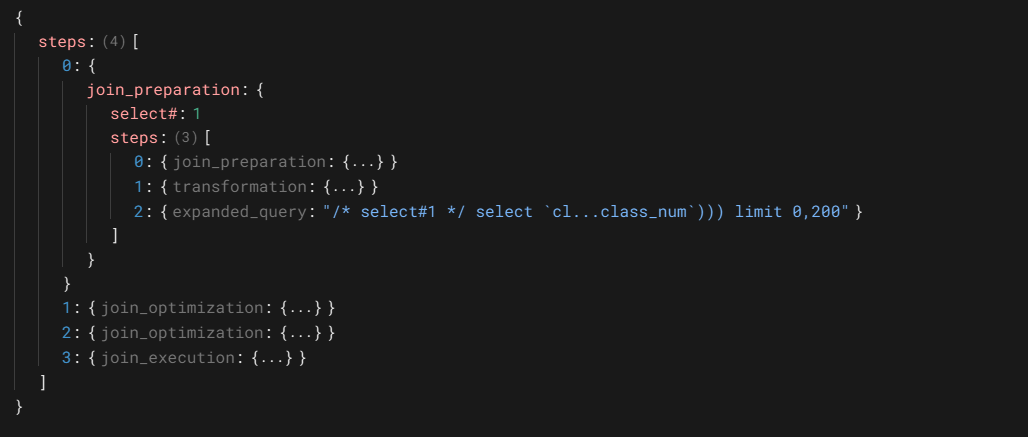
展开后,join_preparation操作的执行对象是select#:1,即对class表的查询,执行三个操作,第一个操作也是一个join_preparation操作,第二个是查询的转换操作,第三个是查询的扩展操作。先看第一个join_preparation操作
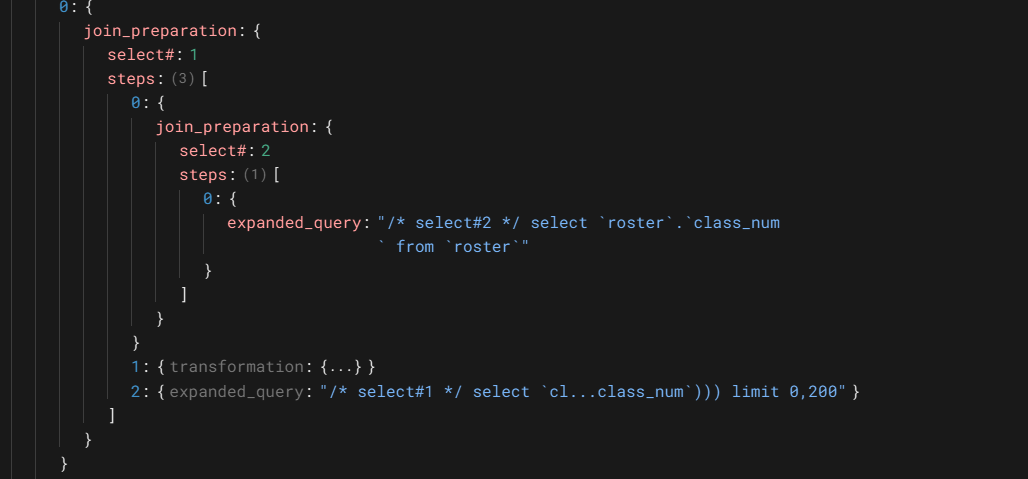
这个操作的执行的对象是select#:2,即子查询,MySQL为每个join(对应一个select)操作执行一次prepare操作,这个操作执行的是子查询对查询的扩展。
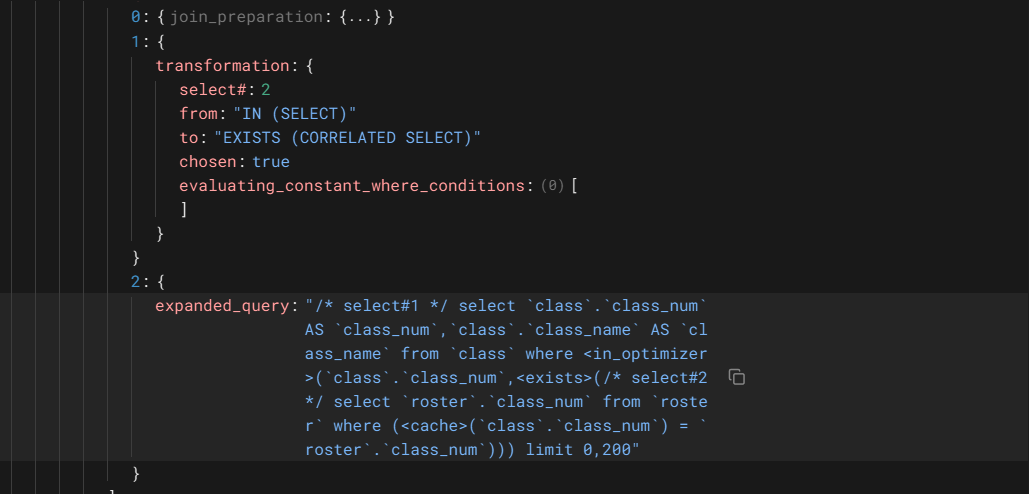
上图同时显示了第二个和第三操作的详细信息,第二个操作时转换操作,将子查询从in语法转换成exist语法,第三个操作是查询扩展,将语句扩展成优化器理解的形式。
4.2.2 join_optimization
MySQL为每个join(select)执行一次优化,首先执行的是对主查询的优化
优化的对象是select#:1 ,共执行9个步骤
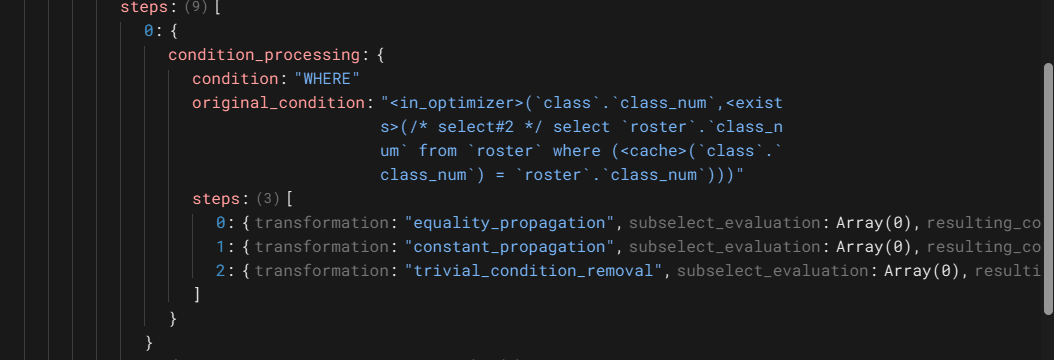
第一个步骤是条件处理,执行三个转换,等式传播,常量传播,无效条件移除(如1=1)。
{
"rows_estimation": [
{
"table": "`class`",
"range_analysis": {
"table_scan": {
"rows": 10,
"cost": 4.1
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": true,
"key_parts": [
"class_num"
]
}
],
"setup_range_conditions": [],
"group_index_skip_scan": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"skip_scan_range": {
"chosen": false,
"cause": "disjuntive_predicate_present"
}
}
}
]
}
第二个是行评估操作,评估操作返回的行数和成本,这里分别对全表扫描、索引范围扫描、组索引跳扫、索引范围跳扫进行了评估,给出了不采用后面两个操作的原因。
{
"considered_execution_plans": [
{
"plan_prefix": [],
"table": "`class`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 10,
"access_type": "scan",
"resulting_rows": 10,
"cost": 2,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 10,
"cost_for_plan": 2,
"chosen": true
}
]
}
这一步是考虑的执行计划,显示的是执行计划的信息,包括最佳访问路径等,chosen的值为true,指示出优化器选择了这个执行计划。
{
"finalizing_table_conditions": [
{
"table": "`class`",
"original_table_condition": "<in_optimizer>(`class`.`class_num`,<exists>(/* select#2 */ select `roster`.`class_num` from `roster` where (<cache>(`class`.`class_num`) = `roster`.`class_num`)))",
"final_table_condition ": "<in_optimizer>(`class`.`class_num`,<exists>(/* select#2 */ select `roster`.`class_num` from `roster` where (<cache>(`class`.`class_num`) = `roster`.`class_num`)))"
}
]
}
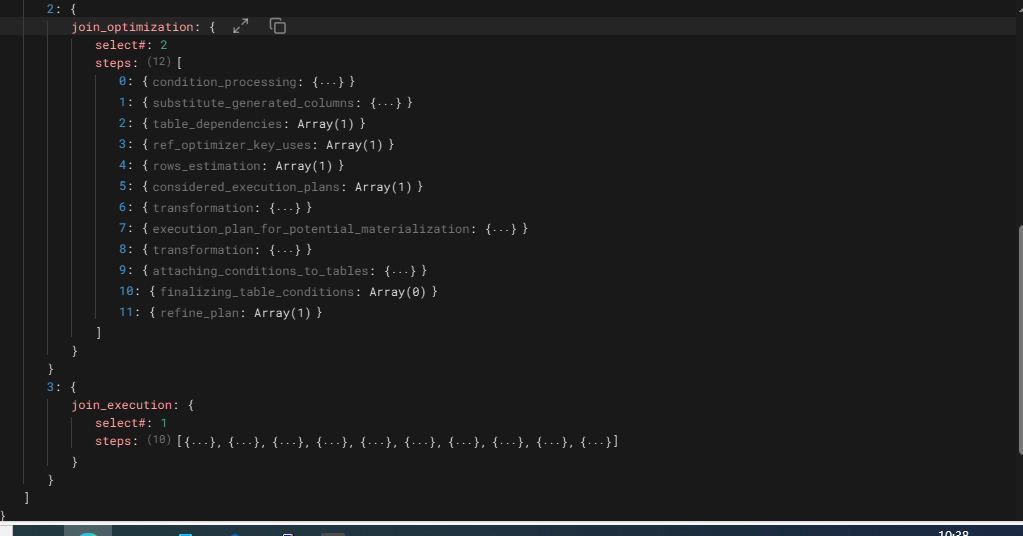
这个部分显示表class最终的过滤条件。下面看对第二个join及子查询的优化
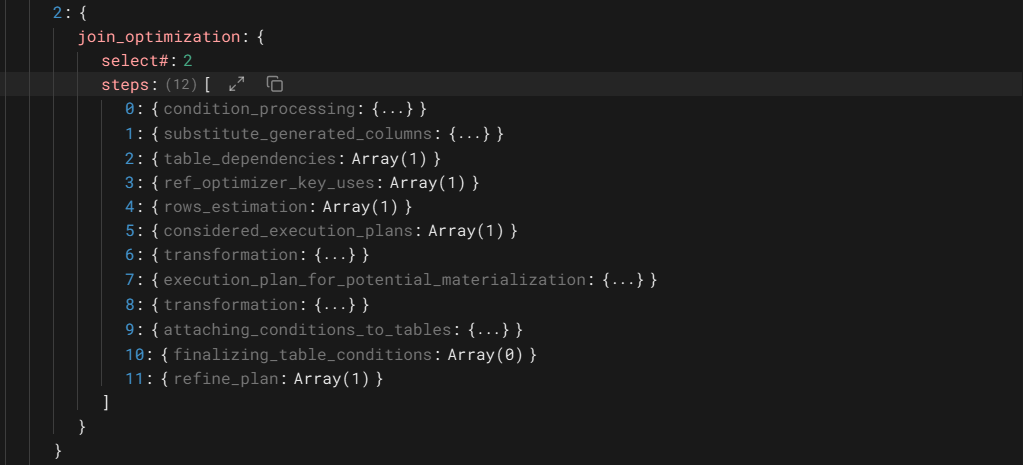
这个操作的优化步骤较多,有11步,和前面不同的多了第7步,潜在物化的执行计划以及对转换操作,这里只对和前一个操作有明显不同的进行分析
{
"ref_optimizer_key_uses": [
{
"table": "`roster`",
"field": "class_num",
"equals": "<cache>(`class`.`class_num`)",
"null_rejecting": true
}
]
}
这一步是优化器考虑的索引ref操作,即通过索引来访问表。
{
"considered_execution_plans": [
{
"plan_prefix": [],
"table": "`roster`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "class_num",
"rows": 600,
"cost": 61.3467,
"chosen": true
},
{
"access_type": "scan",
"cost": 307.909,
"rows": 3000,
"chosen": false,
"cause": "cost"
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 600,
"cost_for_plan": 61.3467,
"chosen": true
}
]
}
优化器考虑的执行计划的信息,最佳访问路径选择了使用索引class_num的ref操作,它访问的行数和成本明显更低。
{
"transformation": {
"select#": 2,
"from": "IN (SELECT)",
"to": "materialization",
"has_nullable_expressions": false,
"treat_UNKNOWN_as_FALSE": true,
"possible": true
}
}
这是对子查询的转换,评估物化的可能性。
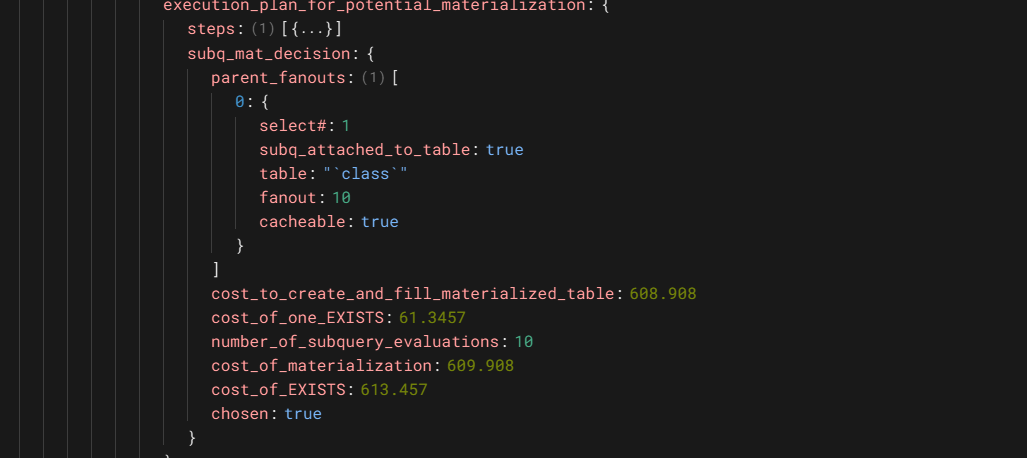
子查询物化的执行计划,物化的成本和exist的成本的比较,exist执行10次,每次61.3457,总成本是613.457,物化的成本是609.908,最终选择了物化。
```json
{
"select#": 2,
"from": "IN (SELECT)",
"to": "materialization",
"chosen": true,
"unknown_key_1": {
"creating_tmp_table": {
"tmp_table_info": {
"table": "<materialized_subquery>",
"columns": 1,
"row_length": 5,
"key_length": 4,
"unique_constraint": false,
"makes_grouped_rows": false,
"cannot_insert_duplicates": true,
"location": "TempTable"
}
}
}
}
创建子查询临时表的信息。
4.2.3 join_execution
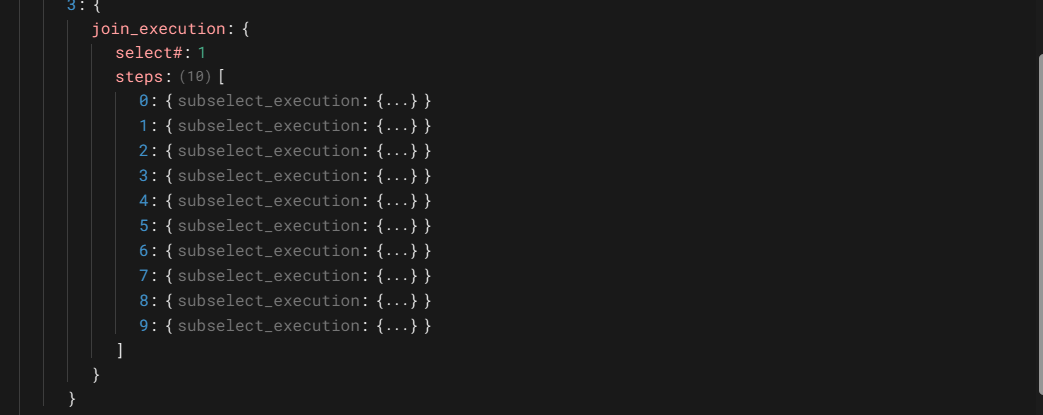
join_execution的操作对象是select#:1,这个操作有10个子操作,即执行了10子查询操作(subselect_execution),主查寻返回的行数也是10行,这可以从语句的实际执行里Covering index lookup on roster using class_num这个操作的loops的值是10得到验证。
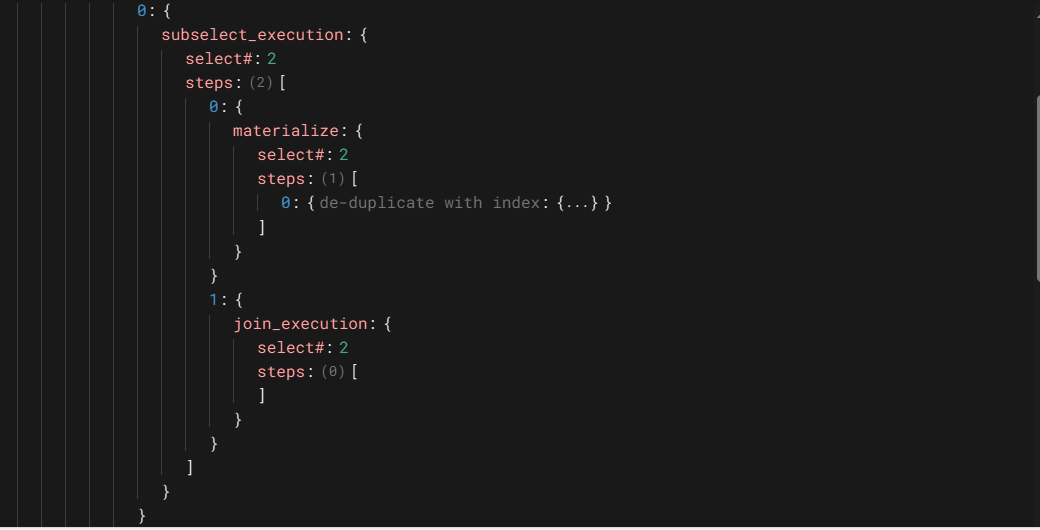
子查询的首次执行,这个操作有两步,第一步是子查询的物化,这一步执行一个操作,使用索引去重;第二步是子查询第一个循环的执行。
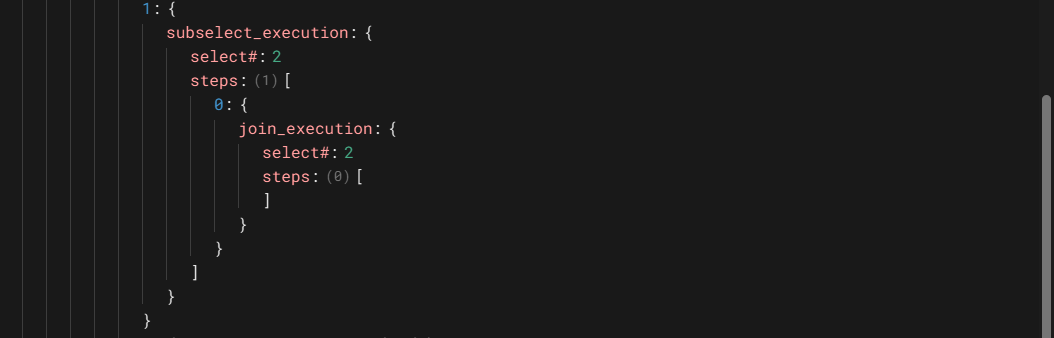
这个是子查询的第二次执行,这一次执行可以利用前面物化的结果,只有一步,即执行子查询。
4.3 执行计划生成过程一览
放一个执行计划的整体图,看一下效果
5小结
通过分析过程可以看出,使用json工具,更容易从总体上把握优化器执行计划的生成过程,在分析的过程中,可以对树的每一级结构进行展开和收缩,也支持对每一级结构的单独复制,使对每一部分进行深度的分析也很容易。
