





数仓成本优化需从“成本结构拆解”入手,聚焦存储、计算、人力、架构四大核心模块,通过“技术优化-流程提效-架构升级”三级策略,在不影响数据可用性和业务需求的前提下,实现“降本”与“提效”的平衡。
一、先搞清楚:数仓成本从哪里来?
数仓成本的核心构成可概括为“3+1”模型:
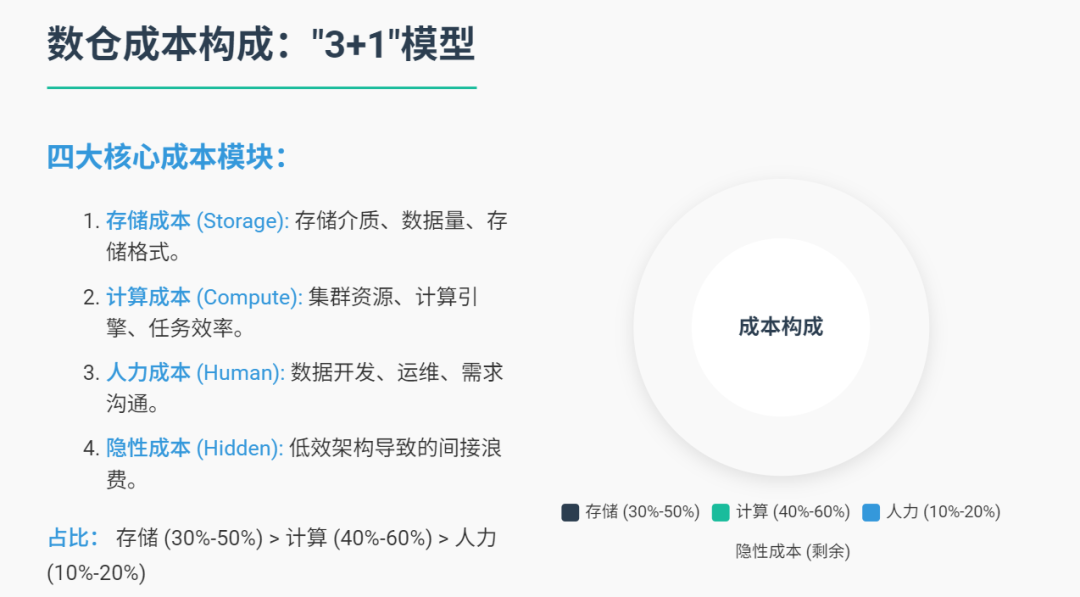
存储成本:数据存储介质(HDFS/对象存储/云数据库)、数据量(冗余/冷数据)、存储格式(文本/列式压缩);
计算成本:集群资源(CPU/内存/磁盘IO)、计算引擎(MapReduce/Spark/Flink)、任务效率(重复计算/资源错配);
人力成本:数据开发(ETL脚本编写)、运维(任务监控/故障修复)、需求沟通(业务方反复变更);
隐性成本:低效架构导致的“间接浪费”(如数据链路冗长、跨部门数据孤岛重复存储)。
二、存储成本优化:从“无限扩容”到“精益管理”
存储成本占比通常达数仓总成本的30%-50%,核心优化思路是“数据分级存储+冗余清理+格式压缩”,减少无效存储占用。
1. 数据生命周期分级:让数据“待在该待的地方”
按数据“访问频率”和“业务价值”分级,匹配不同成本的存储介质,避免“热数据用冷存储(慢)”或“冷数据用热存储(贵)”。

| 数据级别 | 定义 | 存储介质 | 成本对比(相对HDFS) | 管理策略 |
|---|---|---|---|---|
| 热数据 | 近3个月,高频查询(如实时报表、业务监控) | HDFS/云数据库(RDS/Redshift) | 100% | 保留全量,支持低延迟查询(毫秒级) |
| 温数据 | 3个月-1年,低频查询(如周/月报表) | 对象存储(S3/OSS/OBS) | 30%-50% | 保留表结构,数据迁移至对象存储(Hive通过ALTER TABLE SET LOCATION指向),查询时按需加载 |
| 冷数据 | 1年以上,极少查询(如合规归档、历史审计) | 离线归档存储(磁带库/S3 Glacier) | 10%-20% | 压缩后归档,仅保留元数据,查询需提前申请恢复(如通过工单触发数据解冻) |
落地工具:
调度工具(Airflow/DolphinScheduler)定期执行“分级迁移任务”(如每日凌晨迁移超3个月的温数据,每月迁移超1年的冷数据);
元数据管理工具(Apache Atlas/Amundsen)记录数据级别和存储位置,支持“一键查询数据存储状态”。

2. 冗余数据“断舍离”:删除“无效数据”
数仓中30%-50%的数据为冗余数据(临时表、废弃表、重复表),需定期清理:
临时表/中间表清理:
规则:保留最近N天数据(如ETL中间表保留7天,临时查询结果表保留3天),通过调度工具自动删除过期分区(如Hive
ALTER TABLE ... DROP IF EXISTS PARTITION (dt < '${date-7}')
);案例:某电商数仓通过清理日均产生的500+临时表,存储成本降低25%。

废弃表下线:
流程:每季度审计表使用率(通过查询日志工具如Hive Server2日志、Trino查询记录),对“6个月无查询记录+业务方确认无用”的表直接删除(需先备份元数据);
工具:用Python脚本批量分析查询日志,输出“低价值表清单”,减少人工筛查成本。

重复表合并:
场景:不同业务线重复建设相同指标表(如“用户活跃表”同时存在于电商、支付、营销部门),需推动跨部门数据复用,合并为“公共汇总表”;
效果:某金融数仓合并12张重复指标表后,存储占用减少40%,计算任务量减少35%。

3. 数据格式与压缩:用“更小的空间存更多的数据”
文本格式(CSV/TSV)存储效率极低,转为列式压缩格式可降低70%-90%存储占用,同时提升查询性能(减少IO)。
| 数据格式 | 压缩率(相对CSV) | 查询性能(相对CSV) | 适用场景 |
|---|---|---|---|
| Parquet | 80%-90% | 5-10倍 | 结构化数据(事实表、维度表) |
| ORC | 75%-85% | 3-8倍 | Hive生态优先 |
| CSV(gzip压缩) | 50%-60% | 1-2倍 | 临时数据、外部接口输出 |
落地步骤:
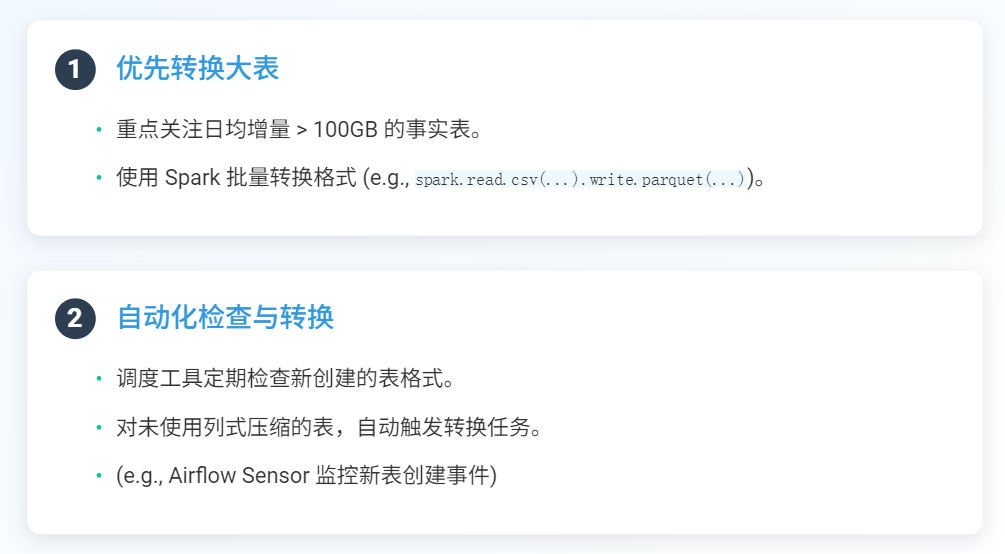
优先转换大表(如日均增量>100GB的事实表),通过Spark批量转换格式(
spark.read.csv(...).write.parquet(...)
);调度工具定期检查新表格式,对未使用列式压缩的表自动触发转换任务(如通过Airflow的Sensor监控新表创建事件)。
三、计算成本优化:从“资源浪费”到“精准匹配”
计算成本占比约40%-60%,核心优化思路是“资源精细化配置+减少重复计算+引擎效率提升”,提升CPU/内存利用率。

1. 资源错配:避免“大马拉小车”或“小马拉大车”
数仓中60%以上的任务存在资源配置不合理问题(如简单SQL任务分配8核16G内存,或复杂JOIN任务仅2核4G),需按“任务画像”动态调整资源。
任务画像分类:

轻量型:简单聚合(如
COUNT/DISTINCT
)、单表过滤,CPU<1核,内存<2G(例:每日用户注册数统计);中量型:多表JOIN、窗口函数,CPU 2-4核,内存4-8G(例:用户购买行为明细表);
重型型:全表扫描、大表JOIN(10亿级数据),CPU 8核+,内存16G+(例:历史订单全量汇总)。
动态资源调整:

通过调度工具监控任务历史资源使用率(如Airflow的
TaskInstance
metrics、DolphinScheduler的任务日志),对“CPU使用率<30%”的任务下调资源(例:从4核8G降至2核4G),对“频繁OOM”的任务上调资源;工具支持:Spark任务开启动态资源分配(
spark.dynamicAllocation.enabled=true
),自动根据数据量调整executor数量。
2. 重复计算:让“一份计算结果被多次复用”
数仓中30%-40%的计算任务在重复计算相同中间结果(如不同报表都计算“近7日GMV”),需通过“结果复用”减少无效计算。
公共中间层建设:
抽象“公共汇总层”(如DWS层),将高频复用的指标(如用户活跃、订单金额)统一计算并存储,下游报表/应用直接读取,避免重复JOIN和聚合;
案例:某零售数仓建设公共中间层后,下游任务计算量减少50%,集群CPU使用率从80%降至45%。

结果缓存:
对实时看板、高频查询指标(如“当前在线人数”),通过调度工具定时计算并写入缓存(Redis/ClickHouse),查询时直接读取缓存(TTL设为5-15分钟);
工具:用Flink定时任务计算指标,写入Redis,业务侧通过API读取,避免每次查询重跑SQL。

依赖驱动调度:
通过元数据血缘工具(如Atlas)标记“上游表→下游表”依赖关系,仅当上游表数据更新时触发下游任务(例:用户表分区更新→用户标签表重跑),避免“每日全量重跑”;
调度工具集成血缘信息:如Airflow通过
ExternalTaskSensor
监控上游任务状态,仅就绪后才执行下游。
3. 计算引擎优化:用“更快的引擎跑更高效的任务”
低效引擎(如MapReduce)和不合理的计算逻辑(如笛卡尔积、全表扫描)会显著增加计算耗时和资源消耗。
引擎替换:
批处理任务:用Spark替代MapReduce(性能提升3-5倍,资源占用减少40%);
即席查询:用Trino/Presto替代Hive on MapReduce(查询速度提升10-100倍,适合业务方临时分析);
流批一体:对“实时+离线均需”的指标(如实时GMV+日终GMV),用Flink批流一体架构统一计算逻辑,避免重复开发(减少50%代码量)。

SQL逻辑优化:
避免全表扫描:强制分区过滤(
WHERE dt='${date}'
)、使用索引(如Hive Bloom Filter索引);减少JOIN次数:通过子查询合并、维度退化(将小维度表字段冗余至事实表);
案例:某银行数仓将“5表JOIN”优化为“2表JOIN+维度退化”,任务耗时从2小时降至20分钟,资源占用减少70%。

四、人力成本优化:从“人工重复”到“自动化提效”
人力成本(开发+运维)占比约10%-20%,核心优化思路是“流程标准化+工具自动化+自助化”,减少人工干预和重复劳动。
1. 开发流程标准化:减少“重复造轮子”
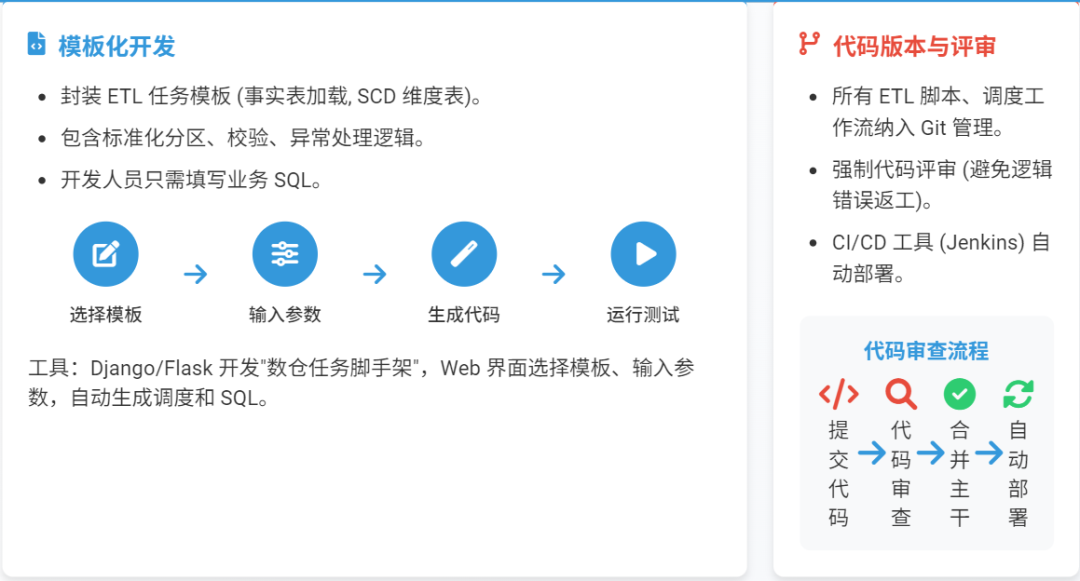
模板化开发:
封装ETL任务模板(如“事实表加载模板”“维度表缓慢变化维模板”),包含标准化的分区管理、数据校验、异常处理逻辑,开发人员只需填写业务SQL;
工具:用Django/Flask开发“数仓任务脚手架”,通过Web界面选择模板、输入参数(表名、分区字段),自动生成调度工作流和SQL脚本。

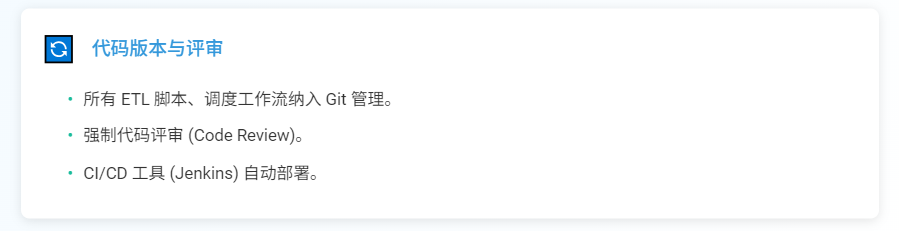
代码版本与评审:
所有ETL脚本、调度工作流纳入Git管理,强制代码评审(避免逻辑错误导致返工),通过CI/CD工具(Jenkins)自动部署(减少手动操作耗时)。
2. 运维监控自动化:减少“人工盯屏”

异常监控告警:
数据质量监控:用Great Expectations配置规则(如“订单金额>0”“用户ID非空”),异常时自动推送钉钉/邮件告警;
任务监控:调度工具设置“失败自动重试+告警升级”(首次失败重试2次,间隔5分钟;重试失败通知负责人,30分钟未处理通知团队负责人);
资源监控:用Prometheus+Grafana监控集群CPU/内存使用率,设置阈值告警(如使用率>90%时扩容,<30%时缩容)。
自动修复:
对常见故障(如任务超时、源数据延迟),配置调度工具自动修复规则(如超时任务自动增加资源重试,源数据延迟时触发补数任务)。
3. 业务自助化:让“业务方自己取数”

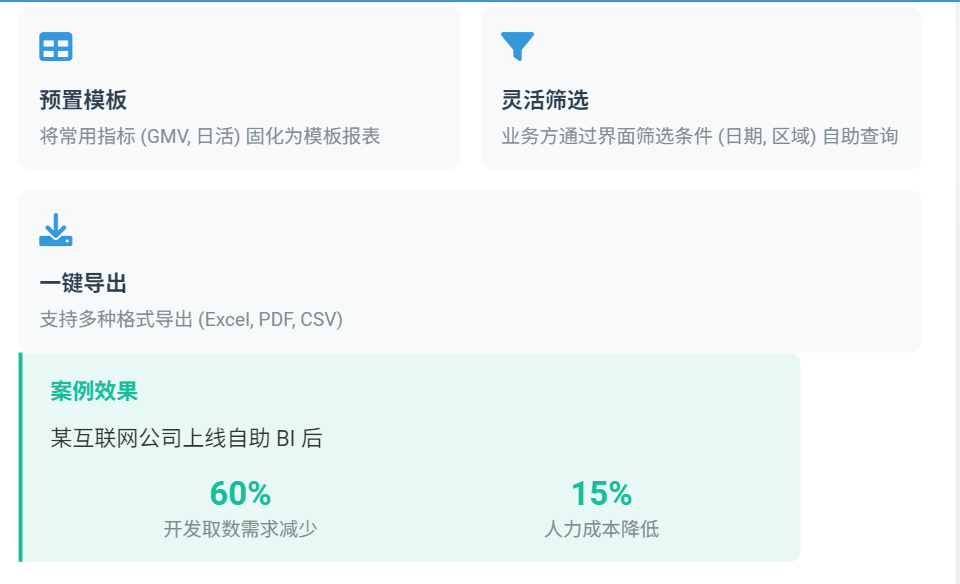
自助报表平台:
搭建BI平台(如Tableau/Metabase),将常用指标(如GMV、日活)固化为模板报表,业务方通过界面筛选条件(日期、区域)自助查询,减少“开发取数”需求;
案例:某互联网公司上线自助BI后,数据开发取数需求减少60%,人力成本降低15%。
五、架构升级:从“传统数仓”到“云原生+精益数仓”
长期成本优化需依赖架构升级,从“静态集群”转向“弹性、按需”的云原生架构,从“全量存储计算”转向“按需存储计算”。

1. 云原生架构:按需付费,避免资源闲置
弹性集群:使用云厂商托管数仓(如AWS Redshift、阿里云AnalyticDB),支持“按查询量付费”或“弹性扩缩容”(业务高峰期扩容,低谷期缩容);
存算分离:采用“计算集群+对象存储”架构(如Hadoop存算分离、Snowflake),存储和计算资源独立扩缩,避免“为存储买计算,为计算买存储”;
效果:某企业从自建Hadoop集群迁移至云原生数仓后,资源利用率从40%提升至80%,年成本降低35%。

2. 精益数仓:“小而美”替代“大而全”
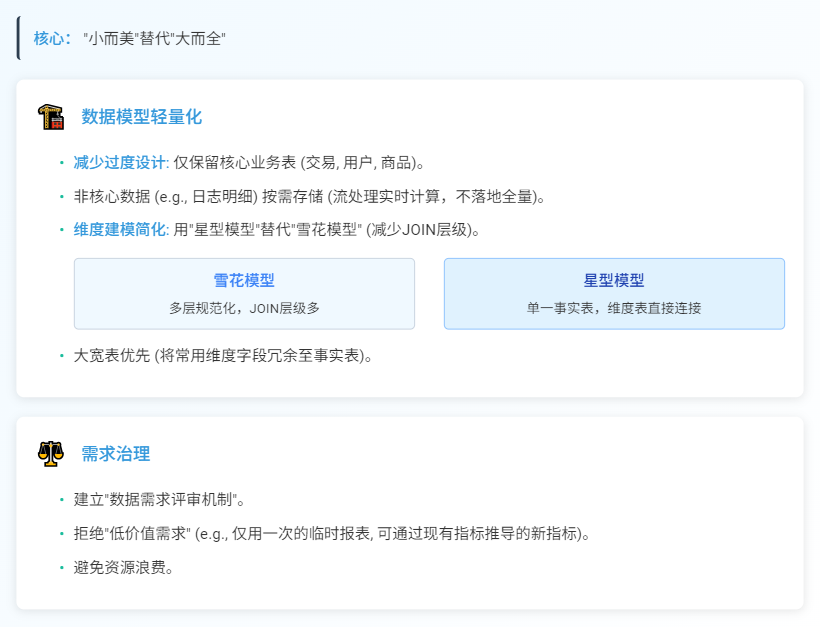
数据模型轻量化:
减少过度设计:仅保留核心业务表(如交易、用户、商品),非核心数据(如日志明细)按需存储(通过流处理实时计算,不落地全量);
维度建模简化:用“星型模型”替代“雪花模型”(减少JOIN层级),大宽表优先(将常用维度字段冗余至事实表)。
需求治理:
建立“数据需求评审机制”,拒绝“低价值需求”(如“仅用一次的临时报表”“可通过现有指标推导的新指标”),避免资源浪费。

六、实施步骤:从“快速见效”到“长期优化”
| 阶段 | 目标 | 关键动作 | 预期效果 |
|---|---|---|---|
| 短期(1-2月) | 快速降本(存储+计算) | 清理冗余表、转换列式压缩格式、优化高频任务资源配置 | 存储成本降低20%-30%,计算资源利用率提升15% |
| 中期(3-6月) | 流程提效(自动化+标准化) | 部署数据质量工具、开发ETL模板、上线自助BI平台 | 人力成本降低10%-20%,数据异常率降低40% |
| 长期(6月+) | 架构升级(云原生+精益) | 迁移至存算分离架构、建设公共中间层、治理低价值需求 | 总成本降低30%-50%,业务响应速度提升50% |
总结
数仓成本优化不是“一刀切”的削减,而是“精准识别浪费点+系统性优化”的过程:短期通过“存储清理+资源调优”快速见效,中期通过“流程自动化+自助化”减少人力投入,长期通过“云原生+精益架构”实现可持续降本。核心是“以业务价值为导向”——只保留和计算对业务决策有价值的数据,让每一分资源都产生收益。

